作者:猛码Memmat

Abstract

主要的序列转导模型是基于复杂的循环或卷积神经网络,包括一个编码器和一个解码器。表现最好的模型还通过注意机制连接编码器和解码器。我们提出了一个新的简单的网络架构,Transformer,完全基于注意力机制,完全摒弃递归和卷积。在两个机器翻译任务上的实验表明,这些模型在质量上更优越,同时更具并行性,并且需要更少的训练时间。我们的模型在WMT 2014英语-德语翻译任务上实现了28.4 BLEU,比现有的最佳结果(包括集合)提高了2个BLEU以上。在WMT 2014英法翻译任务中,我们的模型在8个gpu上训练3.5天后,建立了一个新的单模型最先进的BLEU分数41.8,这是文献中最佳模型训练成本的一小部分。我们通过将Transformer成功地应用于具有大量和有限训练数据的英语选区解析,证明了它可以很好地推广到其他任务。
1 Introduction


neural networks, long short-term memory [13] and gated recurrent [7] neural networks
我们提出了Transformer,这是一种模型架构,避免了递归,而是完全依靠注意力机制来绘制输入和输出之间的全局依赖关系。Transformer 允许更多的并行化,并且在八个 P100 GPU 上训练多达 12 小时后,可以在翻译质量方面达到新的技术水平。
2 Background

grows in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet.
In the Transformer this is reduced to a constant number of operations
在Transformer中,这被减少为一个常数数量的操作,尽管代价是由于平均注意力加权位置而降低了有效分辨率,我们用Multi-Head Attention抵消了这一影响,如3.2节所述。
Self-attention, sometimes called intra-attention
the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequencealigned RNNs or convolution.
然而,据我们所知,Transformer是第一个完全依靠自我注意来计算输入和输出表示的转导模型,而不使用序列对齐的rnn或卷积。在接下来的章节中,我们将描述Transformer,激发自我关注,并讨论它相对于[17,18]和[9]等模型的优势。
3 Model Architecture

At each step the model is auto-regressive [10], consuming the previously generated symbols as additional input when generating the next.
在每一步中,模型都是自动回归[10],在生成下一步时,将先前生成的符号作为额外的输入。
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
Transformer遵循这种总体架构,为编码器和解码器使用了堆叠的自关注层和按点完全连接层,分别如图1的左右两部分所示。
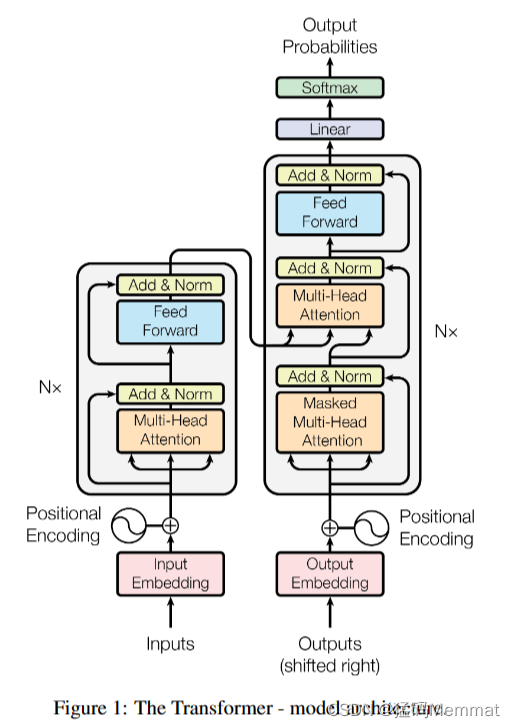
3.1 Encoder and Decoder Stacks

编码器由N = 6个相同层的堆栈组成。每一层有两个子层。第一个是一个多头自注意机制,第二个是一个简单的、按位置完全连接的前馈网络。我们在两个子层的每一层周围都使用了一个残余连接[11],然后是层规范化[1]。也就是说,每个子层的输出是LayerNorm(x + Sublayer(x)),其中Sublayer(x)是子层本身实现的函数。为了方便这些残余连接,模型中的所有子层以及嵌入层都会产生维度为 d m o d e l = 512 d_{model} = 512 dmodel=512的输出。
解码器也由N = 6个相同层的堆栈组成。除了每个编码器层中的两个子层外,解码器还插入第三个子层,该子层对编码器堆栈的输出执行多头注意。与编码器类似,我们在每个子层周围使用剩余连接,然后进行层归一化。我们还修改了解码器堆栈中的自关注子层,以防止位置关注后续位置。这种掩蔽,结合输出嵌入被一个位置抵消的事实,确保对位置i的预测只能依赖于小于i位置的已知输出。
3.2 Attention