微信好友数据分析
这里很多工作量,参考了该篇博客,在此致谢,传送门如下:
一件有趣的事:我用 Python 爬了爬自己的微信朋友
不过原博客代码不是特别全,有些没有放出来,而且代码都是图片截图,比较模糊,所以我来整理一下我的代码,贴上来,同时也进行一定的讲解。
(不想看讲解,想用完整代码的,可以戳下面的传送门,我把代码上传到了我的Github里了:
GIthub代码传送门)
下面来介绍所有的代码:
首先,我们导入itchat包,然后登录自己的微信,获取好友的数据,保存到变量friends内。
# -*- coding: utf-8 -*-
import numpy as np
import itchat
import matplotlib.pyplot as plt
# 登录微信,会弹出二维码,用手机微信扫一扫即可登录
itchat.login()
# 获取好友的所有数据
friends = itchat.get_friends(update=True)[0:]
接着,我们对好友的性别比例进行分析,这一块儿代码比较简单,会卡的地方主要是绘图那块儿,我是绘制了柱状图,显示中文卡了一次,然后每个柱子上显示数据又卡了一次。大家可以按照代码中的设置即可,代码中有注释。
# ***-----统计好友性别比例-----***
# 初始化计数器
male = female = other = 0
# friends[0]是自己的信息,因此从friends[1]开始
for i in friends[1:]:
sex = i['Sex']
if sex == 1:
male += 1
elif sex == 2:
female += 1
else:
other += 1
# 计算朋友总数
total = len(friends[1:])
# 打印输出好友性别比例
print(
"男性好友: %.2f%%" % (float(male)/total * 100) + "\n" +
"女性好友: %.2f%%" % (float(female)/total * 100) + "\n" +
"不明性别好友: %.2f%%" % (float(other)/total * 100)
)
# 进行绘图
label_name = ["Boy", "Girl", "Unknown"]
gender_list = [male, female, other]
plt.figure()
plt.bar(range(len(gender_list)), gender_list, tick_label=label_name)
# 绘图中文显示设置
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.xlabel(u'性别')
plt.ylabel(u'人数')
plt.title(u'好友性别比例')
# 在柱状图上显示数字
x=np.arange(3)
y=np.array(gender_list)
for a,b in zip(x,y):
plt.text(a, b+0.1, '%.2f' % b, ha='center', va= 'bottom',fontsize=12)
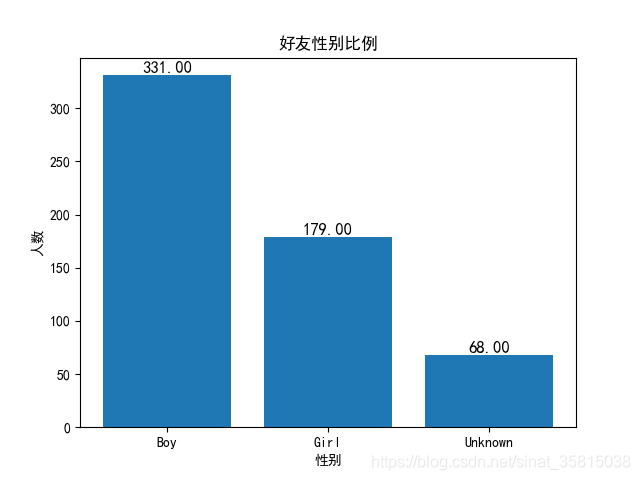
我得到的好友性别比例,如下图所示,充分显示了工科男身边男生多,女生少的规律(男生数量近乎是女生的两倍,其中Unknown指的是没有填写性别信息的好友):
然后我们对其他信息进行获取,并保存到相应的变量里,方便处理。也可以将数据导入到csv中方便查看,对相应的信息有个大致的了解,不过中文在csv里出现了乱码的问题,加了encoding=‘utf-8’也还是乱码,包括‘utf_8_sig’,暂时的解决办法是,通过Excel->数据->文本导入的形式,将csv文件导入,就可以避免乱码问题。
# ***-----获取各类信息-----***
# 定义函数,爬取所有好友的指定信息
def get_var(var):
variable = []
for i in friends[1:]:
value = i[var]
variable.append(value)
return variable
# 调用函数,得到对应信息,并存入csv文件,保存到桌面
NickName = get_var("NickName")
Sex = get_var("Sex")
Province = get_var("Province")
City = get_var("City")
Signature = get_var("Signature")
# Excel 打开中文乱码问题 未解决
# 不过可以通过Excel->数据->文本导入的形式,将csv文件导入,就可以避免乱码问题
from pandas import DataFrame
data = {"NickName": NickName, "Sex": Sex, "Province": Province,
"City": City, "Signature": Signature}
frame = DataFrame(data)
frame.to_csv('data.csv', encoding='utf_8_sig', index=True)
接下来是,对好友的城市分布进行统计,代码如下:
# ***-----统计好友城市分布-----***
city_dict = {}
x_city = []
y_city = []
for city_name in City:
if city_name in city_dict:
city_dict[city_name] += 1
else:
city_dict[city_name] = 1
city_list = sorted(city_dict.items(), key=lambda item:item[1], reverse=True)
# 将前14个城市排序显示,去除排名第一的未知城市(城市信息为空的好友)
for i in city_list[1:15]:
x_city.append(i[0])
y_city.append(i[1])
# 绘制城市分布柱状图
plt.figure()
plt.bar(range(len(x_city)), y_city, tick_label=x_city)
plt.xlabel(u'城市')
plt.ylabel(u'人数')
plt.title(u'好友城市分布')
# 在柱状图上显示数字
x=np.arange(len(x_city))
y=np.array(y_city)
for a,b in zip(x,y):
plt.text(a, b+0.06, '%.2f' % b, ha='center', va='bottom', fontsize=9)
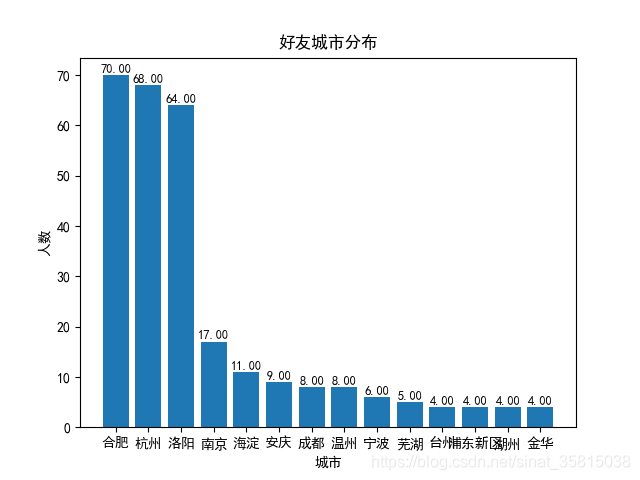
我得到的好友城市分布如下图所示,从好友城市分布也可以看出自己的成长轨迹:
然后,就是词云图的绘制了,代码如下:
# ***-----根据个性签名绘制词云图-----***
# 通过正则匹配清洗数据
import re
Signature_list = []
for i in friends:
signature = i["Signature"].strip().replace("span", "").replace("class", "").replace("emoji", "")
rep = re.compile("lf\d+\w*|[<>/=]")
signature = rep.sub("", signature)
Signature_list.append(signature)
text = "".join(Signature_list)
# 调包进行分词
import jieba
wordlist = jieba.cut(text, cut_all=False)
word_space_split = " ".join(wordlist)
这里,我们先是对好友的个性签名进行数据清洗,因为一些好友的个性签名会有表情符号,所以会得到类似于“< span class=“emoji emoji261d”></ span>”这种内容,因此我们要通过正则表达式,将这些符号去除掉。接着,我们导入jieba包,可以对中文句子进行分词。很简单,它所做的工作就是,比如将“我来到北京清华大学”分词,得到:“我”,“来到”,“北京”,“清华大学”。当然,jieba 分词包有不同的分词模式,前面的这种模式是默认的分词模式,比较符合我们的需求,其他的分词模式具体就不展开讲了,感兴趣的话可以上网搜索了解一下。
分词结束后,我们就得到了好友的个性签名里的所有词语,然后我们调用Pillow包里的相应包,进行词云图的绘制,代码如下:
# 调包进行词云图绘制
from wordcloud import WordCloud, ImageColorGenerator
import PIL.Image as Image
coloring = np.array(Image.open("weixin_sj520_33.jpg"))
my_wordcloud = WordCloud(background_color="white", max_words=200,
mask=coloring, max_font_size=70, random_state=42, scale=2,
font_path="C:\Windows\Fonts\SimHei.ttf").generate(word_space_split)
image_colors = ImageColorGenerator(coloring)
plt.figure()
plt.imshow(my_wordcloud.recolor(color_func=image_colors))
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
词云图的绘制,可以提供一个背景图片作为轮廓和底色,我这里选用了微信的logo,不过由于都是绿色的,所以颜色上会比较单调。你在使用该代码时,要将Image.open后面的文件名,换作你要用的背景图片的文件名,路径的话,我图省事,就把图片和Python代码放在了一个路径下,省去了敲路径的麻烦。接下来就是词云图绘制的相关配置,如代码所示。注意,最后的plt.show(),会将我们前面的图片全部展示出来。因为plt.show()会使得代码停在这里,所以我将它放在了代码的最后。
我的微信得到的词云图如下所示:

以上是这次博客的所有内容,其实itchat的功能有很多,有时间的话再进一步了解,慢慢学。
我的个人博客
欢迎大家访问我搭建的个人博客哦,通过github Page搭建的,基于hexo,用了next主题。有什么问题都可以互相交流。博客地址:我的个人博客:CodeSausage的博客