1 将存在更新部分字段信息,不存在则执行插入合并为一个SQL,需要创建唯一索引
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`password` varchar(255) DEFAULT NULL,
`createtime` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
-- 先select,然后update或insert
INSERT INTO user(name,password,createtime) VALUES('1','123',now()) ON DUPLICATE KEY UPDATE createtime=now()
如果存在,将会更新createtime字段的值卫当前时间,
返回值为1则说明执行了插入语句,返回值为2则说明执行了更新语句。
在一个特殊的场景中,需要对存在的值进行判断,然后选择性的去更新,如下demo
INSERT INTO user(name,password)
VALUES("123","111") ON DUPLICATE KEY UPDATE password=IF(VALUES(name)='123',"222","333")
如果存在的值为123,就将passwor的值更新为333,否则为222
2 将存在就删除,不存在就执行插入合并为一个SQL,同样需要创建唯一索引
表结构同上
-- 先DELETE重复的语句,然后执行插入新的记录即delete-》insert
REPLACE INTO user(name,password,createtime) VALUES('1','1',now())
返回值为1则说明执行了插入语句,返回值为2则说明执行了删除和插入语句,新的数据将覆盖之前的数据。
参考文章:https://www.cnblogs.com/Dong-Ge/p/6518071.html
2 with rollup
数据:
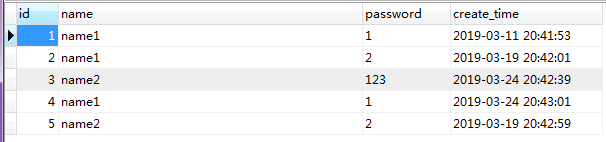
SELECT name,password,count(*) from user GROUP BY name,password with rollup
在统计分析的场景蛮有用。
查询重复字段id最小的那条记录,如查询user表中username字段重复的记录,取id最小的那一条。
思路,按username进行分组,取每组最小的记录,外面嵌套一个根据id查询即可。
SELECT
*
FROM
user
WHERE
id IN ( SELECT min( id ) FROM USER GROUP BY username HAVING count( * ) > 1 )
如果存在重复的记录,保留最小的记录,先分组,得到每组最小的记录id,然后删除即可。
DELETE
FROM t_call_detail
where id in (
SELECT ids.id
FROM (
SELECT min( id ) AS id FROM t_call_detail GROUP BY contact_id HAVING count(*) > 1
) AS ids )
JSON字段适合存储数据,不适合检索数据。
PerconaTookit 在线修改表。
即不删除数据,又能缩小表体积,可以把记录迁移到历史表中。
读少写多 采用NoSQL数据库,没有事务和约束,数据的写入速度很快。
读多写少 关系型数据
读多写多 数据库集群
排它锁 Mysql默认会给添加、修改和删除记录设置排它锁。
不用数据库的缓存
数据库不好管理,一股脑的缓存,然后更新一条记录,导致所有的缓存数据失效。
外部的缓存可以根据自己的实际情况做缓存。默认是关闭的。
mysql全文索引
中文分词切词结果太多,占用 大量存储空间。
更新字段内容,全文索引不会更新,必须定期手动维护。
在数据库集群中维护全文索引难度很大。
Sysbench安装
curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh |sudo bash
yum -y install sysbench
初始化测试表,需要提前安装sbtest库。
sysbench /usr/share/sysbench/tests/include/oltp_legacy/oltp.lua --mysql-host=192.168.209.101 --mysql-port=3306 --mysql-user=root --mysql-password=123123 --oltp-tables-count=10 --oltp-table-size=10000 prepare
执行测试,结果输出到sysbench-0914.log文件中
sysbench /usr/share/sysbench/tests/include/oltp_legacy/oltp.lua --mysql-host=192.168.209.101 --mysql-port=3306 --mysql-user=root --mysql-password=123123 --oltp-test-mode=complex --threads=10 --time=60 --report-interval=10 run >> ./sysbench-0914.log
MySQl为每个连接创建缓冲区,所以不应该盲目上调最大连接数。
3000连接大概消耗800M内存。一般设置得比较大一点,因为有缓存的存在。
max_connections
设置并发线程数,并发线程数应该设置为CPU核心数的两倍。默认为151,修改my.conf。
innodb_thread_concurrency=2
innodb缓存,缓存了热点索引数据,默认设置为128M
innodb_buffer_pool_size=设置为内存的70-80%