前言
讲一下大概的内容(类加载-JVM内存模型-对象的创建-垃圾回收-JVM调优(入门))
最近抽了时间学了一直都很想学的 JVM,之前也学过一点,也发布过一些零散的文章,但这篇文章会更加全面,学完这篇文章就足以应对有关 JVM 的面试(如果遇到没有的题,请写在评论区)。
本文主要从以下六个方面来讲述:
- 类加载之前
- 类加载。
- JVM 内存模型。
- 对象的创建。
- 垃圾回收。
- JVM 调优(入门)。
本文主要按照对象的生命周期:字节码文件的编译到被加载进 JVM,再到对象的创建,最后到各种垃圾收集器对对象的回收流程,最后的最后再补上 JVM 调优。
类加载之前
在类加载之前,我们必然需要写好一段代码,并将这段代码编译好,得到一个 class 文件,这个文件就是我们所说的字节码文件,一说到字节码就会提到静态常量池,还有运行时常量池是什么?
这一部分我们就来普及这些概念:
- 字节码
- 常量池( 静态常量池 & 运行时常量池、字面量 & 符号引用)
字节码
首先,我们需要一个 java 文件,像这样。
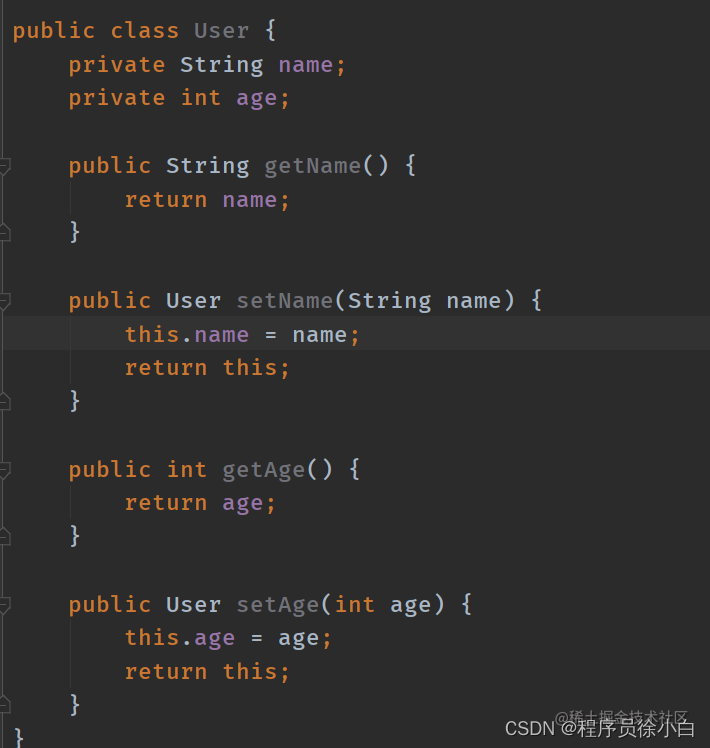
然后,编译它,使用javac User.java或者 IDEA 编辑器编译都可以。
然后得到一个 User.class,这就是字节码文件。

字节码的含义
当我们使用文本编辑工具打开字节码文件,会看到很多很多根本看不懂的十六进制数(除了最前面的cafe babe,这个数被称为魔数,用来标识这个文件是 java 的字节码文件)。

如果想要一个字一个字地去解读这份字节码文件,可以翻看我之前的文章,但这个不是特别重要,毕竟我们不需要敲字节码来开发,这些都是给虚拟机看的。
我们可以使用javap -v User.class命令来把字节码编译成更加可读的指令码。
javap -v User.class > User.txt 这个命令可以把指令码文件输出到 User.txt 中,于是我们可以得到这样一个文件:
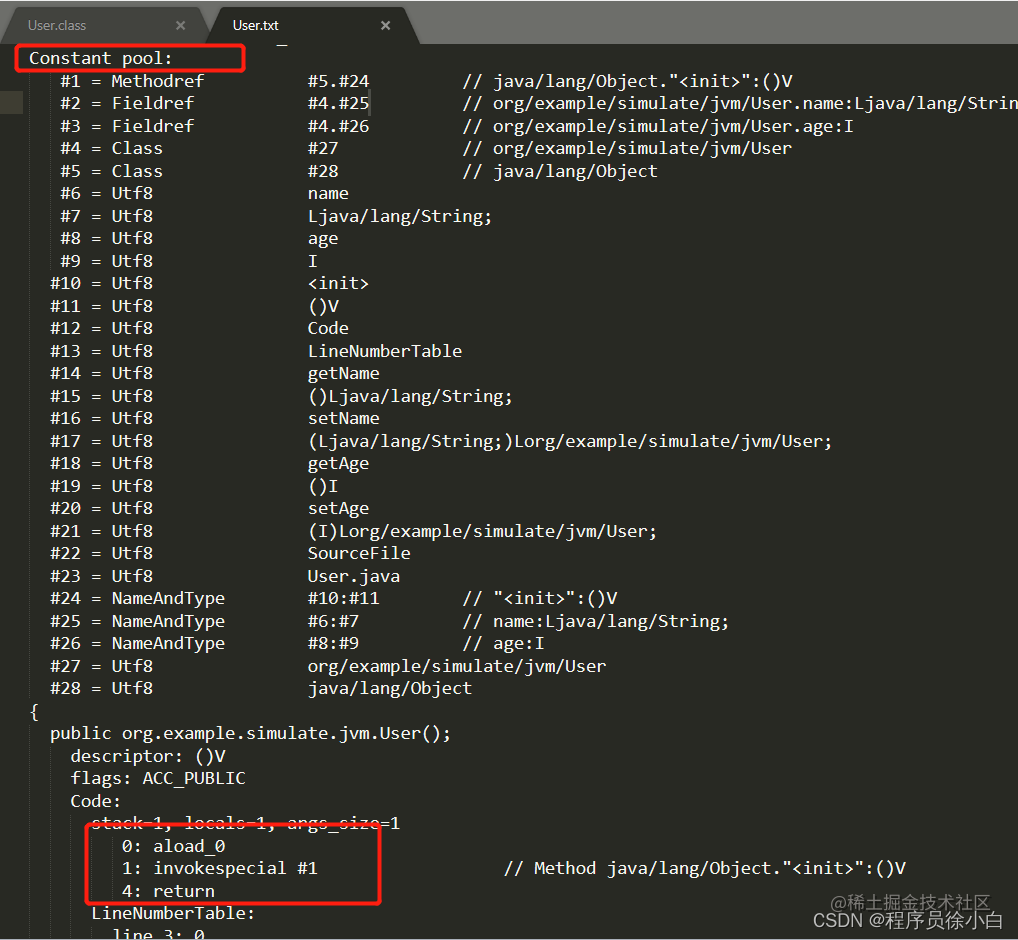
好像变得更容易读懂了,又好像没有那么容易读懂。
像这里的 Constant pool 就是我们常说的静态常量池,后续会进行解读,而 Code 里面的就是指令码,想要读懂指令码就需要参照 Java指令码表。
常量池
我们可以在字节码中看到静态常量池,它和运行时常量池有什么关系?还有字符串常量池、基础类型常量池又是什么?
静态常量池
静态常量池说的就是字节码文件中的 Constant pool,这里存放的都是字面量和符号引用。
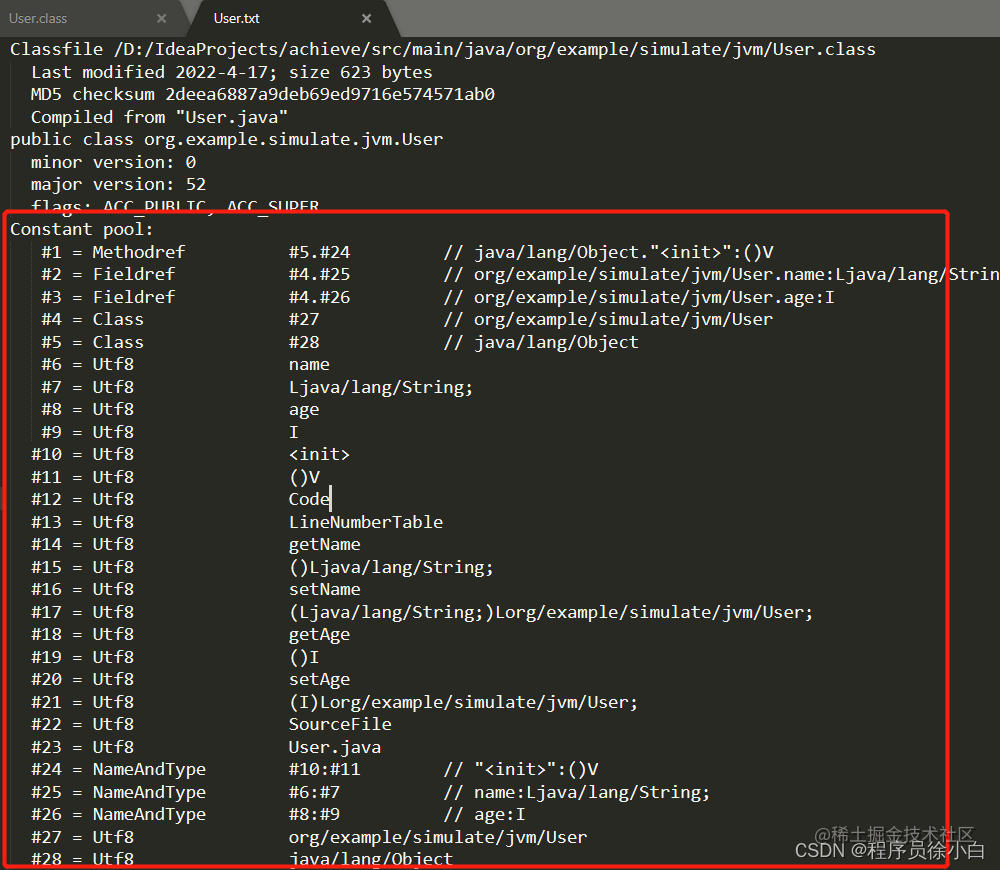
字面量
字面量就是那种我们写在代码中的字符串或者基本数据类型的值,比如下图的"11",1。
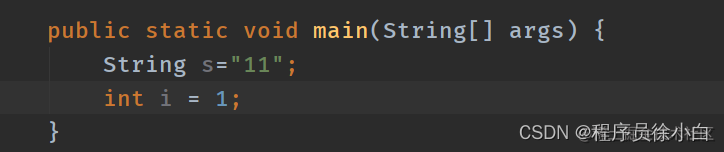
但如果把这个代码编译成字节码,我们只能看到字符串的字面量出现在 Constant pool 中,而不会出现在 Code 中。
符号引用
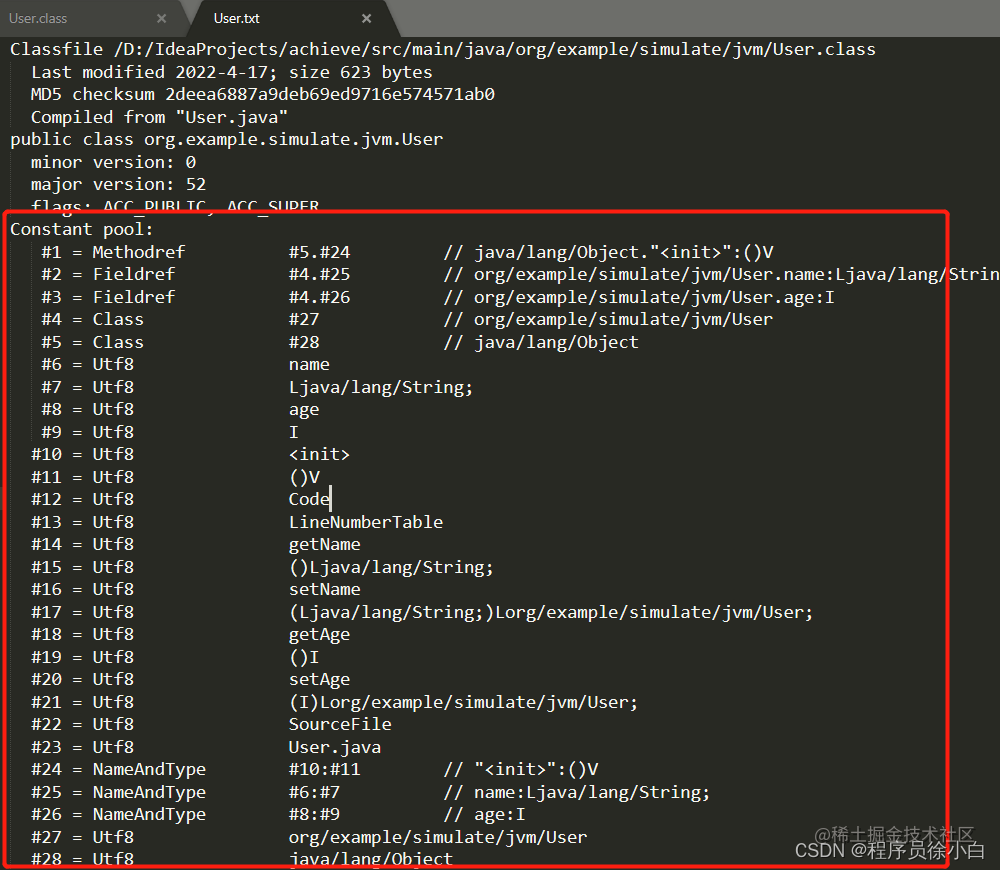
符号引用的主要表现形式是字符串,主要包括以下三种类型:
- 类和接口的全限定名(比如上图的#4、#5)
- 字段的名称和描述符(比如#2、#3)
- 方法的名称和描述符(比如#1)
因为字节码文件是静态的,还没有被加载进内存,所以无法使用准确的地址来表示要引用那个类/接口、字段、方法,于是就使用了一段(能够准确地表达想要引用什么的)符号来表示要引用那个类、接口、字段、方法。
在经过类加载器加载进入 JVM 时,类加载器就会把这个符号引用转换为一个可以被引用的地址,这个过程就是把符号引用转换成直接引用。
当然,直接引用也有三种分类:
按我的理解:
- 类的静态成员属性或者静态方法的引用转换成目标的地址的符号引用
- 对象的成员属性的引用转换成相对的偏移量的符号引用
- 对象或者接口(不能明确调用那个类的对象)的方法的引用转换成句柄的符号引用
总之,直接引用就是内存中实打实的可以被调用的地址。
运行时常量池
当静态常量池被加载进 JVM 后,就变成了运行时常量池,而运行时常量池存放着类信息,属性信息,方法信息以及字符串常量池,当然还有根据不同的对象类型被分为 Integer 常量池、Long 常量池等基础数据类型的包装类常量池。
这一小节,统统给大家讲明白。
字符串常量池
字符串常量池是一个比较复杂的常量池。
为什么会有字符串常量池?
字符串不是基础数据类型,它是一个对象,但它的使用频率却和基础数据类型差不多,高频率地创建对象会极大地影响程序的性能。
JVM 为了提高程序的性能和减少内存的开销,于是给字符串的创建增加了一层缓存,以此来减少相同字符串的创建。
字符串常量池的位置
首先,我们要了解一下字符串常量池的存放位置。
先放一张 JVM 内存模型的图片,看不懂没关系,可以看到后面的JVM内存模型再回来看。
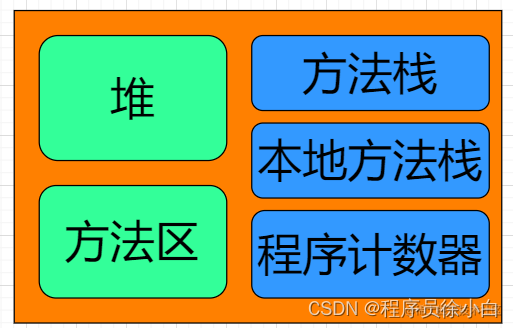
字符串主要涉及的内存区域是堆和方法区。
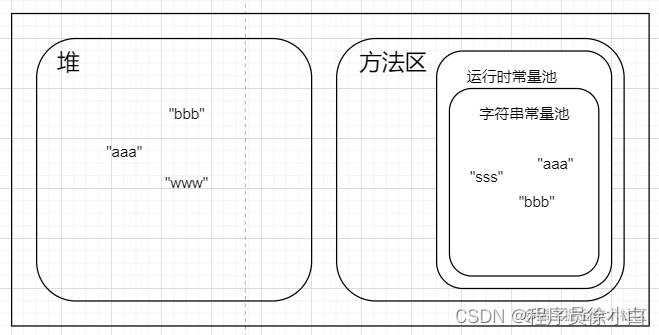
在 JDK1.6 时,字符串常量池是在运行时常量池里的,而运行时常量池是放在方法区里的永久代中,除非手动把字符串加入到方法区(这个操作后面会说),否则只有在静态常量池中的字符串才会被加载到字符串常量池。
所以 JDK1.6 的字符串分布大概是这样的。
从 JDK1.7 开始,JVM 就把字符串常量池从永久代中转移到了堆,运行时常量池还在永久代中,永久代还在方法区中。
所以 JDK1.7 之后的字符串分布大概是这样的。
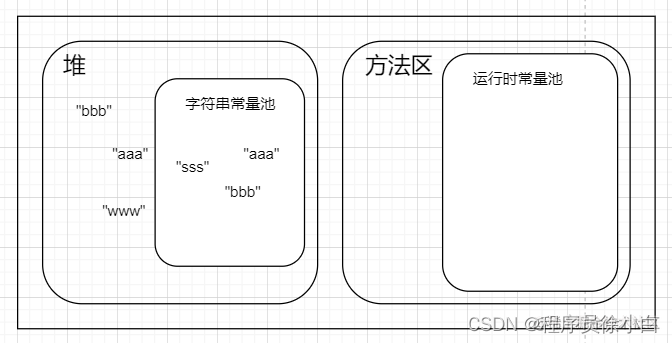
到了 JDK1.8,就没有永久代了,字符串常量池在堆中,运行时常量池就是方法区内了。
所以我们要探讨字符串的设计原理需要分为 JDK1.7 之前和之后两种情况来讨论。
三种字符串操作
然后,讲一下字符串的一些操作,这样我们才能知道什么时候字符串会在堆里创建,什么时候在字符串常量池中创建。
- 直接赋值一个字符串
String s="abc";
通过这种方式创建的字符串都是在字符串常量池里面的,因为 JVM 在加载这个字面量“abc”的时候,会先去字符串常量池中通过 equals(key) 的方式找一下有没有相同的字符串,如果有就返回,没有就在字符串常量池中创建一个。
- new String()
String s=new String("aaa");
通过这种方式创建的字符串都是在堆里的,这也很好记,通过 new 创建的对象都是在堆里的,不会再去字符串常量池中判断。
但是,这个操作会同时创建两个字符串,一个在字符串常量池中,是在加载字节码时加载字面量"aaa"创建的,另一个是直接 new String() 操作时创建在堆里的。
- String.intern()方法
String s1 = new String("bbb");
String s2 = s1.intern();
System.out.println(s1==s2); //false
String.intern()方法是一个 native 方法,想看它的代码只能去下载 JVM 的源码了。
(这个方法逻辑不同版本不一样,详情往下看)
看起来这个逻辑和直接赋值一个字符串差不多,但这个方法的调用对象在或者不在字符串常量池里,就会有不同的情况。
回到上面的代码String s2 = s1.intern();,这里的 s1 是创建在堆上的,不在字符串常量池里的,在字符串常量池里的字符串是在字节码加载到 JVM 时,JVM 根据字面量"bbb"创建的。
这里以 JDK1.8 为标准画了一个图, s2 指向的是字符串常量池内的字符串"bbb"。
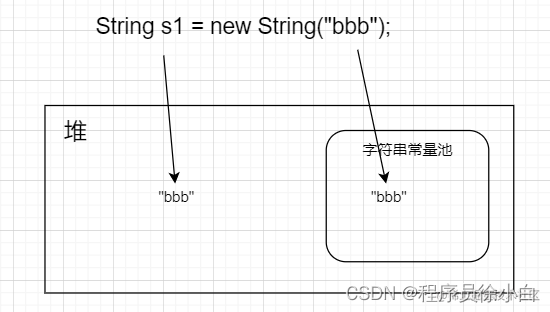
所以 s1==s2 是 false。
那不同版本的 intern 方法差别有多大?
JDK1.7 之前,在调用 intern 方法时,JVM 会通过 equals(key) 的方式在字符串常量池中去找一下这个字符串,如果有相同的就返回,没有就新建一个。
JDK1.7 之后,在调用 intern 方法时,JVM 会通过 equals(key) 的方式在字符串常量池中去找一下这个字符串,如果有相同的就返回,没有就把调用这个方法的对象加入字符串常量池。
字符串常量池从方法区转移到了堆和 intern 方法的调整会带来多大的影响呢?让我们看一下下面这段代码。
String s1=new String("aa")+new String("bb");
String s2=s1.intern();
System.out.println(s1==s2);
/*
在 JDK1.7 之前,输出的结果是 false,总共创建了 6 个字符串。
在 JDK1.7 之后,输出的结果是 true,总共创建了 5 个字符串。
*/
你知道为什么会这样吗?
说不出来也没关系,我来给你详细地讲述一下(说出来这一段就不用看了)。
字符串常量池实际上是一个类似 Map 的数据结构,想要从字符串常量池中查找字符串是需要通过 equals(key) 的方式去查找的,所以实际上的字符串常量池不是包含着字符串,而是把字符串的引用存储在一个 map 里,如下图。
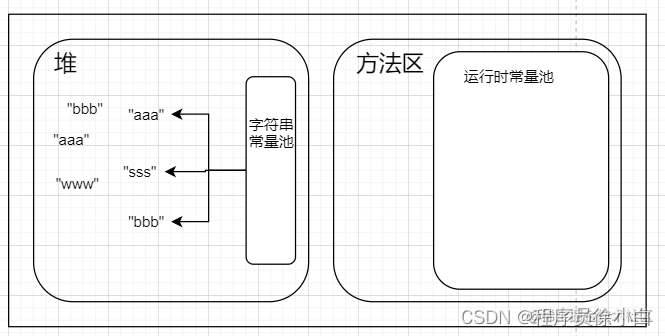
接下来,我就按照 JDK1.7 之前和之后两种情况分别画图演示一下上面三行代码的运行过程。
JDK1.7 之前
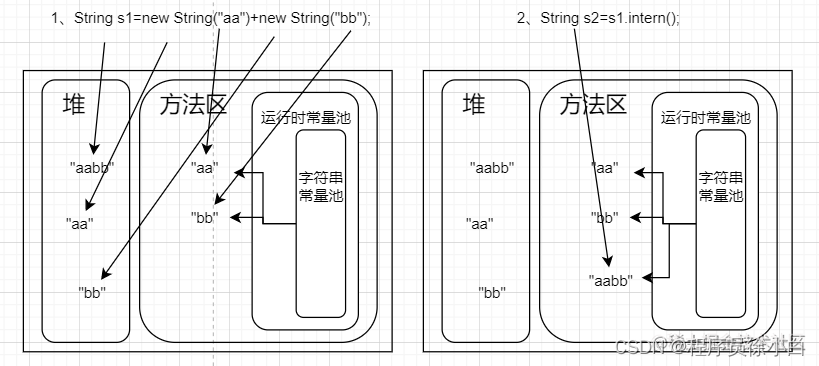
- 第一行代码会在加载字节码的时候根据字面量在字符串常量池(在方法区里)创建两个字符串
"aa","bb",紧接着有因为 new String() 在堆里创建了两个字符串"aa","bb",后来因为两个字符串相加又在堆里创建了一个字符串"aabb"。
-
"aabb"调用 intern 方法,因为这个字符串不在堆里,字符串常量池里是找不到这个字符串的,所以又会在字符串常量池中再创建一个字符串"aabb"。
所以,s1 指向的是堆里的"aabb",而 s2 指向的是方法区里被字符串常量池引用的"aabb",这不是同一个字符串,s1==s2 是 false。
JDK1.7 之后
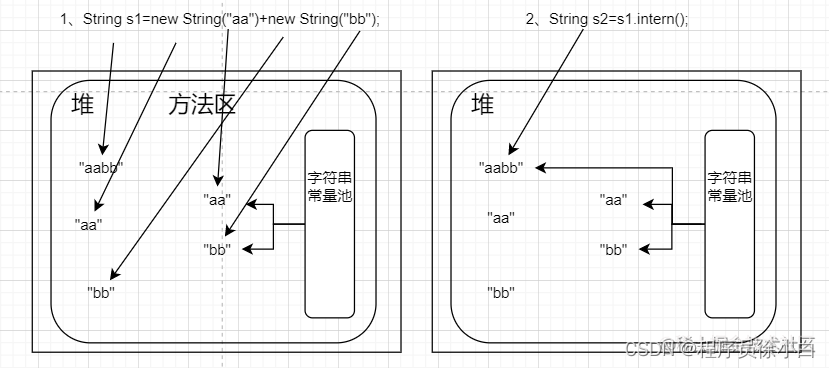
- 和 JDK1.7 之前一样,只不过字符串都是在堆里的。
-
"aabb"调用 intern 方法,但在字符串常量池中找不到,于是就把这个字符串加入到字符串常量池中了,再把这个字符串赋值给 s2。
所以,s1 和 s2 指向的都是同一个字符串,s1==s2 是 true。
关于字符串的练习题
最后用几个笔试可能会经常遇到的练习题来帮助大家更了解字符串的三种操作。
习题1:
String s3 = "xiaobai";
String s4 = "xiaobai";
String s5 = "xiao"+"bai";
System.out.println(s3 == s4); // true
System.out.println(s4 == s5); // true
这道题很简单,s3 = s4 是因为他们的字面量是一样的,所以必然是同一个字符串,而 s5 则是在编译成字节码的时候会做出优化,s5 的字面量也是"xiaobai"。
习题2:
String s6 = "xiaobai";
String s7 = new String("xiaobai");
String s8 = "xiao"+new String("bai");
System.out.println(s6 == s7); // false
System.out.println(s6 == s8); // false
System.out.println(s7 == s8); // false
String s12 = "xiaobai";
String s13 = "bai";
String s14 = "xiao"+s13;
System.out.println(s12 == s14); //false
s6 是通过字面量生成的,所以位于字符串常量池的;s7 是通过 new String 生成的,所以是一个新的字符串;而 s8 实际上也是 new String 生成的,因为 Java 的编译器是没办法优化"xiao"+new String("bai")(字面量+对象/对象引用)的情况,只能优化"xiao"+"bai"(字面量+字面量)这种情况。
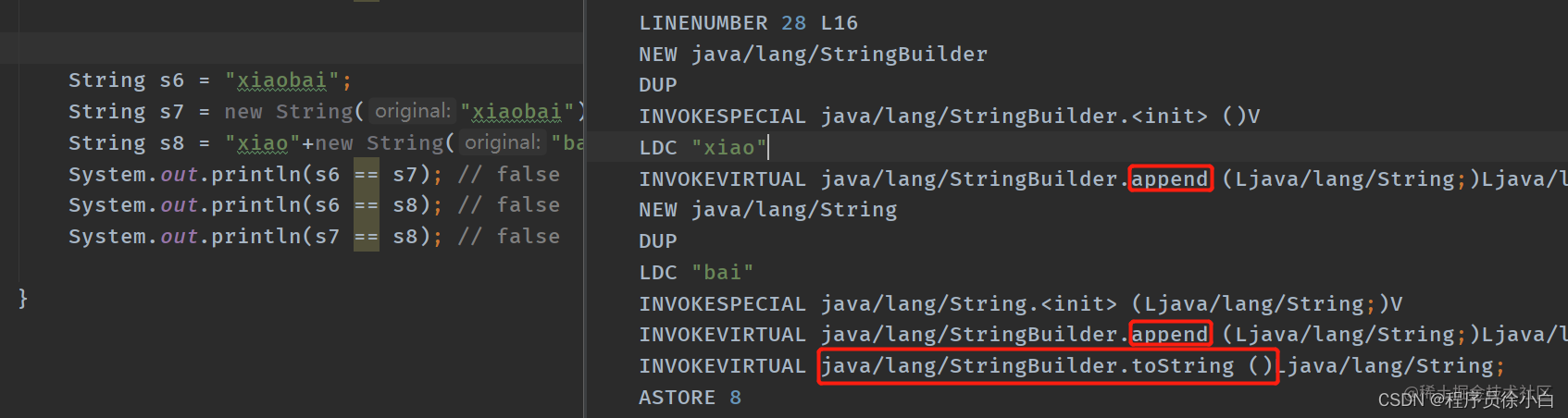
可以看到字面量+对象/对象引用的情况,是会调用 StringBuilder 来拼接字符串的,最后调用 StringBuilder.toString() 返回一个新的字符串。
而字面量+字面量的情况是包含字符串字面量+基础类型字面的情况的,什么意思呢?看一下下面的代码就懂了。
String s9 = "xiaobai1";
String s10 = "xiaobai"+1;
String s11 = "xiaobai"+'1';
System.out.println(s9 == s10); // true
System.out.println(s9 == s11); // true
在编译之后,s9、s10、s11 的字面量都会变成"xiaobai1"。
总结
最后放一个字符串常量池在 JDK1.7前后 的区别的表格。
|
JDK1.7之前 |
JDK1.7之后 |
| 字符串常量池的位置 |
方法区 |
堆 |
| 直接赋值 |
在字符串常量池中创建一个字符串 |
在字符串常量池中创建一个字符串 |
| new String() |
在堆上创建一个字符串 |
在堆上创建一个字符串 |
| intern() |
先在字符串常量池中找有没有相同的字符串,有就返回,没有就重新创建一个 |
先在字符串常量池找有没有相同的字符串,找到就返回,找不到就把调用该方法的字符串加入字符串常量池并返回 |
基础数据类型常量池
基础数据类型常量池主要是针对八种基础数据类型的包装类做的缓存,而且这些缓存都是直接使用 Java 代码实现的,和字符串常量池的实现是不一样的。
| 基础数据类型 |
包装类 |
| byte |
Byte |
| short |
Short |
| int |
Integer |
| long |
Long |
| float |
Float |
| double |
Double |
| char |
Char |
| boolean |
Boolean |
(我除了 int 的包装类,其他就把第一个字母大写了,如果有写错了,请以官方的为标准。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)