http://www.netlib.org/utk/people/JackDongarra/etemplates/node373.html
主要参考这里面的内容
现有一个矩阵
![\begin{displaymath}
A =
\left[\begin{array}{rrrrrr}
10 & 0 & 0 & 0 &-2 & 0 \\
...
... 9 & 9 & 13 \\
0 & 4 & 0 & 0 & 2 & -1
\end{array}\right] ~.
\end{displaymath}](http://www.netlib.org/utk/people/JackDongarra/etemplates/img3559.png)
观察该矩阵可以发现,该矩阵有很多0,压缩的方式就是去掉这些0元素,所用的方法就是将这个矩阵的存储换为3个数组进行存储
| val |
10 |
-2 |
3 |
9 |
3 |
7 |
8 |
7 |
3 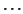 9 9 |
13 |
4 |
2 |
-1 |
|
|
| col_ind |
1 |
5 |
1 |
2 |
6 |
2 |
3 |
4 |
1 5 |
6 |
2 |
5 |
6 |
|
|
val数组表示数值,val[k]=A[i][j],k为val中的位置,val保存的是A中不为0的元素,这样子val这个数组就定下来了,对应的k也定下来了
上面val数组定下来以后有val[k]=A[i][j],对应的col_ind[k]=j,即第k个col_ind表示对应元素的列值,这样子col_ind这一组也定下来了
而row_ptr则是该行之前所有非零元素个数的和并加一,这样子就能定下来里面每个元素。那么如何运用压缩的三个数组恢复出那个矩阵
int index=0;
for(int i=1;i<rows;i++)
{
for(int j=1;j<row_ptr[i];j++)
{
col=col_ind[index];
a[i-1][col]=val[index];
index++;
}
}
而CSR和CSC的区别主要是ptr的选取不同,CSR选取是row_ptr,而CSC则选择col_ptr