前言
索引时存储引擎用于快速找到记录的一种数据结构,索引主要用来查找和排序。
索引是表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据。对于索引,会保存在额外的文件中。
索引对于良好的性能非常关键。数据量越大时,索引对性能的影响也越重要,好的索引可以将查询性能提高几个数量级,但是在数据量很大时,糟糕的索引也会使MySQL的性能急剧的下降
一、索引的语法
1.1 创建索引
- 创建表之后添加索引
CREATE INDEX indexName ON tableName(username(length));
或者
ALTER table tableName ADD INDEX indexName(columnName)
- 创建表的时候直接指定
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
1.2 删除索引
DROP INDEX [indexName] ON tableName ;
或者
ALTER TABLE table_name DROP INDEX index_name;
1.3 查看索引
SHOW INDEX FROM tableName ;
1.4 查看查询语句使用索引的情况
# explain 加查询语句
explain SELECT * FROM table_name WHERE column_1 = '123';
二、索引的优缺点
2.1 索引的优点
索引可以让服务器快速的定位到表的指定位置。但是这并不是索引的唯一作用,到目前位置,可以看到,根据索引的数据结构不同,索引也有一些其他的附加作用,总结下来索引有以下三个优点:
- 索引大大减少了服务器需要扫描的数据量
- 索引可以帮助服务器避免排序和临时表
- 索引可以将随机I/O变为顺序I/O ```
2.2 索引的缺点
索引本身也是表,因此会占用存储空间,创建和维护索引需要耗费空间和时间成本,这个成本随着数据量增大而增大;构建索引会降低数据表的修改操作(删除,添加,修改)的效率,因为在修改数据表的同时还需要修改索引表;
三、索引的类型
索引有很多类型,可以为不同场景提供更好的性能。在MySQL中,索引是在存储引擎层实现。因此,并没有统一的索引标准,不同引擎的索引工作方式并不一样,即使是多个存储引擎支持同一种索引,其底层实现也可能不同。
3.1 按照功能逻辑区分
MySQL目前主要有以下五种索引类型:
1.普通索引
是最基本的索引,它没有任何限制。
ALTER TABLE 'table_name' ADD INDEX index_name('col');
2.唯一索引
与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
ALTER TABLE 'table_name' ADD UNIQUE index_name('col');
3.主键索引
是一种特殊的唯一索引,一个表只能有一个主键,索引列的值必须唯一,不允许有空值。一般是在建表的时候同时创建主键索引
ALTER TABLE 'table_name' ADD PRIMARY KEY pk_index('col');
4.组合索引
指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合
ALTER TABLE 'table_name' ADD INDEX index_name('col1','col2','col3');
5.全文索引
主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。fulltext索引配合match against操作使用,而不是一般的where语句加like。它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。值得一提的是,在数据量较大时候,现将数据放入一个没有全局索引的表中,然后再用CREATE index创建fulltext索引,要比先为一张表建立fulltext然后再将数据写入的速度快很多。
创建时需要在INDEX前面加上FULLTEXT
ALTER TABLE 'table_name' ADD FULLTEXT INDEX ft_index('col');
3.2 按照数据结构区分
在 MySQL 中,主要有四种类型的索引,分别为: B-Tree 索引, Hash 索引, Fulltext 索引和 R-Tree 索引。我们主要分析B-Tree 索引。
1.B-Tree(B+Tree)索引
目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构。当谈论索引的时候,如果没有特别指明类型,多半说的是B-Tree索引,它使用B-Tree数据结构来存储数据。
B-Tree索引的原理请参考MySQL索引背后的数据结构及算法原理
2.Hash索引
只有memory(内存)存储引擎支持哈希索引,哈希索引用索引列的值计算该值的hashCode,然后在hashCode相应的位置存执该值所在行数据的物理位置,因为使用散列算法,因此访问速度非常快,但是一个值只能对应一个hashCode,而且是散列的分布方式,因此哈希索引不支持范围查找和排序的功能。
3.全文索引
4.R-Tree(控件数据索引)
四、高性能的索引策略
4.1 三星系统
正确地创建和使用索引是实现高效能查询的基础。高效的选择和使用索引有很多种方式,其中有些是针对特殊案例的优化方法,有些则是针对特定行为的优化。
Lahdenmaki和Leach在书中介绍如何评价一个索引是否适合某个查询的三星系统
- 索引将相关记录放在一起则获得一星
- 索引的数据顺序和排列顺序一致则获得二星
- 如果索引中的列包含了查询中的全部列则获取三星
4.2 什么时候要使用索引?
- 主键自动建立主键索引
- 频繁作为查询条件在WHERE
- 查询中与其他表关联的字段,外键关系建立索引
- 作为排序的列要建立索引,排序字段通过索引去访问,会大大提高排序速度
- 高并发条件下倾向组合索引;
- 查询中统计或者分组的字段或者用于聚合函数的列可以建立索引,例如使用了max(column_1)或者count(column_1)时的column_1就需要建立索引
4.3 什么时候尽量不要建立索引
- 表记录太少(全表扫描也很快,没有必要)
- 经常增删改的字段上不要建立索引
- 有大量重复且分布均匀的数据的列不建立索引
4.3 高性能的索引策略
正确的创建和使用索引是实现高性能查询的基础。前面已经介绍了各种类型的索引及其对应的优缺点, 我们通常会看到一些查询不当的使用索引,或者使用MySQL无法使用已有的索引,高性能的索引策略就是要避免索引失效,并尽可能的发挥这些索引的优势。
4.3.1 独立的列
如果查询中的列不是独立的,则MySQL就不会使用索引。独立的列指索引列不能是表达式的一部分,也不能是函数的参数
比如:
mysql> SELECT actor_id FROM actor WHERE actor_id + 1 = 5
或者
mysql> SELECT ... WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col) <= 10
4.3.2 前缀索引和索引选择性
4.3.2.1 前缀索引
有时候需要很长的字符列,就会让索引变的大且慢。一个策略是前面提到过的Hash索引。另外一种方式就是使用前缀索引。
前缀索引就是指使用索引列开始的部分字符建立索引
4.3.2.2 前缀索引的优缺点
优点:这样可以大大节约索引的空间,从而提高索引的效率。
缺点:使用前缀索引会降低索引的选择性,而且无法使用前缀索引做ORDER BY和GROUP BY,也无法使用前缀索引做覆盖扫描
4.3.2.3 索引的选择性:
索引的选择性是指不重复的索引值(也成为基数)和数据表记录总数(#T)的比值,范围从1/#T到1之间,索引选择性越高,查询效率越快
4.3.2.4 如何选则前缀索引长度
选择前缀的索引的原则是要选择足够的长度保证索引较高的选择性,前缀索引的选择性应该接近于索引的整个列,但同时又不能太长。
可以根据,前缀的基数应该接近于完整列的基数,来确定基数的长度,我们可以通过截取不同长度的字符和完整列进行比较,找到合适的长度
另外一个办法就是计算完整列的选择性,并使用前缀的选择性接近完整列的选择性
mysql>select count(distinct left(city,3))/count(*) as sel3
-> count(distinct left(city,4))/count(*) as sel4
-> count(distinct left(city,5))/count(*) as sel5
-> count(distinct left(city,6))/count(*) as sel6
-> count(distinct left(city,7))/count(*) as sel7
-> from city_table
比例接近完整列的选择性的,就可以使用作为前缀索引的长度
注:只看平均选择性长度是不够的,对于数据分布很不均匀的数据,可能会有陷阱,比如平均值很接近完整列的选择性,但是由于数据的不均匀,可能对于某些数据很不友好,比如选择4个字段,平均值可能很好,但是"San"和"New"开头的选择性就特别糟糕,因此在选怎前缀索引时,要根据实际情况
4.3.3 多列索引
多列索引指的是组合索引,组合多个列创建一个索引,很多人对多列索引理解不够,常见的就是为每一个列创建独立的索引,或者按照错误的顺序创建组合索引。
再多个列上建立单列索引大部分情况下并不能提高MySQL的查询性能。MySQL5.0和更新的版本引入了一种“索引合并”(index merge)的策略,一定程度上可以使用表上的多个单列索引来定位指定的行。
在MySQL’更早的版本中只能使用其中某一个单列索引。但在MySQL5.0和更新的版本中,查询能够同时使用多个单列索引进行扫描,并将结果进行合并。
该特新主要应用于以下三种场景:
1、 对OR语句求并集,如查询SELECT * FROM TB1 WHERE c1=“xxx” OR c2="“xxx"时,如果c1和c2列上分别有索引,可以按照c1和c2条件进行查询,再将查询结果合并(union)操作,得到最终结果
2、 对AND语句求交集,如查询SELECT * FROM TB1 WHERE c1=“xxx” AND c2=”"xxx"时,如果c1和c2列上分别有索引,可以按照c1和c2条件进行查询,再将查询结果取交集(intersect)操作,得到最终结果
3、 对AND和OR组合语句求结果
mysql> explain select * from t01 where c1 = 1 or c2 = 2
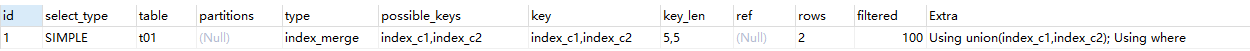
MySQL合并策略有时候是一种优化的结果,但实际上更多的时候说明了表上的索引建的很糟糕
- 当出现多个索引相交操作时(通常有多个AND条件),通常意味着需要一个包含所有相关列的多列索引,而不是多个独立的单列索引
- 当出现多个索引联合操作时(通常有多个OR条件),通常需要消耗大量CPU和内存资源在算法的缓存、排序和合并操作上。特别是当其中有些索引的选择性并不高,需要合并扫描返回大量数据的时候
- 更重要的是,优化器不会把这些计算到“查询成本”中,优化器只关心随机页面读取。这会使得查询成本被“低估”,导致该执行计划还不如直接走全表扫描。这样做不但会消耗更多的CPU和内存,还可能会影响查询的并发性,但如果是单独运行这样的查询则往往会忽略对并发性的影响。通常来说,还不如MySQL4.1之前,将查询改写成UNION的方式好
如果在EXPLAIN中看到索引合并,应该好好检查一下查询和表结构,看是不是已经是最优。
4.3.4 选择合适的索引列顺序
我们遇到最容易引起困惑的问题就是索引列的顺序,正确的顺序依赖于使用该索引的查询,并且同时满足排序和分组的需要(适用于B-Tree索引,Hash或者其他类型的索引并不会想B-Tree索引一样按照顺序存储数据)
在多列索引中,索引的顺序非常重要,如果索引的顺序不正确,会导致索引失效
-
最佳左前缀法则
在一个多列B-Tree索引中,索引列的顺序意味着索引首先先按照最左列进行排序,其次是第二列
以下面查询位列
mysql>select * from payment where staff_id = 2 and customer_id = 584;
应该如何创建索引呢?是(staff_id ,customer_id )索引还是颠倒一下呢,我们可以泡一下查询来确定这个表中值的分布情况,来确定哪个列的查询到的数据量更小,将查询到数据量小的列放在左边
索引创建后,必须按照索引创建顺序
-
存储引擎不能使用索引中范围条件右边的列
-
在使用不等于<>或者!= 时,无法使用索引会导致全表扫描
-
is null和is not null无法使用索引
-
like以通配符%开头,索引会失效,可以使用‘***%’,索引不会失效(这是底层存储引擎API的限制,MySQL可以将最左前缀的LIKE比较转换为简单的比较操作)
-
字符串不加单引号,索引会失效
-
少用or,用他连接会导致索引失效
假设复合索引index(a,b,c)
| where语句 |
索引使用情况 |
| where a=3 |
Y,使用到了a |
| where a=3 and b = 5 |
Y,使用到了a,b |
| where a=3 and b = 5 and c= 6 |
Y,使用到了a,b ,c |
| where b=3或者 where b=3 and c=5 |
N,没有用到最左侧的索引,索引就会失效 |
| where a = 3 and c = 5 |
Y,只使用到了a ,b索引没有被用到,只要左侧的索引没有用到,后面的索引就都会失效 |
| where a = 3 and b > 4 and c = 5 |
Y,只使用到了a 和b,b使用了范围,其后续索引失效 |
| where a=3 and b like ‘kk%’ and c=5 |
Y,使用到了a,b ,c |
| where a=3 and b like ‘%kk%’ and c=5 |
Y,只是用到了a |
| where a=3 and b like ‘k%kk%’ and c=5 |
Y,使用到了a,b ,c |
ORDER BY 和GROUP BY使用复合索引时,也要注意顺序
| where语句 |
索引使用情况 |
| where a=3 order by c |
排序 Using filesort |
| where c1 = 2 order by c3,c2 |
排序 Using filesort |
| where a=3 and b=4 order by c 或者where a=3 order by b,c |
排序也使用索引 |
注:where a=3 and b = 5 and c= 6 也会使用到所有的索引,因为MySQL优化器会调整顺序,但是最好还是以什么顺序创建的,就以什么顺序使用
4.3.5 覆盖索引
如果索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为覆盖索引。覆盖索引可以使用索引直接获取列数据,这样就不再需要读取数据行
覆盖索引是非常有用的工具,能够极大的提高性能。
- 索引条目通常远远小于数据行操作,索引如果只需要读取索引,那么MySQL就会极大的减少数据访问量
- 因为索引是按照列值顺序存储的(至少单个页内如此),所以对于I/O密集型的范围查询会比随机从磁盘读取每一行数据的I/O要少的多
- 一些存储引擎如MyISAM的内存中只缓存索引,数据则依赖操作系统来缓存,因此访问数据需要一次系统调用。这会导致严重的性能问题
- 由于InnoDB的聚簇索引,覆盖索引对于InnoDB表特别有用。由于InnoDB的二级索引在叶子结点中保存了行的主键值,如果二级主键能够覆盖查询,则可以便面对主键索引的二次查询
不是所有的索引都可以成为覆盖索引,覆盖索引必须要存储索引列的值,索引哈希索引、空间索引、全文索引的都不存储索引列的值,所以MySQL只能使用B-Tree索引做覆盖索引
当发起一个呗索引覆盖的查询,在explain的Extra列可以看到“Using index”的信息
t02表(字段,c1,c2,c3,c4),创建索引(index_c12)
mysql查询优化器会在执行查询前判断是否有一个索引能进行覆盖,假设索引覆盖了where条件中的字段,但不是整个查询涉及的字段,mysql5.5和之前的版本也会回表获取数据行,尽管并不需要这一行且最终会被过滤掉。

如上图则无法使用覆盖查询,原因:
1.没有任何索引能够覆盖这个索引。因为查询从表中选择了所有的列,而没有任何索引覆盖了所有的列。
2.mysql不能在索引中执行LIke操作。mysql能在索引中做最左前缀匹配的like比较,但是如果是通配符开头的like查询,存储引擎就无法做比较匹配。这种情况下mysql只能提取数据行的值而不是索引值来做比较

优化后SQL:使用了延迟关联(延迟了对列的访问)。在查询的第一阶段(join 子句中的查询),MySQL可以使用覆盖索引,在FROM子句的子查询中找到匹配的c1,然后根据c1值,在外层查询匹配获取所有的列值。