预定义变量
$0 脚本名
$* 所有的参数
$@ 所有的参数
$# 参数的个数
$$ 当前进程的PID
$! 上一个后台进程的PID
$? 上一个命令的返回值 0表示成功
for:循环次数是固定的
for i in (取值) 范围{1…20} zhangsan lisi wanger mazi ${array[*]}
for 变量名 [ in 取值列表 ]
do
循环体
done
while 条件测试
do
循环体
done
当条件测试成立(条件测试为真),执行循环体
case num in
模式1) 选项
命令序列1 命令/if语句/for循环……
;;
模式2)
命令序列2
;;
模式3)
命令序列3
;;
*)
无匹配后命令序列
esac
iptables四表五链
四表:
raw 追踪数据包
mangle 对数据包打标记
nat 地址转换
filter 数据包过滤
五链:
PREROUTING 在路由之前 prerouting
INPUT 数据包进入时 input
FORWARD 数据包经过时 forward
OUTPUT 数据包出去时 output
POSTROUTING 在路由之后 postrouting
iptables -t 表 动作 链 匹配条件 -j 目标动作
iptables -t filter -A INPUT -p tcp --dport 22 -s 192.168.222.129 -j REJECT
firewalld
九区:
drop(丢弃)
任何接收的网络数据包都被丢弃,没有任何回复。仅能有发送出去的网络连接。
block(限制)
任何接收的网络连接都被 IPv4 的 icmp-host-prohibited 信息和 IPv6 的 icmp6-adm-prohibited 信息所拒绝。
public(公共)
在公共区域内使用,不能相信网络内的其他计算机不会对您的计算机造成危害,只能接收经过选取的连接。
external(外部)
特别是为路由器启用了伪装功能的外部网。您不能信任来自网络的其他计算,不能相信它们不会对您的计算机造成危害,只能接收经过选择的连接。
dmz(非军事区)
用于您的非军事区内的电脑,此区域内可公开访问,可以有限地进入您的内部网络,仅仅接收经过选择的连接。
work(工作)
用于工作区。您可以基本相信网络内的其他电脑不会危害您的电脑。仅仅接收经过选择的连接。
home(家庭)
用于家庭网络。您可以基本信任网络内的其他计算机不会危害您的计算机。仅仅接收经过选择的连接。
internal(内部)
用于内部网络。您可以基本上信任网络内的其他计算机不会威胁您的计算机。仅仅接受经过选择的连接。
trusted(信任)
可接受所有的网络连接。
配置方法:
三种:firewall-config(图形方式)、firewall-cmd(命令行方式)和直接编辑xml文件
tcp三次握手
客户端向服务端发送一个连接请求,服务端收到请求并回复客户端可以建立连接,然后客户端和服务端就开始正常的交流了。
tcp四次握手
客户端请求服务端断开连接,服务器端确认可以断开,服务器端也发送一个断开连接的请求,客户端也确认可以断开。
NFS和FTP
NFS远程共享存储,借助rpc进行服务端和客户端沟通,但是centos7好像不用装rpc也行;
文件传输协议FTP,基于该协议FTP客户端与服务端可以实现共享文件、上传文件、下载文件,21端口是连接端口,20号端口是传输数据,vsftpd是ftp的进程软件服务(cs架构,ftp服务端,lftp客户端)
四层负载和七层负载的区别?
所谓四层就是基于IP+端口的负载均衡;七层就是基于URL等应用层信息的负载均衡。
http和https的区别?
1,HTTP 未加密的,安全性较差,HTTPS(SSL+HTTP) 数据传输过程是加密的,安全性较好。
2,使用 HTTPS 协议需要到 CA机构申请证书,一般免费证书较少,因而需要一定费用。
3,HTTP 页面响应速度比 HTTPS 快,主要是因为 HTTP 使用 TCP 三次握手建立连接,客户端和服务器需要交换 3 个包,而 HTTPS除了 TCP 的三个包,还要加上 ssl 握手需要的 9 个包,所以一共是 12 个包。
4,http 和 https 使用的是完全不同的连接方式,用的端口也不一样,前者是 80,后者是 443。
5,HTTPS 其实就是建构在 SSL/TLS 之上的 HTTP 协议,所以,要比较 HTTPS 比 HTTP 要更耗费服务器资源。
说说常见的状态码?
15,301永久重定向,302临时重定向;前者是访问的url跳转后地址不变,后者是url跳转后地址不是固定的。403请求被拒绝,404请求的资源不存在。500服务器内部错误.
常见的web服务器由apache和nginx,apache是一款开源的web服务器,广泛使用,主要功能是访问控制和虚拟主机多实例,基于IP,端口和域名。
find的用途
1,find主要是查找文件的,可以针对文件名,文件大小,文件的修改时间,文件类型等查找。还可以结合exec和xargs进行之后的动作处理。
find / -name “.txt" -exec rm -rf {} ;
find / -name ".txt” | xargs -i rm -rf {}
2,打包压缩命令gzip,bzip2,tar
cpu的利用率和负载有什么区别?
回答:cpu的平均负载,指在某段时间,cpu处理进程的数量
回答:cpu的利用率,指的是所有进程,当前占用cpu的百分比
如何挂载磁盘?
首先创建挂载目录
再用mount命令挂载即可
vim /etc/fstab mount -a刷新挂载
取消挂载
umount+挂载路径
磁盘分区方式区分?
MBR <2TB
分区工具:fdisk
一共可以分14个分区(4个主分区,扩展分区,逻辑分区) 例如: 3主 + 1扩展(n逻辑)
MBR 小于2TB的可以。
一块硬盘最多分4个主分区。
查看磁盘lsblk空间-->fdisk创建分区-->文件系统格式化xfs或者ext4格式-->mount挂载使用
GPT >2TB和<2TB
分区工具:gdisk
一共可以分128个主分区
GPT大于小于2TB都可以。
#注意:从MBR转到GPT,或从GPT转换到MBR会导致数据全部丢失!
如何开启路由转发工能?
sysctl.conf #系统配置
vim /etc/sysctl.conf
net.ipv4.ip_forward = 1
保存退出
sysctl -p #生效
什么是进程?
进程是在内存中的表现形式,进程是已启动的可执行程序的运行实例,是程序运行的过程,动态的,有生命周期.
top命令中VSZ和RSS的区别
VSZ:进程占用的虚拟内存空间
RSS:进程占用的物理内存空间
请解释下telnet和ssh的区别
首先他们都是远程连接服务
telnet采用明文传送,不安全。ssh是加密的传输很安全 (个人觉得这是最大的区别)
软硬链接的区别?
1:- 软链接可以跨文件系统,硬链接不可以;
2:- 软链接可以对目录进行连接,硬链接不可以;
3:- 删除源文件之后,软链接失效,硬链接无影响; 4:- 两种链接都可以通过命令 ln 来创建;
5:- ln 默认创建的是硬链接;
6:- 使用 -s 参数可以创建软链接。
7:-软链接的inode的号不一样,硬链接的都一样。
总结创建硬链接是ln,创建软链接是ln -s;软链接可以跨文件系统,可以对目录进行链接,硬链接不行;
硬链接的inode号是一样的,软链接不一样,删除源文件,硬链接无影响,软链接失效。
linode号
磁盘存储文件,存储不成功,可以能是 Inode号不够用了
可以给主管申请 重启一下虚拟机 reboot
Inode号 一共是65536个
磁盘格式和磁盘的分区?
自定义磁盘分区有;
1)/;根分区
2)/swap;交换分区
3)/boot;系统内核
如何做扩容(也就是如何做逻辑卷)
首先用fdisk创建磁盘分区
如何做pv(物理卷)
如何将pv加入到vg(卷组中)
再将vg加入到lv(逻辑卷中)
tcp和udp的区别?
首先他们都是dns域名解析的一种
tcp面向连接 udp面向无连接
tcp安全 udp不安全
tcp的传输速度慢 udp的传输速度块
udp用于网络直播,qq聊天等等
arp协议主要解析mac地址;icmp是ping命令的协议。
对称加密和非对称加密的区别?
对称加密就是加密和解密都是一个私钥
非对称加密就是公钥加密私钥解密
raids磁盘阵列最常用的raid级别:0、1、5、6、10?(磁盘阵列)
raid0的话最少需要2块磁盘,读写速度快,磁盘利用率高,但是没有冗余和校验,容易出现单点故障,数据安全性不高。
raid1的话最少需要2块磁盘,读速度快,写速度比较慢,有冗余校验,磁盘利用率不高,但数据安全性比较高。
raid5的话比较常用,最少需要3块磁盘,读写快,有校验机制,磁盘的利用率比较高,数据安全性比较高。
raid6的话最少需要4块磁盘,是在raid5的基础上增加了双校验的的方式,但是写入速度差,成本高。
redis10的话需要4块,读写速度很快,有冗余,无单点故障,镜像成本高。
常见协议的分类
http(不安全的超文本传输协议)
https(安全的文本传输协议)
ftp(文件传输协议)
stmp(邮件传输协议)
dns(域名解析)
telnet(远程登录协议)
ARP协议(解析mac地址)
icmp协议(ping命令的协议)
VRRP协议(虚拟路由冗余协议,用于keepalived)
iptunnel协议(主要用于LVS的隧道模式)
OSI七层模型
7 应用层; (ssh,http,https,应用)服务都是第七层
6 表示层; (传递报文)
5 会话层; (smtp,ftp,telnet,dns,tftp。。。)
4 传输层; (tcp,udp【传输协议组】)
3 网络层; (icmp协议 【ping命令】)
2 数据链路层;(网络接口协议)
1 物理层; (物理硬件设施)
怎么查看一个磁盘的io
第一种:用 top 命令 中的cpu 信息观察
第二种:用vmstat
第二种:用iostat
如何写计划任务
crontab -e
* * * * * 后面接路径
每周末早上8点重启
0 8 * * 7 reboot
Linux系统如何优化:
1,安全优化
ssh端口不用22号默认端口,使用20022
设置防火墙规则:
如果是nginx服务器,80端口和443端口对外开放;
mysql服务器,3306只能对程序所在的服务器ip地址进行开放
堡垒机JumpServer
重要服务器不允许root用户登录,只允许普通用户登录,而且只允许使用秘钥认证方式登录;
修改/etc/pam.d/login文件,能设置用户冻结策略
2,性能
磁盘:调整文件句柄数vim /etc/security/limits.conf
cpu:调整进程优先级nice值大小,将进程绑定到某个cpu上,能提升cpu处理此进程的效率
内存:内存充分情况下,完全禁用swap分区;内存不充足情况下,启用swap分区策略
mysql数据库专题
1,如何设置弱密码?
弱密码设置validate_password=off添加到/etc/my.cnf
2,数据库如何重置?
如果mysql密码忘记,可以进行数据库重置或则进行重新安装,要是初始化的话第一:停止服务,删除数据库存放目录下的所以内容,rm -rf /var/lib/mysql/*,清除my.cnf内修改的内容,然后重启mysql,查看密码修改密码。
3,数据的编译安装?
数据库的编译安装:清理环境(卸载并删除yum安装的mariadb和mysql)–安装编译环境(如gcc,make,cmake等)–指定mysql为不可登录的系统用户–解压源码包到指定目录下然后cmake配置–编译安装(make && make install)–初始化修改密码–登录验证。
4,数据库存储引擎有哪些?
innodb默认的存储引擎:支持事务,外键,支持锁表和锁行,支持崩溃修复和并发控制。
myisam存储引擎:MyISAM拥有较高的插入、查询速度,支持锁表,不支持锁行,不支持事务。
memory存储引擎:数据主要存储在内存里,因此读写速度很快,数据的安全风险比较大。
innodb,myisam,
innodb支持锁表或锁到表的某一行,更加精确一点,myisam也可以锁表,但只能锁整张表,不能锁表的某一行(锁完表后就只能读不能写)。
数据库的增删改查?
创建表:create table 表名
查看表:select * from 表名
表插入:insert into 表名
修改表:alter table 表名 add 字段 alter table 表名 change 旧的字段 新字段名
删除数据 delete from 表名 where id=1
删除字段 alter table 表名 drop 字段名;
删除表 drop table 表名;
关系型和非关系型?
常见的关系型数据库:mysql/mariadb,sql server,oracle.非关系数据库:redis,mongodb,memcached.
什么是备份和冗余?
备份是文件保存到其他地方,能防止机械故障和认为误操作带来的数据丢失;冗余不是备份,只能防止机器故障带来的数据丢失,例如主备模式和数据库群。
数据库的备份方式有哪些,具体是?
物理备份和逻辑备份
物理备份:备份的是数据库的文件,不受存储引擎影响,常用于大型数据库环境,不能跨版本恢复。备份的文件速度相对较慢,但恢复速度快。主要用到的是xtrbackup 计划任务+脚本,实现自动化备份。
逻辑备份:备份的是增改查sql语句,效率比较低,主要用于中小型数据库。备份速度相对较快,但恢复速度慢。binlog日志,mysqldump。
说一下xtrbackup备份
主要是有完整备份、增量备份、差异备份,完整备份备份所有数据,增量备份备份上一次到现在的数据,差异备份备份与上一次完整备份不同的数据。
我们公司周一做完整备份,周三周天做差异备份,这要脚本结合计划任务进行。
数据库事务特性?
原子性:要么都执行,要么都不执行
一致性:在事务开始之前和完成之后,数据都必须保持一致状态,必须保证数据库的完整性
隔离性:事务与事务间互不影
持久性:事务中通过SQL语句产生的信息会写入到磁盘中
隔离级别?
隔离性四个级别:
读未提交(Read uncommitted),最低级别,任何情况都无法保证。
读提交(read committed),可避免脏读的发生。
可重复读(repeatable read),可避免脏读、不可重复读的发生。
串行化(Serializable),可避免脏读、不可重复读、幻读的发生。
【1】脏读(脏读是指一个事务读取到了另外一个事务未提交的数据)
【2】不可重复读(一个事务读取2次,得到的结果不一致)
【3】幻读(一个事务读取2次,记录数量不一致)
mysql主从集群原理?
主从复制集群实际上是冗余的一种解决方案,可以防止单点故障。主从原理:从库的slave会产生两个线程,i/o线程和sql线程,i/o线程将主库的binlog日志中的sql语句发送到从库,再写入到中继日志中,sql线程会将中继日志中更新的语句读取并执行,从而让保证主从复制数据的一致性。
gtid主从集群原理?
gtid主从复制是基于事务id,与普通的主从复制最大不同有:不需要指定binlog日志的文件名和位置点,MASTER_AUTO_POSTION=1的方式开始复制,并且从库的binlog日志要强制开启,目的是记录执行过的GTID。
GTID的工作原理:
1、master更新数据时,会在事务前产生GTID,一同记录到binlog日志中。
2、slave端的i/o 线程将变更的binlog,写入到本地的relay log中。
3、sql线程从relay log中获取GTID,然后对比slave端的binlog是否有记录。
4、如果有记录,说明该GTID的事务已经执行,slave会忽略。
5、如果没有记录,slave就会从relay log中执行该GTID的事务,并记录到binlog。
mysql主从复制不成功_mysql主从同步失败处理?
注意:show binlog events 来查看一个sql里有多少个event。
#查看同步状态,show slave status \G;
方法一:忽略错误后,继续同步。该方法适用于主从库数据相差不大,或者要求数据可以不完全统一的情况,数据要求不严格的情况
解决:
stop slave;
#表示跳过一步错误,后面的数字可变
set global sql_slave_skip_counter =1;
start slave;
show slave status\G 查看
方式二:备份恢复数据
解决步骤如下:
1.先进入主库,进行锁表,防止数据写入
使用命令:
mysql> flush tables with read lock;
注意:该处是锁定为只读状态,语句不区分大小写
2.mysqldump进行数据备份
#把数据备份到mysql.bak.sql文件
[root@server01 mysql]#mysqldump -uroot -p -hlocalhost > mysql.bak.sql
这里注意一点:数据库备份一定要定期进行,可以用shell脚本或者python脚本,都比较方便,确保数据万无一失
3.查看master 状态
mysql> show master status;
4.把mysql备份文件传到slave,进行数据恢复
#使用scp命令
[root@server01 mysql]# scp mysql.bak.sql root@192.168.128.101:/tmp/
5.停止从库的状态
mysql> stop slave;
6.然后到从库执行mysql命令,导入数据备份
mysql> source /tmp/mysql.bak.sql
7.设置从库同步,注意该处的同步点,就是主库show master status信息里的| File| Position两项
change master to master_host = ‘192.168.128.100’, master_user = ‘rsync’, master_port=3306, master_password=‘’, master_log_file = ‘mysqld-bin.000001’, master_log_pos=3260;
8.重新开启从同步
mysql> start slave;
9.查看同步状态
mysql> show slave status\G 查看:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
好了,同步完成啦。
————————————————
apache专题
apache和nginx的区别?
apache的稳定性比nginx好,但是nginx的并发量要远远大于apache
apache处理请求是阻塞型的,nginx处理请求是异步非阻塞的
高并发下apache的话资源消耗大,处理比较慢,而nginx消耗资源比较少,并且处理比较快
apache擅长处理动态资源,nginx擅长处理静态资源
apache的主配置文件是/etc/httpd/conf/httpd.conf;子配置文件是/etc/httpd/conf.d;默认的网站发布目录/var/www/html.
基于域名的虚拟主机
<virtualhost *:80>
server name www.alan.com
documentroot /web1
</virtualhost>
<directory "/web1">
require all granted
</directory>
<virtualhost *:80>
server name www.haha.com
documentroot /web2
</virtualhost>
<directory "/web2">
require all granted
</directory>
18,apache的访问控制
只允许一部分客户端访问: ALL
<directory "/var/www/html/web">
allowoverride none
require ip 192.168.222.222 可以写IP
require ip 10.0.0.0 可以写网段
</directory>
只拒绝一部分客户端访问:
<directory "/var/www/html/web">
allowoverride none
<requireall>
require not ip 10.0.0.10 192.168.222.131
require all granted
</requireall>
</directory>
拒绝所有人
<directory "/var/www/html/web">
allowoverride none
<requireall>
require all denied
</requireall>
</directory>
nginx专题
什么是pv和uv?
pv页面访问量,uv用户访问数,也叫独立IP访问量
简单说说nginx的优势?
nginx是开源的,轻量级,高性能的,高并发代理服务器,功能丰富,资源消耗少
nginx的主要功能?
nginx的三大功能:
WEB服务器
代理服务器(正向代理和反向代理)
负载均衡器
什么是异步非阻塞?
同步与异步的重点在消息通知的方式上,也就是调用结果通知的方式,同步调用是坐等结果通知,异步调用是等结果通知或者主动询问结果。
阻塞与非阻塞的重点在于进/线程等待消息时候的是挂起状态,还是非挂起状态。阻塞调用是没消息就挂起,有消息就激活工作,非阻塞调用发出后,当前进程/线程不会阻塞,也不会挂起,还积极返回干其他活。
nginx为什么能实现这么多的性能呢?
nginx是高性能高并发高效率的web服务器,并广泛用于反向代理和负载均衡。怎么实现这些性能呢?
第一,nginx工作时,有master主进程和worker工作进程,主进程主要负责调度worker工作进程,worker进程主要处理网络请求;
第二是模块化设计,可以根据业务需求,对功能模块进行修改,满足不同的功能需求。
第三,异步非阻塞,这是nginx获得高并发性能的关键因素,
第四,nginx高性能的代理服务器
nginx编译安装的步骤?
1.安装编译安装所需要的环境(软件包,创建用户)
2.下载编译安装所需要的包(源码包)解压的操作
3.到解压后的目录下进行配置(./configure 配置所需要的参数)【mysql:cmake进行配置】
4.编译 make
5.安装 make install
23,http块中有多个server块,server块中有多个location块
nginx的虚拟主机?
nginx的虚拟主机(基于域名,端口和IP)一台主机可以分成多个虚拟主机,同时对外提供相同的web服务。
server{
listen 80;
server_name www.haha.com
location / {
root /web1;
index index.html index,htm;
}
}
server{
listen 80;
server_name www.alan.com
location / {
root /web1;
index index.html index,htm;
}
}
nginx的代理概念?
正向代理是给客户端代理,反向代理是给后端服务器代理
nginx的负载均衡代理?
负载均衡代理
server {
listen 80;
server_name localhost;
location /{
proxy_pass http://web
}
}
upstream web{
server 192.168.222.131;
server 192.168.222.132;
}
负载均衡的算法有哪些?
轮询,还有加权轮询,根据性能权重来处理请求
ip_hash,同网络的IP固定到后端服务器来处理
url_hash,访问的每个url定向到同一个后端服务器。
还支持热备
1,热备
upstrem web {
server 10.0.0.10;
server 10.0.0.20 backup; 热备
}
2,轮询
upstream web {
server 10.0.0.10;
server 10.0.0.20;
}
3,加权轮询
upstrem web {
server 10.0.0.10 weight=1;
server 10.0.0.20 weight=2;
}
4,ip_hash会让相同的客户端ip请求相同的服务器
upstream web {
server 10.0.0.10;
server 10.0.0.20;
ip_hash;
}
nginx的会话保持?
nginx的会话保持有两种方式:
一是ip_hash算法将同一网段客户端的请求总是发往同一个后端服务器,除非该服务器不可用,ip_hash是基于IP来判断的;sticky_cookie_insert是利用会话亲缘关系将同一客户端的请求总是发往同一个后端服务器,基于cookie来判断的。
nginx的动静分离?
动静分离:加快网站的解析速度,把动态页面和静态页面交给不同的服务器去解析,可以大大降低原来单个服务器处理动静的压力,提高解析速度。
nginx的防盗链?
防盗链就是防止别人网站引用自己网站的图片。
nginx的rewrite?
Rewrite对称URL Rewrite,即URL重写,就是把传入Web的请求重定向到其他URL的过程。比如伪静态http://www.123.com/news/index.php?id=123 使用URLRewrite 转换后可以显示为 完美的http://www.123.com/news/123.html。从安全角度上讲,如果在URL中暴露太多的参数,无疑会造成一定量的信息泄漏,所以静态化的URL地址可以给我们带来更高的安全性。
nginx的模块有哪些?
nginx的内部模块http是协议级别的,server是服务器级别的,location是请求级别的。location 是在 server 块中配置的,根据不同的 URI 使用不同的配置,来处理不同的请求。
nginx的访问日志?
nginx的日志access_log,error_log等。访问日志可以给我们提供很多有价值的数据分析,如可以统计UV和PV,利用awk,uniq,sort,或者awk数组遍历获取。
nginx的性能优化?
两方面:内核优化和nginx自身优化
内核优化/etc/sysctl.conf 来修改内核参数
系统性能优化设置文件句柄 /etc/security/limits.conf
nginx本身优化:
worker进程数量auto自动获取
配置cpu亲和,auto代表自动绑定:减少进程迁移的频率,减少损耗
nginx 进程打开文件的数量
gzip压缩级别1-9提高
定义日志的输出格式
利用ab进行压力请求测试
系统性能优化,系统的文件句柄设置修改,配置文件etc/security/limits.conf 。
进程服务的局部性修改调整,如nginx的配置性能优化,worker进程优化,nginx的文件句柄设置,并发连接数设置,文件压缩设置,nginx的cpu亲和配置,使nginx对于不同的work进程绑定到不同的cpu上,减少进程迁移的频率,从而减少性能损耗,定义日志的输出格式等。利用ab进行压力请求测试。
jenkins工作流程?
jenkins是做
jenkins做持续集成,持续发布的一个工具,首先jenkins是java开发出来的,所以需要Java环境才能运行,我们得配置jdk基础环境,然后我们用的是jenkins的war包,把它放在tomcat的发布目录下,启动tomcat即可启动jenkins。
我们公司用的gitlab,首先jenkins从gitlab仓库上拉取代码,拉到jenkins的工作目录下,然后把这些代码进行编译打包,我们后台开发用的是java语言,这里用到了maven工具进行编译打包,然后把打包出来的war发送到后端服务器上,然后把后端服务器的应用重启一下,这里面涉及到拉取发送的密码问题,我们使用的是秘钥对来实现免密操作。首先jenkins生成密钥对,然后在gitlab上添加ssh公钥,建立连接,然后再把密钥发送给后端服务器,给后端服务器建立连接,这样我们就可以在使用过程中实现免密操作。
我们公司刚开始用jenkns发布的时候,也不太了解,用的方式可能有点普通,就比如,我们发布的版本出现问题时,然后需要进行版本回退,我们需要手动在这个tomcat上面,把新版本的war包替换成老版本的,这样就很不方便,后来了解到jenkins有参数化构建的功能,用了jenkins参数化构建时,我们就和开发进行了沟通嘛,让他们在推送代码到gitlab上的时候打上标签,但是,由于打标签用到tag,他们不怎么乐意,于是就让他们在往gitlab上推送新版本的时候打上版本号和描述信息,然后我们利用参数化构建的选择 修订,然后选择对应版本进行构建就可以了,这里面我们参数化构建选用的是脚本的方式,据我老大说,参数化构建还可以结合ansible剧本,让然这里我只是了解,只在实验环境下构建过一些简单的操作,
对了参数化构建里边还有一个小细节,起初我没考虑到,然后我们老大后来点拨了我一下,就是在设置参数化构建的时候,对版本信息进行倒叙排列,这样在后期回退版本或者其他操作的时候,方便查找。
jenkins也有自动构建的功能,如果使用gitlab,依赖于gitlab的webcook组键,所以要提前下载好jenkins插件。要将jenkins中的url复制到gitlab中的webcook上,可以给予分支变动或者tag的变动,只要有人推送到分支上,就会触发自动构建,如果推送了新版本,也会触发自动构建,这都是jenkins可以做的。
遇到的问题:采用yum安装的jenkins的插件不太完善,安装其他maven工具的时候会存在兼容性问题。我在实验环境中试了试,做后还是选择war包的方式。
什么是mycat?
MyCAT是一个数据库中间件
MyCAT可以实现对数据库的读写分离和分库分表
MyCAT对前端应用隐藏了后端数据库的存储逻辑
mycat配置文件?
mycat服务默认的数据端口是8066,而9066端口则是mycat管理端口
server.xml的配置的什么?
配置系统相关参数:配置mycat的端口,IP地址,队列大小4096,连接数据库的隔离级别设置等
配置用户访问权限
配置SQL防火墙以及SQL拦截功能
schema.xml的配置是什么
配置逻辑库和逻辑表
配置逻辑表所存储的数据节点
配置数据节点所对应的物理数据库服务器信息
LVS介绍?
1,lvs是高性能的四层负载均衡软件,特点是成本低廉,高并发,稳定性强,配置简单,支持多种算法。
2,高并发是指lvs有超强的承载力和并发处理能力,单台可支持上万并发链接请求;
3,稳定性强是它对内存和cpu消耗极地;
4,开源免费,性价比高;
5,LVS配置非常简单,仅需几行命令即可完成配置,也可写成脚本进行管理;
6,支持多种轮调算法,可根据业务场景灵活调配进行使用。
lvs的四种的工作模式:
nat网络地址转换模式;DR直接路由模式;tun隧道模式;full-nat双向转换模式。
NAT:网络地址转换模式,进站/出站的数据流量经过分发器(IP负载均衡,他修改的是IP地址) ,具体来说的话就是客户端请求的数据包目标IP通过lvs转发到后端服务器来处理,然后数据的处理完后再经过lvs把目标IP改为客户端IP,数据回传给客户端。
优点:负载均衡只需要一个合法的IP地址
缺点:扩展性有限,节点服务器增加,负载均衡器会成为架构的瓶颈,大量的请求和响应数据交会于此,速度会变慢。
DR :直接路由模式,只有进站的数据流量经过分发器(数据链路层负载均衡,因为他修改的是目标mac地址),具体就是后端服务器ARP保持静默,网关只接受负载均衡器的请求,lvs修改请求端的目标mac地址为后端服务器的mac地址,后端服务器处理完后直接返给客户端。
优点:负载均衡器也只是分发请求,应答包通过单独的路由方法返回给客户端,支持大多数操作系统。
TUN: 隧道模式,只有进站的数据流量经过分发器,跟DR模式有点类似,
需要所有的服务器支持iptunnel协议,服务器只能局限在linux系统上。
full-nat:双向转换,用的比较少
LVS的算法?
静态算法
静态:只根据算法进行调度
轮叫调度;按顺序轮流分配给后端服务器
加权轮叫:根据服务器的处理能力来调度访问请求。
动态算法
动态:会根据后端服务器的实际连接情况进行分配请求
最少链接;分发给当前处理请求出最少的服务器
加权最少链接;会询问连接最少的服务器负载情况,动态调整,而不是直接分发请求过去。
最少队列调度;只要后端服务器的连接数是0,就立马分配请求。
介绍haproxy?
haproxy高性能的负载均衡软件,与nginx相比,它更专业,做的会更好。
haproxy的特点?
1,支持四层负载和七层负载均衡;
2,支持多种算法,特别是七层负载支持的功能比较丰富。
3,拥有一个功能出色的监控页面,实时了解系统的当前状况。
haproxy配置文件有四大模块?
全局配置块global:对最大连接限制4096,用户,日志等进行配置。
默认配置块default:默认是http七层负载,默认连接数是2048,健康检查连接次数,超时连接时间设置等。
frontend前端配置块,面对用户侧:IP地址和端口设置,访问的url设置。
backed后端服务器配置块:填写真实服务器的IP地址和相关的算法配置等。
haproxy的算法?
动态权重轮询roundrobin ,静态权重轮叫static-rr,最少连接数leastconn,source的hash运算。
介绍一下keepalived?
keepalived高可用,用来防止单点故障。
keepalived工作原理?
以vrrp虚拟路由冗余协议为基础的,当backup收到不到master的vrrp包时就认为它宕机了,这时候vrrp协议会根据优先级重新选择master,来保证集群的高可用。
keepalived三个模块?
keepalived的配置文件主要有三个模块,分别是core、check和vrrp。core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。check负责健康检查,包括常见的各种检查方式。vrrp模块是来实现VRRP协议的。
介绍一下tomcat?
Tomcat服务器是一个免费的开放源代码的Web应用服务器,属于轻量级应用服务器。
目前Tomcat最新版本为10.0,nginx最新的是1.22
tomcat的三个端口?
tomcat自身服务的端口:8005
tomcat和其他应用通信的端口:8009
tomcat给客户端浏览器访问页面使用的端口:8080
tomcat的主目录介绍?
tomcat的主目录:bin目录存放二进制命令的,conf存放配置文件server.xml,logs是日志存放,webapps是网站的默认发布目录,启动日志catalinna.out
部署tomcat:jdk1.8+tomcat8.0+mysql5.7+项目jspgou商城+nginx负载均衡
tomcat多实例?
tomcat多实例:单机多实例端口访问,多实例运行相同的应用(实现负载均衡,支持高并发处理,session问题)
tomcat服务调优?
考虑从内存,并发,缓存,安全,网络,系统等进行入手
1、日志格式配置vim tomcat/conf/server.xml
2,JVM 参数优化(java堆),结合服务器性能设置Xms初始堆大小,-Xmx:最大堆大小
3、开启GC日志vim catalina.sh,GC日志,我们可以了解Java虚拟机内存分配与回收策略。
ELK日志中心集群
elasticsearch集群+logstash业务服务器+kibana展示
es主要是用来存储日志的,logstash主要用来搜集日志,kibana主要用来日志展示的
logstash是怎么实现搜集过滤发送的?
Logstash实现的功能主要依赖对应的插件,依次是input插件是读取文件、filter插件是过滤解析的、output插件是发送到es集群的。也就是说在一个完整的Logstash配置文件中,必须有input插件和output插件。
es怎么保证安全性?
设置集群证书和访问密码,可以防止别人恶意创建节点加入集群。
什么是kafka以及特性是什么?
kafka是一个分布式的消息订阅和发布系统,本质是消息队列
kafka的特性:
1,高吞吐量低延迟,每秒可以处理十几万条消息,延迟只有几毫秒。
2,可扩展性强,kafka集群支持热扩展
3,可靠性强,消息持久化到本地磁盘,并且支持数据备份防止数据丢失
4,容错性强:集群中的某一节点失败,不会影响集群的使用
5,高并发:支持数千客户端同时读写
EFK架构?
EFK集群:elasticsearch集群+filebeat业务服务器+kibana展示
kibana展示<-----elasticsearch集群<-------logstash转发消费者消息<----kafka消息队列集群<-----filebeat搜集日志也是消息的生产者
logstash是日志搜集的工具,filebeat是轻量级的本地文件和日志搜集器,不占用系统资源,即使意外关闭,不会造成日志传输的丢失,重启后,依旧继续执行未完成的工作,但是远端的文件和日志读取不了。
CI/CD持续集成交付发布
git和svn的区别?
1,git是分布式的,svn不是。
2,git是元数据方式存储,svn是按照文件存储的。
3,git的内容完整性比svn好,是因为引用了哈希算法。
单台服务器发布模式?
平滑发布是发布过程中不会影响用户的正常使用
灰度发布是部分用户升级使用新版本,部分用户使用老版本,逐步更新,例如华为的鸿蒙系统跟新就是如此。
多台服务器的发布模式?
蓝绿发布是项目分为AB两组,A组停掉服务,进行新版本部署,B组仍对外提供服务;然后B组停掉服务,进行新版本部署,A组对外提供服务;最后就完成了平滑的无感知发布,需要注意的是需要准备备用的服务器,防止业务的突发造成单点故障。
灰度发布是部分服务升级新版本,部分用户使用老版本,逐步更新扩大范围直到版本更新完毕,发现问题可以及时调整,但是自动化要求高
滚动发布是每次只更新一个或者多个服务,升级完成后再加入生产环境,不断执行这个过程,知道集群中的旧版本全部升级为新版本。节约资源,但时间慢,过程较复杂,
实际工作如何选择?
如果你们运维自动化能力储备不够,肯定是越简单越好,建议蓝绿发布,如果业务对用户依赖很强,建议灰度发布。如果是K8S平台,滚动更新是现成的方案,建议先直接使用。
消息中间件?
消息中间件或者叫消息队列(rabbimq,kafka)
特点:解耦,削峰,扩展性强,冗余存储
消息中间件的两种模式?
p2p模式?
主要有三个角色:消息队列,发送者,接收者。每个消息只有一个消费者,一旦被消费,消息就不再队列中了。如果希望发送的每个消息都会被成功处理的话,那么需要P2P模
pub模式?
主要有三个角色:主题,发布者,订阅者。每个消息可以有多个消费者,如果希望发送的消息可以不被做任何处理、或者只被一个消费者处理、或者可以被多个消费者处理的话,那么可以采用Pub/Sub模型。
rabbimq和kafka的区别?
rabbimq主要面向消息、队列、路由,数据存储的,它的一致性,稳定性,可靠性和安全性比较高,但是性能和吞吐量一般。
kafka主要用于日志的收集和传输,对消息的重复丢失错误没有严格要求,但是吞吐量是其最大的特色。
rabbimq的特点?
可靠,灵活,扩展性,高可用,支持多种协议等
rabbimq的端口?
15627是web界面的访问端口
25672是rabbitmq的自身端口
5672程序客户端连接rabbitmq的通信端口
rabbitmq 集群模式是?
普通模式?
默认模式,以两个节点为例,消息出口总在其中的一个节点上,会产生瓶颈;如果没有持久化,会产生消息丢失现象。
镜像模式?
高可用模式,消息实体会主动在镜像节点间同步,该模式可以解决普通模式的问题,但是不足是,镜像队列太多,大量的消息进入,系统性能会降低。
mysql和redis的区别对比?
1,从类型上来说,MySQL是关系型数据库,Redis是非关系型缓存数据库
2,mysql数据存放到磁盘中,redis存放在缓存中
3,mysql支持表结构,支持复杂的表查询。
4,mysql偏重于存储数据,redis偏重于读取数据,因此热门的数据放redis上,mysql存放基本的数据。
memcache,redis,mongodb区别?
memcache数据结构单一,只支持内存服务,不支持持久化,数据不能备份,重启后数据全部丢失。
redis支持多种数据类型,数据可以做持久化,可以做主从复制和备份,读写性能优异。
mongodb是文档型非关系型数据库,支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富,因此查询功能比较强大
https://cloud.tencent.com/developer/article/1676767(三者区别详解)
redis的持久化存储方式有两种?
RDB:根据不同的时间点,将数据已快照的方式存入磁盘
AOF:主要是记录redis的指令,实时性完整性好,但是体积大
若RDB和AOF两种同时使用的话,优先采用AOF方式恢复数据,因为所有的指令都可以恢复回来,恢复的完整度好
redis的数据类型?
redis的端口6379
数据类型说明:
string(字符串)做访问计数,
hash(哈希字典),适用于存储对象
list(列表)做简单的消息队列,
set(集合)有去重功能
zset(有序集合)做排行榜应用
redis的哨兵模式?
Redis Sentinel(哨兵)实现 Redis 的高可用性(通过ping发送消息来判断连通性)
redis哨兵模式主观下线和客观下线(网络延迟)?
主观下线:只有一个哨兵节点认为主节点不可用
客观下线:主服务器故障时,哨兵会询问其他的哨兵节点主服务器的状态,超过半数以上就认为主服务器不可达,判定为客观下线。简单来说半数以上的节点认为某节点不可用,就是主观下线。
Redis-cluster去中心化集群?
Redis-cluster去中心化集群中有16384个哈希槽,每个redis实例负责一部分槽点,集群中的所有信息通过节点数据交换更新。一个hash 槽点会有很多键值对。
https://blog.csdn.net/weixin_43451430/article/details/115708479
为什么使用Redis-cluster去中心化集群?
Redis Cluster的架构,是属于分片集群的架构,当遇到内存、并发、流量等瓶颈时,就可以使用。而redis本身在内存上操作,不会涉及IO吞吐,即使读写分离也不会提升太多性能,Redis在生产上的主要问题是考虑容量,单机最多10-20G,key太多降低redis性能.因此采用分片集群结构,已经能保证高性能。其次,用上了读写分离后,还要考虑主从一致性,主从延迟等问题,徒增业务复杂度。
redis的雪崩,穿透,击穿?
什么是雪崩?
简单来说雪崩:高峰值的极限请求造成数据库缓存全盘宕机,从而数据库
也扛不住宕机,
雪崩怎么解决?
事前:redis高可用,主从+哨兵,redis cluster多主多从,避免全盘
崩溃。
事中:本地ehcache缓存+hystrix限流&降级,避免MySQL被打死。
事后:redis持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存
数据。
什么是穿透?
简单来说:恶意的高并发请求越过数据库缓存redis,直奔数据库,造成数据库
宕机。
穿透怎么解决?
解决方式很简单,每次系统 A 从数据库中只要没查到,就写一个空值到
缓存里去,比如 set -999 UNKNOWN。然后设置一个过期时间,这样的话,
下次有相同的 key 来访问的时候,在缓存失效之前,都可以直接从缓存
中取数据。
什么是击穿?
缓存击穿,就是说某个 key 非常热点,访问非常频繁,处于集中式
高并发访问的情况,当这个 key 在失效的瞬间,大量的请求就击穿了
缓存,直接请求数据库,就像是在一道屏障上凿开了一个洞。
解决方案?
解决方式也很简单,可以将热点数据设置为永远不过期
什么是ansible?
ansible是基于python开发的,基于ssh工作的,分布式的,轻量级,无需客户端的自动化运维工具,可以实现批量化的系统配置,服务部署,命令运行等。
ansible怎么部署?
部署简单,所有机子做解析,master发送公钥给其他被控制节点,就可以完成。
在主机清单里/etc/ansible/hosts添加被控制节点IP主机名或者域名,也可以自定义创建主机组。
ansible的模块都有哪些?
有很多命令模块:
shell模块;copy复制模块;yum下载模块;service服务管理模块;启动停止重启等;file文件模块
playbook剧本:执行批量化复杂的操作指令
vim handlers.yml
- hosts: web1
user: root
tasks:
- name: test copy
copy: src=/root/a.txt dest=/mnt
notify: test handlers #通知的意思
handlers:
- name: test handlers
shell: echo “abcd” >> /mnt/a.txt
ansible的5大核心元素?
files存储文件
variables变量元素:存放定义变量的文件
tasks任务元素:专门存储任务的目录,
templates模板元素:调用存储在该目录下的变量配置文件
handlers触发器:前一个任务执行成功后,才触发执行后面的任务
zabbix的优缺点?
zabbix优点有哪些?
开源,无软件成本投入
Server 对设备性能要求低
支持设备多,自带多种监控模板
支持分布式集中管理,有自动发现功能,可以实现自动化监控
开放式接口,扩展性强,插件编写容易
Api 的支持,方便与其他系统结合
缺点:
所有数据都存在数据库里, 产生的数据据很大,瓶颈主要在数据库。因此监控项历史数据保存选择30天
监控的对象有哪些?
zabbix监控系统监控对象(数据库,应用软件,集群,虚拟化软件,操作系统,硬件设备,网络)
监控的模式?
默认是被动模式,server向agent请求获取监控的数据;
主动模式是主动地将监控数据发送给server。
zabbix都有什么动作?
触发器动作,自动发现
Zabbix Proxy 代理服务器?
Zabbix Proxy 代理服务器,可代替zabbix服务器搜集数据,分担负载压力,主要用于跨区域
Zabbix监控项?
预定义参数监控项,自定义用户参数UserParameter,用zabbix_get相关命令查看能否获取值
系统参数获取?
vim /proc/meminfo可以得到linux内核的很多详细参数,再结合脚本,获取监控项
zabbix监控nginx?
预定义监控nginx服务端口?
通过预定义监控项监控80端口(主机组-主机-监控项-图形-聚合图像-触发器-动作-媒介类型等)
自定义监控nginx其他监控项?
首先安装ngx_http_stub_status_module,这个模块提供了基本的监控功能的数据
其次修改nginx的配置文件后,打开server {
listen 80;
server_name localhost;
location /nginx-status {
stub_status on;
access_log on;
}
}
用curl 10.0.0.19/nginx_status测试是否可以获取想要的监控数据。
然后是脚本编写:通过定义函数和使用case
最后通过userparemeter编写自定义监控值,再server端通过zabbix_get -s 获取值后,把监控的项写入监控项中。
监控Nginx活动连接数,监控Nginx处理连接数,监控Nginx处理请求总数等等
监控Nginx活动连接数,vim /etc/zabbix/zabbix_agentd.d/nginx_status.conf
UserParameter=Nginx.Active.Connections,/usr/bin/curl -s http://10.8.165.27/ngx_status 2>/dev/null |grep ‘Active connections:’|awk ‘{print $NF}’
自定义监控tomcat服务的三个端口?
写一个脚本监听Tomcat的端口
Vim tomcat_monitor.sh
判断8005、8009、8080端口服务是否正常
zabbix监控redis主从集群?
预定义监控redis服务端口?
通过预定义监控项监控6379端口(主机组-主机-监控项-图形-聚合图像-触发器-动作-媒介类型等)
自定义监控redis其他监控项?
redis-cli -h 127.0.0.1 -p 6379 info 该命令可以查看集群详细信息可以获取,如cpu使用,内存使用等
通过用户参数UserParameter结合脚本的方式获取对应的监控项,用zabbix_get命令查看获取的值
zabbix监控mysql主从集群?
预定义监控mysql服务端口?
通过预定义监控项监控3306端口(主机组-主机-监控项-图形-聚合图像-触发器-动作-媒介类型等)
自定义监控mysql的IO/SQL线程数量?
自定义监控IO/SQL线程,获取的结果是2个yes,表示正常,vim /etc/zabbix/zabbix_agentd.d/status.conf
UserParameter=mysql.status,mysql -u root -e “show slave status\G” | grep -E ‘Slave_IO_Running: Yes|Slave_SQL_Running: Yes’ | grep -c Yes
自定义监控mysql是否存在延迟?
自定义监控主从是否存在延迟,获取的结果是0,表示正常,vim /etc/zabbix/zabbix_agentd.d/status.conf
UserParameter=mysql.ab,ysql -u root -e “show slave status\G” | grep SQL_Delay | awk -F : ‘{print $2}’
zabbix 自定义发现是怎么做的?
1、首先需要在模板当中创建一个自动发现的规则,这个地方只需要一个名称和一个键值。
2、过滤器中间要添加你需要的用到的值宏。
3、然后要创建一个监控项原型,也是一个名称和一个键值。
4、然后需要去写一个这样的键值的收集。
自动发现实际上就是需要首先去获得需要监控的值,然后将这个值作为一个新的参数传递到另外一个收集数据的item里面去。
zabbix 是怎么微信报警的?
1、首先,需要有一个微信企业号。(一个实名认证的[微信号]一个可以使用的[手机号]一个可以登录的[邮箱号]
2、下载并配置微信公众平台私有接口。
3、配置Zabbix告警,(增加示警媒介类型,添加用户报警媒介,添加报警动作)。
zabbix 监控了多少客户端 客户端是怎么进行批量安装的?
根据实际公司台数回答。
1、使用命令生成密钥。
2、将公钥发送到所有安装zabbix客户端的主机。
3、安装 ansible 软件,(修改配置文件,将zabbix 客户机添加进组)。
4、创建一个安装zabbix客户端的剧本。
5、执行该剧本。
6、验证。
容器管理工具docker-compose?
docker-compose 通过一个配置文件来管理多个Docker容器,在配置文件中,所有的容器通过services来定义,然后使用docker-compose脚本来启动,停止和重启应用
微信小程序上的不同组件和模块可以通过docker容器来运行,微服务。开发或者测试需要的环境都可以用docker来部署相应的环境。
服务器很卡?
使用top命令去查看,top结果:MySQL进程占用内存最大
解决思路:
1.MySQL进程绝对不能杀死,
2.进去MySQL数据库里面,show processlist显示出正在执行的sql语句,而且会有执行时长,
3.如果有超过5s还未执行完成的sql语句,sql语句截图,发到群里,询问负责sql语句的开发人员是否可以杀死
实际工作中遇到过哪些问题?
Zabbix企业微信报警接受不到消息?
检测发现部门和成员,只选择拉成员,没有选择部门id
keepalived(vip不漂移)?
测试环境中:
keepalived高可用的时候,发现出现vip不漂移现象
仔细检测发现从节点的keepalived配置文件里面,优先级没有调,不抢占资源,修改之后发现在VIP可以漂移拉,但是杀死mysql进程的时候发现还是不能漂移公网,仔细检测是shell脚本里面,root用户不支持远程登录服务,换普通用户即可
Jenkins构建项目,版本不知道怎么回退?
Jenkins构建项目,本来无法进行版本回退。这会导致新版本上线之后,如果出现问题,无法立即回退版本。
后来采用了Jenkins基于git tag参数化构建。解决这个问题;
raids磁盘阵列最常用的raid级别:0、1、5、6、10?
raid0的话最少需要两块磁盘,读写速度快,磁盘利用率高,但是没有冗余和校验,容易出现单点故障,数据安全性不高。
raid1的话最少需要两块磁盘,读速度快,写速度比较慢,无数据校验,磁盘利用率不高,数据安全性比较高。
raid5的话比较常用,最少需要三块磁盘,读写高,有校验机制,磁盘的利用率比较高,数据安全性比较高。
raid6的话是在raid5的基础上增加了双校验的的方式,但是写入速度差,成本高。
简单说说华为云和阿里云?
华为云:ECS弹性云服务器,RDS云数据库,OBS对象存储,ELB弹性负载均衡,CDN内容分发网络
阿里云:ECS弹性云服务器,RDS云数据库,OSS对象存储,SLB弹性负载均衡,CDN内容分发网络
k8s介绍
yaml文件释义?
apiversion: apps/v1 #指定api版本标签】
kind: Deployment
#定义资源的类型/角色】,deployment为副本控制器,此处资源类型可以是Deployment、Job、Ingress、Service等
metadata : #定义资源的元数据信息,比如资源的名称、namespace、标签等信息
name: nginx-demo1 #定义资源的名称,在同一个namespace空间中必须是唯一的
labels: #定义资源标签(Pod的标签)
app: nginx
spec: #定义deployment资源需要的参数属性,诸如是否在容器失败时重新启动容器的属性
replicas: 3 #定义副本数量
selector: #定义标签选择器
matchLabels : #定义匹配标签
app: nginx #匹配上面的标签,需与上面的标签定义的app保持一致
template: #【定义业务模板】,如果有多个副本,所有副本的属性会按照模板的相关配置进行匹配
metadata:
labels:
app: nginx
spec:
containers: #定义容器属性
- name: nginx #定义一个容器名,一个- name:定义一个容器
image: nginx:1.15.4 #定义容器使用的镜像以及版本
imagePullPolicy: IfNotPresent #镜像拉取策略
ports:
- containerPort: 80 #定义容器的对外的端口
master作用?
Master主要负责资源调度,控制副本,提供统一访问集群的入口。
node节点作用?
Node是Kubernetes集群架构中运行Pod的服务节点。
Node用来承载被分配Pod的运行,是Pod运行的宿主机,由Master管理,
并汇报容器状态给Master,同时根据Master要求管理容器生命周期。
node节点的IP?
Node节点的IP地址,是Kubernetes集群中每个节点的物理网卡的IP地址,
是真是存在的物理网络,所有属于这个网络的服务器之间都能通过这个网络直接通信;
什么是pod?
Pod是k8s进行创建、调度和管理的最小单位,一个Pod可以包含一个容器或者多个相关容器。 Pod 就是 k8s 集群里的"应用";而一个平台应用,可以由多个容器组成。
什么是pause?
每个Pod中都有一个pause容器,pause容器做为Pod的网络接入点,Pod中其他的容器会使用容器映射模式启动并接入到这个pause容器。
属于同一个Pod的所有容器共享网络的namespace。
如果Pod所在的Node宕机,会将这个Node上的所有Pod重新调度到其他节点上
什么是pod volume?数据卷挂载
pod volume是数据卷挂载
什么是namespace?
命名空间将资源对象逻辑上分配到不同Namespace,可以是不同的项目、用户等区分管理,并设定控制策略,从而实现多租户。命名空间也称为虚拟集群。
什么是RC-Replication Controller?
Replication Controller用来管理Pod的副本数量的,保证集群中存在指定数量的Pod副本。集群中副本的数量大于指定数量,则会停止指定数量之外的多余pod数量,反之,则会启动少于指定数量个数的容器,保证数量不变。Replication Controller是实现弹性伸缩、动态扩容和滚动升级的核心。
什么是deployment?
Deployment是一个更高层次的API/资源对象,可以说是RC的升级版本吧,它管理ReplicaSets和Pod,并提供声明式更新等功能。是控制副本创建的数量,不能多也不能少。
什么是service?
Service定义了Pod的逻辑集合和访问该集合的策略,是真实服务的抽象。Service提供了一个统一的服务访问入口以及服务代理和发现机制,用户不需要了解后台Pod是如何运行。
一个service定义了访问pod的方式,就像单个固定的IP地址和与其相对应的DNS名之间的关系。
什么是Label?
Kubernetes中的任意API对象都是通过Label进行标识,Label的实质是一系列的K/V键值对。Label是Replication Controller和Service运行的基础,二者通过Label来进行关联Node上运行的Pod。
注:Node、Pod、Replication Controller和Service等都可以看作是一种"资源对象",几乎所有的资源对象都可以通过Kubernetes提供的kubectl工具执行增、删、改、查等操作并将其保存在etcd中持久化存储。
master组件有哪些?
Kubernetes Master:
集群控制节点,负责整个集群的管理和控制,基本上Kubernetes所有的控制命令都是发给它,它来负责具体的执行过程,我们后面所有执行的命令基本都是在Master节点上运行的;
包含如下组件:
1.Kubernetes API Server
主要用于集群内部通信。
2.Kubernetes Scheduler
负责集群的资源调度,为新建立的Pod进行节点分配。
3,etcd是整个集群的后台数据库,是以键值对的方式存储数据。
4,kube-controller-manager负责运行控制器进程。
5,Kubernetes Controller
负责执行各种控制器,目前已经提供了很多控制器来保证Kubernetes的正常运行。
- Replication Controller:管理维护Replication Controller,保证定义的副本数量与实际运行Pod数量一致。
- Deployment Controller
管理维护Deployment,关联Deployment和Replication Controller,保证运行指定数量的Pod。当Deployment更新时,控制实现Replication Controller和Pod的更新。
-
Node Controller
管理维护Node,定期检查Node的健康状态,标识出(失效|未失效)的Node节点。
-
Namespace Controller
管理维护Namespace,定期清理无效的Namespace,包括Namesapce下的API对象,比如Pod、Service等。
-
Service Controller
管理维护Service,提供负载以及服务代理。
-
EndPoints Controller
管理维护Endpoints,关联Service和Pod,创建Endpoints为Service的后端,当Pod发生变化时,实时更新Endpoints。
-
Service Account Controller
管理维护Service Account,为每个Namespace创建默认的Service Account,同时为Service Account创建Service Account Secret。
-
Persistent Volume Controller
管理维护Persistent Volume和Persistent Volume Claim,为新的Persistent Volume Claim分配Persistent Volume进行绑定,为释放的Persistent Volume执行清理回收。
-
Daemon Set Controller
管理维护Daemon Set,负责创建Daemon Pod,保证指定的Node上正常的运行Daemon Pod。
- Job Controller
管理维护Job,为Jod创建一次性任务Pod,保证完成Job指定完成的任务数目
- Pod Autoscaler Controller
实现Pod的自动伸缩,定时获取监控数据,进行策略匹配,当满足条件时执行Pod的伸缩动作。
Kubernetes Node:
除了Master,Kubernetes集群中的其他机器被称为Node节点,Node节点才是Kubernetes集群中的工作负载节点,每个Node都会被Master分配一些工作负载(Docker容器),当某个Node宕机,其上的工作负载会被Master自动转移到其他节点上去;
包含如下组件:
1.Kubelet
负责管控容器,Kubelet会从Kubernetes API Server接收Pod的创建请求,启动和停止容器,监控容器运行状态并汇报给Kubernetes API Server。
2.Kubernetes Proxy
负责为Pod创建代理服务,Kubernetes Proxy会从Kubernetes API Server获取所有的Service信息,并根据Service的信息创建代理服务,实现Service到Pod的请求路由和转发,从而实现Kubernetes层级的虚拟转发网络。
3.Docker Engine(docker),Docker引擎,负责本机的容器创建和管理工作;
4.Flannel网络插件
什么是数据库?
etcd数据库,可以部署到master上,也可以独立部署
分布式键值存储系统。用于保存集群状态数据,比如Pod、Service等对象信息
Kubernetes集群如何部署?
1、Kubernetes集群部署架构规划
2、部署Etcd集群
3、在Node节点安装Docker
4、部署Flannel网络插件
5、在Master节点部署组件
6、在Node节点部署组件
7、查看集群状态
8、运行一个测试示例
9、部署Dashboard(Web UI)
Kubernetes的基本操作命令?
在master查看集群状态:kubectl get nodes 或者kubectl get cs
创建:kubectl create/apply -f *.yaml
查看命名空间:kubectl get all -n kube-system
查看指定命名空间的服务:kubectl get svc -n kube-system
查看pod:kubectl get pods
查看pod详细信息:kubectl describe pod nginx-64f497f8fd-fjgt2
查看servic:kubectl get svc
查看节点:kubectl get nodes
查看pods:kubectl get pods -n kube-system
查看异常pod信息:kubectl describe pods kube-flannel-ds-sr6tq -n kube-system
删除异常pod:kubectl delete pod kube-flannel-ds-sr6tq -n kube-system
删除节点:kubectl delete node kub-k8s-node1
查看某一个节点:kubectl get node kub-k8s-node1
查看node的详细信息:kubectl describe node kub-k8s-node1
查看service的信息:kubectl get service
在不同的namespace里面查看service:kubectl get service -n kube-system
查看所有名称空间内的资源:kubectl get pods --all-namespaces
同时查看多种资源信息:kubect get pod,svc -n kube-system
查看主节点:kubectl cluster-info
api查询:kubectl api-versions
创建并启动yaml文件:kubectl create/apply -f nginx.yml配置文件
配置文件更改后重新创建的话用apply
Kubernetes的yaml文件释义?
apiVersion: v1 #api版本
kind: Namespace #类型—固定的
metadata: #元数据
name: ns-monitor #起个名字
labels: #标签
name: ns-monitor #标签名字
注意:YAML文件,对应到k8s中,就是一个API Object(API 对象)。当你为这个对象的各个字段填好值并提交给k8s之后,k8s就会负责创建出这些对象所定义的容器或者其他类型的API资源。
[root@kub-k8s-master prome]# vim pod.yml
apiVersion: v1 #api版本,支持pod的版本
kind: Pod #Pod,定义类型注意语法开头大写
metadata: #元数据
name: website #这是pod的名字
labels:
app: website #自定义,但是不能是纯数字
spec: #指定的意思
shareProcessNamespace: true #true共享进程名称空间,false是关闭。Pod 中的容器要共享宿主机的 Namespace,是 Pod 级别的定义。
hostNetwork: true #共享宿主机网络
hostIPC: true #共享ipc通信
hostPID: true #共享宿主机的pid
nodeName: node1 #指定容器运行在node1上
containers: #定义容器
- name: test-website #容器的名字,可以自定义
image: daocloud.io/library/nginx #镜像
ports:
- containerPort: 80 #容器暴露的端口
lifecycle:
postStart: #容器启动之后
exec:
command: [“/bin/sh”, “-c”, “echo Helloword > /usr/share/message”]
preStop: #容器关闭之前
exec:
command: [“/usr/sbin/nginx”,“-s”,“quit”]
- name: busybos #容器的名字,可以自定义
image: daocloud.io/library/busybox #镜像
stdin: true
tty: true
nodeSelector: #指定标签
kubernetes.io/hostname: kub-k8s-node1 #这个pod只能运行在node1上,要是 nodeName设置了其他节点,那么就会运行失败
hostAliases: #定义Pod 的 hosts 文件(比如 /etc/hosts)里的内容,在 k8s 中,如果要设置 hosts 文件里的内容,一定要通过这种方法
- ip: “10.0.0.200” #给哪个ip做解析,实验环境下这个ip自定义的
hostnames: #主机
- “www.haha.com” #解析的名字,用引号引起来可以写多个,创建后查看的话kubectl exec -it nginx-pod0 /bin/bash
- “www.alan.com”
pod的查看删除?
查看pod运行在哪台机器上:kubectl get pods -o wide
查看pod的详细信息----指定pod名字:kubectl get pod nginx-pod -o yaml
进入容器内部:kubectl exec -it nginx-pod /bin/bash或者kubectl exec -it nginx-pod /bin/sh
删除容器:kubectl delete -f pod.yml或者kubectl delete pod nginx-pod
删除所有pod:kubectl delete pod --all
指定容器运行在节点1上:nodeName: node1
注意:create与apply的区别:
create创建的应用如果需要修改yml文件,必须先指定yml文件删除,在创建新的pod。
如果是apply创建的应用可以直接修改yml文件,继续apply创建,不用先删掉。
使用YAML用于K8s的定义的好处:
便捷性:不必添加大量的参数到命令行中执行命令
可维护性:YAML文件可以通过源头控制,跟踪每次操作
灵活性:YAML可以创建比命令行更加复杂的结构
YAML语法规则:
1. 大小写敏感/区分大小写
2. 使用缩进表示层级关系
3. 缩进时不允许使用Tab键,只允许使用空格
4. 缩进的空格数不重要,只要相同层级的元素左侧对齐即可
5. " 表示注释,从这个字符一直到行尾,都会被解析器忽略
Pod 扮演的是传统环境里"虚拟机"的角色。是为了使用户从传统环境(虚拟机环境)向 k8s(容器环境)的迁移,更加平滑。
把 Pod 看成传统环境里的"机器"、把容器看作是运行在这个"机器"里的"用户程序",那么很多关于 Pod 对象的设计就非常容易理解了。
凡是调度、网络、存储,以及安全相关的属性,基本上是 Pod 级别的。
"Containers"和"Init Containers"这两个字段都属于 Pod 对容器的定义,内容也完全相同,只是 Init Containers 的生命周期,会先于所有的 Containers,并且严格按照定义的顺序执行.
Docker中Image(镜像)、Command(启动命令)、workingDir(容器的工作目录)、Ports(容器要开发的端口),以及 volumeMounts(容器要挂载的 Volume)都是构成 k8s 中 Container 的主要字段。
ImagePullPolicy 字段:定义镜像的拉取策略。是一个 Container 级别的属性。
策略是:
Always:表示每次创建 Pod 都重新拉取一次镜像。
Never:表示Pod永远不会主动拉取这个镜像。
IfNotPresent:表示只在宿主机上不存在这个镜像时才拉取。
secret和configmap
1,Secret:保存敏感的数据,可用与加密数据库的用户名密码
2,ConfigMap:
ConfigMap是一种API对象,用来将非加密数据保存到键值对中。可以用作环境变量、命令行参数或者存储卷中的配置文件。ConfigMap可以将环境变量配置信息和容器镜像解耦,便于应用配置的修改。如果需要存储加密信息时可以使用Secret对象。
使用ConfigMap有三种方式,一种是通过环境变量的方式,直接传递pod,另一种是通过在pod的命令行下运行的方式,第三种是使用volume的方式挂载入到pod内。
作为volume挂载使用。
创建ConfigMap的方式有4种:
命令行方式,指定文件,指定目录的方式,卷挂载的方式
方式1:通过直接在命令行中指定configmap参数创建,即–from-literal
方式2:通过指定文件创建,即将一个配置文件创建为一个ConfigMap,–from-file=<文件>
方式3:通过指定目录创建,即将一个目录下的所有配置文件创建为一个ConfigMap,–from-file=<目录>
方式4:事先写好标准的configmap的yaml文件,然后kubectl create -f 创建
当ConfigMap以数据卷的形式挂载进Pod时,更新ConfigMap(或删掉重建ConfigMap),Pod内挂载的配置信息会热更新,但使用环境变量方式加载到pod,则不会自动更新
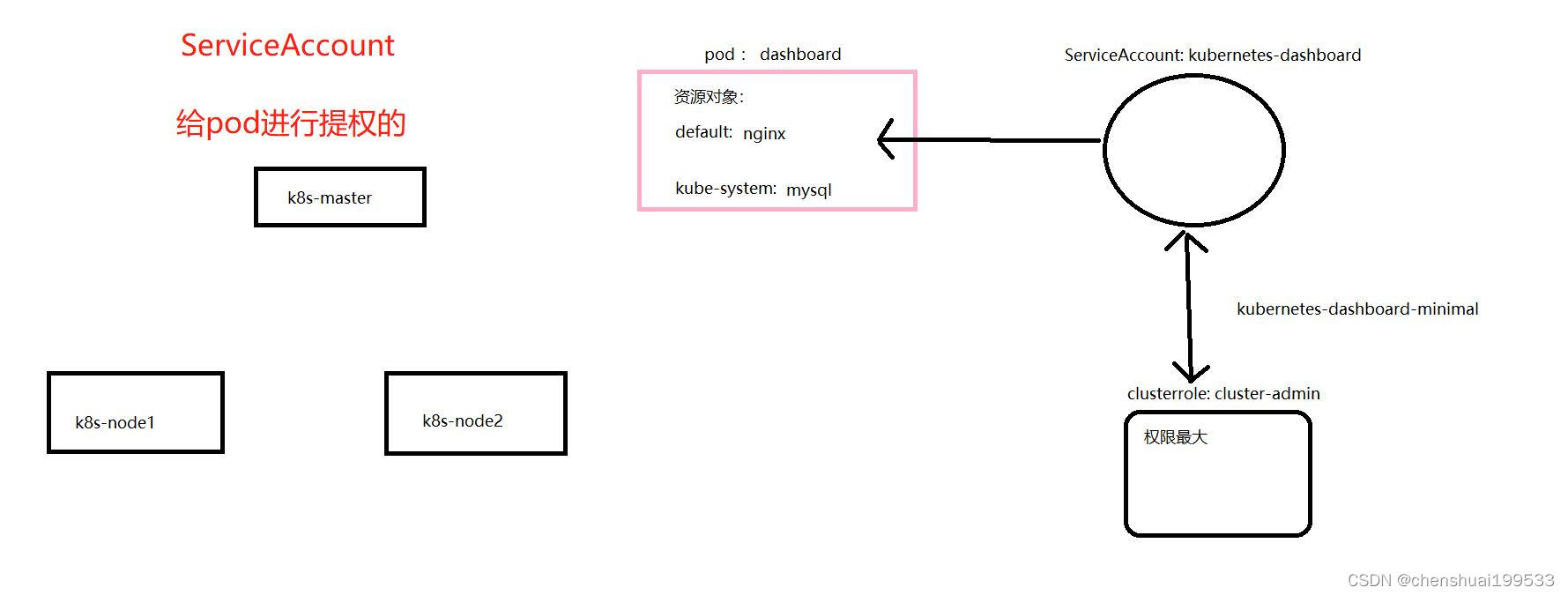
ServiceAccount
Service Account为服务提供了一种方便的认证机制,Service Account它并不是给kubernetes集群的用户使用的,而是给pod里面的进程使用的,它为pod提供必要的身份认证。----专门为pod里面的进程和apiserver通信提供认证。
RBAC 详解(基于角色的访问控制)
RBAC来为Service Account来鉴定授权的。
在RBAC API中,通过如下的步骤进行授权:
1)定义角色role:在定义角色时会指定此角色对于资源的访问控制的规则;
2)绑定角色:将主体与角色进行绑定,对用户进行访问授权。
容器监控检查及恢复机制
在 k8s 中,可以为 Pod 里的容器定义一个健康检查"探针"(Probe)。kubelet 就会根据这个 Probe 的返回值决定这个容器的状态,而不是直接以容器是否运行(来自 Docker 返回的信息)作为依据。这种机制,是生产环境中保证应用健康存活的重要手段。
Pod 的恢复策略:
可以通过设置 restartPolicy,改变 Pod 的恢复策略。一共有3种:
1. Always: 在任何情况下,只要容器不在运行状态,就自动重启容器。
2. OnFailure: 只在容器异常时才自动重启容器。
3. Never: 从来不重启容器。
实际使用时,需要根据应用运行的特性,合理设置这三种恢复策略。
Deployment详解
使用yaml创建Deployment
k8s deployment资源创建流程:
- 用户通过 kubectl 创建 Deployment。
- Deployment 创建 ReplicaSet。
- ReplicaSet 创建 Pod。
Deployment是一个定义及管理多副本应用(即多个副本 Pod)的新一代对象,与Replication Controller相比,它提供了更加完善的功能,使用起来更加简单方便。
Deployment 是 Pod 的控制器,主要控制pod副本的数量,如果某个pod故障,服务也不会停止,还可以滚动更新,弹性升级。
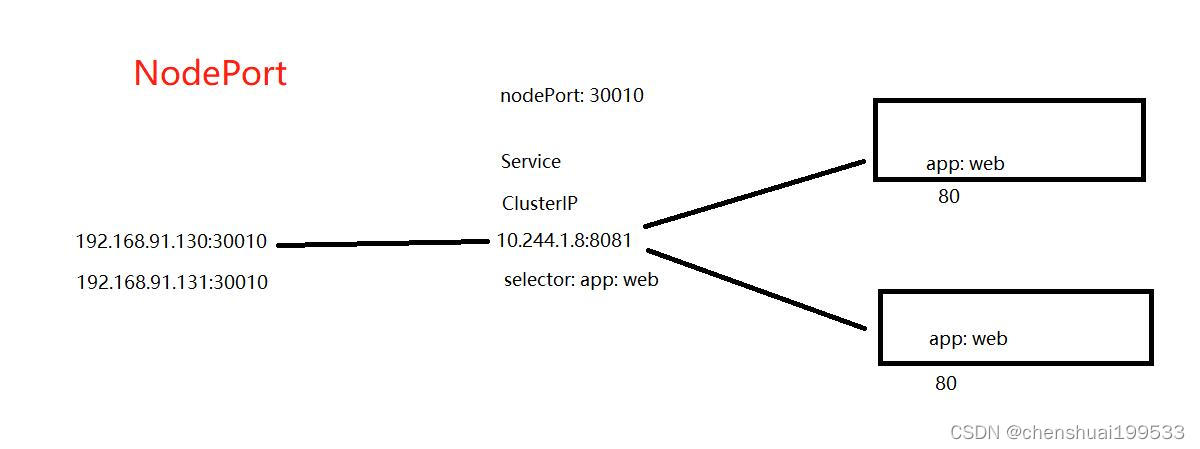
service是以nodePort的方式暴露端口给外网
ports:
- port: 8080 对内访问的端口
nodePort: 30001 对外访问的端口
targetPort: 80 是pod上容器的端口
总的来说,port和nodePort都是service的端口,前者暴露给集群内客户访问服务,后者暴露给集群外客户访问服务。从这两个端口到来的数据都需要经过反向代理kube-proxy流入后端pod的targetPod,从而到达pod上的容器内。
ClusterIP 是集群内部的虚拟IP,供集群内部的pod通信使用。
deployment+volume控制副本数量和卷挂载 卷挂载类似于容器-v文件映射
replicas: 2 指定pod副本数量
nodeName: node1 指定pod的节点
volumeMounts: #定义挂载卷
- mountPath: "/usr/share/nginx/html"
name: nginx-vol
volumes: #定义共享卷
- name: nginx-vol
hostPath:
path: /var/data
弹性伸缩:就是pod的副本数量增加减少
滚动升级:将一个集群中正在运行的多个 Pod 版本,修改镜像版本,交替地逐一升级的过程,就是"滚动更新"。
K8s通过NFS+PV和PVC实现持久化存储的
Volume 提供了非常好的数据持久化方案,不过在集群少的情况下还可以,集群规模扩大的话,效率问题和安全问题就比较多
Kubernetes 给出的解决方案是 PersistentVolume 和 PersistentVolumeClaim。
PersistentVolume (PV) 是外部存储系统中的一块存储空间,由管理员创建和维护。与 Volume 一样,PV 具有持久性,生命周期独立于 Pod。
PersistentVolumeClaim (PVC) 是对 PV 的申请 (Claim)。PVC 通常由普通用户创建和维护。需要为 Pod 分配存储资源时,用户可以创建一个 PVC,指明存储资源的容量大小和访问模式(比如只读)等信息,Kubernetes 会查找并提供满足条件的 PV。
有了 PersistentVolumeClaim(PVC),用户只需要告诉 Kubernetes 需要什么样的存储资源,而不必关心真正的空间从哪里分配,如何访问等底层细节信息。这些 Storage Provider 的底层信息交给管理员来处理,只有管理员才应该关心创建 PersistentVolume 的细节信息。
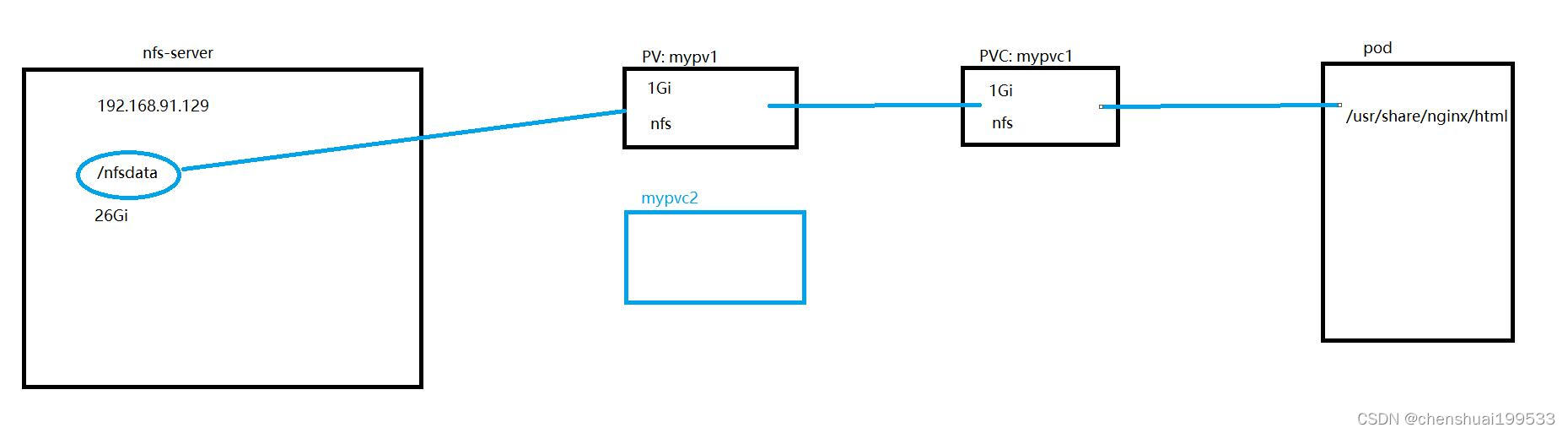
1,指定 PV 的容量为 1G。
2,accessModes 指定访问模式为ReadWriteOnce读写挂载到单个节点
3,PV的回收策略指定为Retain – 需要管理员手工回收。
4,PVC 就很简单了,只需要指定 PV 的容量,访问模式和 class。
5,kubectl get pvc看到pvc已经bound到pv上,申请成功。
6,pod申请pvc,通过卷挂载的方式申请。
7,我们可以进入pod中查看共享的目录或者文件,在NFS共享目录中也可以查看到同样的内容,同步更新,同步删除。
PVC代表用户向PV申请
PV/PVC的静态供给
创建了 PV,然后通过 PVC 申请 PV 并在 Pod 中使用,这种方式叫做静态供给
PV/PVC的动态供给
动态供给:
动态供给是通过 StorageClass 实现的,StorageClass 定义了如何创建 PV
我们需要使用到StorageClass,来对接存储,靠他来自动关联pvc,并创建pv。
PV&PVC在应用在Mysql的持久化存储实战项目
下面演示如何为 MySQL 数据库提供持久化存储,步骤为:
- 创建 PV 和 PVC。
- 部署 MySQL。
- 向 MySQL 添加数据。
- 模拟节点宕机故障,Kubernetes 将 MySQL 自动迁移到其他节点。
- 验证数据一致性
因为storage自动创建pv需要经过kube-apiserver,所以要进行授权
创建1个sa(serviceaccount)
创建1个clusterrole,并赋予应该具有的权限,比如对于一些基本api资源的增删改查;
创建1个clusterrolebinding,将sa和clusterrole绑定到一起;这样sa就有权限了;
然后pod中再使用这个sa,那么pod再创建的时候,会用到sa,sa具有创建pv的权限,便可以自动创建pv;
K8s的控制器
控制器主要是控制pod的状态和行为的。
部分控制器类型如下:
ReplicationController 和 ReplicaSet
Deployment:指定pod的数量,随机分配到节点上,同时创建,同时删除。
DaemonSet:主要是全部的节点都运行一个pod的副本,有新增的节点会自动增加pod,如果节点移除pod也会回收。
具体使用场景:节点的监控,节点日志的收集logstash,都可以用这种daemonset。
StatefulSet:StatefulSet 中的 Pod 拥有唯一的具有黏性的身份标识;有序创建和有序删除。
使用场景:需要稳定的网络连接或者持久话存储,基于pvc实现。
serviceaccount
总结:serviceaccount是pod访问apiserver的权限认证,每个pod中都默认会绑定当前名称空间默认的sa中的secrets,来保证pod能正常的访问apiserver;
serviceaccount能和clusterrole进行绑定。绑定成功之后,serviceaccount的权限就和clusterrole一致了。后续pod再使用这个serviceaccount,pod的权限也就相同了;
不过这个,是pod进程的权限;如果真正关乎与用户的权限的话,还是使用RBAC
说白了,serviceaccount就是pod使用的账号而已;
dockerfile, Dockercompose,K8s区别?
dockerfile: 构建单个服务镜像,以脚本形式
从无到有的构建镜像,包括依赖环境、代码、中间件、数据库等。
docker-compose:多镜像编排容器
是单机管理,编排容器,可以同时管理多个 container ,将多个相关的容器一次性启动,比如运行一个jar需要依赖jdk、mysql、mq、redis等,这些容器只需要 docker-composer up 就可以全部启动,不需要一个个单独启动。
k8s:跨服务编排
k8s就像一个领航员,把各种集装箱(container)有条不紊地组装起来,着重提供如下功能:
1.快速部署功能:定义对应的charts,可以方便把大型的应用部署上去。
2.智能的缩扩容机制:部署时候会自动去考虑容器应该部署在哪个服务器上,以及副本的数量可以自定义。
3.自愈功能:某个节点的服务崩溃了,可以自动迁移到另外一个服务器节点来恢复来实现高可用。
4.智能的负载均衡:利用Ingress,可以实现流量通过域名访问进来时候,进行流量的分流到不同服务器上。
5.智能的滚动升降级:升级或者降级时候,会逐个替换,当自定义数量的服务升级OK后,才会进行其他的升级以及真正销毁旧的服务。
总结:Docker Compose是一个基于Docker的单主机容器编排工具.而k8s是一个跨主机的集群部署工具
nodeport 还有 clusterIP 这两个有什么区别?
NodePort:
我们的场景不全是集群内访问,也需要集群外业务访问。那么ClusterIP就满足不了了。NodePort当然是其中的一种实现方案。
ClusterIP的service:
这个service有一个Cluster-IP,其实就一个VIP。具体实现原理依靠kubeproxy组件,通过iptables或是ipvs实现。
这种类型的service 只能在集群内访问。
你 ping不通你 clusterIP 地址,这种现象是否正常?怎么解决?
不正常。
查看kube-proxy日志
原因:kube-proxy使用了iptable模式,修改为ipvs模式则可以在pod内ping通clusterIP或servicename
解决办法:
查看kube-proxy configMapkubectl get cm kube-proxy -n kube-system -o yaml
发现执行命令后输出的mode: “”
编辑kube-proxy configMap,修改mode为ipvskubectl edit cm kube-proxy -n kube-system
开启ipvs支持
重启kube-proxy就ok了
DNS递归查询
是指DNS服务器在收到用户发起的请求时,必须向用户返回一个准确的查询结果。如果DNS服务器本地没有存储与之对应的信息,则该服务器需要询问其他服务器,并将返回的查询结构提交给用户。
DNS迭代查询
是指DNS服务器在收到用户发起的请求时,并不直接回复查询结果,而是告诉另一台DNS服务器的地址,用户再向这台DNS服务器提交请求,这样依次反复,直到返回查询结果。
DNS缓存
DNS缓存是将解析数据存储在靠近发起请求的客户端的位置,也可以说DNS数据是可以缓存在任意位置,最终目的是以此减少递归查询过程,可以更快的让用户获得请求结果。
DNS解析的过程?
dns查询的结果通常会在本地域名服务器进行缓存,如果本地域名服务器中有缓存,会跳过dns查询步骤。
如果没有缓存。会进行递归查询或迭代查询
浏览器输入www.baidu.com,先查询本地dns,如果本地dns没有结果,则由本地域名服务器开始进行递归查询
本地域名服务器采用迭代查询的方法,向根域名服务器进行查询。
根域名服务器告诉本地域名服务器,下一步应该查询顶级域名服务器.com TLD的ip地址
本地域名服务器向顶级域名服务器TLD进行查询
顶级域名服务器告诉本地域名服务器,下一步查询baidu.com权威域名服务器的ip地址
本地域名服务器向baidu.com权威域名服务器发送查询
权威域名服务器告诉本地域名服务器下一步查询www.baidu.com子域名服务器的ip地址
www.baidu.com子域名服务器告诉本地域名服务器所查询的主机ip地址
本地域名服务器最后把查询的ip地址响应给浏览器
一旦返回了ip地址,浏览器就能对网页发出请求,浏览器向ip地址发送http请求
如何查看客户端真实IP?
nginx上要安装:–with-http_realip_module 模块
配置文件server块中要打开:real_ip_recursive on;
查看日志就可以得到客户端真实的IP
pod
Pod是k8s进行创建、调度和管理的最小单位,能使部署和管理更加灵活,一个Pod可以包含一个容器或者多个相关容器,但是实际工作中一个pod最好放一个容器。
pause容器
每个Pod中都有一个pause容器,pause容器是Pod的网络接入点,Pod中其他的容器会使用容器映射模式连接到这个pause容器。
Replication Controller和deployment
Replication Controller用来管理Pod的副本,保证集群中存在指定数量的Pod副本。集群中副本的数量大于指定数量,则会停止指定数量之外的多余pod数量,反之,则会启动少于指定数量个数的容器,保证数量不变。Replication Controller是实现弹性伸缩、动态扩容和滚动升级的核心。Deployment是一个更高层次的API/资源对象,RC的基本功能它都有的。
k8s集群二进制部署流程(生产环境)
1、Kubernetes集群部署架构规划
2、部署Etcd集群
3、在Node节点安装Docker
4、部署Flannel网络插件
5、在Master节点部署组件
6、在Node节点部署组件
7、查看集群状态
8、运行一个测试示例
9、部署Dashboard(Web UI)
k8s的yum安装部署(学习环境)
Docker 的优点和不足?
容器的本质是进程
优点:Docker 的五大优点:轻量级,启动时间快,可移植性强,隔离性好,可持续部署,管理维护方便
传统搭建环境这一步往往会耗费我们好几个小时的时间,部署过程中一个小问题就可能需要找很久才能够解决。而有了容器之后,环境部署这些都变得非常容易。
不足
Docker是基于Linux 64bit的,无法在32bit的linux/Windows/unix环境下使用。
docker对磁盘存储的管理比较有限。
Docker三大核心组件
Docker 镜像 - Docker images
Docker 仓库 - Docker registeries
Docker 容器 - Docker containers
docker的网络模式?
1,host模式:docker容器和主机共用一个ip地址。
2,container模式:容器和另外一个容器共享Network namespace。
kubernetes中的pod就是多个容器共享一个Network namespace。
3,none模式:docker容器不会网络ip
4,默认bridge模式:当Docker进程启动时,会连接到默认的网桥上
镜像打包和迁移?
export 容器打包成镜像 import是把打包的镜像解压成镜像
commit是把容器做成镜像 save -o是把镜像打包 load是把镜像解压
DockerFile常见指令?
构建镜像的yaml文件
from指定镜像;
add自动解压;
copy是复制文件;
run是运行的命令;
workerdir切换工作目录;
env是环境变量;
expose暴露端口;
cmd容器启动要运行的命令;
写过哪些dockerfile文件?
利用Dockerfile文件构建nginx镜像


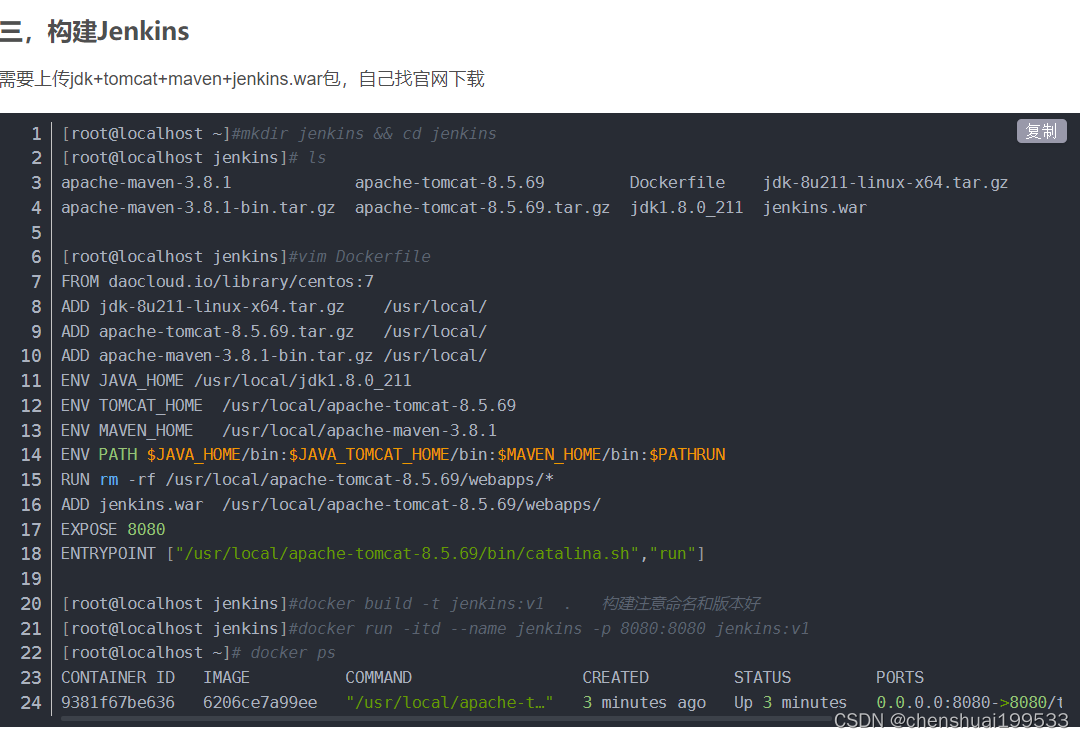 访问:http://10.0.0.10:8080/jenkins
访问:http://10.0.0.10:8080/jenkins
k8s和docker的最大不同
Docker跟Kubernetes最大的不同是,docker主要是以命令行的方式,k8s主要是以yaml文件的方式来进行统一的管理和配置的
k8s的插件和资源对象都有哪些?
Master主要负责资源调度,控制副本,和提供统一访问集群的入口。
k8s-master:
kube-apiserver:集群内部通信的入口
kube-scheduler:资源调度
etcd:数据存储
kube-controller-manager:负责各种控制器
Node是Kubernetes集群架构中运行Pod的服务节点。Node是Kubernetes集群操作的单元,用来承载被分配Pod的运行,是Pod运行的宿主机,由Master管理。
k8s-node:
kubelet:负责管控容器,kubelet会从k8sapiserver接受pod的创建请求,启动和停止容器,监控容器的状态并汇报给k8sapiserver
k8s-proxy:负责为pod创建代理服务。k8s-proxy会从apiserver获取所有的service信息,并根据service的信息创建代理服务,实现service到pod的请求路由和转发,从而实现k8s层级的虚拟转发网络
docker engine:docker引擎,负责本机的容器创建和管理工作以及镜像的拉取
flannel网络插件
控制器:
rc:保证集群中存在指定数量的Pod副本。集群中副本的数量大于指定数量,则会停止指定数量之外的多余pod数量,反之,则会启动少于指定数量个数的容器,保证数量不变。Replication Controller是实现弹性伸缩、动态扩容和滚动升级的核心。
deployment:Deployment是一个更高层次的API/资源对象,RC的基本功能它都有的。
daemonset:能确保全部(或者某些)节点上运行一个 Pod 的副本。当有节点加入集群时,会为他们新增一个 Pod。当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。比如搜集节点的上的应用日志的话logstash、filebeat,就可以用这个控制器。
statefullset:
主要提供了唯一的,粘性的域名标识,不规则的域名,pod即使重新调度ip虽然变化,但是唯一域名标识是不变的
每个pod都有一个唯一的顺序索引。
基于PVC实现稳定的、持久的存储,即Pod重新调度后还是能访问到相同的持久化数据。
顺序部署,逆序收缩或者删除,平滑滚动更新
service:service是pod的一个逻辑分组,是pod服务的对外入口抽象。service同样也通过pod的标签来选择pod,与控制器一致。
1,ClusterIP:默认类型,自动分配一个仅可在内部访问的虚拟IP。应用方式:内部服务访问
2,NodePort:在ClusterIP的基础之上,为集群内的每台物理机绑定一个端口,外网通过任意节点的物理机IP:端口来访问服务。应用方式:外服访问服务
3,LoadBalance:在NodePort基础之上,提供外部负载均衡器与外网统一IP,此IP可以将请求转发到对应服务上。这个是各个云厂商提供的服务。应用方式:外服访问服务
4,ExternalName:引入集群外部的服务,可以在集群内部通过别名方式访问(通过 serviceName.namespaceName.svc.cluster.local访问)
支持持久化存储
volume:卷挂载,解决Pod中容器之间的数据共享。
secret:存放敏感的加密数据信息,例如密码、用户名、token等,创建secret后,pod引用这个secret才能使用
configmap:存放非加密的数据,可以降低耦合性,可以用来存放应用的配置文件,然后pod可以引用
serviceaccount:它并不是给kubernetes集群的用户使用的,给pod使用的,主要是给pod提权,但是需要定义角色、定义绑定规则,将定义的角色通过绑定规则与clusterrole绑定,然后serviceaccount关联clusterrole,pod引用这个serviceaccount实现提权
RBAC:访问控制
nfs,pv,pvc主要用来做持久化存储的
1,先是创建nfs服务器目录,配置读写权限,开放节点的网段
/nfsdata *(rw,no_root_squash,no_all_squash,sync)
2,创建一个yaml文件,指定pv的大小,指定访问模式ReadWriteMany :PV 能以 read-write 模式 mount 到多个节点
3,指定pv的回收策略Retain: 需要管理员手工回收。
4,指定 PV 的 class 为 nfs。相当于为 PV 设置了一个分类,PVC 可以指定 class 申请相应 class 的 PV。
5,指定 PV 在 NFS 服务器上对应的目录。
创建pvc的yaml文件,指定PV 的容量,访问模式和class。
创建pod,pod中用卷挂载的方式引用这个pvc即可。然后就实现了容器目录创建的数据会持久化存储到nfs服务器指定的目录中。