需要源码和数据集请点赞关注收藏后评论区留言私信~~~
特征抽取 TF-IDF
TF-IDF是两个统计量的乘积,即词频(Term Frequency, TF)和逆向文档频率(Inverse Document Frequency, IDF)。它们各自有不同的计算方法。
TF是一个文档(去除停用词之后)中某个词出现的次数。它用来度量词对文档的重要程度,TF越大,该词在文档中就越重要。IDF逆向文档频率,是指文档集合中的总文档数除以含有该词的文档数,再取以10为底的对数。
TF-IDF的主要思想是如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为这个词或者短语具有很好的类别区分能力
具体实现步骤如下
(1)新建MAVEN项目,名称为spark-mlllib
(2)数据准备。新建一个文本文件,包含四行数据,内容如下:
hello mllib hello spark
goodBye spark
hello spark
goodBye spark
(3)新建Scala类,功能是计算单词的TF –IDF
创建TF计算实例
val hashingTF = new HashingTF()
//计算文档TF值
val tf = hashingTF.transform(documents).cache()
println("计算单词出现的次数结果为:")
tf.foreach(println)
//创建IDF实例并计算
val idf = new IDF().fit(tf)
//计算TF_IDF词频
val tf_idfRDD: RDD[linalg.Vector] = idf.transform(tf)
统计结果如下
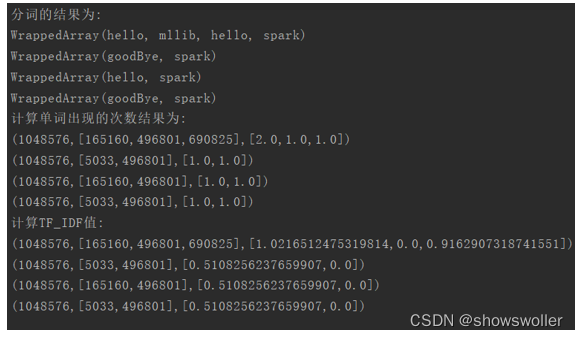
部分代码如下
package com.etc
import org.apache.spark.mllib.feature.{HashingTF, IDF}
import org.apache.spark.mllib.linalg
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object TF_IDF {
def main(args: Array[String]) {
//创建环境变量
val conf = new SparkConf()
//设置本地化处理
.setMaster("local")
//设定名称
.setAppName("TF_IDF") //设定名称
val sc = new SparkContext(conf)
//设置日志级别
sc.setLogLevel("error")
//读取数据并将句子分割成单词
val documents = sc.textFile("a.txt")
.map(_.split(" ").toSeq)
println("分词的结果为:")
documents.foreach(println)
//创建TF计算实例
val hashingTF = new HashingTF()
//计算文档TF值
val tf = hashingTF.transform(documents).cache()
println("计算单词出现的次数结果为:")
tf.foreach(println)
//创建IDF实例并计算
val idf = new IDF().fit(tf)
//计算TF_IDF词频
val tf_idfRDD: RDD[linalg.Vector] = idf.transform(tf) //计算TF_IDF词频
println("计算TF_IDF值:")
tf_idfRDD.foreach(println)
}
}
创作不易 觉得有帮助请点赞关注收藏~~~