习题一 证明卷积具有交换性,即证明公式

首先,宽卷积定义为 ,其中
,其中 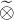 表示宽卷积运算,我们不妨先设一个二维图像
表示宽卷积运算,我们不妨先设一个二维图像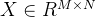 和一个二维卷积核
和一个二维卷积核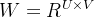 ,然后对该二维图像X进行零填充,两端各补U-1 和V-1 个零,得到全填充的图像
,然后对该二维图像X进行零填充,两端各补U-1 和V-1 个零,得到全填充的图像
现有

根据宽卷积定义

为了让x的下标形式和w的进行对换,进行变量替换
令 , 故
, 故
则

已知 ![i \in [1,M]J,J \in [1,N]](https://private.codecogs.com/gif.latex?i%20%5Cin%20%5B1%2CM%5DJ%2CJ%20%5Cin%20%5B1%2CN%5D)
因此对于

由于宽卷积的条件,s和t的变动范围是可行的。
习题二 分析卷积神经网络中用1×1卷积核的作用
卷积核又称filter,过滤器,每个卷积核有长宽深3个维度,在某个卷积层中,可以有多个卷积核,下一层需要多少个feature map ,本层就需要多少个卷积核。
卷积核的长宽是人为指定的,长×宽被称为卷积核的尺寸。常用尺寸有1*1 ,3*3 ,5*5 等,卷积核的深度与当前图像的深度相同(即通道数保持相同)。指定卷积核时,只需要指定长宽两个参数,其通道数会默认与当前作用图像的通道数相同。
1*1卷积是大小为1*1的滤波器做卷积操作,不同于2*2、3*3等filter,没有考虑在前一特征层局部信息之间的关系。
作用:
1*1卷积核可以通过控制卷积核通道数来实现升维或降维;
降维(缩减网络通道数,减少参数,减少计算量)
升维(用最少的参数拓宽网络channal)
跨通道信息交互(channal的变换)
添加非线性特性(可以增加网络深度)
例如,GoogleNet中的3a模块
输入的feature map是28×28×192,1×1卷积通道为64,3×3卷积通道为128,5×5卷积通道为32
左图卷积核参数:192 × (1×1×64) +192 × (3×3×128) + 192 × (5×5×32) = 387072
右图对3×3和5×5卷积层前分别加入了通道数为96和16的1×1卷积层,这样卷积核参数就变成了:
192 × (1×1×64) +(192×1×1×96+ 96 × 3×3×128)+(192×1×1×16+16×5×5×32)= 157184

同时在并行pooling层后面加入1×1卷积层后也可以降低输出的feature map数量(feature map尺寸指W、H是共享权值的sliding window,feature map 的数量就是channels)
左图feature map数量:64 + 128 + 32 + 192(pooling后feature map不变) = 416 (如果每个模块都这样,网络的输出会越来越大)
右图feature map数量:64 + 128 + 32 + 32(pooling后面加了通道为32的1×1卷积) = 256
GoogLeNet利用1×1的卷积降维后,得到了更为紧凑的网络结构,虽然总共有22层,但是参数数量却只是8层的AlexNet的十二分之一(当然也有很大一部分原因是去掉了全连接层)
跨通道信息互换(channal的变换)
增加非线性特性
1*1卷积核,可以在保持feature map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很deep。
一个filter对应卷积后得到一个feature map,不同的filter(不同的weight和bias),卷积以后得到不同的feature map,提取不同的特征,得到对应的specialized neuro。
参考:卷积神经网络中的1*1卷积核
习题三 对于一个输入为100×100×256的特征映射组,使用3×3的卷积核,输出为100×100×256的特征映射组的卷积层,求其时间和空间复杂度。如果引入一个1×1卷积核,先得到100×100×64的特征映射,再进行3×3卷积,得到100×100×256的特征映射组,求其时间和空间复杂度。
3×3卷积核,
时间复杂度: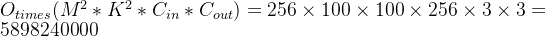
空间复杂度: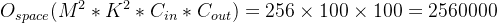
1×1卷积核,
时间复杂度:

空间复杂度:
习题四 忽略激活函数,分析卷积网络中卷积层的前向计算和反向传播(下面公式)是一种转置关系。

在不考虑激活函数的情况下,
卷积层的前向计算可参考:卷积层的前向计算
卷积层的反向传播可参考:卷积层的反向传播
这个自己本来没推明白,参考的其他同学的推导

习题五 推导CNN的反向传播算法
首先介绍一下卷积的运算,
在卷积神经网络中,所谓的卷积运算,其实并不是严格的数学意义上的卷积。深度学习中的卷积实际上是信号处理和图像处理中的互相关运算,它们二者之间有细微的差别。深度学习中的卷积(严格来说是互相关)是卷积核在原始图像上遍历,对应元素相乘再求和,得到的新图像在尺寸上会有减小。可以通过下图直观的去理解。假设输入图像的有m行,n列,卷积核的尺寸为filter_size×filter_size,输出图像的尺寸即为(m-filter_size+1)×(n-filter_size+1)

在全连接神经网络,图像数据以及特征是以列向量的形式进行存储。而在卷积神经网络中,数据的格式主要是以张量(可以理解为多维数组)的形式存储。图片的格式为一个三维张量,行×列×通道数。卷积核的格式为一个四维张量,卷积核数×行×列×通道数。
卷积操作是每次取出卷积核中的一个,一个卷积核的格式为三维,为行×列×通道数。对应通道序号的图片与卷积核经过二维卷积操作后(即上图所示操作),得到该通道对应的卷积结果,将所有通道的结果相加,得到输出图像的一个通道。每个卷积核对应输出图像的一个通道,即输出图像的通道数等于卷积核的个数。
这里概念有一点绕,但是卷积神经网络中所谓张量的卷积,本质上是进行了一共卷积核数×通道数次二维卷积操作。每一个卷积核对应卷积结果的一个通道,每一个卷积核的通道对应原始图片的一个通道。这个操作和一个列向量乘上一个矩阵得到一个新的列向量有相似的地方。
(1) 随机初始化权重和偏置为一个接近0的值(一般用正态分布),然后“前向传播”计算每层每个单元的激活值,包括输出层。激活值a=f(z),其中神经元输入z=wx+b。
(2) 计算输出层L每个单元的误差,第L层第j个单元的误差的定义:
根据链式求导得:
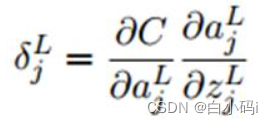
因为在上式右边第二项里,激活值a=f(z),所以误差最终写为:
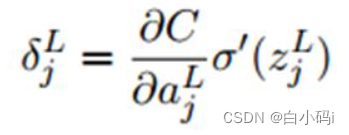
上式右边第一个项代表代价函数C随着第j个单元输出激活值的变化而变化的速度,假如C不太依赖某个输出单元,那么这个单元对应的误差δ就会很小。第二项代表激活函数f在z处的变化速度。如果给定了二次代价函数:

我们可以用矩阵方式重写误差方程:

中间这个运算符叫做哈达玛(Hadamard)乘积,用于矩阵或向量之间点对点的乘法运算:

向量也可以进行函数运算:

(3) 算完输出层开始往回算之前层的误差,当前层l的误差用下一层l+1的误差来表示:

我们可以用链式法则对误差的定义进行推导,来证明上式:
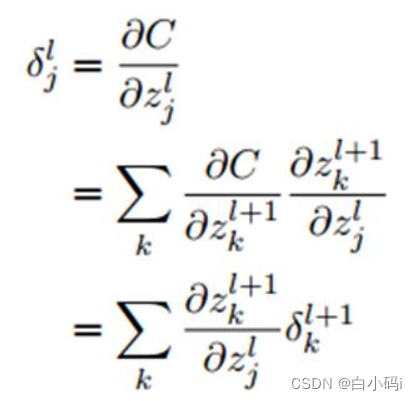
其中j是当前层的某个神经元,它和下一层的若干个神经元(由k表示)相连。注意上式交换右边两项,并用误差δ的定义代入,同时注意到:

求微分后得到:

所以:

这正是原式矩阵表达的分量形式,证明完毕。
(4) 计算代价函数关于权重和偏置的偏导数:
偏置:

权重:

其中偏置等价于误差,权重等价于误差乘以上一层神经元的输出,而上述式子的右边的项我们之前都已经算出来了。至于为什么等价可以用链式法则证明:
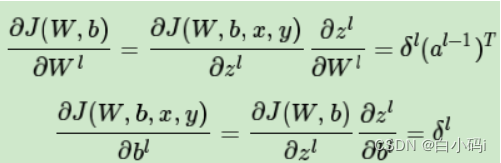
习题六 设计简易CNN模型,分别用Numpy、Pytorch实现卷积层和池化层的反向传播算子,并带入数值测试。
反向传播的编写思路:
首先,算子会涉及到的一些参数有,
- 输入与输出:算子的输入张量和输出张量。正向传播和反向传播的输入输出恰好是相反的。
- 属性:算子的超参数。比如卷积的
stride, padding。
- 中间变量:前向传播传递给反向传播的变量。
一般情况下,我们应该编写一个算子类。在初始化算子类时,算子的属性就以类属性的形式存储下来了。
在正向传播时,我们按照算子定义直接顺着写下去就行。这个时候,可以先准备好cache变量,但先不去管它,等写到反向传播的时候再处理。
接着,编写反向传播。由于反向传播和正向传播的运算步骤相似,我们可以直接把正向传播的代码复制一份。在这个基础上,思考每一步正向传播运算产生了哪些导数,对照着写出导数计算的代码即可。这时,我们会用到一些正向传播的中间结果,这下就可以去正向传播代码里填写cache,在反向传播里取出来了。
代码实现,
卷积层的反向传播实现:
from typing import Dict, Tuple
import numpy as np
import pytest
import torch
def conv2d_forward(input: np.ndarray, weight: np.ndarray, bias: np.ndarray,
stride: int, padding: int) -> Dict[str, np.ndarray]:
"""2D Convolution Forward Implemented with NumPy
Args:
input (np.ndarray): The input NumPy array of shape (H, W, C).
weight (np.ndarray): The weight NumPy array of shape
(C', F, F, C).
bias (np.ndarray | None): The bias NumPy array of shape (C').
Default: None.
stride (int): Stride for convolution.
padding (int): The count of zeros to pad on both sides.
Outputs:
Dict[str, np.ndarray]: Cached data for backward prop.
"""
h_i, w_i, c_i = input.shape
c_o, f, f_2, c_k = weight.shape
assert (f == f_2)
assert (c_i == c_k)
assert (bias.shape[0] == c_o)
input_pad = np.pad(input, [(padding, padding), (padding, padding), (0, 0)])
def cal_new_sidelngth(sl, s, f, p):
return (sl + 2 * p - f) // s + 1
h_o = cal_new_sidelngth(h_i, stride, f, padding)
w_o = cal_new_sidelngth(w_i, stride, f, padding)
output = np.empty((h_o, w_o, c_o), dtype=input.dtype)
for i_h in range(h_o):
for i_w in range(w_o):
for i_c in range(c_o):
h_lower = i_h * stride
h_upper = i_h * stride + f
w_lower = i_w * stride
w_upper = i_w * stride + f
input_slice = input_pad[h_lower:h_upper, w_lower:w_upper, :]
kernel_slice = weight[i_c]
output[i_h, i_w, i_c] = np.sum(input_slice * kernel_slice)
output[i_h, i_w, i_c] += bias[i_c]
cache = dict()
cache['Z'] = output
cache['W'] = weight
cache['b'] = bias
cache['A_prev'] = input
return cache
def conv2d_backward(dZ: np.ndarray, cache: Dict[str, np.ndarray], stride: int,
padding: int) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""2D Convolution Backward Implemented with NumPy
Args:
dZ: (np.ndarray): The derivative of the output of conv.
cache (Dict[str, np.ndarray]): Record output 'Z', weight 'W', bias 'b'
and input 'A_prev' of forward function.
stride (int): Stride for convolution.
padding (int): The count of zeros to pad on both sides.
Outputs:
Tuple[np.ndarray, np.ndarray, np.ndarray]: The derivative of W, b,
A_prev.
"""
W = cache['W']
b = cache['b']
A_prev = cache['A_prev']
dW = np.zeros(W.shape)
db = np.zeros(b.shape)
dA_prev = np.zeros(A_prev.shape)
_, _, c_i = A_prev.shape
c_o, f, f_2, c_k = W.shape
h_o, w_o, c_o_2 = dZ.shape
assert (f == f_2)
assert (c_i == c_k)
assert (c_o == c_o_2)
A_prev_pad = np.pad(A_prev, [(padding, padding), (padding, padding),
(0, 0)])
dA_prev_pad = np.pad(dA_prev, [(padding, padding), (padding, padding),
(0, 0)])
for i_h in range(h_o):
for i_w in range(w_o):
for i_c in range(c_o):
h_lower = i_h * stride
h_upper = i_h * stride + f
w_lower = i_w * stride
w_upper = i_w * stride + f
input_slice = A_prev_pad[h_lower:h_upper, w_lower:w_upper, :]
# forward
# kernel_slice = W[i_c]
# Z[i_h, i_w, i_c] = np.sum(input_slice * kernel_slice)
# Z[i_h, i_w, i_c] += b[i_c]
# backward
dW[i_c] += input_slice * dZ[i_h, i_w, i_c]
dA_prev_pad[h_lower:h_upper,
w_lower:w_upper, :] += W[i_c] * dZ[i_h, i_w, i_c]
db[i_c] += dZ[i_h, i_w, i_c]
if padding > 0:
dA_prev = dA_prev_pad[padding:-padding, padding:-padding, :]
else:
dA_prev = dA_prev_pad
return dW, db, dA_prev
@pytest.mark.parametrize('c_i, c_o', [(3, 6), (2, 2)])
@pytest.mark.parametrize('kernel_size', [3, 5])
@pytest.mark.parametrize('stride', [1, 2])
@pytest.mark.parametrize('padding', [0, 1])
def test_conv(c_i: int, c_o: int, kernel_size: int, stride: int, padding: str):
# Preprocess
input = np.random.randn(20, 20, c_i)
weight = np.random.randn(c_o, kernel_size, kernel_size, c_i)
bias = np.random.randn(c_o)
torch_input = torch.from_numpy(np.transpose(
input, (2, 0, 1))).unsqueeze(0).requires_grad_()
torch_weight = torch.from_numpy(np.transpose(
weight, (0, 3, 1, 2))).requires_grad_()
torch_bias = torch.from_numpy(bias).requires_grad_()
# forward
torch_output_tensor = torch.conv2d(torch_input, torch_weight, torch_bias,
stride, padding)
torch_output = np.transpose(
torch_output_tensor.detach().numpy().squeeze(0), (1, 2, 0))
cache = conv2d_forward(input, weight, bias, stride, padding)
numpy_output = cache['Z']
assert np.allclose(torch_output, numpy_output)
# backward
torch_sum = torch.sum(torch_output_tensor)
torch_sum.backward()
torch_dW = np.transpose(torch_weight.grad.numpy(), (0, 2, 3, 1))
torch_db = torch_bias.grad.numpy()
torch_dA_prev = np.transpose(torch_input.grad.numpy().squeeze(0),
(1, 2, 0))
dZ = np.ones(numpy_output.shape)
dW, db, dA_prev = conv2d_backward(dZ, cache, stride, padding)
assert np.allclose(dW, torch_dW)
assert np.allclose(db, torch_db)
assert np.allclose(dA_prev, torch_dA_prev)
池化层的反向传播实现:
import numpy as np
from module import Layers
class Pooling(Layers):
def __init__(self, name, ksize, stride, type):
super(Pooling).__init__(name)
self.type = type
self.ksize = ksize
self.stride = stride
def forward(self, x):
b, c, h, w = x.shape
out = np.zeros([b, c, h//self.stride, w//self.stride])
self.index = np.zeros_like(x)
for b in range(b):
for d in range(c):
for i in range(h//self.stride):
for j in range(w//self.stride):
_x = i *self.stride
_y = j *self.stride
if self.type =="max":
out[b, d, i, j] = np.max(x[b, d, _x:_x+self.ksize, _y:_y+self.ksize])
index = np.argmax(x[b, d, _x:_x+self.ksize, _y:_y+self.ksize])
self.index[b, d, _x +index//self.ksize, _y +index%self.ksize ] = 1
elif self.type == "aveg":
out[b, d, i, j] = np.mean((x[b, d, _x:_x+self.ksize, _y:_y+self.ksize]))
return out
def backward(self, grad_out):
if self.type =="max":
return np.repeat(np.repeat(grad_out, self.stride, axis=2),self.stride, axis=3)* self.index
elif self.type =="aveg":
return np.repeat(np.repeat(grad_out, self.stride, axis=2), self.stride, axis=3)/(self.ksize * self.ksize)
对函数进行测试,结果为

参考:
卷积神经网络(CNN)反向传播算法 - 刘建平Pinard - 博客园 (cnblogs.com)
卷积神经网络(CNN)反向传播算法推导 - 知乎 (zhihu.com)
十二、CNN的反向传播 - 知乎 (zhihu.com)