Redis字典介绍
Redis是K-V型数据库, 整个数据库是用字典来存储的, 对Redis数据库进行任何增、 删、 改、 查操作, 实际就是对字典中的数据进行增、 删、 改、 查操作
字典需要的特征
1、O(1)的时间复杂度取出或插入关联值
2、key 唯一,key类型可以是各种类型, value也可以是各种类型
根据特征如何设计
1、实现O(1)时间复杂度,那就得用数组,因为Redis是C实现的,所以用数组是最好的选择
2、有了数组,应该怎么将不同的key映射到数组的下标呢?
哈希算法:
1) 相同的输入经Hash计算后得出相同输出;
2) 不同的输入经Hash计算后一般得出不同输出值, 但也可能会出现相同输出值。
所以需要有一个强随机分布的hash函数
Daniel J.Bernstein在comp.lang.c上发布的“times 33”散列函数
Redis 哈希函数的实现使用siphash
uint64_t dictGenHashFunction(const void *key, int len) {
return siphash(key,len,dict_hash_function_seed);
}
uint64_t siphash(const uint8_t *in, const size_t inlen, const uint8_t *k) {
#ifndef UNALIGNED_LE_CPU
uint64_t hash;
uint8_t *out = (uint8_t*) &hash;
#endif
uint64_t v0 = 0x736f6d6570736575ULL;
uint64_t v1 = 0x646f72616e646f6dULL;
uint64_t v2 = 0x6c7967656e657261ULL;
uint64_t v3 = 0x7465646279746573ULL;
uint64_t k0 = U8TO64_LE(k);
uint64_t k1 = U8TO64_LE(k + 8);
uint64_t m;
const uint8_t *end = in + inlen - (inlen % sizeof(uint64_t));
const int left = inlen & 7;
uint64_t b = ((uint64_t)inlen) << 56;
v3 ^= k1;
v2 ^= k0;
v1 ^= k1;
v0 ^= k0;
for (; in != end; in += 8) {
m = U8TO64_LE(in);
v3 ^= m;
SIPROUND;
v0 ^= m;
}
switch (left) {
case 7: b |= ((uint64_t)in[6]) << 48; /* fall-thru */
case 6: b |= ((uint64_t)in[5]) << 40; /* fall-thru */
case 5: b |= ((uint64_t)in[4]) << 32; /* fall-thru */
case 4: b |= ((uint64_t)in[3]) << 24; /* fall-thru */
case 3: b |= ((uint64_t)in[2]) << 16; /* fall-thru */
case 2: b |= ((uint64_t)in[1]) << 8; /* fall-thru */
case 1: b |= ((uint64_t)in[0]); break;
case 0: break;
}
v3 ^= b;
SIPROUND;
v0 ^= b;
v2 ^= 0xff;
SIPROUND;
SIPROUND;
b = v0 ^ v1 ^ v2 ^ v3;
#ifndef UNALIGNED_LE_CPU
U64TO8_LE(out, b);
return hash;
#else
return b;
#endif
}
这时,无论是什么类型的键值,在redis都是字符串,这样都能通过哈希函数获取到对应的64位的数值,这个数值再对数组求余就是数组的下标。
冲突解决:
如果出现了冲突,那么就需要键的结构是个链表
typedef struct dictEntry {
void *key;
void *val;
struct dictEntry *next;
} dictEntry;
大概的字典的存储结构:
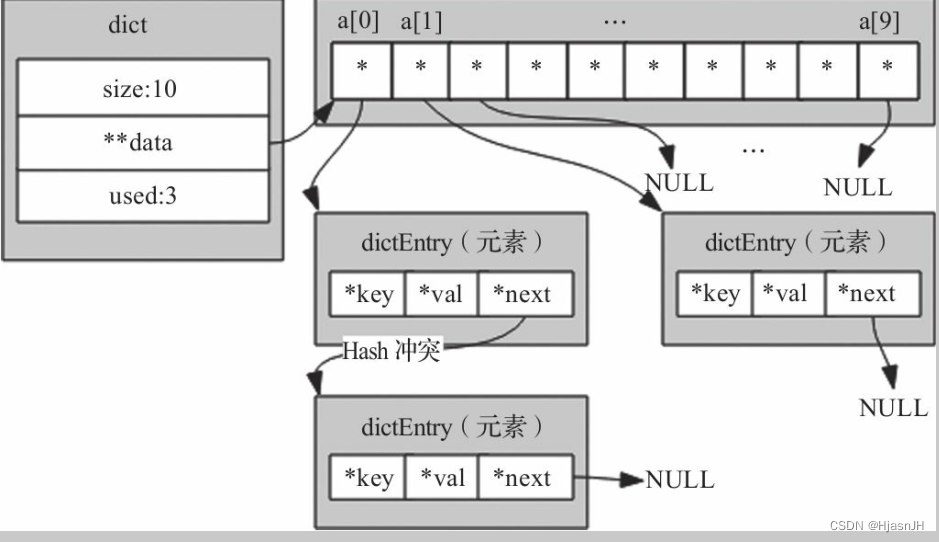
所以就可以大概定义字典哈希表的结构了
typedef struct dictht {
dictEntry **table; // 指针数组, 用于存储键值对,是个二维的
unsigned long size; // 大小为2^n
unsigned long sizemask; // 2^n -1
unsigned long used; // 已经存在的元素个数,二维格子中已存在的键值对个数
} dictht;
一个数对size求余,相当于对sizemask 位&,位运算速度快于求余。这就是sizemask的作用,加速
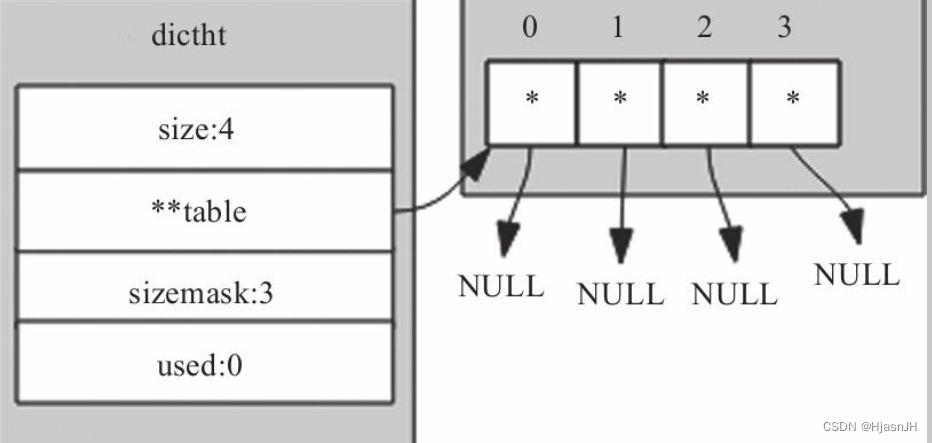
这就是hash表的定义。
rehash是怎么实现?
数组的大小需要可变,首次需要扩容,第一次的大小位4,后续根据每次都是加倍扩容。如果没有使用,需要缩容,这就是rehash。
具体实现:
1、新分配一个新的ht[0] 两倍大小的内存给ht[1],并置为dict的rehash标志
2、新添加的键添加到新的hash表ht[1]中,而查找,删除,修改,则都要到两个中检查,因为有可能再ht[0],也有可能再ht[1]中
3、ht[0]的所有值重新计算放到ht[1]中,并删除就的ht[0]的键值
4、完成后对调ht[0]和ht[1]指针。
rehash如果容量很大的情形,则要利用分治思想,不能一次性把所有数据rehash,这样会导致redis服务不可用。
dictRehashStep提供了对一个键值的rehash
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
真正的rehash实现
int dictRehash(dict *d, int n) {
int empty_visits = n*10; // 最大可以访问多少个空桶
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
其中empty_visits,是防止如果再rehash的过程中,比如由一片连续的空捅,也就是空数组,而如果这时候是步进的访问的话,可能很多步都访问不到数据,而如果一直查找下去的话,又有可能在数据量大的时候会查找很久,所以就是入参n的10倍,比如当前要rehash 1个,但是走了10个桶,发现还是空的,就返回了,不一直找下去。这也是为了兼顾性能的折中方案。
incrementallyRehash
N次rehash操作后, 整个ht[0]的数据都会迁移到ht[1]中, 这样做的好处就把是本应集中处理
的时间分散到了上百万、 千万、 亿次操作中, 所以其耗时可忽略不计
int dictRehashMilliseconds(dict *d, int ms) {
long long start = timeInMilliseconds();
int rehashes = 0;
while(dictRehash(d,100)) {
rehashes += 100;
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}
有了hash的概念,实现字典就比较容易了
字典实现
typedef struct dict {
dictType *type;
void *privdata; // 该字典依赖的数据,配合type使用
dictht ht[2]; // 字典扩容缩容使用
long rehashidx; // rehash标识。 默认值为-1, 代表没进行rehash操作
unsigned long iterators; // 当前运行的迭代器数
} dict;
其中:
terators字段, 用来记录当前运行的安全迭代器数, 当有安全迭代器绑定到该字典时, 会暂停rehash操作。 Redis很多场景下都会用到迭代器, 例如: 执行keys命令会创建一个安全迭代器, 此时iterators会加1, 命令执行完毕则减1, 而执行sort命令时会创建普通迭代器,该字段不会改变
一个典型的字典图
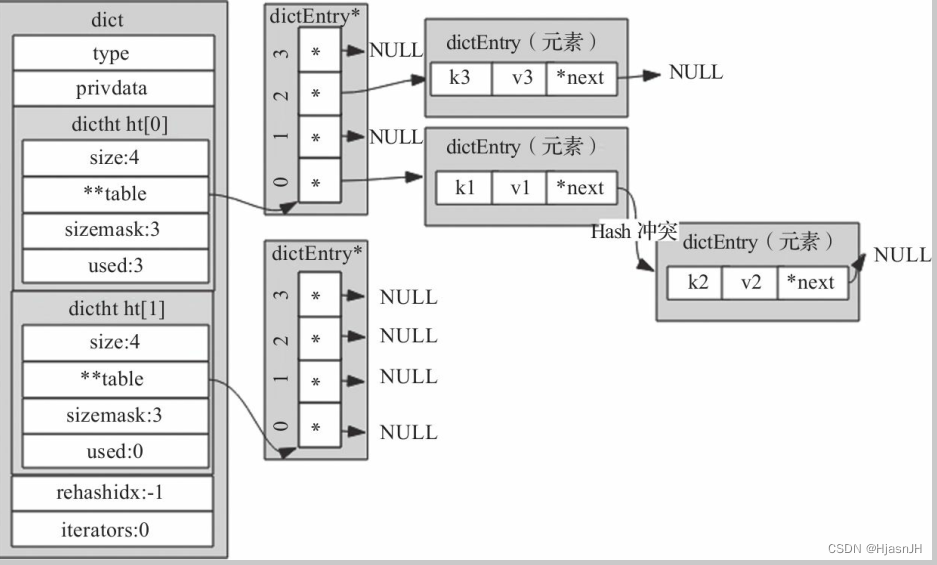
看下来,其中数据结构的定义就到这里。
实现:
1、创建dictCreate,初始化。
dict *dictCreate(dictType *type,
void *privDataPtr)
{
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
}
static int _dictInit(dict *ht, dictType *type, void *privDataPtr) {
_dictReset(ht);
ht->type = type;
ht->privdata = privDataPtr;
return DICT_OK;
}
static void _dictReset(dict *ht) {
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
2、添加
其中应该有个概念就是rehash,这是我们首先假定我们一开始就是数组,数组总有不够的时候,不够的时候扩容或者太多的时候缩容,都是交rehash操作。
rehash会使用到了dict结构的ht[1],这就是为什么dict结构里面需要两个哈希表的原因。
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key,NULL);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
/*该字典是否在进行rehash操作 进行一步rehash*/
if (dictIsRehashing(d)) _dictRehashStep(d);
/* 获取新节点的洗标 如果等于-1 则代表存在,返回空,并把老节点存入existing*/
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
// 分配新节点的内存,加入到节点的top,假定新加入的节点使用的频率更高
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
3、查找元素
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx, table;
if (d->ht[0].used + d->ht[1].used == 0) return NULL; /* dict is empty */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
查找过程如果发现正在rehash,则进行一次rehash,分别在两个哈希表中取值
void dbOverwrite(redisDb *db, robj *key, robj *val) {
dictEntry *de = dictFind(db->dict,key->ptr);
serverAssertWithInfo(NULL,key,de != NULL);
dictEntry auxentry = *de;
robj *old = dictGetVal(de);
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
val->lru = old->lru;
}
dictSetVal(db->dict, de, val);
if (server.lazyfree_lazy_server_del) {
freeObjAsync(old);
dictSetVal(db->dict, &auxentry, NULL);
}
dictFreeVal(db->dict, &auxentry);
}
4、删除
int dictDelete(dict *ht, const void *key) {
return dictGenericDelete(ht,key,0) ? DICT_OK : DICT_ERR;
}
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {
uint64_t h, idx;
dictEntry *he, *prevHe;
int table;
if (d->ht[0].used == 0 && d->ht[1].used == 0) return NULL;
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
prevHe = NULL;
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
/* Unlink the element from the list */
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next;
if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
zfree(he);
}
d->ht[table].used--;
return he;
}
prevHe = he;
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return NULL; /* not found */
}