当我们开始学习编程的时候,第一件事往往是学习打印"Hello World"。就好比编程入门有Hello World,机器学习入门有MNIST。
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片:
它也包含每一张图片对应的标签,告诉我们这个是数字几。比如,上面这四张图片的标签分别是5,0,4,1。
MNIST数据集
MNIST数据集的官网是Yann LeCun's website。在这里,我们提供了一份python源代码用于自动下载和安装这个数据集。你可以下载这份代码,然后用下面的代码导入到你的项目里面,也可以直接复制粘贴到你的代码文件里面。
import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
下载下来的数据集被分成两部分:60000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)。这样的切分很重要,在机器学习模型设计时必须有一个单独的测试数据集不用于训练而是用来评估这个模型的性能,从而更加容易把设计的模型推广到其他数据集上(泛化)。
正如前面提到的一样,每一个MNIST数据单元有两部分组成:一张包含手写数字的图片和一个对应的标签。我们把这些图片设为“xs”,把这些标签设为“ys”。训练数据集和测试数据集都包含xs和ys,比如训练数据集的图片是 mnist.train.images ,训练数据集的标签是 mnist.train.labels。
当你安装了tensorflow后,tensorflow自带的教程演示了如何使用卷积神经网络来识别手写数字,tensorFlow会自己下载图片训练集。下面这两行代码
会自动创建一个
'MNIST_data'
的目录来存储数据。
import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)

这里,mnist是一个轻量级的类。它以Numpy数组的形式存储着训练、校验和测试数据集。同时提供了一个函数,用于在迭代中获得minibatch,后面我们将会用到。
这个是TensorFlow官方教程《深入MNIST》中的完整代码。完整教程在这里。
import tensorflow as tf
#导入input_data用于自动下载和安装MNIST数据集
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
#创建一个交互式Session
sess = tf.InteractiveSession()
#创建两个占位符,x为输入网络的图像,y_为输入网络的图像类别
x = tf.placeholder("float", shape=[None, 784])
y_ = tf.placeholder("float", shape=[None, 10])
#权重初始化函数
def weight_variable(shape):
#输出服从截尾正态分布的随机值
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
#偏置初始化函数
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
#创建卷积op
#x 是一个4维张量,shape为[batch,height,width,channels]
#卷积核移动步长为1。填充类型为SAME,可以不丢弃任何像素点
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1,1,1,1], padding="SAME")
#创建池化op
#采用最大池化,也就是取窗口中的最大值作为结果
#x 是一个4维张量,shape为[batch,height,width,channels]
#ksize表示pool窗口大小为2x2,也就是高2,宽2
#strides,表示在height和width维度上的步长都为2
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1],
strides=[1,2,2,1], padding="SAME")
#第1层,卷积层
#初始化W为[5,5,1,32]的张量,表示卷积核大小为5*5,第一层网络的输入和输出神经元个数分别为1和32
W_conv1 = weight_variable([5,5,1,32])
#初始化b为[32],即输出大小
b_conv1 = bias_variable([32])
#把输入x(二维张量,shape为[batch, 784])变成4d的x_image,x_image的shape应该是[batch,28,28,1]
#-1表示自动推测这个维度的size
x_image = tf.reshape(x, [-1,28,28,1])
#把x_image和权重进行卷积,加上偏置项,然后应用ReLU激活函数,最后进行max_pooling
#h_pool1的输出即为第一层网络输出,shape为[batch,14,14,1]
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
#第2层,卷积层
#卷积核大小依然是5*5,这层的输入和输出神经元个数为32和64
W_conv2 = weight_variable([5,5,32,64])
b_conv2 = weight_variable([64])
#h_pool2即为第二层网络输出,shape为[batch,7,7,1]
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#第3层, 全连接层
#这层是拥有1024个神经元的全连接层
#W的第1维size为7*7*64,7*7是h_pool2输出的size,64是第2层输出神经元个数
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
#计算前需要把第2层的输出reshape成[batch, 7*7*64]的张量
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
#Dropout层
#为了减少过拟合,在输出层前加入dropout
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
#输出层
#最后,添加一个softmax层
#可以理解为另一个全连接层,只不过输出时使用softmax将网络输出值转换成了概率
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
#预测值和真实值之间的交叉墒
cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv))
#train op, 使用ADAM优化器来做梯度下降。学习率为0.0001
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
#评估模型,tf.argmax能给出某个tensor对象在某一维上数据最大值的索引。
#因为标签是由0,1组成了one-hot vector,返回的索引就是数值为1的位置
correct_predict = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
#计算正确预测项的比例,因为tf.equal返回的是布尔值,
#使用tf.cast把布尔值转换成浮点数,然后用tf.reduce_mean求平均值
accuracy = tf.reduce_mean(tf.cast(correct_predict, "float"))
#初始化变量
sess.run(tf.initialize_all_variables())
#开始训练模型,循环20000次,每次随机从训练集中抓取50幅图像
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
#每100次输出一次日志
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_:batch[1], keep_prob:1.0})
print ("step %d, training accuracy %g" % (i, train_accuracy))
train_step.run(feed_dict={x:batch[0], y_:batch[1], keep_prob:0.5})
print ("test accuracy %g" % accuracy.eval(feed_dict={
x:mnist.test.images, y_:mnist.test.labels, keep_prob:1.0}))
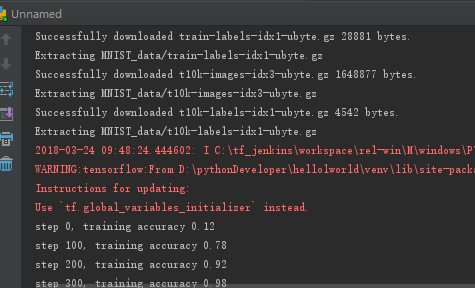
实验过程:
因为单机性能有限,所以程序运行时间比较长,我们发现,越到后面,准确率越高

参考地址:http://www.tensorfly.cn/tfdoc/tutorials/mnist_pros.html