1)什么是决策树?
顾名思义,决策树是以树形的结构方式来对事件做决定和分类。我们以来判断一个瓜是不是好瓜来举例子,如下:
决策树的结构一般包含一个根节点,若干个内部节点和若干个叶节点;根节点包含所有样本(各种各样的瓜)。内部节点是西瓜的属性(根茎叶是什么样子的),叶节点是结论(好瓜,坏瓜)。每条从根节点到叶节点的路径就代表一种属性判定路径。
2)划分依据
你可能要问,西瓜有那么多属性,我们到底先选择什么来作为第一个判定属性?我们怎么分类才能让该属性下的样本尽可能是“一伙儿”的。
(1)第一种划分依据
信息熵(info entropy)
信息熵是用来度量样本集合纯度最常用的指标,其公式如下:
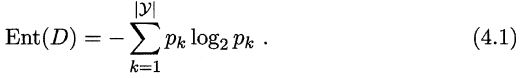
其中p是所分类的西瓜样本所占总样本的比例(k=1,2,3....y)。Ent(D)的值越小,则
D的纯度越高。
信息增益
假定离散属性a有V个可能取值{a1,a2,a3.....av },我们若用a来对样本集合D来进行划分,则会产生V个分支结点,其中第v个分支结点包含D中所有在属性a上取值为av的样本,记做Dv。则信息增益公式如下:
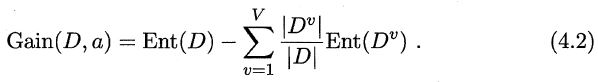
这里,我们将信息增益的大小作为划分结点的依据。如果节点的某属性信息增益最大,我们就以该属性来划分此结点。每个属性划分都只能用一次。
(
2)第二种划分依据
可能你已经发现了,由于权重的存在,信息增益准则对包含数目较多的属性有偏好。为了减少这种不“客观”的判定,我们选择”增益率“(C4.5)来划分属性。公式如下;
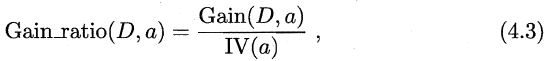
其中
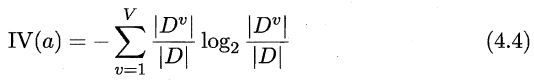
这里IV(a)称之为属性a的固有值。通常情况下,a越大,固有值越大。这样就减小了上面信息增益对包含数目多的属性的偏好。但是尴尬的是,似乎减少的太多了。增益率对包含数目较少的属性有偏好,这里Quinlan提出了一种方法:先找出信息增益高于平均水平的,然后再选出增益率最高的。
(3)第三种划分依据
基尼指数,公式如下:
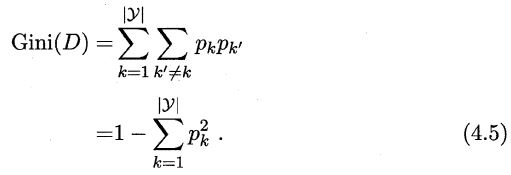
这里的基尼指数越小,则数据集D的纯度越高。同理,推广到属性a的基尼指数如下:
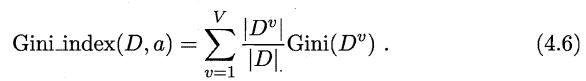
这里选择基尼指数最小的属性作为划分的依据。
3)建立一棵决策树(示例)
这里,我们来判断一棵西瓜的好坏。现在有17颗西瓜,其属性状况如下:
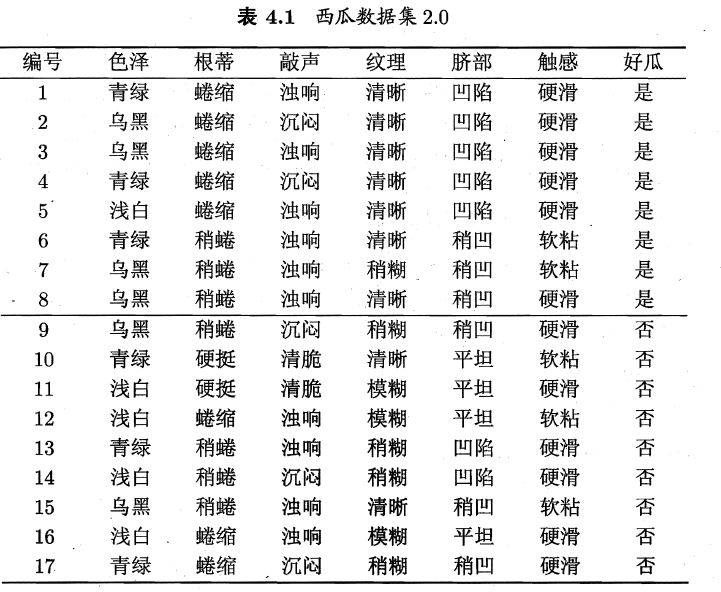
显然,根节点是这17个样本。好了,我们现在开始计算了。
(1)计算第一层内结点
首先,计算样本的信息熵。
很明显我们要分类的结果是好与坏两种类别,则|y|=2。那么其信息熵如下:
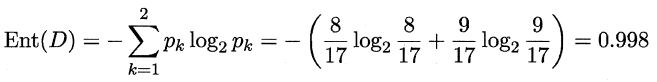
这里有8个好瓜,9个坏瓜。
接下来,我们要计算各个属性的信息增益,我们以色泽举例。色泽包含三种情况{青绿,乌黑,浅白}。其好瓜样本占属性样本比例分别是3/6,4/6,1/5。坏瓜样本占属性样本比例分别是3/6,2/6,4/5。则根据信息熵公式(4.1)得到:
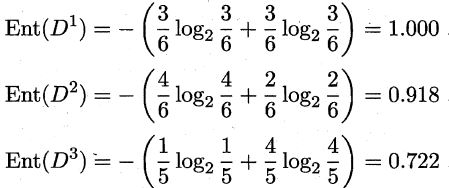
再根据公式(4.2)计算‘色泽’的信息增益得到:
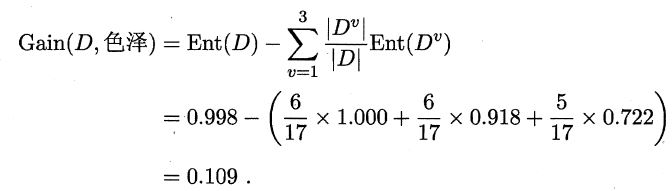
同理,我们计算得到其他属性的信息增益如下:

我们可以看到纹理的信息增益最大,为0.381。于是我们选择纹理作为我们的第一层属性结点。如下:
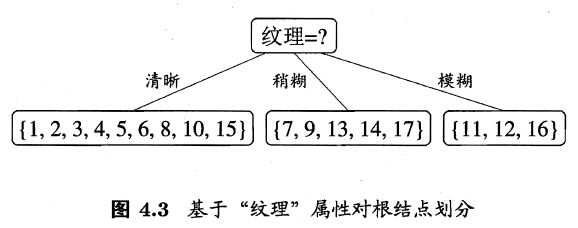
(2)第二层属性结点
我们已经在第一层属性结点中用过了“纹理”,所以本层就不可以再用了。首先,我们在由“纹理”划分出的“清晰”样本{1,2,3,4,5,6,8,10,15}中,计算各剩余属性的信息增益。我们这里以色泽举例,如下:
首先计算‘“清晰”样本的信息熵:
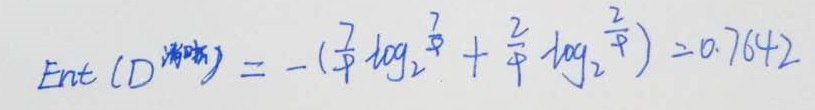
接下来计算各个属性的信息熵:

接下来,计算”色泽“在”清晰“样本中的信息增益:
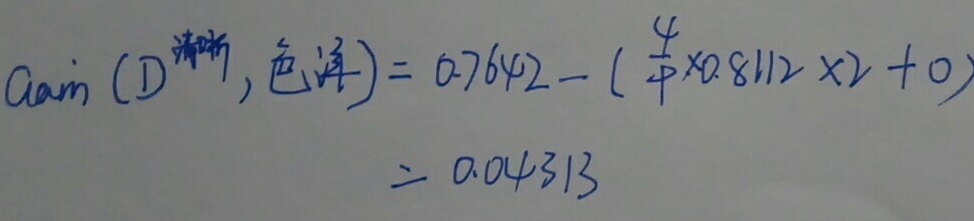
同理,我们计算其他属性在“清晰”样本下的信息增益。如下:

我们可以看到“脐部”,“根蒂”,”触感“三个属性的信息增益最大,所以本层,我们任选三个属性的一个来分类。我们这里选择“根蒂”,如下:
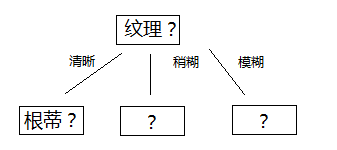
那么,剩下的两个二级样本稍糊和模糊呢?我们来看稍糊:
稍糊有样本{7,9,13,14,17}。我们对该样本求信息熵得到:

同理,计算各属性的信息熵,不再包括属性“根蒂”,。然后再计算信息增益,如下:
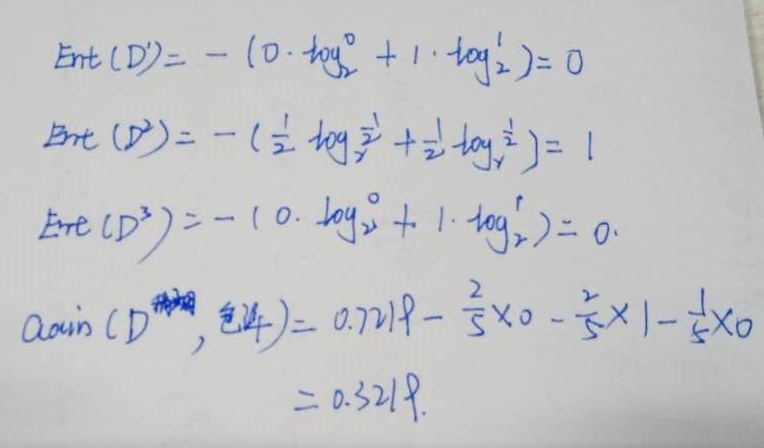
同理,计算得到其他的信息增益。得到触感是最适合的属性。如下:

至于模糊就简单了,因为”模糊“这类样本只有坏瓜,第二层决策树枝到此结束。
(3)第三层属性结点
这里我们先从第二层的第一类属性(根蒂)开始,将其分成三类样本。如下:
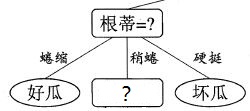
这里,我们很容易发现这里的蜷缩和硬挺都已经结束。这里,只需要对”稍蜷“样本进行分类。其样本有{6,8,15}。同理,我们需要计算信息熵,信息增益,还是首先以”色泽“来计算。如下:

2.计算剩余的熵:

3.计算增益:

计算剩余的信息增益,得到色泽是最大的增益。这里选择”色泽“做为我们第三层的属性划分。同理,我们对第四层,第五层做属性划分。得到最终的决策树:
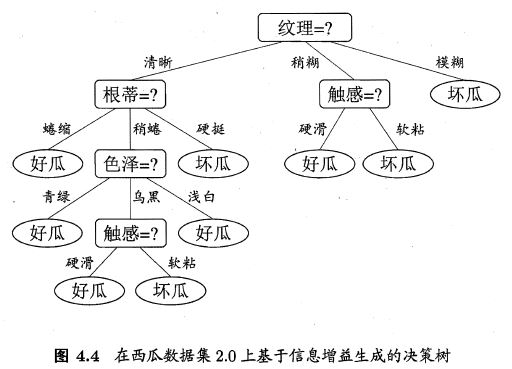
今天我们就到这里,剩下的剪枝处理,连续值和缺失值处理后面再讲。希望有志同道合的小伙伴关注我的公众平台,欢迎您的批评指正,共同交流进步。
