《汇编程序设计与计算机体系结构: 软件工程师教程》这本书是由Brain R.Hall和Kevin J.Slonka著,由爱飞翔译。中文版是2019年出版的。个人感觉这本书真不错,书中介绍了三种汇编器GAS、NASM、MASM异同,全部示例代码都放在了GitHub上,包括x86和x86_64,并且给出了较多的网络参考资料链接。这里只摘记了NASM和MASM,测试代码仅支持Windows和Linux的x86_64。
这里是基于之前所有笔记的简单总结,笔记列表如下:
处理器、寄存器简介:https://blog.csdn.net/fengbingchun/article/details/108164694
汇编语法基础知识:https://blog.csdn.net/fengbingchun/article/details/108165957
指令:https://blog.csdn.net/fengbingchun/article/details/108203513
函数、字符串、浮点运算:https://blog.csdn.net/fengbingchun/article/details/108419088
内联汇编与宏:https://blog.csdn.net/fengbingchun/article/details/108421641
其它架构:https://blog.csdn.net/fengbingchun/article/details/108546018
1. 处理器、寄存器简介:
指令集架构(Instruction Set Architecture, ISA)是计算机体系结构中与编程有关的方面。它指出了处理器所具备的指令、寄存器、内存架构、数据类型以及其它一些属性,以供程序员使用。指令集架构分为复杂与精简两种。复杂指令集(Complex Instruction Set Computing, CISC)架构中的指令,其长度(也就是表示该指令所需的字节数)不固定。之所以说它复杂,是因为一条指令有可能要完成多项任务。与之相对的ISA设计称为精简指令集(Reduced Instruction Set Computing, RISC),其中的所有指令都一样长,而且只执行一项任务。x86与x86_64都是CISC架构,而其它一些ISA设计方案则多为RISC架构。
反汇编是由反汇编器对包含机器语言的目标文件进行解码之后所输出的汇编代码,这实际上相当于把机器语言的二进制序列解码成汇编指令。大多数汇编器、编译器、调试器以及开发环境都提供反汇编功能,例如NASM、GDB、LLVM、Xcode以及Visual Studio。
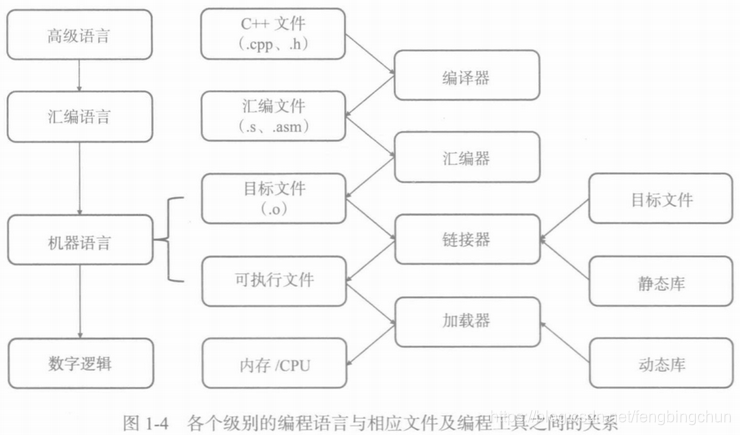
编程语言与相应文件及编程工具之间的关系,如下图所示:
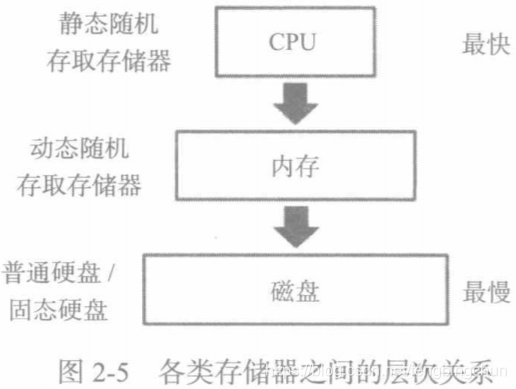
计算机必须拥有存储器(memory)。下图描述了各类存储器之间的层次关系:离CPU最近的存储器是静态随机存取存储器(Static Random Access Memory),简称SRAM。它实际上就在CPU芯片中。这种存储器通常称为缓存(cache)。SRAM是速度最快的存储器类型。比它稍慢一些的是动态随机存取存储器(Dynamic RAM),简称DRAM。主板上有一些靠近CPU的槽位,其中插着的内存条就属于这种类型的存储器。大家通常所说的主存(main memory)一般指的就是DRAM,也可以简称RAM。还有一种存储器比DRAM还慢,这就是机械硬盘或固态硬盘等磁盘(disk),主要相当于我们常说的硬盘。这种存储器用来长期保存数据,而不像缓存或RAM只用来暂时保存。
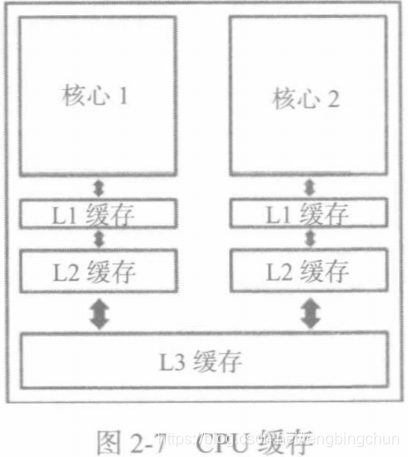
紧邻CPU的存储器就叫做cache(高速缓存,简称缓存),实际上,它跟逻辑电路一起位于CPU芯片中。当前的处理器缓存通常分为三个级别,分别是L1缓存(一级缓存)、L2缓存(二级缓存)与L3缓存(三级缓存)。缓存本身的层次结构与存储器的层次结构都遵循同一条原则:距离ALU越远容量越大。L1与L2缓存都离ALU很近,不过L2要比L1稍远一些,因此其容量也大一些。L3缓存一般出现在多核处理器中,它为所有CPU核心所共享,而L1与L2缓存则每个CPU核心都配有一套,如下图所示:L3缓存是静态存储器中的最后一层,如果数据不保存在该层及其上方的各层中,那就只好放到它下方的RAM中了。CPU提供了一些与缓存有关的指令,然而开发者一般都不用专门编写代码去访问或操作缓存,因为缓存是由复杂的算法来控制的,以确保程序所需的数据能够尽量出现在缓存中,所以开发者通常不需要干预这套机制。
除了缓存之外,CPU中还有一种存储器叫做寄存器(register),它的内容可以通过明确的地址来访问,而且在此类存储器中它是最快的一种。它位于整个存储器层级的最顶端,其容量比缓存更小,速度也比缓存更快。寄存器是最贴近ALU的一小块存储区域,用来保存执行指令时所涉及的操作数、地址及结果。处理器的每个核心都有自己的一套L1与L2缓存,与之类似,每个核心也都有自己的一套寄存器。然而,编写汇编代码的时候你不用指出当前操作的寄存器究竟处在哪个核心上,你只需要写成寄存器的名字就可以了,至于这个寄存器到底指的是哪个核心上的寄存器则由CPU决定。
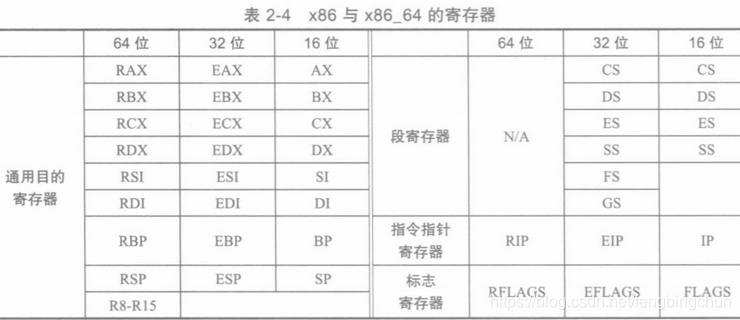
寄存器可以分成4类,通用目的寄存器(General Purpose Register)、段寄存器(Segment Register)、标志寄存器(Flags Register)及指令指针寄存器(Instruction Pointer Register)。汇编程序所操作的基本上都是通用目的寄存器,其中,32位的通用寄存器有8个,64位的有16个。通用寄存器用来执行计算或移动数据。由于64位处理器是在32位设计方案的基础上构建的,而32位处理器又是在16位设计方案的基础上构建的,因此新式处理器不仅可以通过寄存器本身的名字来使用该寄存器,而且还能通过旧式处理器所用的名字将其当成旧式的寄存器来使用。此外,如果你要使用的数据或是你要执行的运算只需占据8个二进制位,那么可以把16位的寄存器想象成两个8位的寄存器,这样就可以用它来保存两份数据了。凡是以小寄存器的名义来操作大寄存器的,其实操作的都是大寄存器中与这个小寄存器相对应的那一部分二进制位。下表列出了寄存器名称:尽管rflags是64位,但其中能够用到的只有低32位,因此,x86与x86_64处理器用的是同一套状态标志。
x86_64指令集是对x86指令集(这是一种32位指令集)的扩充,因此能够在32位环境下执行的操作,同样可以放在64位的处理器中执行。由于x86_64处理器是64位的,因此其数据与地址都可以用64个二进制位来表示,然而,当前的x86_64处理器只用到了其中的低48位,所以说,尽管理论上能够在2^64字节的地址空间中寻址,但实际上最多只支持2^48字节的地址空间。用48个二进制位来表示物理地址空间中的地址意味着RAM(内存)容量可达256TB,这比32位处理器所支持的4GB要高出很多。
程序是由一个叫做程序加载器的工具来加载的。加载进来之后,CPU(主要是说它的eip/rip寄存器)指向程序的入口点,这个入口点可能叫做main或start等。下面描述启动程序的一般步骤。当用户开启程序(例如用鼠标双击程序的图标)时:
(1). 操作系统把文件的大小以及该文件在磁盘中的物理位置等信息获取出来。
(2). 操作系统在内存中寻找合适的地点分配空间,并把必要的信息放在描述符表(descriptor table)中。
(3). 操作系统开始执行程序的第一条指令(也就是位于入口点的那条指令)。这时程序变为进程,并获得由系统所赋予的ID。
(4). 该进程自行运作,而操作系统则会对进程所发出的资源请求予以响应。
(5). 进程结束并让出它所占据的内存。
2. 汇编语法基础知识:
汇编代码的五大支柱:保留字(reserved word)、标识符(identifier)、命令(directive, 也称为指示或伪操作)、区段(section或segment, 简称段)以及指令(instruction)。
(1). 保留字:是一种具备特定用途的字词。例如MOV就是个保留字,它代表一条特定的指令,即MOV指令。你不能把它当成变量名来用,也不能做其它用途。汇编语言的保留字不区分大小写。指令(例如MOV)、命令(例如PROC)、寄存器(例如eax)、属性(例如可以当作.MODEL命令参数值的FLAT)等,都是保留字。
(2). 标识符:是由程序员所定义的名称,用来表示变量、常量及过程等事物,它最多可以包含247个字符。第一个字符不能是数字,且必须从英文字母(大写的A至Z及小写的a至z)、下划线(_)、问号(?)、at符号(@)及美元符号($)这五种中选择,其后的字符则可以使用数字。
(3). 命令:是与指令集无关的一些操作,可以指挥汇编器去做某件事,例如定义变量、指明内存段等。如用MASM汇编器撰写32位程序时专用的命令:.386、.MODEL、.STACK。
(4). 程序段(program section或program segment):是用相关命令所标出的特殊段落。汇编器预先定义了几种这样的段落。如MASM中的.data、.code;NASM中的section .bss、section .data、section .text。
(5). 指令:是程序中的可执行语句。指令由两个基本部分组成,其语法如下:”mnemonic [operands]”,其中mnemonic(助记符)是指令的名称,开发者用它来指代某个架构所支持的一套指令集里的一条指令。助记符通常是个缩写形式或首字母缩略形式的词,实际上也可以认为是数字形式的操作码所对应的英语写法。有些指令不需要操作数,有些则需要一个、两个或三个操作数。
如果某个十六进制数(例如内存地址)是以英文字符开头的,那么汇编器就会把它当成标识符看待,为了令其能够正确地将该值解读为字面量,你应该在前面添一个0。
MASM与NASM中的字符字面量可以用一对单引号括起来,也可以用一对双引号括起来,这两种写法是等效的。字符在存储器中是以整数形式的ASCII编码来表示的。
MASM与NASM的字符串与单个字符类似,也可以用一对单引号或双引号括起来。如果字符串的内容本身就有引号,那么对于MASM及NASM来说,你必须用另外一种引号把这个字符串括起来。字符串通常保存成字节数组,其中的每个字节都与字符串中处在该位置上的字符相对应,字节的内容就是字符的ASCII码。
NASM的标签用在.text段里的标签区分大小写,MASM的标签写在.code段里则不区分大小写。
MASM及NASM的单行注释以分号(;)开头。注释可以单独占据一行也可以写在某行代码的后面。
汇编语言的数据类型根据数据的大小来确定(例如8位、16位、32位)。无论采用哪种汇编器,.data段里定义的变量都必须予以初始化,也就是必须具备初始值。
NASM要求.data段里的变量必须用明确的值来初始化,而MASM则允许开发者在该段中采用问号(?)充当变量的初始化器来定义未初始化的变量。NASM要求未初始化的变量必须创建在.bss段中(bss的意思是Block Started by Symbol,以符号开始的块),而且要用特定的命令来创建。MASM的初始化器可以用DUP括起来,以便反复创建大小与内容均相同的多个值。
字符串是以BYTE(字节)数组的方式存储的。字符串必须以null结尾,也就是说,其最后一个字节必须是值为0的ASCII码。不同的汇编器采用不同的方式来定义这种字符串。MASM与NASM则是直接用字面量0来设置最后一个字节。一个涉及字符串的重要问题是换行。不同的汇编器采用不同的方式换行。MASM用十六进制码0Dh与0Ah来表示CR/LF这两个符号并以此实现换行(CR的意思是carriage-return, 回车)。NASM则只用0Ah这一个十六进制码(也就是LF)表示换行。
符号常量(symbolic constant)可以在MASM版本的汇编代码里取代某些变量,用以表示程序执行期间绝对不会变化的值。你可以用等号(=)定义这样的常量。MASM里的符号常量不占内存,因为MASM在对代码作汇编的时候,会把所有出现符号常量的地方都改成该常量所对应的实际值。采用等号来定义符号常量的写法只适用于MASM汇编器。此外,MASM的符号常量还可以用来表示字符串值。
所有的汇编器都可以把表达式的值表示成符号常量。符号必须用EQU命令来定义。与定义变量时的要求不同,用EQU所创建的符号既可以出现在数据段也可以出现在代码段(对于MASM汇编器,它可以出现在.data与.code段,对于NASM汇编器,它可以出现在SECTION .data与SECTION .text段)。这些汇编器在对代码作汇编的时候会把每一个出现这种符号的地方都替换成对应的表达式。EQU命令还有一个用途,是通过创建符号常量来表示某个标识符所指代的数据占用了多大的内存空间。
3. 指令:
在撰写指令的目标操作数时,如果要对变量解引用(dereference),NASM要求你必须指出大小,也就是必须在变量名的前面写上一个表示尺寸的命令,例如用BYTE表示字节、WORD表示字等,比方说像这样:”mov DWORD [test], eax”
MOV指令有几条具体的要求:
(1). 两个操作数的大小必须相同;
(2). 两个操作数不能全是内存操作数(也就是说要想在两个内存操作数之间移动数据,必须用寄存器做中介);
(3). 指令指针寄存器(ip/eip/rip)不能用作目标操作数。
NASM对待变量的方式有点像C++对待指针的方式:如果直接写出变量名本身,那么它会将其视为内存地址。要想引用该地址中的内容(也就是由变量名所指代的那份数据),必须用一对方括号给变量解引用,如:”INC DWORD [sum]”
MUL指令用来给无符号的整数执行乘法。带符号的整数相乘要通过IMUL指令执行。
与MUL类似,除法也分为无符号与带符号两种。DIV指令用来执行无符号整数的除法运算。带符号的整数需要用IDIV指令来相除。
SHL和SHR是逻辑移位(logical bit shift),这会令某些二进制位出现在存储范围之外,同时会令空出来的那些数位都填上0.无符号的数据通常是可以做逻辑移位的。如果想通过左移位或右移位的方式给带符号的整数做乘除法,必须使用算术移位(arithmetic bit shift)指令以便保留其符号位。SAL(Shift Arithmetic Left)是算术左移,SAR(Shift Arithmetic Right)是算术右移。
CPU访问存放在偶数地址上的数据要比访问存放在奇数地址上的数据更快。每种汇编器都有1条或多条命令用来修改位置计数器。MASM用的是ALIGN命令,NASM则依据不同的程序段分别使用ALIGN或ALIGNB命令。这几种命令的参数都必须是整数,而且应该是2的幂。这些命令会推进位置计数器,直到它的值变为该整数的倍数为止。这可以用来确保数据出现在偶数的内存地址上。
直接寻址(direct addressing)是直接访问某个值,而间接寻址(indirect addressing)则是通过值所代表的内存地址来访问另一个值。NASM的变量表示的就是其内存地址,而不是该地址中的值(如果想使用这个值,要用方括号括起来)。在MASM代码中,操作数的地址可以结合MOV指令及OFFSET命令来获取。LEA(Load Effective Address, 加载有效地址)指令在32位与64位模式之下都可以把操作数的地址加载到目标中。
汇编语言里的数组也是由类型相同的一系列数据构成的,这些数据在内存中以相等的间隔存放。数组的名称实际上指的是该数组中的首个元素。访问数组元素时,一定要正确算出该元素距离数组开头有多少个字节。汇编器不会自动检查你所做的访问是否与元素之间的边界相合。
我们在将数值复制到大寄存器的低半区时,应该使用MOVZ/MOVZX(ZX表示Zero eXtend,用0来扩展)与MOVS/MOVSX(SX表示Sign eXtend, 用符合位来扩展)两种指令,因为它们能够在复制的同时,用0位或符合位来填充高半区里的每一个二进制位。
XOR运算是可逆的(reversible),因此成为很多对称加密(symmetric encryption)算法与数据存储算法中的重要环节。将原值与另一个值(此值称作键,key)连取两次XOR,就可以令运算结果回到原值。
4. 函数、字符串、浮点运算:
栈内存(stack memory)是为自动变量而设的一块区域(这里的自动变量是指局部变量,或者说非动态的变量)。调用函数的时候,需要用栈来保存函数中的局部变量,而函数结束的时候,则需要弃用这些变量。
x86_64的函数都必须按16字节对齐(所有平台都是这样)。
64位环境下通常使用寄存器(而不是栈)来传递参数。
stdcall的RET指令与cdecl稍有不同,它必须指出栈中有多少个字节的内容需要移除。
64位模式下的函数必须按16字节对齐。SSE的操作一般都是128位的,SSE操作必须按16字节对齐。为了确保使用SSE指令的函数不会出现栈对齐错误,所有的栈帧都应该向16字节处对齐。此外,由于CALL指令默认会把8个字节的地址推入栈中,因此,在很多情况下,我们都需要再向栈中推入8字节,从而实现16字节对齐。
在Windows系统中编写代码时,应该用PROC与ENDP命令指出例程的起点与终点。
方向标志决定了内存地址在执行字符串指令的过程中是应该自动递增还是自动递减,这实际上也就决定了字符串的处理顺序是从左至右还是从右至左。CLD与STD指令最适合用在重复操作之前,以便将方向标志调整好。
计算机中的浮点值(floating-point value)是一种用来近似表示实数的数据形式,这种值的小数点前后通常都有一些数位。浮点数由有效数(significand)、基数与指数三部分组成,其中的有效数部分可以容纳固定个数的有效数位,而基数则用来与指数相配合,以便对有效数放大或缩小。
NaN是一种用来表示未定义值或假想值的数据。
FPU的8个数据寄存器(R0至R7)形成循环栈,其中任何一个寄存器都有可能充当栈顶。如果向R0推入一个值,那么下一个值就会推入R7中。从栈中删除元素时也会出现这样的循环现象,只不过方向与推入元素时相反。为了利用这种特性,开发者并不直接以R0至R7这样的名称来指代寄存器,而是以ST0至ST7等写法来指代它们,哪个R寄存器充当栈顶就把哪个R寄存器叫做ST0.这个R寄存器在整个R系列中的序号保存在FPU状态寄存器的TOP字段中。
凡是提到压缩形式的数据,就意味着这些数据能够在程序运行过程中并行地得到处理。
5. 内联汇编与宏:
内联汇编是一种在高级语言中嵌入汇编代码的办法。还有一种办法也能把汇编语言的代码同高级语言的代码结合起来,就是用汇编代码来撰写函数,并将其放在一份文件中,然后在C++代码中调用这些函数。
各种编译器会采用不同的做法来处理内联式的汇编代码。如果高级语言的代码所内嵌的汇编代码在编译过程中没有受到修改或优化,那么GCC实际上就相当于把这一部分汇编代码复制到它所输出的汇编文件中(这种文件的后缀名是.s),进而把这些代码与从高级语言转换而来的那些汇编代码一起交给GNU汇编器(GNU Assembler, 也就是GAS)处理。Microsoft的Visual Studio采用Visual C++内置的汇编器处理内联汇编语句,而不会专门采用MASM那样单独的汇编器来做。Microsoft的x64 C/C++编译器不支持内联式的汇编代码,它改用编译器内部函数来完成相应的底层指令。
C++编译器通常用asm或__asm关键字表示内联式的汇编语句。Clang/GCC汇编器要求asm关键字后面必须写一对圆括号及一个分号,而汇编代码则要以字符串的形式写在一对双引号中,并放置在这对圆括号中。换行符与制表符用来分割字符串中的各条汇编语句。Visual C++要求__asm关键字的后面要么直接写汇编语句,要么跟上一对花括号。如果汇编语句只有一条可以直接写出来,若有很多条则需放在花括号中。最后的分号可有可无。
内联汇编中的注释既可以按汇编代码自身的格式来写也可以按C++的格式来写,建议采用后一种写法。
根据AT&T汇编语法,寄存器以一个%符号开头。不过,内联式的汇编代码中寄存器需要用两个%符号开头,也就是要在前面加上%%,若只加一个%,表示的则是这段内联代码所用的参数(或变量)。之所以要这样写,是因为内联代码会把%当作转义符使用,以便输出它后面的符号所表示的字符,因此,”%%”输出的是单个%字符,而”%=”则会针对代码库中的每一段asm代码输出一个独特的数字(这个数字可以用来创建标签,以供其它代码引用)。此外,”%{”、”%|”及”%}”这三种写法分别用来输出{、|及}字符。
Clang与GCC默认使用AT&T语法规则,而Visual C++则使用Intel语法规则。不过,Clang与GCC能够在内联的汇编代码中使用多种汇编方言。由AT&T语法切换到Intel语法能够使代码变得好懂一些。要想采用某种特定的语法来撰写内联汇编代码,一种简单的办法是在第一条命令中写上.att_syntax以表示这段代码用的是AT&T语法,或者写上.intel_syntax以表示这段代码用的是Intel语法。Clang与GCC可以通过-masm这个编译选项来指定内联汇编代码所采用的方言。-masm=att与-masm=intel分别表示AT&T语法及Intel语法。
宏与函数有一个共同点,就是都可以接受参数(argument或parameter),不过函数的参数是在运行程序的时候才传递过去的,而宏的参数则是在做汇编的时候就已经替换好了。
6. 其它架构:
段寄存器(segment register)是一种16位宽的寄存器,代码段(code segment)、数据段(data segment)、栈段(stack segment)以及附加段(extra segment)都有对应的段寄存器,分别称为cs、ds、ss、es,此外,还有两个通用的段寄存器叫做fs与gs,这两者是由Intel 80386所添加的。
计算机系统所用的内存模型要根据可以使用的处理器模式以及操作系统的支持情况来决定。常见的两种模型叫做分段(segmented)模型及平面(flat)模型。分段内存模型会把地址空间分成不同的区段或者说段落,以供程序中的各个部分使用,例如数据可以放在一个区段中,代码可以放在另一个区段中。这种模型通过段基址加偏移量的方式来指定内存地址。平面内存模型会把整个内存空间展示成一块连续的区域以供开发者及程序来使用,这种模型也叫做线性(linear)模型。所有的内存地址都是直接以它在线性空间中的位置来确定的,而不通过段与段中的偏移量确定。这两种模型的目标都是把逻辑地址(也就是抽象的引用)映射成物理地址(也就是实际的位置)。对于x86来说,16位系统使用分段内存模型,实模式下的32位系统也是如此。保护模式下实际使用的同样是分段模型,但看起来却跟平面模型一样。x86_64使用平面内存模型。
中断(interrupt)是针对处理器而发的信号,用来表示某种必须立刻予以关注的情况。它可以分为硬件中断与软件中断两大类。软件中断(software interrupt, 软中断)的一种形式是应用程序主动给处理器发信号,可以通过很多办法来实现,例如可以用INT指令明确地产生软件中断。还有一种形式叫做异常(exception)或陷阱(trap),这表示处理器在执行指令的过程中遇到了某种状况,而当前正在运行的应用程序却没有处理或不能处理该状况。硬件中断(hardware interrupt):也会给处理器发信号,但这个信号并不是由软件发出的,而是由某个与系统相通信的设备通过中断请求线(interrupt request line, IRQ line)所发。
精简指令集不一定意味着指令的数量少,而复杂指令集也不一定意味着指令的数量多。RISC系统倾向于减少专门针对某种数据类型的指令。CISC系统通常会用专门的指令来支持字符串等更为复杂的数据类型。
x86架构的处理器有保护模式与长模式之分,与之类似,ARM处理器也可以运行在各种模式下。其中用户模式主要给非特权的处理任务使用,此外还有10种特权模式用来执行中断及异常等任务。
ARM处理器支持哪些寄存器,要看它的核心是32位还是64位,此外还要看是否支持Thumb指令集(一种采用16位编码的ARM指令集)以及它使用的是哪种VFP(Vector Floating-Point unit, 向量浮点运算单元)。
Windows上使用VS编译执行单个MASM汇编文件操作步骤:
(1). 创建一个Win32控制台应用程序AssemblyLanguage_Test;
(2). 右键单击该项目-->生成依赖项-->生成自定义:勾选masm复选框,点击确定;
(3). 添加一个新建文件funset.asm;
(4). 右击funset.asm-->属性:常规:项类型调整为:Microsoft Macro Assembler;
(5). 右键单击该项目-->属性:链接器:系统:子系统:调整为:窗口 (/SUBSYSTEM:WINDOWS);链接器:高级:入口点:填写为_main;
(6). 向funset.asm编写汇编代码。
可以在适当的位置设置断点,F5运行程序,打开寄存器、内存、反汇编、监视等窗口查看相关内容;可以在寄存器窗口中单击鼠标右键,选择”标志”查看标志寄存器的值。
Ubuntu上编译执行单个NASM汇编文件操作步骤:
(1). 新建文件funset.asm;
(2). 脚本文件build.sh内容如下:
#! /bin/bash
nasm -f elf64 -o funset.o funset.asm
ld -e _main -melf_x86_64 -o funset funset.o
可以通过gdb查看寄存器、变量等相关值。
Windows下链接汇编代码及C++代码操作步骤(x64):
(1).创建一个Win32控制台应用程序AssemblyLanguage_Test,并将其调整为x64;
(2).添加几个新文件,AssemblyLanguage_Test.cpp里面主要包含main函数;funset.asm里面包含了一些汇编代码;
(3).通过ml64.exe对funset.asm做汇编,产生目标文件funset.obj:
A.在C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\bin\amd64目录下启动cmd.exe;
B.运行vcvars64.bat或者直接将vcvars64.bat直接拖到cmd中;
C.定位到E:\GitCode\CUDA_Test\demo\AssemblyLanguage_Test\masm,执行:$ ml64.exe /c /Cx funset.asm,将会生成funset.obj;
(4).将funset.obj添加到工程中;
(5).生成并运行程序。
如果修改了funset.asm,那么必须通过ml64.exe重新生成funset.obj。
Ubuntu下链接汇编代码及C++代码操作步骤(x64):
(1).添加几个新文件,AssemblyLanguage_Test.cpp里面主要包含main函数;funset.asm里面包含了一些汇编代码;
(2).build.sh内容如下:
#! /bin/bash
real_path=$(realpath $0)
echo "real_path: ${real_path}"
dir_name=`dirname "${real_path}"`
echo "dir_name: ${dir_name}"
new_dir_name=${dir_name}/build
if [[ -d ${new_dir_name} ]]; then
echo "directory already exists: ${new_dir_name}"
else
echo "directory does not exist: ${new_dir_name}, need to create"
mkdir -p ${new_dir_name}
fi
rc=$?
if [[ ${rc} != 0 ]]; then
echo "########## Error: some of thess commands have errors above, please check"
exit ${rc}
fi
cd ${new_dir_name}
cmake ..
make
cd -
(3).CMakeLists.txt内容如下:
PROJECT(AssemblyLanguage_Test)
CMAKE_MINIMUM_REQUIRED(VERSION 3.0)
# support C++11
SET(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -std=c11")
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11")
# support C++14, when gcc version > 5.1, use -std=c++14 instead of c++1y
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++1y")
IF(NOT CMAKE_BUILD_TYPE)
SET(CMAKE_BUILD_TYPE "Release")
SET(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -Wall -O2")
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -O2")
ELSE()
SET(CMAKE_BUILD_TYPE "Debug")
SET(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -g -Wall -O2")
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -g -Wall -O2")
ENDIF()
MESSAGE(STATUS "cmake build type: ${CMAKE_BUILD_TYPE}")
MESSAGE(STATUS "cmake current source dir: ${CMAKE_CURRENT_SOURCE_DIR}")
SET(PATH_TEST_CPP_FILES ${CMAKE_CURRENT_SOURCE_DIR}/./../../demo/AssemblyLanguage_Test)
SET(PATH_TEST_NASM_FILES ${CMAKE_CURRENT_SOURCE_DIR}/./../../demo/AssemblyLanguage_Test/nasm)
MESSAGE(STATUS "path test files: ${PATH_TEST_CPP_FILES} ${PATH_TEST_NASM_FILES}")
# head file search path
INCLUDE_DIRECTORIES(${PATH_TEST_CPP_FILES})
FILE(GLOB TEST_CPP_LIST ${PATH_TEST_CPP_FILES}/*.cpp)
FILE(GLOB TEST_CPP2_LIST ${PATH_TEST_CPP_FILES}/nasm/*.cpp)
MESSAGE(STATUS "test cpp list: ${TEST_CPP_LIST} ${TEST_CPP2_LIST}")
FILE(GLOB_RECURSE TEST_NASM_LIST ${PATH_TEST_NASM_FILES}/*.asm)
MESSAGE(STATUS "test nasm list: ${TEST_NASM_LIST}")
# build nasm
SET(CMAKE_ASM_NASM_FLAGS_DEBUG_INIT "-g")
SET(CMAKE_ASM_NASM_FLAGS_RELWITHDEBINFO_INIT "-g")
IF(NOT DEFINED CMAKE_ASM_NASM_COMPILER AND DEFINED ENV{ASM_NASM})
SET(CMAKE_ASM_NASM_COMPILER $ENV{ASM_NASM})
ENDIF()
ENABLE_LANGUAGE(ASM_NASM)
MESSAGE(STATUS "CMAKE_ASM_NASM_COMPILER = ${CMAKE_ASM_NASM_COMPILER}")
IF(CMAKE_ASM_NASM_OBJECT_FORMAT MATCHES "elf*")
SET(CMAKE_ASM_NASM_FLAGS "${CMAKE_ASM_NASM_FLAGS} -DELF")
SET(CMAKE_ASM_NASM_DEBUG_FORMAT "dwarf2")
ENDIF()
SET(CMAKE_ASM_NASM_FLAGS "${CMAKE_ASM_NASM_FLAGS} -D__x86_64__")
MESSAGE(STATUS "CMAKE_ASM_NASM_OBJECT_FORMAT = ${CMAKE_ASM_NASM_OBJECT_FORMAT}")
IF(NOT CMAKE_ASM_NASM_OBJECT_FORMAT)
MESSAGE(FATAL_ERROR "could not determine NASM object format")
return()
ENDIF()
get_filename_component(CMAKE_ASM_NASM_COMPILER_TYPE "${CMAKE_ASM_NASM_COMPILER}" NAME_WE)
MESSAGE(STATUS "CMAKE_ASM_NASM_COMPILER_TYPE = ${CMAKE_ASM_NASM_COMPILER_TYPE}")
IF(NOT WIN32 AND (CMAKE_POSITION_INDEPENDENT_CODE OR ENABLE_SHARED))
SET(CMAKE_ASM_NASM_FLAGS "${CMAKE_ASM_NASM_FLAGS} -DPIC")
ENDIF()
ADD_LIBRARY(simd OBJECT ${TEST_NASM_LIST})
IF(NOT WIN32 AND (CMAKE_POSITION_INDEPENDENT_CODE OR ENABLE_SHARED))
set_target_properties(simd PROPERTIES POSITION_INDEPENDENT_CODE 1)
ENDIF()
# build executable program
ADD_EXECUTABLE(AssemblyLanguage_Test ${TEST_CPP_LIST} ${TEST_CPP2_LIST})
TARGET_LINK_LIBRARIES(AssemblyLanguage_Test simd)
(4).执行:$ ./build.sh; ./build/AssemblyLanguage_Test
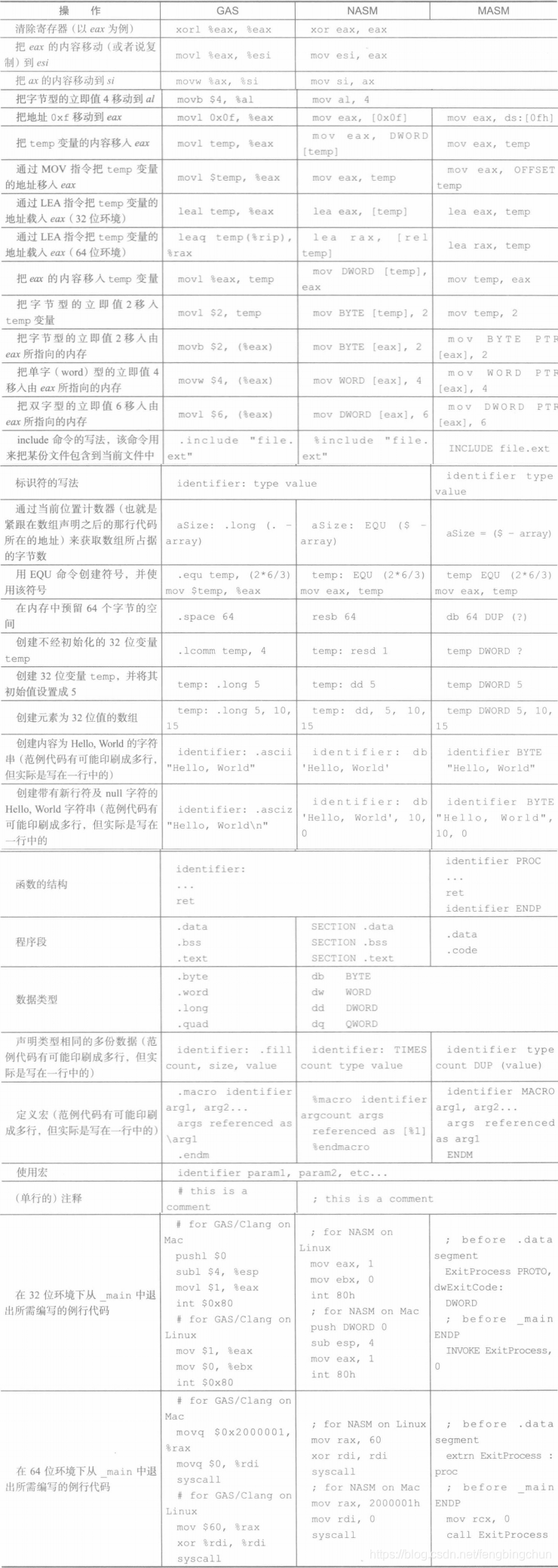
下面列出各汇编器的规则:
GitHub:https://github.com/fengbingchun/CUDA_Test