有关dkt可参考的文章http://blog.kintoki.me/2017/06/06/tensorflow-dkt/

问题陈述
传统的评价方法,如考试和考试,只允许在考试结束后对学生进行评价。因此,这些方法不允许在课程开始时对学生应具备或在课程中学习的所有预期能力进行完整的预先评估。
另一方面,预测模型能够根据历史数据预测未来的信息。从学习管理系统(LMS)收集的数据可以作为训练模型的基础,该模型能够预测学生是否有足够的知识来回答尚未发现的问题,这一问题被称为知识跟踪(KT)。
因此,可以训练LSTM网络,以找出数据集中已解决问题之间的依赖关系,并用它来预测学生正确回答他尚未看到的考试问题的概率。
综上所述,解决选择问题的策略主要包括四个步骤:
1. 下载包含已在其知识组件中分类的已解决问题的大型数据集。
2. 预处理数据并将输入转换为网络预期格式。
3. 建立和训练一个LSTM网络来预测学生正确回答未来问题的概率。
4. 评估模型并改进它。
指标
AUC:这个指标反映了模型区分正确回答和错误回答的能力,其中1.0分表示完全区分。
分析
数据探索
神经网络的监督训练需要一个数据集,其中的例子已经包含了预期的标签。因此,本项目使用最新版本的公共数据集“ASSISTments Skillbuilder data 2009-2010”[4],[5]中包含的示例。表1显示了关于这个数据集的一些统计信息。
表1——数据集统计

此数据集有超过500.000个二进制问题(其中标签为1,正确,或0,不正确),其中大多数问题已被分类到一种类型的知识组件中。在所有可用属性中,知识构件是模型最重要的特征。在训练过程中,利用它找出问题之间的关系和依赖关系。因此,我们需要确保删除该属性中缺少值的那些问题。
通过分析数据集统计数据,可以看出我们有30个不同的属性可用。在所有这些属性中,只选择了三个属性来使用:用户标识符(“user_id”);问题知识组件的标识(“skill_id”);以及一个二进制变量(“correct”),用于指示学生是否正确地回答了问题。在表2中可以看到一个数据样本来更好地阐明整个想法。

探索性可视化
在这个数据集中要解决的一个重要问题是一个问题可以拥有的技能数量。在图1中,我们可以看到有些问题没有任何技能,而其他问题有一个或多个技能。我们可以调整模型或数据集来处理多技能问题,但如果没有技能标记,我们就不能有问题。因此,我们需要从数据集中删除所有没有技能的问题。

对于多技能问题,要以简单的方式处理这一问题,我们可以做两件事:将技能组合作为新的联合技能;或者将技能分成多个重复的响应序列,每个序列中只有一个技能。这个数据集附带了已经应用的第二种方法,为了简单起见,我们将继续使用这种方法。

图2-每解决一个问题的学生的频率
我们需要解决的另一个问题是每个学生解决的问题的数量。在图2中可以看到,有些学生只回答了一个问题(A类),而大多数学生回答的问题介于2到100个之间(B类)。我们还可以看到,我们有一些学生回答了600多个问题,这可能会导致我们由于记忆力不足而头痛。为了解决这一问题,我们可以将算法操作的时间窗口限制为一系列较小的问题。为了简单起见,我们在算法中按批处理提供数据,其中批处理中的每个问题序列将被填充为具有相同大小。
算法和技术
LSTM网络是一种考虑时间序列中元素间依赖关系的递归神经网络。由于学生正确回答问题B的概率取决于前一个问题是否正确回答,LSTM网络可能是本项目问题的可能解决方案。因此,我们将建立一个LSTM网路,以找出资料集中问题之间的关系,并预测学生正确回答未来问题的机率。在图3中,可以看到提议模型的架构。
为了构建模型,它使用了Keras,由于这个工具,我选择了一个 遮罩层是模型中的第一层。该层负责处理用于填充序列和填充不完整批次的掩码值。作为输入,该层将接收一批20个相同大小的序列(每个批的大小可能不同),其中包含246个特性。下一层是由250个单元组成的LSTM层。该层负责查找时间序列中问题之间的关系

第三层是dropout层,为60%,有助于防止过度拟合。最后一层是使用SIGMOD激活函数,由123个神经元组成的dense层(123知识构成的类型数),。因此,预期的输出将是学生正确回答或不回答数据集中技能的概率。最后选择的两个参数是二进制交叉熵作为损失函数,Adagrad作为优化器。所有其他可以设置的参数都没有改变,其默认值可以在Keras文档[6]中找到。
输入编码

由于这种类型的网络只接受相同大小的输入数据,我们需要对“skill_ids”功能应用一个热编码,并将问题序列填充到相同的大小。为了使模型对学生回答正确与否的技能敏感,我们将在应用一个热编码之前将每个技能id与标签(问题答案)一起编码。因此,输入维度将是技能总数的2倍,其中有回答错误的技能ID和回答正确的技能ID。预期网络的输入是一个序列,包含学生解决的所有问题,如表3所示。
具体实现
数据预处理
分析数据集,我们发现在训练模型之前我们需要做一些预处理。让我们总结一下我们要做的:
1. 在没有技能id的情况下删除问题。
2. 将数据样本转换为按用户标识分组的序列。
3. 将技能id值转换为从零开始的连续变量。
4. 将数据分成三个数据集(培训、验证和测试)。
5. 将技能id与标签一起编码(问题答案)。
6. 应用一个热编码。
7. 填写不完整的批次。
8. 按相同的顺序填充
def load_dataset(fn, batch_size=32, shuffle=True):
df = pd.read_csv(fn)
if "skill_id" not in df.columns:
raise KeyError(f"The column 'skill_id' was not found on {fn}")
if "correct" not in df.columns:
raise KeyError(f"The column 'correct' was not found on {fn}")
if "user_id" not in df.columns:
raise KeyError(f"The column 'user_id' was not found on {fn}")
if not (df['correct'].isin([0, 1])).all():
raise KeyError(f"The values of the column 'correct' must be 0 or 1.")
# Step 1.1 - Remove questions without skill
df.dropna(subset=['skill_id'], inplace=True)
# Step 1.2 - Remove users with a single answer
df = df.groupby('user_id').filter(lambda q: len(q) > 1).copy()
# Step 2 - Enumerate skill id
df['skill'], _ = pd.factorize(df['skill_id'], sort=True)
# Step 3 - Cross skill id with answer to form a synthetic feature
df['skill_with_answer'] = df['skill'] * 2 + df['correct']
# Step 4 - Convert to a sequence per user id and shift features 1 timestep
seq = df.groupby('user_id').apply(
lambda r: (
r['skill_with_answer'].values[:-1],
r['skill'].values[1:],
r['correct'].values[1:],
)
)
nb_users = len(seq)
# Step 5 - Get Tensorflow Dataset
dataset = tf.data.Dataset.from_generator(
generator=lambda: seq,
output_types=(tf.int32, tf.int32, tf.float32)
)
if shuffle:
dataset = dataset.shuffle(buffer_size=nb_users)
# Step 6 - Encode categorical features and merge skills with labels to compute target loss.
# More info: https://github.com/tensorflow/tensorflow/issues/32142
features_depth = df['skill_with_answer'].max() + 1
skill_depth = df['skill'].max() + 1
dataset = dataset.map(
lambda feat, skill, label: (
tf.one_hot(feat, depth=features_depth),
tf.concat(
values=[
tf.one_hot(skill, depth=skill_depth),
tf.expand_dims(label, -1)
],
axis=-1
)
)
)
# Step 7 - Pad sequences per batch
dataset = dataset.padded_batch(
batch_size=batch_size,
padding_values=(MASK_VALUE, MASK_VALUE),
padded_shapes=([None, None], [None, None]),
drop_remainder=True
)
length = nb_users // batch_size
return dataset, length, features_depth, skill_depth
在步骤1中,检测到66.326个样本需要从数据集中移除。步骤2生成了4.163个序列,而步骤3将技能id重新排列为[0 123]的连续间隔。在表5中,可以看到这些步骤之后的数据集摘要。

在第4步中,我们将前一步生成的序列分成三个序列:用于训练、验证和测试。它保留了20%的数据集用于测试,20%的剩余数据用于验证。在表6中可以看到每个数据集的摘要。

表 由于内存限制,每批执行步骤5-8。在步骤7中,不完整的批次用常量值-1填充,在步骤8中,序列按照其批次中的最大序列大小填充相同的常量。在步骤7-8中没有应用一个热编码,因为我们将在模型上使用一个遮罩层来处理它。
import numpy as np
import tensorflow as tf
from deepkt import data_util
class DKTModel(tf.keras.Model):
""" The Deep Knowledge Tracing model.
Arguments in __init__:
nb_features: The number of features in the input.
nb_skills: The number of skills in the dataset.
hidden_units: Positive integer. The number of units of the LSTM layer.
dropout_rate: Float between 0 and 1. Fraction of the units to drop.
Raises:
ValueError: In case of mismatch between the provided input data
and what the model expects.
"""
def __init__(self, nb_features, nb_skills, hidden_units=100, dropout_rate=0.2):
inputs = tf.keras.Input(shape=(None, nb_features), name='inputs')
x = tf.keras.layers.Masking(mask_value=data_util.MASK_VALUE)(inputs)
x = tf.keras.layers.LSTM(hidden_units,
return_sequences=True,
dropout=dropout_rate)(x)
dense = tf.keras.layers.Dense(nb_skills, activation='sigmoid')
outputs = tf.keras.layers.TimeDistributed(dense, name='outputs')(x)
super(DKTModel, self).__init__(inputs=inputs,
outputs=outputs,
name="DKTModel")
def compile(self, optimizer, metrics=None):
"""Configures the model for training.
Arguments:
optimizer: String (name of optimizer) or optimizer instance.
See `tf.keras.optimizers`.
metrics: List of metrics to be evaluated by the model during training
and testing. Typically you will use `metrics=['accuracy']`.
To specify different metrics for different outputs of a
multi-output model, you could also pass a dictionary, such as
`metrics={'output_a': 'accuracy', 'output_b': ['accuracy', 'mse']}`.
You can also pass a list (len = len(outputs)) of lists of metrics
such as `metrics=[['accuracy'], ['accuracy', 'mse']]` or
`metrics=['accuracy', ['accuracy', 'mse']]`.
Raises:
ValueError: In case of invalid arguments for
`optimizer` or `metrics`.
"""
def custom_loss(y_true, y_pred):
y_true, y_pred = data_util.get_target(y_true, y_pred)
return tf.keras.losses.binary_crossentropy(y_true, y_pred)
super(DKTModel, self).compile(
loss=custom_loss,
optimizer=optimizer,
metrics=metrics,
experimental_run_tf_function=False)
def fit(self,
dataset,
epochs=1,
verbose=1,
callbacks=None,
validation_data=None,
shuffle=True,
initial_epoch=0,
steps_per_epoch=None,
validation_steps=None,
validation_freq=1):
"""Trains the model for a fixed number of epochs (iterations on a dataset).
Arguments:
dataset: A `tf.data` dataset. Should return a tuple
of `(inputs, (skills, targets))`.
epochs: Integer. Number of epochs to train the model.
An epoch is an iteration over the entire data provided.
Note that in conjunction with `initial_epoch`,
`epochs` is to be understood as "final epoch".
The model is not trained for a number of iterations
given by `epochs`, but merely until the epoch
of index `epochs` is reached.
verbose: 0, 1, or 2. Verbosity mode.
0 = silent, 1 = progress bar, 2 = one line per epoch.
Note that the progress bar is not particularly useful when
logged to a file, so verbose=2 is recommended when not running
interactively (eg, in a production environment).
callbacks: List of `keras.callbacks.Callback` instances.
List of callbacks to apply during training.
See `tf.keras.callbacks`.
validation_data: Data on which to evaluate
the loss and any model metrics at the end of each epoch.
The model will not be trained on this data.
shuffle: Boolean (whether to shuffle the training data
before each epoch)
initial_epoch: Integer.
Epoch at which to start training
(useful for resuming a previous training run).
steps_per_epoch: Integer or `None`.
Total number of steps (batches of samples)
before declaring one epoch finished and starting the
next epoch. The default `None` is equal to
the number of samples in your dataset divided by
the batch size, or 1 if that cannot be determined. If x is a
`tf.data` dataset, and 'steps_per_epoch'
is None, the epoch will run until the input dataset is exhausted.
validation_steps: Only relevant if `validation_data` is provided.
Total number of steps (batches of
samples) to draw before stopping when performing validation
at the end of every epoch. If
'validation_steps' is None, validation
will run until the `validation_data` dataset is exhausted.
validation_freq: Only relevant if validation data is provided. Integer
or `collections_abc.Container` instance (e.g. list, tuple, etc.).
If an integer, specifies how many training epochs to run before a
new validation run is performed, e.g. `validation_freq=2` runs
validation every 2 epochs. If a Container, specifies the epochs on
which to run validation, e.g. `validation_freq=[1, 2, 10]` runs
validation at the end of the 1st, 2nd, and 10th epochs.
Returns:
A `History` object. Its `History.history` attribute is
a record of training loss values and metrics values
at successive epochs, as well as validation loss values
and validation metrics values (if applicable).
Raises:
RuntimeError: If the model was never compiled.
ValueError: In case of mismatch between the provided input data
and what the model expects.
"""
return super(DKTModel, self).fit(x=dataset,
epochs=epochs,
verbose=verbose,
callbacks=callbacks,
validation_data=validation_data,
shuffle=shuffle,
initial_epoch=initial_epoch,
steps_per_epoch=steps_per_epoch,
validation_steps=validation_steps,
validation_freq=validation_freq)
def evaluate(self,
dataset,
verbose=1,
steps=None,
callbacks=None):
"""Returns the loss value & metrics values for the model in test mode.
Computation is done in batches.
Arguments:
dataset: `tf.data` dataset. Should return a
tuple of `(inputs, (skills, targets))`.
verbose: 0 or 1. Verbosity mode.
0 = silent, 1 = progress bar.
steps: Integer or `None`.
Total number of steps (batches of samples)
before declaring the evaluation round finished.
Ignored with the default value of `None`.
If x is a `tf.data` dataset and `steps` is
None, 'evaluate' will run until the dataset is exhausted.
This argument is not supported with array inputs.
callbacks: List of `keras.callbacks.Callback` instances.
List of callbacks to apply during evaluation.
See [callbacks](/api_docs/python/tf/keras/callbacks).
Returns:
Scalar test loss (if the model has a single output and no metrics)
or list of scalars (if the model has multiple outputs
and/or metrics). The attribute `model.metrics_names` will give you
the display labels for the scalar outputs.
Raises:
ValueError: in case of invalid arguments.
"""
return super(DKTModel, self).evaluate(dataset,
verbose=verbose,
steps=steps,
callbacks=callbacks)
def evaluate_generator(self, *args, **kwargs):
raise SyntaxError("Not supported")
def fit_generator(self, *args, **kwargs):
raise SyntaxError("Not supported")
优化
为了更好地调整模型的参数,我不得不对其进行多次训练和评估。尝试中更改的主要参数有:
1. 优化器。
2. 批量大小。
3. dropout。
4. LSTM单元数。
它尝试了三种不同的优化器:RMSProp、Adam和Adagrad。三种不同的批量大小:10、20和32。三种不同的辍学率:60%、30%和50%。以及两个不同数量的LSTM单元:250和150。我的第一次尝试是:RMSProp;每批20个序列;60%的退出率;250个LSTM单元。
图4-所选优化器之间的比较

每一次试验的结果都是相似的,其中一次或另一次在验证损失上有微小的收益。每次尝试的日志可以在“logs”目录中找到,它们的摘要可以在excel文件中找到结果.xlsx“可以在同一目录中找到。在每次尝试中,最佳模型的权重也可以在“日志”中的相应目录中找到。它们可以用来验证我的结果,并与其他参数配置进行比较。

模型评估和验证
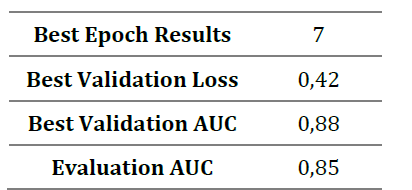
在图5中,可以看到使用上述模型配置的每个训练阶段的验证和训练损失以及验证AUC。在对测试数据进行验证和评估期间,该模型的最终结果见表8。
图5-每个epoch最终模型的演变。

从结果中可以看出,该模型很好地找到了数据集中问题之间的关系,从而完成了任务。将此结果与第2节中的PFA和BKT方法相比较,所提出的模型要好得多。同时,它在测试数据集上的AUC与相关工作中的DKT模型相似。
自由形式可视化
解决所选问题时需要考虑的一个非常重要的方面是问题技能id和标签的编码。如果特征不考虑标签,模型将很难找到问题与其期望标签之间的关系。我们做了一些实验来证明这一点,在图6中可以看到一个在没有这种编码的情况下训练的模型(模型a)和这个项目中提出的模型(模型B)之间的比较。
图6-在不编码技能id和标签的情况下训练的模型(a)与建议的模型(B)的比

完整项目:https://github.com/chrispiech/DeepKnowledgeTracing
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)