绪论
博主目前是一位大二学生,鉴于数据结构与算法是一门考试课,故记录以便学习
数据结构的研究对象
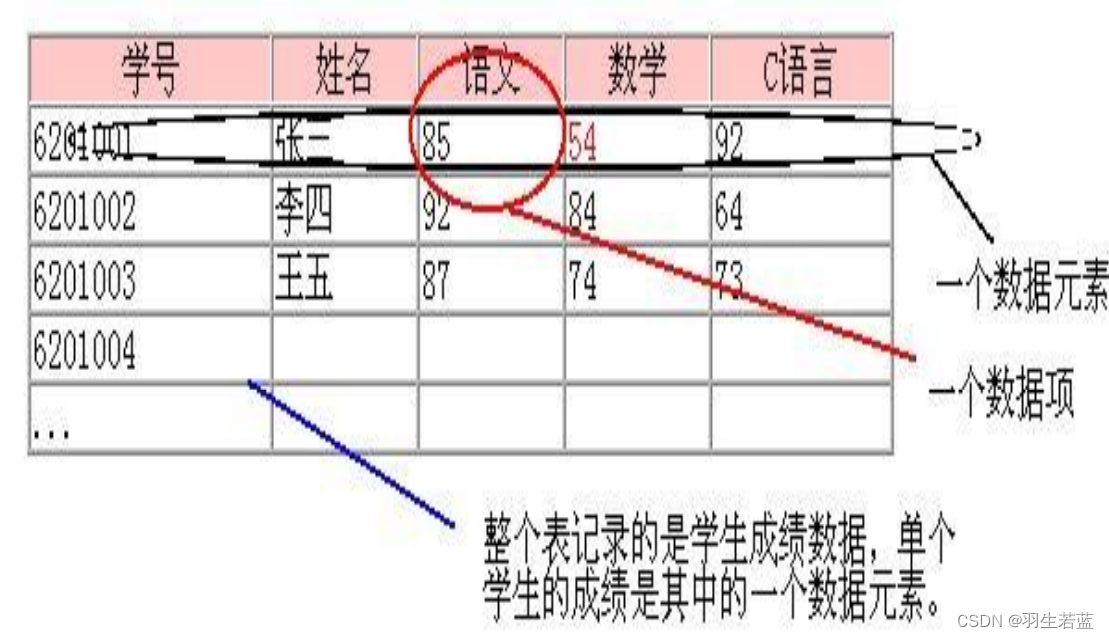
数据、数据元素、数据项
数据对象也是整张表
-
数据是信息的载体,是描述客观事物的数、 字符、以及所有能输入到计算机中,能被计算机程序识别和处理的符号的集合
-
数据元素是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。数据元素又称为元素、结点、记录
-
数据项是数据结构中讨论的最小单位
-
组合项:例如生日
-
原子项:不可再分割的数据项如年、月、日
-
数据对象:性质相同的数据元素的集合
-
数据结构是数据元素之间抽象的相互关系,并不涉及数据元素的具体内容
数据结构的表示:
通常可以用一个二元组<D,R>来表示。或写成DS=<D,R>。
D是数据集合(数据对象),R是D中数据元素之间所存在的关系的有限集合。
数据结构(技术)就是根据各种不同的数据集合和数据元素之间的关系,研究如何表示、存储和操作(查找、插入、删除、修改、排序)这些数据的技术。
DS的第一个重要部分——逻辑结构
数据的逻辑结构—人为定义的,用户可以看到
数据的逻辑结构从逻辑关系上描述数据,与数据的存储无关;可以看作是从具体问题抽象出来的数据模型; 数据的逻辑结构与数据元素的相对(存储)位置无关。
分类:
线性结构
关系r 是一种线性关系,或称为“前后关系”,有时也称为“大小关系”。关系 r 是有向的,且满足全序性和单索性等约束条件
e.g. linearity=(K,R)
K={1,2,3,4,5,6,7,8,9,10}
R={<5,1>,<1,3>,< 3,8>,<8,2>,<2,7>,<7,4>,<4,6>,<6,9>,<9,10>}
对应的图形:
⑤→①→③→⑧→②→⑦→④→⑥→⑨→⑩
<>表示有序()表示无序
DS第二个重要部分——数据的存储结构-计算机如何存储(结点及结点关系)
- 数据的存储结构是逻辑结构用计算机语言的实现;
- 数据的存储结构依赖于计算机语言;
- 计算机处理问题时是一条一条的,不能像人一样整体处理,根据存储结构找到下一条数据
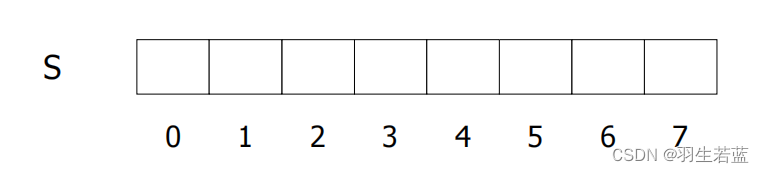
基本存储映射方法:顺序(索引、散列)、非顺序(链接)
顺序存储表示:逻辑相邻则物理相邻
结点间的逻辑后继关系用存储单元的自然顺序关系来表达
链接存储表示:逻辑相邻未必物理相邻
利用指针,在结点的存储结构中附加指针字段称为链接法。
两个结点的逻辑后继关系用指针来表达

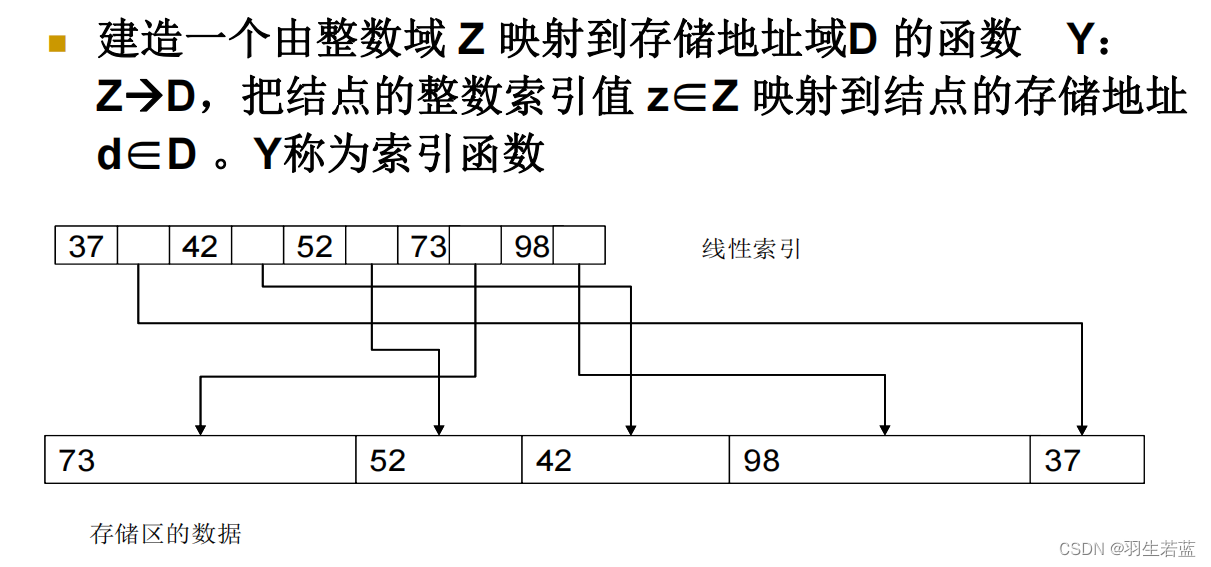
索引存储表示:为数据建立索引表
顺序存储法的一种推广,也使用整数编码来访问数据结点位置
数据结构的发展概况
略
抽象数据型
abstract data types,ADT
抽象数据型的定义
抽象数据型是一个数学模型和在该模型上定义的操作集合的总称。
数据类型、数据结构和抽象数据型
一个变量的数据类型是该变量值的类型
抽象数据型是一个数学模型以及在该模型上定义的操作集合的总称
数据结构是抽象数据型中数学模型的表示
数据类型:一组性质相同的值的集合,以及定义于这个值集合上的一组操作的总称。
C语言中的数据类型
char int float double void *
字符型 整型 浮点型 双精度型 无值 地址
数据类型由基本数据类型或构造数据类型组成
构造数据类型由不同成分类型构成。
基本数据类型可以看作是计算机中已实现的数据结构。
数据类型就是数据结构,不过是从编程者的角度来使用。(不太理解)
多层次抽象技术
建议自底向上。
如文章->行->字
抽象数据型的优点
1.降低软件设计的复杂性
2.提高程序可读性和可维护性
3.降低程序复杂度
4.有利于基于软件构件的程序开发和程序重用(不太懂)
算法及其复杂度
算法是为解决某一特定问题而采取的具体有限的操作步骤。
算法与程序
算法是有穷性 : 算法应在执行有穷步后结束。
程序可能持续运行,直到系统退出,例如操作系统wait函数。
算法是面向问题的。
程序是算法的具体语言实现。
算法的特性
- 有穷性
- 有n个输入(n可以=0)与输出(n>0)
- 确定性:算法的每条指令是清晰、无歧义的。
- 可行性
算法设计与算法分析是计算机科学的核心问题

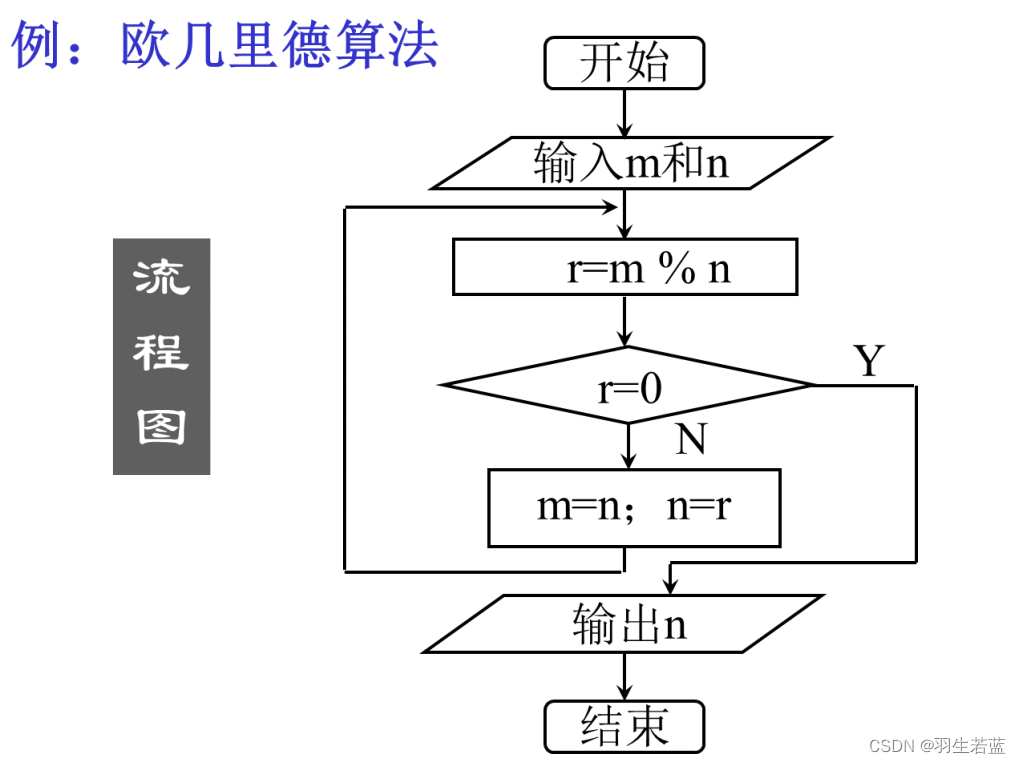
算法的描述方法

算法的复杂度及其表示
计算算法效率的方法
-
事后分析
-
事前分析
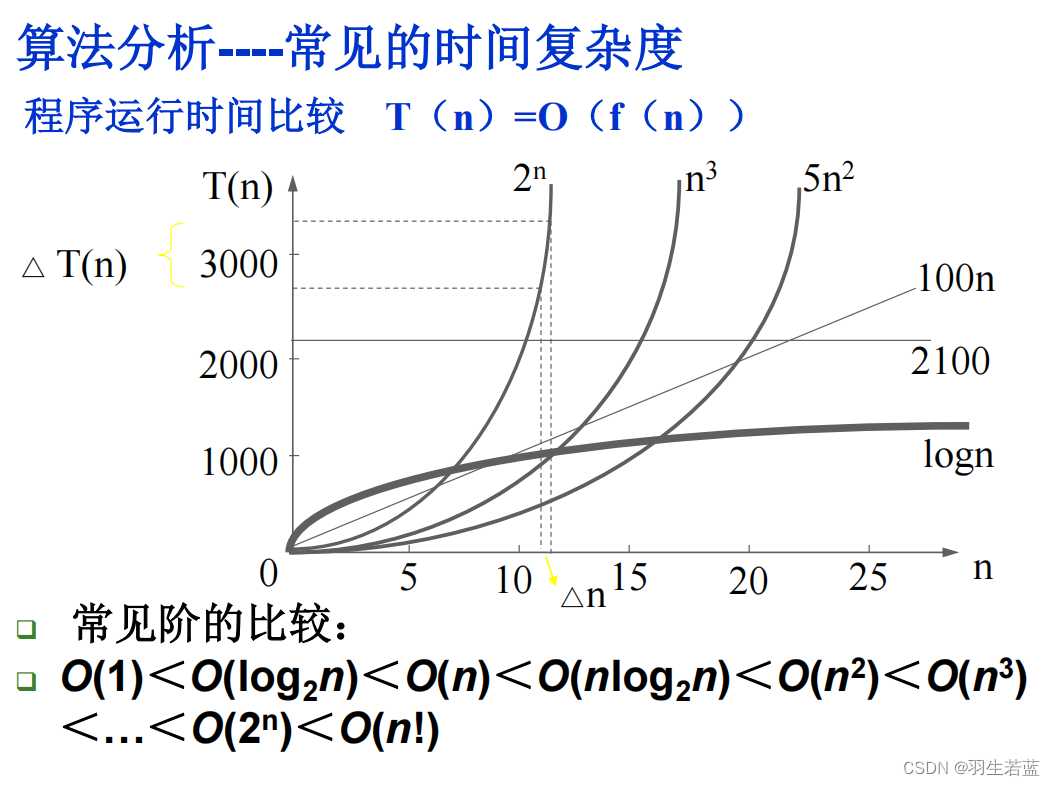
2.1 时间复杂度Time Complexity
2.2空间复杂度Space Complexity
-
如何表达一个算法的复杂性
算法的执行时间,是基本(操作)语句重复执行的次数,它是问题规模的一个函数。我们把这个函数的渐近阶称为该算法的时间复杂度。
问题规模:输入量的多少
算法分析----大O符号
定义: 若存在两个正的常数c和n0,对于任意n≥n0,都有T(n)≤c×f(n),则称T(n)=O(f(n))
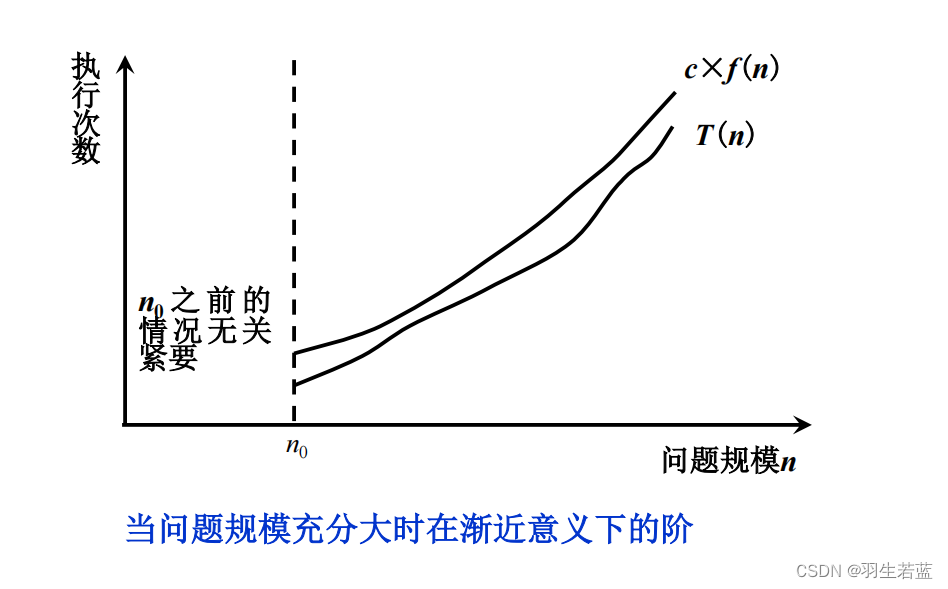
很多算法使用的数据结构是静态的存储结构,即存储空间在算法执行过程中并不发生变化
使用动态数据结构算法的存储空间是变化的,在算法运行过程中有时会有数量级的增大或缩小。对于这种情况,空间开销的分析和估计是十分必要的
-
怎样计算一个算法的复杂性
时间复杂度分析的基本方法

算法分析:各种语句遵循的规则
(1)赋值语句或读/写语句: 运行时间通常取O(1)
(2)语句序列: 运行时间由加法规则确定
(3)分支语句:运行时间由条件测试(通常为O(1) )加上分支中运行时间
最长的语句的运行时间
(4)循环语句: 运行时间是对输入数据重复执行n次循环体所耗时间的总和
每次重复所耗时间包括两部分:一是循环体本身的运行时间;二是计算循环参数、测试循环终止条件和跳回循环头所耗时间。后一部分通常为O(1)。 通常,将常数因子忽略不计,可以认为上述时间是循环重复次数n和m的乘积,其中m是n次执行循环体当中时间消耗最多的那一次的运行时间(乘法规则)当遇到多重循环时,要由内层循环向外层逐层分析。因此,当分析外层循环的运行时间是,内层循环的运行时间应该是已知的。此时,可以把内层循环看成是外层循环的循环体的一部分。
(5)函数调用语句: (不太懂,较难,会在第八章详细讲)
①若程序中只有非递归调用,则从没有函数调用的被调函数开始,计算所有这种函数的运行时间。然后考虑有函数调用的任意一个函数P,在P调用的全部函数的运行时间都计算完之后,即可开始计算P的运行时间。
②若程序中有递归调用,则令每个递归函数对应于一个未知的时间开销函数T(n),其中n是该函数参数的大小,之后列出关于T的递归方程并求解之。


拓展

最坏、最好和平均情况分析
在进行算法增长率估计时,有些算法,即使问题规模相同,若输入数据不同,其时间复杂度也不同,由于算法实际执行的操作往往依赖于分支条件的走向,而输入数据的取值又影响这些分支走向,因此很多算法都无
法得出独立于输入数据的渐进估计
- 针对这一情况,提出了最差情况估计、平均情况估计、最佳 情况估计等三种方法
平均:
随机情况下,数组的元素是无序的,既非升序也非降序
计算平均情况的复杂度应该考虑算法的所有输入情况,确定针对每种输入情况算法所需的操作数目
简单情况:每种输入出现的概率相同
复杂情况:每种输入的出现概率并非相同,
需要了解算法的实际输入在所有可能的输入集合中的分布状
况
对于时间开销,一般不注意算法的“最好估计” 。特别是处理应急事件,计算机系统必须在规定的响应时间内做完紧急事件处理。这时,最坏估计是唯一的选择
对于多数算法而言,最坏情况和平均情况估计两者,它们的时间开销的公式虽然不同,但是往往只是常数因子大小的区别,或者常数项的大小区别。因此不会影响渐进分析的增长率函数估计
结论:一般而言计算最差情况即可
逐步求精的程序设计方法
如何求解问题
问题抽象成数学模型,
写成算法,
转化成计算机能执行的指令,
精细化,细致化,形式化。
算法的逐步求精
很是困难啊,日后精进吧
习题



