首先看下平时我们所说的交叉熵:
传送门
在信息论中,交叉熵可认为是对预测分布q(x)用真实分布p(x)来进行编码时所需要的信息量大小。而在机器学习的分类问题中,真实分布p(x)是one-hot形式,表明独属于one-hot中1对应的角标的那个类,因此这也是为什么交叉熵常用于做分类问题的损失函数。
H
(
p
,
q
)
=
∑
x
p
(
x
)
log
1
q
(
x
)
=
−
∑
x
p
(
x
)
log
q
(
x
)
\begin{aligned} H(p, q) &=\sum_{x} p(x) \log \frac{1}{q(x)} \\ &=-\sum_{x} p(x) \log q(x) \end{aligned}
H(p,q)=x∑p(x)logq(x)1=−x∑p(x)logq(x)
那么pytorch里的交叉熵是这样的吗?我们测试下:
pytorch:
import torch
loss = torch.nn.CrossEntropyLoss(reduction = "none")
pred = torch.tensor([[0.0,1.0],[0.4,0.6,],[0.8,0.2]])
label = torch.tensor([1,0,0])
print(loss(pred,label))
# 输出:tensor([0.3133, 0.7981, 0.4375])
手动:
import math
# [0.0,1.0]和[1]
res = -math.log(0.1) = -1 * 0 = 0
# [0.4,0.6,]和[0]
res = -math.log(0.4) = 0.916290731874155
# [0.8,0.2]和[0]
res = -math.log(0.8) = 0.2231435513142097
很显然和通过torch得到的结果不同。那么看下pytorch文档里的交叉熵公式。
torch.nn.CrossEntropyLoss是nn.logSoftmax()和nn.NLLLoss()整合起来的版本,其中NLLLoss()是negative log likelihood loss,负对数似然(损失)函数和交叉熵(损失)函数背后的思想或者说得到的过程有些不同。这里先介绍下“似然”的概念:在机器学习中,似然函数是一种关于模型中参数的函数。“似然性(likelihood)”和"概率(probability)"词意相似,但在统计学中它们有着完全不同的含义:概率用于在已知参数的情况下,预测接下来的观测结果;似然性用于根据一些观测结果,估计给定模型的参数可能值。因此负对数似然函数是希望通过已知的训练数据的标注去找到一组模型的参数,让模型的预测结果贴合训练数据的标注结果,寻找这组模型参数的过程就是模型训练的过程,也是最小化负似然函数的过程;而交叉熵则是熵的概念,即用真实分布编码预测分布时所需要的信息量大小,信息量越小,两个分布越接近,因此最小化这个的过程就是训练模型的过程。
虽然两者背后思想有些不同,但是最后呈现的公式是一样的,即上面提到平时所说的交叉熵公式。
那么nn.NLLLoss()已经可以用来做交叉熵公示了,为什么还要有torch.nn.CrossEntropyLoss呢?这是因为nn.CrossEntropyLoss()是考虑具体训练过程做了优化得到的版本:
在具体训练过程中,假设batch_size=32, num_classes = 10, 那么经过最后的Linear得到一个batch的预测结果的shape为[32,10],其中每条数据在不同类别上的值有可能小于0,且所有类别值加起来不为1,因此这不能算概率值,所以需要softmax。softmax之后结果再取log,这样做的目的是将乘法改成加法减少计算量,同时保障函数的单调性。因此最后将nn.logSoftmax()和nn.NLLLoss()结合得到了nn.CrossEntropyLoss()。
下面看下具体怎么结合的:
torch.nn.NLLLoss:
官方地址
这个
w
n
w_n
wn是focal loss里的α,数据不平衡时用的,因此一般没有
ℓ
(
x
,
y
)
=
L
=
{
l
1
,
…
,
l
N
}
⊤
,
l
n
=
−
w
y
n
x
n
,
y
n
,
w
c
=
\ell(x, y)=L=\left\{l_{1}, \ldots, l_{N}\right\}^{\top}, \quad l_{n}=-w_{y_{n}} x_{n, y_{n}}, \quad w_{c}=
ℓ(x,y)=L={l1,…,lN}⊤,ln=−wynxn,yn,wc= weight
[
c
]
⋅
1
{
c
≠
[c] \cdot 1\{c \neq
[c]⋅1{c= ignore_index
}
\}
}
torch.nn.LogSoftmax:
官方地址
LogSoftmax
(
x
i
)
=
log
(
exp
(
x
i
)
∑
j
exp
(
x
j
)
)
\operatorname{LogSoftmax}\left(x_{i}\right)=\log \left(\frac{\exp \left(x_{i}\right)}{\sum_{j} \exp \left(x_{j}\right)}\right)
LogSoftmax(xi)=log(∑jexp(xj)exp(xi))
因为在NLLLoss()中true label也是one-hot,即只有true label那个类参与计算,因此将NLLLoss()的
x
n
y
n
x_ny_n
xnyn代入logSoftmax分子的
x
i
x_i
xi,得到一个公式,然后再根据log(xy) = logx + logy化简:
1.9.1 pytorch官方地址
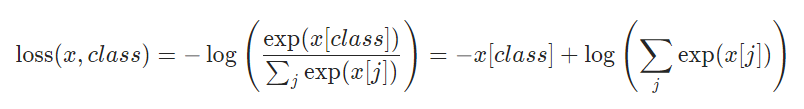
上面用1.9.1的pytorch是因为从1.10.1开始,公式没有展示化简后那步,不便于本文理解,并且1.10.1的交叉熵实现了label smooth。
因此理解上述内容后,根据pytorch的交叉熵公式再计算下:
import math
loss = torch.nn.CrossEntropyLoss(reduction = "none")
# 1.[0.0, 1.0]和[1]
# torch
loss(torch.tensor([[0.0,1.0]]), torch.tensor([1]))
# 输出:tensor([0.3133])
# 手写
-1+math.log(math.exp(0)+math.exp(1))
# 输出:0.3132616875182228
# 2.[0.0, 1.0]和[0]
# torch
loss(torch.tensor([[0.0,1.0]]), torch.tensor([0]))
# 输出:tensor([1.3133])
# 手写
-0+math.log(math.exp(0)+math.exp(1))
# 输出:1.3132616875182228
# 3.[0.0, 0.0, 1.0]和[2]
loss(torch.tensor([[0.0,0.0,1.0]]), torch.tensor([2]))
# 输出:tensor([0.5514])
-1+math.log(math.exp(0)+math.exp(0)+math.exp(1))
# 输出:0.5514447139320509
# 4.模拟一个batch
entroy=torch.nn.CrossEntropyLoss() # reduction默认为mean
input=torch.Tensor([[0.1234, 0.5555,0.3211],[0.1234, 0.5555,0.3211],[0.1234, 0.5555,0.3211],])
target = torch.tensor([0,1,2])
output = entroy(input, target)
print(output)
# 输出:tensor(1.1142)
input=np.array(input)
target = np.array(target)
def cross_entorpy(input, target):
output = 0
length = len(target)
for i in range(length):
hou = 0
for j in input[i]:
hou += np.exp(j)
output += -input[i][target[i]] + np.log(hou)
return np.around(output / length, 4)
print(cross_entorpy(input, target))
# 输出:1.1142
对数似然、负对数似然
交叉熵、负对数似然
pytorch交叉熵公式推导以及代码证明
pytorch交叉熵