YOLOv5算法原理与网络结构
1.1 YOLOv5算法
YOLOv5算法共有4种网络结构,分别是YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,这四种网络结构在宽度和深度上不同,原理上基本一样,接下来以 YOLOv5s 为例介绍 YOLOv5网络结构。

图1 YOLOv5网络结构图
YOLOv5s的网络结构如图1所示,该结构分为四个部分输入端、Backbone(主干网络)、Neck网络和Prediction(输出端)。
各部分具有的主要功能结构如下:
输入端:Mosaic数据增强、自适应锚框计算,以及自适应图片缩放。
主干网络:Focus结构、CSP结构。
Neck网络:FPN+PAN结构。
输出端:GIOU_Loss。
1.1.1 输入端
(1) Mosaic数据增强
输入端使用的数据增强方式是Mosaic方式,对数据集合采取随机缩放、随机剪裁、随机排布。
主要有两个优点:
第一,提高了数据集的复杂度:对多张图片,进行随机的缩放以及剪裁,之后再随机分布,进行拼接,使数据集得到极大地丰富,特别是进行随机缩放操作,可以增加许多小目标,训练得到的模型,鲁棒性会更好;
第二,减少 GPU 内存使用:使得 Mini-batch 也就是一个批次从数据集读取进行训练的图片张数,不需要设置的很大,因此,训练时使用一个GPU也能达到比较好的训练效果。
(2) 自适应锚框计算
YOLO系列检测算法中,针对不同目标,都会初始设定好默认长宽的锚框,进行训练时,在初始设定好的锚框基础上,输出一个预测框,将标注的真实框和预测框做对比,并且计算它们的差距,之后再反向更新,迭代网络结构中的参数。在 YOLOv3、YOLOv4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的,但在YOLOv5中将此功能嵌入到算法结构中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
(3) 自适应图片缩放
在目标检测算法中,针对数据集中图片长宽一般不相同的问题,经常是将原始图片先缩放成一个统一的标准尺寸,全部处理后,再送入检测网络中,将长宽800*600的图像进行缩放,使用黑色背景来填充,填充后会出现大区域的黑边。在项目实际使用时,图片的长宽比几乎都不相同,因此缩放填充后,黑边大小都不同,如果填充的比较多,则存在信息冗余,影响网络推理速度。
因此,在最新的 YOLOv5 算法中进行了改进,这也是 YOLOv5算法推理速度能够变快的一个方面。该算法对原始图像进行缩放操作时,可以根据图片尺寸,自适应的添加最少黑边,图像的黑边明显变少了,这样处理后,在推理时,计算量也会得到减少,从而使得网络的目标检测速度会得到提高。
通过这种自适应缩放的优化改进,YOLOv5的推理速度得到了提升,把长宽 800*600 的图像缩放填充为 416*416 尺寸的图像为例,介绍自适应图片缩放的三步:
第一步,计算长宽的缩放比例,将原始图像尺寸 800*600,分别除以缩放后的尺寸 416*416,可以计算出长边的缩放系数为0.52,宽边的缩放系数为0.69。
第二步,选择较小的缩放系数 0.52,将原始图像的长宽都乘以0.52,计算出此时的长边是416,宽边是312。
第三步,计算需要填充的黑色区域,宽边312和需要缩放到的 416相差104,差值除以 2,就得到了两端需要填充的黑色区域的高度。
1.1.2 主干网络
(1) Focus结构
Focus结构中关键的是切片操作,切片操作演示过程,将4×4×3的特征图经过切片处理,变成2×2×12的特征图。将608×608×3 的三通道图像输进 Focus 结构,经过切片操作,先变成304×304×12 的特征图,之后,经过使用 32 个卷积核的卷积操作,最终变成 304×304×32 的特征图。需要注意的是,YOLOv5s网络结构中的 Focus 结构使用32个卷积核,进行卷积操作,而其他三种网络结构,使用的卷积核数量有所增加。
(2) CSP结构
YOLOv5中有两种结构的CSP,CSP1_X结构在Backbone主干网络中,另一种CSP2_X结构在Neck中。对于Backbone的主
干网络结构,CSP 模块中的卷积核大小都是 3*3,步进值为 2,假如输入的图像尺寸是 608*608,那么它的特征图变化的规律
是:608*608 -> 304*304 -> 152*152 -> 76*76 -> 38*38 -> 19*19,最终得到了一个19*19大小的特征图。
使用CSP模块的优点:
一是增强网络的学习能力,使得训练出的模型,既能保持轻量化,又能有较高的准确性。
二是降低计算瓶颈。
三是降低内存成本。
1.1.3 Neck网络
(1) FPN+PAN
FPN 是自顶向下的,通过上采样操作,将高层的特征信息和低层特征进行融合,计算出预测的特征图。YOLOv5网络结构中在FPN层后面,还添加了一个特征金字塔,自下向上,其中有两个PAN 结构,通过下采样操作,将低层的特征信息和高层特征进行融合,输出预测的特征图。
优点:通过自顶向下的FPN层,传达强语义特征,而通过自底向上的特征金字塔,传达强定位特征,从不同的主干层,对不同的检测层,进行参数聚合。
1.1.4 输出端
(1) GIOU_Loss损失函数
目标检测算法的损失函数一般由 Classification Loss(分类损失函数)以及 Bounding Box Regression Loss(回归损失函数)两大部分组成。回归损失函数在近几年的发展过程是:
Smooth L1 Loss -> IOU _Loss(2016)-> GIOU_Loss(2019)-> DIOU_Loss(2020)-> CIOU_Loss(2020)。
假设预测框和真实框的交集为A,并集为B,IOU定义为交集A除以并集B,IOU的Loss为:
IOU_Loss = 1-IOU=1-AB (1)
(1)
IOU的Loss比较简单,但存在两个问题。
问题1:预测框和真实框不相交的情况,此时 IOU 为 0,无法反应出预测框和真实框距离的远近,此时损失函数不能求导,IOU_Loss损失函数无法优化预测框和真实框不相交的情况。
问题 2:当预测框和真实框大小相同,IOU 也可能会相同,此时 IOU_Loss 损失函数也不能区分这两种情况的不同。
因此使用GIOU_Loss来进行改进。令预测框和真实框的最小外接矩形为集合C,差集定义为集合C和并集B的差,则GIOU_Loss为:
GIOU_Loss=1-GIOU=1-(IOU-|差集||C |) (2)
GIOU_Loss损失函数提高了衡量相交尺度的方式,减少了单纯IOU_Loss时的不足。
1.2 YOLOv5网络结构分析
YOLOv5的4种网络结构YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x内容基本一样,只在深度和宽度上不同,通过depth_multiple 和 width_multiple 两个参数来进行控制,其中前者控制网络深度,后者控制网络宽度。现在分析4 种网络结构的差异。
1.2.1 网络结构深度
YOLOv5 网络结构中有两种CSP结构,分别是CSP1和CSP2,其中CSP1结构存在于Backbone主干网络中,CSP2结构存在于Neck网络中,四种网络中每个CSP结构的深度都是不同的。
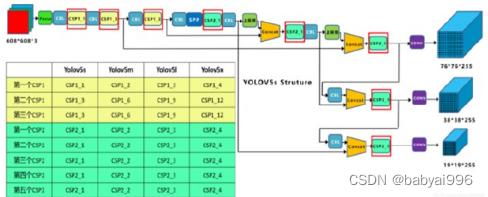
图5 YOLOv5四种网络的CSP结构
以 YOLOv5s为例,第一个CSP1中,使用了1个残差组件,因此是CSP1_1,在YOLOv5m中,增加了网络的深度,在第一个CSP1中,使用了2个残差组件,因此是CSP1_2,YOLOv5l中,同样的位置,则使用了3个残差组件,YOLOv5x中,使用了4个,其余CSP也是同样的原理,使用残差组件的个数如图5所示。
在CSP2结构中,以第一个CSP2结构为例,YOLOv5s中使用了1组2*1等于2的卷积,因此是 CSP2_1,而YOLOv5m中使用了2 组,YOLOv5l中使用了3组,YOLOv5x中使用了4组,其他的四个CSP2结构,同理。YOLOv5的四种网络结构,随着不断加深网络层数,网络的特征提取能力以及特征融合能力也不断提高。
1.2.2 网络结构宽度
如图6可以看出四种网络结构在不同位置,使用的卷积核数量都是不一样的,因此直接影响卷积后特征图的第三维度,即网络的宽度。

图6 YOLOv5四种网络的卷积核个数
以 YOLOv5s的网络结构为例,YOLOv5s网络中的第一个Focus结构,进行卷积操作时,使用的卷积核个数是32个,而YOLOv5m的Focus结构中,使用48个卷积核,进行卷积操作,在YOLOv5l,YOLOv5x中也是同样的原理。卷积核个数越多,特征图的宽度越宽,网络提取特征的学习能力也越强。
2. Deep sort算法原理与网络结构
2.1 deep sort算法
Deepsort在原来Sort算法的基础上,改进了以下内容:
使用级联匹配算法:针对每一个检测器都会分配一个跟踪器,每个跟踪器会设定一个time_since_update参数。
添加马氏距离与余弦距离:实际上是针对运动信息与外观信息的计算。
添加深度学习特征:这一部分也就是ReID的模块,也是deepsort的亮点之一。
代码流程
由于deepsort的流程和算法原理几乎和sort一样,只是说增加了上边三个特色,因此我们直接从代码开始讲起:
2.2 deep sort算法整体流程图
算法的整体流程图如下所示:
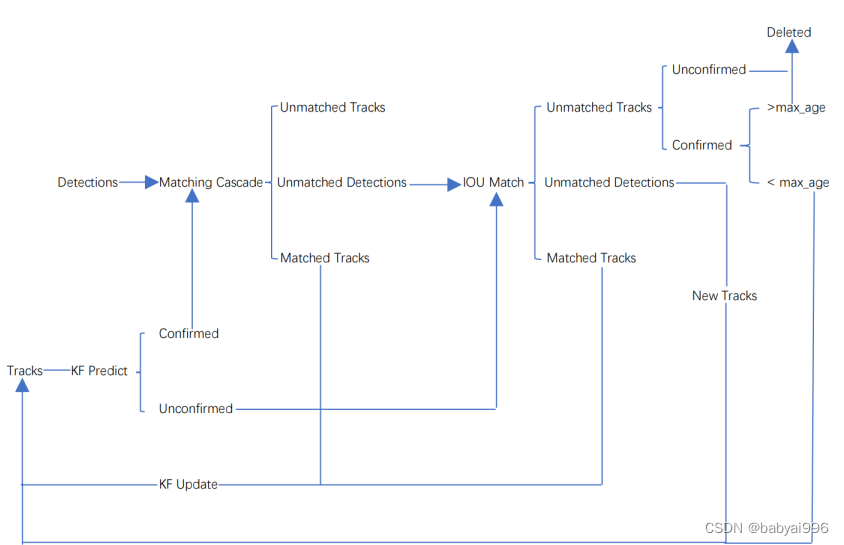
整个算法的工作流程如下:
(1)将第一帧次检测到的结果创建其对应的Tracks。将卡尔曼滤波的运动变量初始化,通过卡尔曼滤波预测其对应的框框。这时候的Tracks一定是unconfirmed的。
(2)将该帧目标检测的框框和第上一帧通过Tracks预测的框框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(3)将(2)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks(因为这个Tracks是不确定态了,如果是确定态的话则要连续达到一定的次数(默认30次)才可以删除)删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(4)反复循环(2)-(3)步骤,直到出现确认态(confirmed)的Tracks或者视频帧结束。
(5)通过卡尔曼滤波预测其确认态的Tracks和不确认态的Tracks对应的框框。将确认态的Tracks的框框和是Detections进行级联匹配(之前每次只要Tracks匹配上都会保存Detections其的外观特征和运动信息,默认保存前100帧,利用外观特征和运动信息和Detections进行级联匹配,这么做是因为确认态(confirmed)的Tracks和Detections匹配的可能性更大)。
(6)进行级联匹配后有三种可能的结果。第一种,Tracks匹配,这样的Tracks通过卡尔曼滤波更新其对应的Tracks变量。第二第三种是Detections和Tracks失配,这时将之前的不确认状态的Tracks和失配的Tracks一起和Unmatched Detections一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(7)将(6)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks(因为这个Tracks是不确定态了,如果是确定态的话则要连续达到一定的次数(默认30次)才可以删除)删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(8)反复循环(5)-(7)步骤,直到视频帧结束。