原文地址
译者:本人翻译水平有限,目的仅是为了学好Docker,如有错误请见谅。
翻译版本:v1.01(将不断优化翻译质量)
本文包含以下内容
Docker容器就是将应用及其所依赖运行环境的完整文件系统打成一个包:包括所需代码,运行库,系统工具,系统库等。如此来保证应用和应用的运行环境始终不变,从而保证该应用每次运行的结果都是相同。且Docker默认已为应用提供了一个保护层,使容器和其它基础架构是相互之间是隔离的。
但当应用需要与外界沟通时,应如何设计网络去实现,使容器易于维护,服务发现,负载均衡,安全,性能和可扩展性呢?此文档则是提出解决这些网络设计难题的可用工具列表和一般的部署模式。本文不包含物理网络的设计,但会提供设计Docker网络时对应用物理网络的约束条件。
前提
在继续阅读之前,推荐先熟悉Docker慨念和Docker Swarm部分内容。
容器网络和微服务的挑战
微服务实践已经增大了应用的规模,使到应用的连接与隔离的变得更加重要了。Docker的连网理念以应用为驱动。目标是为向应用开发者提供正确的虚拟层网络操作。
有如其它所有的设计,网络设计是一个追求平衡的艺术。Docker企业版和Docker生态系统已为网络工程师去搭建最平衡的应用及其环境提供了一整套工具。且每个可选的工具都俱有不同的优点和取舍。每个选择都提供了详细的指南,使到网络工程师可以很容易地知道那些工具最适合用于他们的环境。
Docker已经开发出新的应用交付方法,并且容器也改变了一些传统的连网方法。以下是应器化应用的一般性设计主题:
- 可移植性,如可利用特定网络功能去保证最大的跨网络环境可移植性?
- 服务发现,如何知道服务的位置及其数量的增加或减少?
- 负载均衡,如何共享多个位置的服务负载,并可随时扩大与缩小?
- 安全,如何分段隔离以防止有问题的容器去访问其它容器?如何保证容器应用及群集的控制流是安全的?
- 性能,如何提供高性能的网络服务,最小的延迟和最大的带宽?
- 可扩展性,如何确保应用扩展至多台主机时不会丢失原有的特性?
容器网络模型
Docker网络架构是基于一套叫做容器网络模型(CNM)的接口。CNM的理念是提供可以跨不同网络基础架构可实现移植的应用。这个模型平衡了应用的可移植性同时不会损失基础架构原有的各种特性和功能。
CNM结构
CNM中的高层架构。他们虚拟了所有操作系统和基础架构的不可知性,所以应用无论在何种基础架构上都可以有一样的体验。
- 沙箱(SandBox)--一个沙箱包含了容器的网络配置。这里包括了容器接口的管理,路由表,和DNS设定。沙箱的实现可以是Linux网络命名空间,FreeBSD Jail或其它类似的慨念。一个沙箱可以包含多个来自不同网络的端点,即可以同时连接多个网络。
- 端点(Endpoint)--沙箱通过端点来连接网络。端点结构的存在使到应用与网络的连接实现虚拟化。这样有助于维护应用的可移值性,因此一个服务可以在无须知道如何去连接网络的情况下使用不同类型的网络驱动。
- 网络(Network)--CNM并不是OSI模型中说的网络层。而是由Linux桥接,VLan等来实现。网络收集了所有连接在其上的端点,并实现了这些端点的互连。端点如果不连接到其中一个网络,那么将无法与外界连接。
CNM驱动接口
容器连网模型提供了两个可拔插且开放的接口供用户使用,这些接口是用于通讯,利用供应商提供的附加功能,网络可见性,或网络控制等方面。
目前存在以下网络驱动:
- 网络驱动(Network Drivers)--Docker网络驱动提供了使网络可以工作的具体实现。他们是可拔插的,所以很易于支持不同的用户使用场景。多个网络驱动可同时用于指定的Docker引擎和群集。有以下两个广泛使用的CNM网络驱动:
- 内置网络驱动(Native Network Drivers)--内置网络驱动是内置于Docker引擎,并随Docker提供的驱动。有多个驱动可供选择,以支持不同的功能,如overlay网络和local bridge网络。
- 远程网络驱动(Remote Network Drivers)--远程网络驱动是由社区或其它供应商建立的网络驱动。这些驱动可用于与现有的软件或硬件环境进行集成。用户也可以建立自己的网络驱动以达成各种特殊需求。
- IPAM(IP地址管理)驱动--Docker有一个内置的IP地址管理驱动,在没有特别指定IP的情况下,它会为网络和端点提供了默认的子网或IP地址。IP地址通过网络(docker network create),容器(docker container create)和服务(docker service create)创建指令来人工分配。远程IPAM驱动也存在和提供了集成到现有IPAM的工具。
Docker内置网络驱动
Docker内置网络驱动是Docker引擎的一部份不需要任何额外模块。他们可以被docker network命令所调用。以下是现存的内置网络驱动:
| 驱动 |
描述 |
| Host |
没有命名空间隔离,主机上的所有接口都可以直接被容器使用。 |
| Bridge |
受Docker管理的Linux桥接网络。默认在同一个bridge网络的容器都可以相互通迅。
容器的外部访问也可以使用bridge驱动来设置。 |
| Overlay |
提供多主机的容器网络互连。同时使用了本地Linux桥接网络和VXLAN技术实现容器之间跨物理网络架构的连接。 |
| MACVLAN |
使用MACVLAN桥接模式建立容器接口和主机接口之间的连接。实现为容器提供在物理网络中可路由的IP地址。
此外VLAN可以被中继至macvlan驱动以强制实现容器的2层分段。 |
| None |
容器具有属于自己的网络栈和网络命名空间,但并在容器内添加网络接口。如没有其它的设置,则容器将完全独立于其它网络。 |
网络作用域(scope)
如docker network ls的输出所示,Docker网络驱动有一个作用域的概念。网络的作用域由驱动的作用域决定,如本地或swarm作用域(scope),本地作用域(scope)驱动仅在主机范围内提供连接和网络服务(例如DNS和IPAM)。Swarm作用域驱动则提供跨swarm群集内的连接和网络服务。Swarm作用域网络在整个群集中有相同的网络ID,而本地作用域网络则具有各自唯一的网络ID。
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
1475f03fbecb bridge bridge local
e2d8a4bd86cb docker_gwbridge bridge local
407c477060e7 host host local
f4zr3zrswlyg ingress overlay swarm
c97909a4b198 none null local
Docker远程网络驱动
以下由社区和供应商建立的远程网络驱动是与CNM兼容。各自向容器提供不一样的功能和网络服务。
| 驱动 |
描述 |
| contiv |
由思科提供的一个开源的网络插件,为多租户微服务部署提供基础设施和安全策略。
同时也为非容器负载和物理网络提供集成,例如ACI,contiv实现了远程网络和IPAM驱动。 |
| weave |
提供Docker容器跨多主机或云访问的虚拟网络,提供应用的自动发现,能在部分连接的网络上操作,
不需要额外的群集存储,且操作非常友好。 |
| calico |
在云数据中心上开源的虚拟网络解决方案。针对数据中心的大部份负载(虚拟机,容器,裸机服务器),只要求IP连接。
使用标准的IP路由提供连接。通过iptables编程来实现对服务器上的源和目的地工作负载的多租户隔离和精细化策略。 |
| kuryr |
OpenStack Kuryr项目的一部份。通过使用Neuton实现了Docker网络(libnetwork)远程驱动API,OpenStack网络服务。
kuryr还包含了IPAM驱动。 |
Docker远程IPAM驱动
社区和供应商建立的IPAM驱动也可用于提供与现有系统和特殊功能的集成。
| 驱动 |
描述 |
|
|
开源的IPAM插件,用于与现有的infoblox工具進行集成。 |
Linux网络基础知识
Linux内核网络是TCP/IP协议栈的非常成熟的高性能的实现(除此之外还有其它内核特性如DNS和VXLAN)。Docker网络使用原始的内核网络栈建立的高层网络驱动,简而言之,Docker网络就是Linux网络。
使用Linux内核特性来实现,确保了高性能和强健性。更重要的是它提供了跨多发布版本,如此加强了应用的可移植性。
有几个Docker用于现实内置CNM网络驱动的Linux网络块。这些网络块包括:Linux bridges, network namespaces, veth pairs和iptables。这些工具的组合实现了Docker网络驱动,并提供转发规则,网络分段,和复杂网络策略的管理工具
Linux Bridge
Linux Bridge是用于取代Linux内核实现虚拟2层设备的工具。它是基于MAC地址来转发流量,通过检查流量来动态学习。Linux bridge接被广泛用于很多的Docker网络驱动。不要将Linux Bridge和Docker的bridge相混淆,Docker bridge是Linux Bridge的高层实现。
Network Namespaces
Linux Network Namespace是用于在内核中使用本地主机的接口,路由,和防火墙规则来隔离网络。是容器在Linux上实现安全隔离的一种技术,用于隔离容器。在网络慨念上它们类似于VRF(网络和主机内的数据平面分段)。一般情况下Network Namespace可以确保在同一主机上的容器除非通过Docker network进行连接,否则不能相互通讯。CNM网络驱动实现每个容器的namespace分隔。当然,容器也是可以共享相同的网络命名空间或同属于主机的网络空间的一部份。主机网络命名空间容器、主机接口、主机路由表,这些namespace都被称为全局的网络命名空间。
虚拟以太网设备(veth)
veth是Linux网络接口是两个网络命名空间之间的有线连接。veth在每个命名空间里都有一个接口。流量从一个接口直接传输到另一个接口。Docker网络驱动使用veth去提供明确的命名空间之间的连接。当一个容器被附加到一个Docker网络时,veth的一端就会放到容器的内部(通常显示为ethX接口),而另一端则连接到Docker网络。
iptables
iptables是内置的包过滤系统,它是自Linux内核2.4版本之后的一部分。它提供丰富的3层/4层防火墙功能,如数据包标记规则链,数据包伪装,数据包丢弃。内置Docker网络驱动广泛使用iptables去分段网络流量,提供主机端口映射,和为负载均衡而标记流量等功能。
Docker网络控制平面(control plane)
Docker分布式网络控制平面通过附带传播控制平面数据来管理Swarm-scoped的状态。这是内建于Docker Swarm群集的功能无需任何额外的组件,例如关键值存储。控制平面使用Gossip协议基于SWIM跨整个Docker容器群集拓扑去传播网络状态信息。Gossip协议可以保证集群维护消息大小恒等不变、并高效一致、失败检测时间和跨大规模群集的快速聚合功能。这样可以确保网络可以无故障地稳定地跨多个节点,有效避免如慢聚合或被动节点故障等问题。
控制平面有很高的安全性,提供透过加密通道来提供机密性,完整性,和可验证性。也可以有效减少主机收到的更新数据。
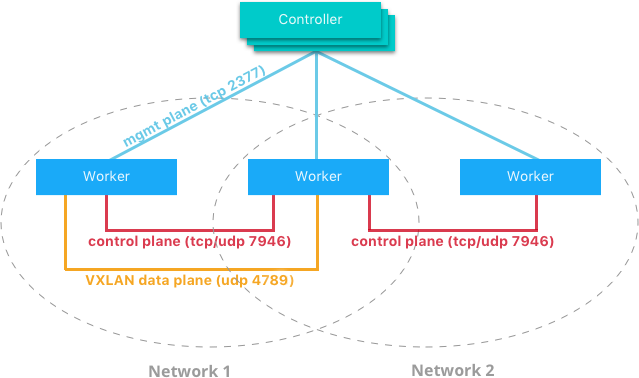
控制平面由几个相互协同工作、能快速跨大规模网络实现快速聚合的组件来组成。控制平面本身的分布性确保了不会由于群集控制器的故障而影响到网络性能,即管理任务配置完成后,群集不再依赖管理端运行。
Docker网络控制平面由以下组件组成:
- 消息散布组件,负责在一组的节点内点对点地扇形散布消息。每次都是在固定的时间间隔和相同的节点数量内进行传播以保证不会由于过大的群集规模而过度占用网络流量。指数级的信息传播横跨节点以确保快速的聚合和满足任意大小的群集运行需求。
- 故障检测,通过直接或间接的Hello消息避免被动的节点故障,且无惧网络自身的拥塞和特殊路径。
- 全状态同步,周期性的全状态同步达到快速聚合和解决网络断层的问题。
- 拓扑感知,该算法可以感知节点与节点之间的延时。使用此数据可以使节点组的快速聚合更加高效。
- 控制平面加密,此保护可免受到中间人攻击,从而缓解网络安全问题。
注:Docker网络控制平面是Swarm的一个组件,需要在Swarm群集中才能操作。
Docker主机(Host)网络驱动
host网络驱动是最为Docker初学者所知的驱动之一。原因是这与Linux原来的操作完全相同。--net=host实际上就是关闭Docker网络而让容器直接使用主机操作系统的网络。
与其它网络驱动让每个容器都被放置在自己的网络空间(或沙箱)提供完全的容器间的网络隔离相比。 host驱动让所有容器都在同一个主机网络空间上并共用主机的IP地址栈。所有在该主机的容器都可通过主机的接口相互通讯。从网络的观点来说这就等同于没有使用容器技术一样。由于容器们都是使用相同的主机接口,所以没有两个节点是可以同时绑定相同的主机TCP端口的。这样导致在同一主机上的容器在绑定端口时必须要相互协调。
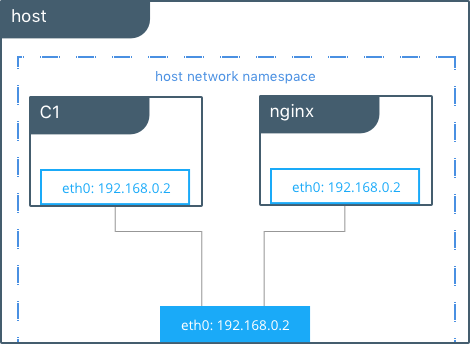
#Create containers on the host network
$ docker run -itd --net host --name C1 alpine sh
$ docker run -itd --net host --name nginx
#Show host eth0
$ ip add | grep eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
inet 172.31.21.213/20 brd 172.31.31.255 scope global eth0
#Show eth0 from C1
$ docker run -it --net host --name C1 alpine ip add | grep eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP qlen 1000
inet 172.31.21.213/20 brd 172.31.31.255 scope global eth0
#Contact the nginx container through localhost on C1
$ curl localhost
!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
在这个例子中,在这台主机上,c1和nginx容器共用主机的eth0接口。这样并不适用于多租户或安全性要求高的应用环境。主机上的容器可以自由访问该主机上的其它容器。由例子中的,c1容器可以执行curl nginx命令,可见容器之间是有可以使用localhost来相互通迅的。
在host驱动下,Docker并不管理任何容器的网络,例如端口映射和路由规则。这意味着常用的网络参数如-p和-icc都不会起作用。这样也使host网络和其它网络驱动相比更简单且延时更低。流量直接从容器到达主机的接口,提供裸机的性能,等同于无容器的处理。
全主机的访问和无自动的策略管理使host驱动不同于其它一般的网络驱动。然而,host驱动也有一些吸引人的属性,经常被用于对网络性能或应用排错需求很高的情况下。
Docker桥接(Bridge)网络驱动
本节只解释默认的Docker bridge网络,暂不讨论用户自定义的bridge网络。
默认Docker bridge网络
默认情况下,在所有运行Docker引擎的主机都会有一个叫做bridge的Docker网络。这个网络是使用bridge网络驱动建立的,是Linux bridge的实例化。以下说明一些容易混乱的慨念:
- bridge,是Docker网络的一个名字
- bridge,是一个网络驱动,或模板,网络是使用这个驱动来建立的。
- docker0,是Linux bridge的名字,是内核建立的块用于实现这个网络。
在一台独立的Docker主机上,在没有特别指定的情况下bridge是容器连接的默认网络。在以下的例子中,容器没有指定其它网络参数。Docker引擎会将容器连接到默认的bridge网络。要注意eth0是由bridge驱动来建立的,并由内置的IPAM驱动来管理IP地址。
#Create a busybox container named "c1" and show its IP addresses
host $ docker run -it --name c1 busybox sh
c1 # ip address
4: eth0@if5: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 scope global eth0
...
注:容器网络接口的MAC地址是动态产生的并内嵌了IP地址从而避免冲突。如此例中的ac:11:00:02就是对应的172.17.0.2。
在主机上使用brctl工具(通过yum install bridge-utils安装)可以查看现存的Linux桥网络命名空间。将会显示一个叫docker0的桥。docker0有一个接口,名为vetha3788c4,它提供从桥到c1容器内eth0接口的连接。
host $ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242504b5200 no vethb64e8b8
在容器c1内部,容器的路由表将流量直接传给eth0接口,再到docker0桥。
c1# ip route
default via 172.17.0.1 dev eth0
172.17.0.0/16 dev eth0 src 172.17.0.2
容器可以绑定多个接口,视乎于有多少个网络连接到该容器。在容器内每一个网络对应一个接口。
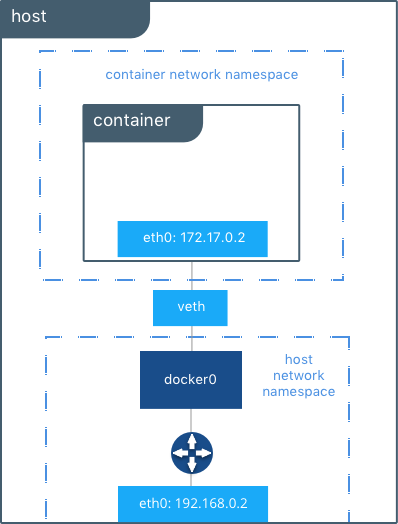
从主机的路由表显示,在全局网络命名空间的IP接口中包含了docker0。主机的路由表提供docker0和eth0之间的外部网络连接,从容器内部到外部网络的完整路径:
host $ ip route
default via 172.31.16.1 dev eth0
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.42.1
172.31.16.0/20 dev eth0 proto kernel scope link src 172.31.16.102
默认情况下bridge分配了一个子网,该子网的地址范围是172.[17-31].0.0/16或192.168.[0-240].0/20,它自动判断,不会与所在主机接口的网段相冲突。默认bridge网络也可以被配置为使用指定的地址范围。现存的Linux bridge会使用bridge网络,而不会由Docker重新建立一个。到Docker引擎文档库中可以获取更多关于bridge的信息。
注:默认bridge网络只支持传统的link。默认的bridge网络不支持基于名称的服务发现和用户指定IP地址。
用户自定义bridge网络
在默认网络的基础上,用户可以建立他们自己的网络,叫做使用任意网络驱动建立的用户自定义网络。在此情况下用户自定义的bridge网络是安装在主机上的新Linux桥。不同于默认的bridge网络,用户自定义网络支持手工指定IP地址和子网分配。如果一个子网已经分配了,IPAM驱会自动分配下一个可用的私网空间子网。
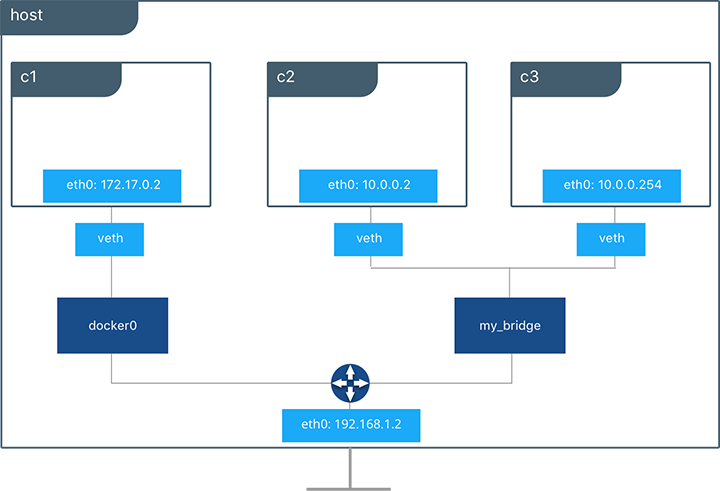
图中的用户自定义bridge网络连接了两个容器。一个是指定子网的叫my_bridge,另一个没有指定任何IP参数,所以IPAM驱动分配了下个可用的IP子网,其余的容器都有指定的IP。
$ docker network create -d bridge --subnet 10.0.0.0/24 my_bridge
$ docker run -itd --name c2 --net my_bridge busybox sh
$ docker run -itd --name c3 --net my_bridge --ip 10.0.0.254 busybox sh
brctl(通过yum install bridge-utils安装)现在显示了第二个在主机上的Linux bridge,名叫br-4bcc22f5e5b9,匹配my_bridge的网络ID。my_bridge也有两个veth接口连接到容器c2和c3。
$ brctl show
bridge name bridge id STP enabled interfaces
br-b5db4578d8c9 8000.02428d936bb1 no vethc9b3282
vethf3ba8b5
docker0 8000.0242504b5200 no vethb64e8b8
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
b5db4578d8c9 my_bridge bridge local
e1cac9da3116 bridge bridge local
...
列出全局网络命名空间接口可见Linux网络电路被Docker引擎实例化了。每个veth和Linux bridge代表了一个Linux bridge和容器网络命名空间的连接。
$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
5: vethb64e8b8@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
6: br-b5db4578d8c9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
8: vethc9b3282@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
10: vethf3ba8b5@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
...
单个容器的外部访问
默认情况下所有的容器都在同一个Docker网络上(多主机swarm作用域或local作用域)容器之间的端口都可相互连接。在不同的Docker网络和进入(ingress)容器发起流量都是经过防火墙的。这是一个基本的安全措施,它保护了容器免受外部网络和容器之间的威胁。这个在网络安全中有更详细的说明。
更多类型的Docker网络(包括bridge和overlay)从外部访问容器内的应用必须要有明确的授权,这个通过内部端口映射来实现。Docker发布的端口将容器内部的端口绑定在主机接口上。下图描述了容器c2流量的进入方式(向下的箭头)和流出方式(向上的箭头)。容器的输出(流出)流量默认是被允许的。容器的流出连接是通一个临时端口伪装(masqueraded)/SNATed来实现的(一般的端口范围是32768到60999)。返回的流量也是被允许的,同时容器会自动使用主机上最佳的可路由IP上的临时端口。
流入访问是由特定的发布端口来提供的。端口发布可以由Docker引擎、UCP和引擎CLI来完成。一个特定的或随机选择的端口会被配置为容器或服务的源端口并绑定在主机上。该端口可以被设定为监听一个特定的或所有的主机接口以接收返回的流量,所有的流量都被映射到这个端口到容器内部接口的链路上。
$ docker run -d --name C2 --net my_bridge -p 5000:80 nginx
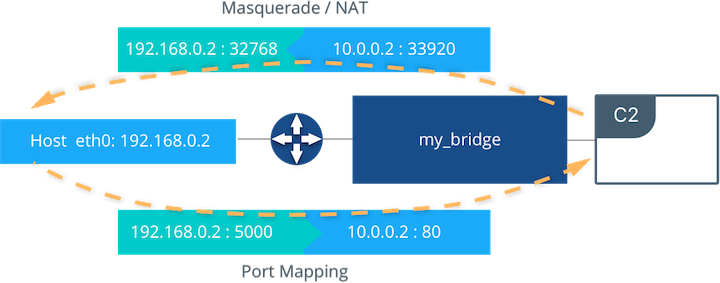
外部访问的配置是在Docker CLI或UCP中使用--publish / -p 参数。运行以上命令后,如图所示容器c2是连接到my_bridge网络并有一个10.0.0.2的IP地址。该容器在主机接口192.168.0.2上对外发布服务端口为5000。所有的流量经由此端口流向容器公开的10.0.0.2:80。
输出流量由容器经过伪装后通过临时端口32768再经过主机的192.168.0.2接口发出。返回流量则使用以相同的IP和端口为目标同样经过伪装后返回到容器的地下:端口10.0.0.2:33920 。当使用端口发布时,在网络上的外部流量总是使用主机IP和容器发布的端口,而不会使用容器内部的IP和端口。
更多关于容器对外提供服务端口和Docker引擎群集的信息请阅读Swarm服务的对外访问。
Overlay驱动网络架构
内置Docker overlay网络驱动使多主机联网变得简单和快速。通过overlay驱动,多主机网络成为了Docker内部的首层网络,且无需额外的准备或组件。overlay使用Swarm分布式控制平面去提供集中化的管理,可以稳定安全地横跨整个大型群集网络。
VXLAN数据平面(data plane)
overlay驱动使用VXLAN数据平面工业标准,使容器网络脱离对物理网络的依赖。Docker overlay网络将容器流量封装在VXLAN包头中,如此就可以穿过2层和3层的物理网络。overlay使到网络不受物理网络拓扑的约束动态分段和易于控制。使用标准的IETF VXLAN包头捉使可以使用标准的工具去检查和分析流量。
注:VXLAN已成为Linux内核3.7版本以后的一部份。Docker使用原生的内核VXLAN特性去建立overlay网络。Docker overlay网络路径全部都在内核命名空间里。这样可以有更少的上下文切换,更少的CPU消耗,流量直接在应用和物理网卡之间传输。
IETF VXLAN(RFC 7348)是数据层的封装格式,可实现在3层网络之上进行2层分段。VXLAN的设计满足可以支持大规模应用的标准的IP网络、在共享物理网络基础架构上的多租户环境和基于云的网络,均可以支持VXLAN的透明传输。
VXLAN定义为将MAC封装在UDP中,将2层帧封装在IP/UDP包头中。在IP/UDP包头帧封下提供主机之间在低层网络传输。在每台主机之间建立overlay无状态VXLAN通道实现点对多点的连接,由于overlay不依赖低层网络的拓扑,所以使应用变得更加便捷。网络策略和连接不管是在内部部署,还是部署在开发者PC或公有云上都可以无源依赖物理网络,实现透明传输。
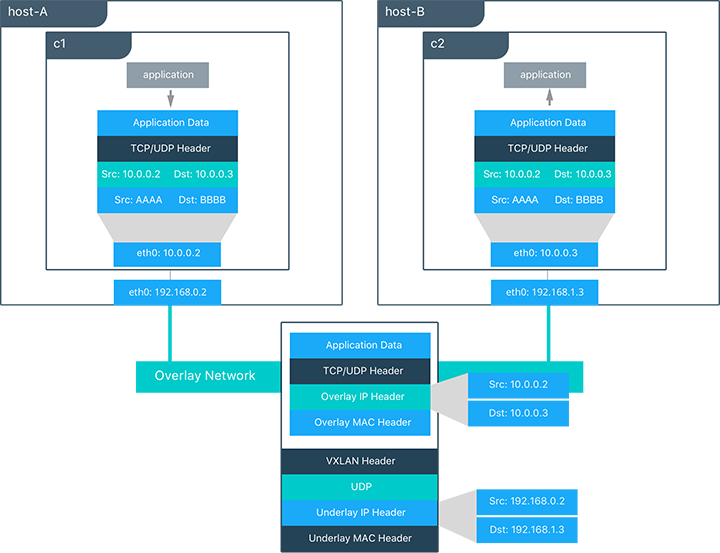
上图展示了数据包从容器c1到容器c2时横跨overlay网络的情况。
- c1对c2进行了DNS解释。两个容器都在同一overlay网络之中,Docker引擎提供了DNS服务器解释c2为overlay IP 10.0.0.3。
- 一个overlay网络就是一个2层网段,因此当出现容器c1到容器c2的通讯时,容器c1会根据容器c2的MAC地址会生成2层帧。
- 此框架通过overlay网络驱动,并由一个VXLAN包头所封装。分布式的overlay控制平面管理每个VXLAN通道端点的位置和状态,因此它知道c2是位置在物理地址为192.168.0.3的主机host-B,这个地址成为了低层IP包头中的目标地址。
- 只要将数据包封装成VXLAN包,物理网络就可以负责将它路由或桥接到正确的主机上。
- 数据包到达host-B的eth0接口后,由overlay网络驱动来解封装。从c1到c2的原始2层帧就会到达c2的eth0接口,并送达监听此数据包的应用。
overlay驱动的内部架构
Docker Swarm控制平面自动提供overlay网络。无需进行VXLAN配置或Linux网络配置。数据平面加密,是overlay的一个可选特性,由overlay驱动自动完成所有网络配置。只需使用docker network create -d overlay命令建立网络或将现有网络连接到已建好的overlay网络中。

在建立overlay网络的过程中,Docker引擎需要每台主机上都必须要有overlay。每建立一个overlay就会有一个Linux bridge关联到一个VXLAN接口上。只有当容器被连接到overlay网络时Docker引擎才会在主机上实例化overlay网络,如此预防了一些不存的容器使到overlay无端扩张。
以下实例建立一个overlay网络并连接一个容器到这个网络上。Docker Swarm/UCP自动建立overlay网络。以下实例要求先将Swarm或UCP配置好。
#Create an overlay named "ovnet" with the overlay driver
$ docker network create -d overlay --subnet 10.1.0.0/24 ovnet
#Create a service from an nginx image and connect it to the "ovnet" overlay network
$ docker service create --network ovnet nginx
当overlay网络建立好之后,注意此时主机内会多出几个接口和bridge,如下所示:
# Peek into the container of this service to see its internal interfaces
conatiner$ ip address
#docker_gwbridge network
52: eth0@if55: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
link/ether 02:42:ac:14:00:06 brd ff:ff:ff:ff:ff:ff
inet 172.20.0.6/16 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe14:6/64 scope link
valid_lft forever preferred_lft forever
#overlay network interface
54: eth1@if53: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450
link/ether 02:42:0a:01:00:03 brd ff:ff:ff:ff:ff:ff
inet 10.1.0.3/24 scope global eth0
valid_lft forever preferred_lft forever
inet 10.1.0.2/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:aff:fe01:3/64 scope link
valid_lft forever preferred_lft forever
两个在容器内部的接口对应两个在主机上的bridge。在overlay网络中,每个容器最少有两个接口分别连接到overlay和docker_gwbridge。
| Bridge |
目的 |
| overlay |
为在同一个overlay网络上的容器之间的流入和流出点提供VXLAN封装和加密。在所有主机上扩展overlay。会分配一个子网,并在参与的overlay网络上有相同的名字。 |
| docker_gwbridge |
流出群集的流出bridge,每台主机只会有一个docker_gwbridge。容器到容器的流量将无法在此通过。 |
注:Dockers Overlay驱动自从Docker引擎1.9后就已经存在,但需要一个额外的关键值存储去管理网络的状态。Docker引擎1.12将控制平面状态集成到Docker引擎,所以不再需要额外的关键值存储。1.12也引进了几个新特性,包括加密和服务负载均衡。旧版本的Docker引擎不支持新引进网络特性。
Docker服务的外部访问
Swarm & UDP提供群集发布端口的外部访问。虽然服务的流入和流出并不依赖中央网关,但分布在各主机的服务任务的流入/流出则不同。有两个服务端口发布的模式,分别是host模式和ingress模式。
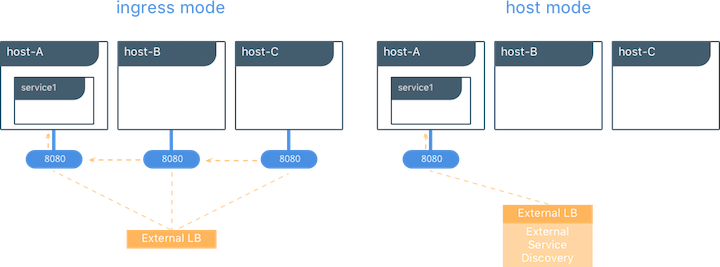
ingress模式的服务发布
ingress模式的端口发布使用Swarm Routing Mesh去应用负载均衡服务中的各个任务。 ingress模式在每个UCP/Swarm节点上发布并绑定端口。到发布端口的流入流量是通过Routing Mesh和轮询实现负载均衡,自动将流量从新导向到一个健康服务任务上。即使该主机上没有运行服务任务,流量也会被自动导向到另一台有运行该任务的主机上。
$ docker service create --replicas 2 --publish mode=ingress,target=80,published=8080 nginx
注:mode=ingress是服务的默认模式。这条命令也能使用简短版本-p 80:8080来定义。端口8080是绑定在每台群集主机上并负载均衡到这个服务的两个容器。
host模式的服务发布
host模式端口发布只在运行服务任务的主机上绑定端口。端口直接映射到该主机上的容器。每台主机只能运行一个服务任务,否则会出现端口冲突。
$ docker service create --replicas 2 --publish mode=host,target=80,published=8080 nginx
注:host模式需要使用mode=host参数。所发布的端口8080只会存在于运行那两个容器的主机上。不会应用负载均衡,因此流量只会直接流向本地容器。如此当同一个主机上运行多个相同的服务任务时会引起端口冲突。
Ingress设计
每种发布模式都有很多好的使用案例。ingress模式适合于服务有多个复制,并要求这些复制能实现负载均衡。host模式适合于已经由其它工具在外部实现了服务发现功能的场景。另一很好的host模式的案例是所有容器只会在一台主机上运行,且各容器都有各自特殊的使命(如监控和记录日志)而无需负载均衡。
MACVLAN
macvlan驱动是一个新推出的经过考验的真实网络虚拟化技术的实现。在Linux上的实现是非常轻量级的,因为它使用了Linux bridge来隔离,简单地关联一个Linux以太网接口或子接口以强制实现物理网络之间的隔离。
MACVLAN提供大量唯一的特性和功能。拥有非常简单和轻量级的架构意味着有积极的性能优势。MACVLAN驱动更优于端口映射,提供容器和物理网络之间的连接。允许容器可以获取能在物理网络上路由的IP地址。
MACVLAN使用案例很多,包括:
- 有非常低网络延迟需求的应用
- 网络设计要求容器要运行在同一个子网上并使用外部主机的网络
macvlan驱动可以使用父接口的概念。这个接口可以是一个物理接口如eth0。802.1q VLAN子接口如eth0.10(.10代表VLAN10),或者甚至可以结合主机的适配器将两个以太网接口捆绑成一个单一的逻辑接口。
在配置MACVLAN网络时需要一个网关。该网关必须由主机的外部网络基础架构来提供。MACVLAN网络允许在同一网络中的容器进行通讯。在同一主机但不同网络的容器在没有外部路由的情况下是无法通讯的。
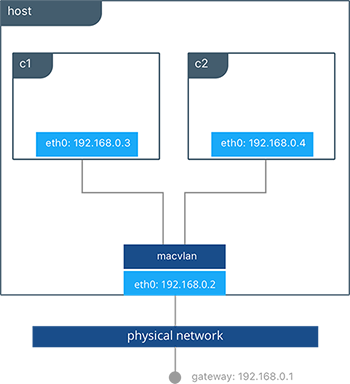
以下实例将MACVLAN网络绑定到主机的eth0上。同时还附加了两个容器到mvnet MACVLAN网络,并展示了它们是可以相互Ping通的。每个容器都有一个在192.168.0.0/24段物理子网的地址,并默认网关是物理网络上的网关。
#Creation of MACVLAN network "mvnet" bound to eth0 on the host
$ docker network create -d macvlan --subnet 192.168.0.0/24 --gateway 192.168.0.1 -o parent=eth0 mvnet
#Creation of containers on the "mvnet" network
$ docker run -itd --name c1 --net mvnet --ip 192.168.0.3 busybox sh
$ docker run -it --name c2 --net mvnet --ip 192.168.0.4 busybox sh
/ # ping 192.168.0.3
PING 127.0.0.1 (127.0.0.1): 56 data bytes
64 bytes from 127.0.0.1: icmp_seq=0 ttl=64 time=0.052 ms
如图所示,c1和c2都是通过主机的eth0附加到一个叫macvlan的MACVLAN网络上。
MACVLAN的VLAN 主干(trunk)
众所周知,主干(Trunking)802.1q的实现对于一台Linux主机是很困难的。它要求更改配置文件才能使在重启后依然生效。如一个bridge参与进来,就需要有一个物理网卡要被移入到该bridge中,并且bridge会获取IP地址。macvlan驱动通过建立,删除和重启主机来完全管理子接口和其它MACVLAN网络组件。
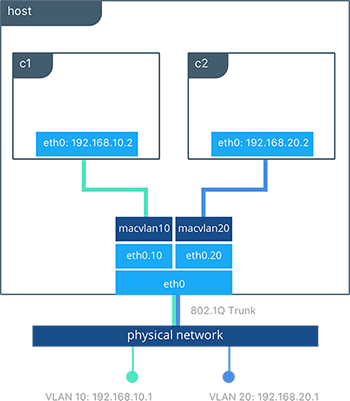
当macvlan驱动用子接口被实例化后,将允许在主机上实现VLAN主干,使容器可以在2层网络上分段。macvlan驱动会自动建立子接口并将这些接口连接到容器的接口上。由此可使每个容器都可以在不同的VLAN中,使它们不能通迅,除非有外部网关路由。
#Creation of macvlan10 network in VLAN 10
$ docker network create -d macvlan --subnet 192.168.10.0/24 --gateway 192.168.10.1 -o parent=eth0.10 macvlan10
#Creation of macvlan20 network in VLAN 20
$ docker network create -d macvlan --subnet 192.168.20.0/24 --gateway 192.168.20.1 -o parent=eth0.20 macvlan20
#Creation of containers on separate MACVLAN networks
$ docker run -itd --name c1 --net macvlan10 --ip 192.168.10.2 busybox sh
$ docker run -it --name c2 --net macvlan20 --ip 192.168.20.2 busybox sh
上述的配置,我们使用通过配置子接口的macvlan驱动建立了两个互相分隔的网络。macvlan驱动建立子接口并用以连接主机eth0和容器接口。主机接口和上游交换机必须要设置成主干模式switchport mode trunk,只有这样VLAN才可以被标记并通过此接口。一个或更多的容器可以连接到指定的macvlan网络以建立复杂的2层网络策略。
注:因为在一个主机接口上有多个MAC地址,所以可能要打开端口的杂乱模式,这还取决于网卡是否支持MAC过滤功能。
none(孤岛)网络驱动
和host网络驱动相似,none网络驱动基本上是一个无管理的网络选项。Docker引擎不会在容器内部建立接口,端口映射或安装连接路由。容器使用--net=none参数后就会完全与其它容器和主机孤立。网络管理员或外部工具必须要负责提供其它与外界联系的管道。使用none网络的容器内部只会有loopback接口。
与host 驱动不同,none驱动会建立一个与其它容器相隔离的命名空间。这样保证了容器网络与其它容器和主机的隔离。
注:容器使用--net=none或--net=host参数后将无法与其它Docker网络连接。
物理网络的设计要求
Docker EE和Docker网络是为一般的数据中心网络基础架构和拓扑而设的。集中的控制器和故障容忍群集保证兼容整个大型的网络环境。组件提供的连网功能(如网络提供,MAC地址学习,overlay加密)都是Docker引擎,UCP,或Linux内核自身的一部份。运行内置的网络驱动时无需任何额外的组件或特殊的网络特性。
更准备地说,Docker内置网络驱动没有以下要求:
- 多播
- 外部关键值存储
- 特殊路由协议
- 主机之间的2层邻接
- 特定的拓扑结构如主干&枝叶结构(spine&leaf),传统的3层结构,和PoD设计。任何类型的拓扑都支持。
容器网络模型提升了应用的可移植性,在所有的环境中均能保证性能要求并能达到应用的策略要求。
Swarm内置的服务发现
单一Docker引擎和一个由Docker Swarm部署的服务任务是使用Docker内嵌的DNS去提供服务发现功能。在用户自定义bridge、overlay网络和MACVLAN网络中Docer引擎有一个内部DNS服务器,它提供了所有在其上的容器的DNS解释。每个Docker容器(或Swarm模式下的服务任务)都有一个DNS解释器负责将DNS请求转发给Docker引擎,Docker引擎则充当DNS服务器的角色。Docker引擎会自动检查这此DNS请求,发现是属于对网络上容器或服务的请求时就会提供解释,为请求提供容器,任务或的服务名的IP地址或服务的虚拟IP(VIP),这些IP地址来源于内置的关键值存储。
服务发现是网络作用域(network-scoped),意思是只有在同一个网络中的容器或任务才能使用内嵌的DNS功能。在不同网络的容器不能相互解释IP地址。另外,节点只会保存参与到同一网络的容器或任务的DNS记录。这样特性提升了网络的安全性和性能。
对于源容器,如果目标容器或服务不属于同一个网络那么Docker引擎就会将DNS请求转发到配置的默认DNS服务器。
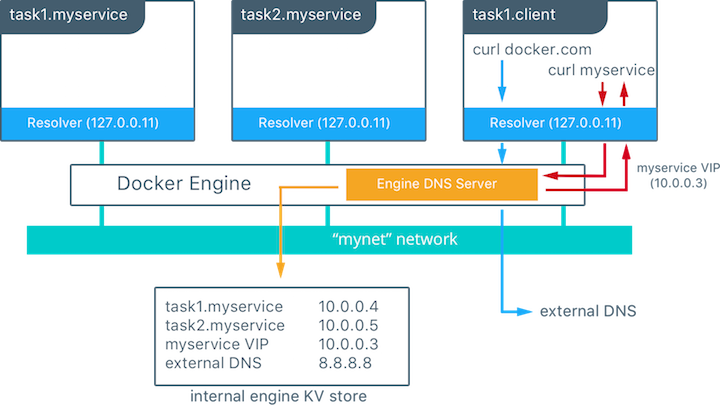
在此实例中有一个具有两个容器的服务,名叫myservice。在同一个网络上还有一个叫client的服务。client执行两个curl操作分别连接docker.com和myservice。有以下要求的动作:
- 容器内建的解释器在127.0.0.11:53上拦截DNS请求,并将请求转发给Docker引擎的DNS服务器。
- myservice解释为内部负载均衡的虚拟IP(VIP),再分发给相应的任务IP。
- docker.com不存在于mynet网络的服务名池中,所以请求会被转发到主机配置的默认DNS服务器。
Docker内置负载均衡
Docker Swarm群集有内置的内部和外部负载均衡功能。内部负载均衡在同一Swarm或UCP群集中提供容器之间的负载均衡。外部负载均衡为流入群集的流量提供负载均衡。
UCP内部负载均衡
内部负载均衡器是在Docker服务建立时自动被实例化的。当Docker Swarm群集建立一个服务时,他们会自动分配一个与服务处的于同一网络的VIP。服务名将会被解释为此IP。传输给VIP的流量会自动转发给voerlay网络内所有健康的服务任务。此法可以避免任何客户端的负载均衡由单一IP而返回给客户端。Docker安排路由并平等分配流量给所有健康的服务任务。

以下命令可以查看VIP,docker service inspect my_service
# Create an overlay network called mynet
$ docker network create -d overlay mynet
a59umzkdj2r0ua7x8jxd84dhr
# Create myservice with 2 replicas as part of that network
$ docker service create --network mynet --name myservice --replicas 2 busybox ping localhost
8t5r8cr0f0h6k2c3k7ih4l6f5
# See the VIP that was created for that service
$ docker service inspect myservice
...
"VirtualIPs": [
{
"NetworkID": "a59umzkdj2r0ua7x8jxd84dhr",
"Addr": "10.0.0.3/24"
},
]
注:DNS轮替(DNS RR)负载均衡,是另一个服务负载均衡可选项(通过配置--endpoint-mode参数来设定)。在DNS RR模式下并不是每个服务都会建立VIP。Docker DNS服务器会将服务名会以轮流的方式解释到各个独立的容器IP。
UCP外部4层负载均衡(Docker Routing Mesh)
在建立和更新服务时可以使用--publish参数绑定服务的对外端口。在Docker Swarm模式下发布端口就意味着所有节点都会监听此端口。但当该服务的任务没有在该节点运行时,它也会监听吗?
这是路由网格(routing mesh)发挥作用的地方。Routing mesh是Docker1.12的新功能,组合了ipvs和iptables去建立功能强大的群集级别的4层负载均衡器。它允许所有的Swarm节点去接受服务发布端口的连接。当任一Swarm节点接收以服务发布TCP/UDP端口为目标的流量时,它会将流量转发给预先定义好的叫ingress的overlay网络。该ingress网络行为与其它的overlay网络相似,只是它仅为来自外部客户端转输给群集服务而设。它与上文提及的基于VIP的内部负载均衡相同。
一旦运行了服务,就可以为应用映射到任一Docker Swarm节点,并建立一个统一的外部DNS记录。在routing mesh路由特性下,无需关心容器运行在哪一台节点上。
#Create a service with two replicas and export port 8000 on the cluster
$ docker service create --name app --replicas 2 --network appnet -p 8000:80 nginx
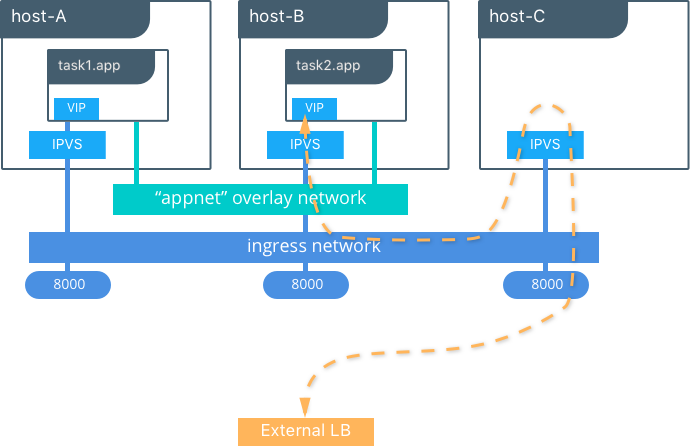
上图展示了Routing Mesh是如何工作的。
- 一个服务建立了两个复制,并发布了一个8000的外部端口。
- routing mesh在群集中的所有主机都绑定了8000端口。
- 流量的目标app可以进入任一节点。上例中External LB将流量发送到没有运行服务复制的节点上。
- 内核的IPVS负载均衡将流量重定向到overlay网络上的健康服务复制。
UCP外部7层负载均衡器(HTTP Routing Mesh)
UCP通过HTTP Routing Mesh提供7层HTTP/HTTPS负载均衡功能。URLs可负载均衡到服务和服务复制。
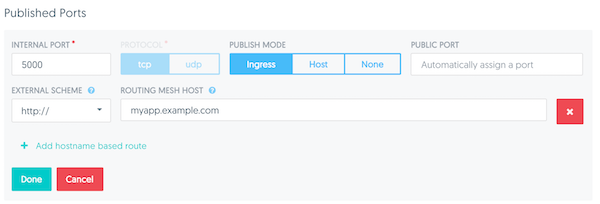
点击UCP负载均衡参考架构获取更多关于UCP 7层LB设计。
Docker网络安全和加密
网络安全是在设计和实现docker容器负载时最应考虑的问题。此节包含Docker网络安全考虑的关键内容。
网络分段和数据平面安全
Docker管理分布式的防火墙去分段容器网络并防止对容器资源恶意访问。默认情况下,Docker网络会分段隔离流量。此方法提供了真正的3层网络隔离。
Docker引擎管理主机的防火墙规则以预防网络和容器发布的管理端口互相访问。在一个Swarm&UCP群集中会建立分布式的防火墙以动态保护群集中的应用运行实例。
下表列出了Docker网络的访问策略。
| 路径 |
访问 |
| 在相同Docker网络 |
在同一Docker网络中的所有接口是被允许访问的。此规则适用于所有网络类型,如swarm scope, local scope, build-in, 和远程驱动。 |
| 在Docker网络之间 |
在Docker引擎管理的分布式主机防火墙下Docker网络之间的访问是被拒的。容器可以附加到多个网络以达到和多个Docker网络通迅的目的。Docker网络之间的网络连接也可以管理为通向外部主机。 |
| 从Docker网络流出 |
从Docker网络流出是被允许的。返回流量会通过本地防火墙并安全地被自动允许。 |
| 流入到Docker网络 |
流入流量默认被拒绝。端口通过host端口或ingress模式发布端口提供特定的流入访问。
一个例外情况是MACVLAN驱动操作与主机相同的IP空间,使容器网络完全开放。其它远程网络驱动提供与MACVLAN类似的功能也是允许流入流量。
|
控制平面安全
Docker Swarm集成了PKI。所有在Swarm的管理端和节点都会从一个已签名证书中得到一个已签名的加密标识。所有管理端到管理端和管理端到节点的控制通迅都通过开箱即用的TLS安全加密。在Swarm模式中无需在外部生成证书或手动设置任何证书颁发机构去得到端到端的控制平面流量加密。证书会定期自动轮换。
数据平面网络加密
Docker开箱即用的overlay网络支持IPSec加密。Swarm&UCP在流量离开源容器时管理IPSec通道加密码网络流量,并在流量到达目标容器后解密流量。这样确保应用流量的高安全性而无需关注低层网络环境。在一个混合的,多租户的或多云的环境中,这是确保数据横跨网络不会超出控制的安全关键。
下图展示了运在一个Docker Swarm中的两个容器之间如何安全通迅。
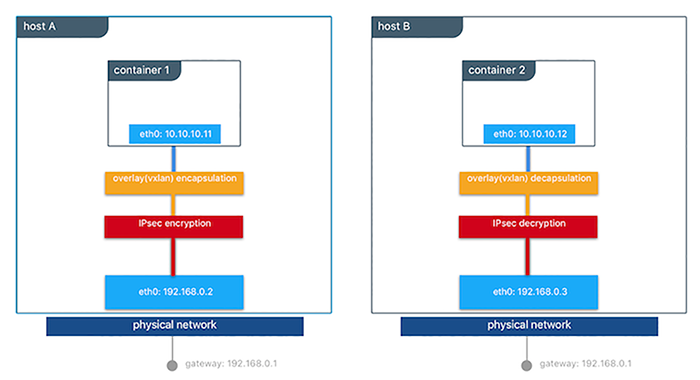
这个特性可在每个网络建立时添加--opt encryted=true参数时启用(如:docker network create -d overlay --opt encrypted=true <NETWORK_NAME>)。网络建立后就可以在网络中建立服务(如:docker service create --network <NETWORK_NAME> <IMAGE> <COMMAND>)。当同一个服务在两个不同的主机上建立任务时,一个IPsec在之主机之间的通道就会被建立,当流量离开源主机时被加密,进入目标主机后会被解密。
Swarm领导者会定期再生成一个对称钥匙并安全地分发到所有群集内的节点。这个钥匙是由IPsec用于加密和解密数据平面流量。加密是通过IPSec在主机对主机(host-to-host)使用AES-GCM转输模式。
管理面安全&UCP中的RBAC
当使用CUP建立网络时,工作组和标签定义到容器资源的访问。资源权限标签定义了什么人可以查看,配置,和使用指定的Docker网络。

这个UCP截屏展示了使用production-team标签如何云控制网络只允许团队的成员访问。另外,如网络加密选项可以通UCP来套接。
IP地址管理
容器网络模型(CNM)提供了IP地址的灵活管理。有两种IP地址的管理方法。
CNM有内置的IPAM驱动,简单的全局地为群集分配IP地址并预防了重复分配。内置的IPAM驱动是用于没任何特别的设定下默认配置。
CNM有使用来自其它供应商和社区的远程IPAM驱动接口。这些驱动使到可以与现有供应商和自建的IPAM工具进行集成。
使用UCP可以进行人工配置容器的IP地址和子网,如CLI或Docker API。这些地址取自于这些决定如何处理请求的驱动。
子网的大小和设计是非常依赖于特定的应用和特殊的网络驱动。IP地址空间在网络部署模型中有更深入的描述。包括端口映射,overlay,和MACVLAN都表达了IP地址是如何组织的。一般情况下容器地址会被分别放置到两个桶里。内部容器网络(bridge和overlay)IP地址默认是不能在物理网络上路由的。从而,来自容器接口的流量是可以在物理网络上路由的。这对节点物理网络的子网和内部网络(bridge, overlay)不会发生IP冲突很重要。重复的地址空间会导致流量无法到达目的地。
网络排错
Docker网络的排错对于开发者和网络工程师来说都是很难的。通过很好地理解Docker网络是如何工作并正确地设置工具,就可以排错和解决这些网络问题。一个推荐的方法是使用netshoot容器来排查网络问题。netshoot容器有一套强大的网络排错工具可以用于排查Docker网络问题。
使用排错容器如netshoot,这些网络排错工具非常便捷。netshoot容器可以附加到任一网络,能放在主机网络命名空间,或在另一个容器的网络命名空间去检查主机网络的任一角度。
此容器包含以下工具:
- iperf
- tcpdump
- netstat
- iftop
- drill
- util-linux(nsenter)
- curl
- nmap
网络部署模型
以下实例使用了虚构的叫做Docker Pets的app,展示了网络部署模型。在网页上展出了宠物的图片,记录了页面的点击计数,此计数保存在后端数据库。
- web是前端网页服务器,基于chrch/docker-pets:1.0镜像
- db是一个consul后端
chrch/docker-pets依赖一个环境变量DB,来指定如何找到后端db服务。
单一主机的Bridge驱动
这个模型是内置Docker bridge网络驱动的默认行为。这个bridge驱动建立了一个连接到主机的私有网络,并提供一个在主机接口上的外部端口映射以提供对外连接。
$ docker network create -d bridge petsBridge
$ docker run -d --net petsBridge --name db consul
$ docker run -it --env "DB=db" --net petsBridge --name web -p 8000:5000 chrch/docker-pets:1.0
Starting web container e750c649a6b5
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
注:当IP地址没有指定时,端口映射绑定在主机的所有接口上。在此案例中容器的应用是绑定在0.0.0.0:8000。要提供特定IP地址的宣告就要使用-p IP:host_port:container_port参数。更多的关于端口发布的可选项可以在Docker文档库中找到。
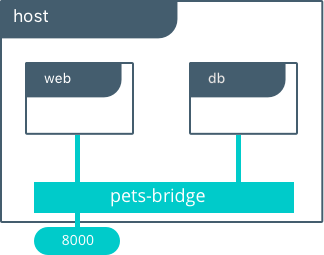
此应用在主机上的所有接口绑定了8000端口。也提供Db=db,提供后端容器的名字。Docker引擎的内建DNS解释这个容器的名字为db的IP地址。由于bridge是本地驱动,DNS决定的作用域只在单台主机上。
以下命令显示了我们的容器已经分配了来自petsBridge网络的172.19.0.0/24 IP空间的私有IP。在没有特别指定IPAM驱动时Docker会使用内建的IPAM驱动去提供一个来自适合子网的IP。
$ docker inspect --format {{.NetworkSettings.Networks.petsBridge.IPAddress}} web
172.19.0.3
$ docker inspect --format {{.NetworkSettings.Networks.petsBridge.IPAddress}} db
172.19.0.2
这些IP地址被用于通往petsBridge网络的内部通迅。这些IP从来不会离开该主机。
带外部服务发现的多主机bridge驱动
因为bridge驱动是一个本地作用域驱动,所以多主机网络需要一个多主机服务发现(SD)解决方案。外部SD注册了容器或服务的位置和状态,并允许其它服务去发现他们的位置。因为bridge驱动通过绑定端口去实现外部访问,外部SD存储host-ip:port作为指定容器的位置。
在以下例子中,每个服务的位置都要手动配置,模仿外部服务发现。db服务的位置是通过DB环境变量传递给web的。
#Create the backend db service and expose it on port 8500
host-A $ docker run -d -p 8500:8500 --name db consul
#Display the host IP of host-A
host-A $ ip add show eth0 | grep inet
inet 172.31.21.237/20 brd 172.31.31.255 scope global eth0
inet6 fe80::4db:c8ff:fea0:b129/64 scope link
#Create the frontend web service and expose it on port 8000 of host-B
host-B $ docker run -d -p 8000:5000 -e 'DB=172.31.21.237:8500' --name web chrch/docker-pets:1.0
web服务在主机host-B IP地址的8000端口提供网页。
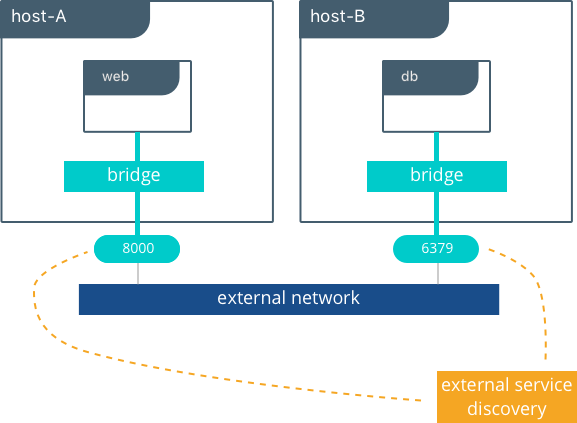
注:在此实例中我们没有特别指定一个网络,所以默认是自动选择使用Docker bridge网络。
当我们配置db的位置在172.31.21.237:8500时,我们正在建立一个服务发现的表格。我们为web服务静态地配置db服务的位置。在单一主机的实例中,这个工作将由Docker引擎提供内建的DNS决定容器名称来自动完成。在多主机的实例中我们通过手动配置服务发现。
在生产环境不推荐使用硬编码的应用位置。外部服务发现工具的存在提供了这个映射在群集中可以动态地建立和删除。例如:Consul和etcd。
下一节将研究overlay驱动方案,它提供了在群集中的内建全局服务发现特性。相对于使用多个外部工具去提供网络服务,简单是overlay驱动的一大主要优势。
带overlay驱动的多主机
此模型合用了内置overlay驱动去提供开箱即用的多主机连接。overlay驱动的默认设置在一个容器应用之内提供到除内部连接之外的外部连接。overlay驱动架构一节中回顾了overlay驱动的内部,在阅读此节时请先回顾该节内容。
这个实例再次使用docker-pets应用。在下例中建立了一个Docker swarm。关于如何建立Swarm请参阅Docker文档库。Swarm建立好之后,使用docker service create命令去建立由Swarm管理的容器和网络。
以下展示了如何检查Swarm,建立一个overlay网络,然后在overlay网络上提供几个服务。所有这些命令都要在UCP/Swarm控制器上运行。
#Display the nodes participating in this swarm cluster that was already created
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
a8dwuh6gy5898z3yeuvxaetjo host-B Ready Active
elgt0bfuikjrntv3c33hr0752 * host-A Ready Active Leader
#Create the dognet overlay network
host-A $ docker network create -d overlay petsOverlay
#Create the backend service and place it on the dognet network
host-A $ docker service create --network petsOverlay --name db consul
#Create the frontend service and expose it on port 8000 externally
host-A $ docker service create --network petsOverlay -p 8000:5000 -e 'DB=db' --name web chrch/docker-pets:1.0
host-A $ docker service ls
ID NAME MODE REPLICAS IMAGE
lxnjfo2dnjxq db replicated 1/1 consul:latest
t222cnez6n7h web replicated 0/1 chrch/docker-pets:1.0
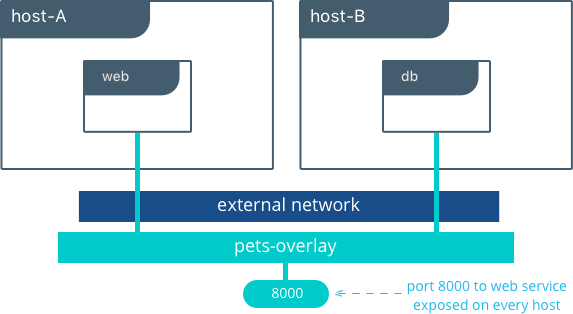
在此单主机bridge实例中,我们通过DB=db作为环境变量,到web服务。overlay驱动解释db服务的名字为容器的overlay IP地址。发生在web和db之间的通迅仅仅使用overlay IP子网。
注:overlay和bridge网络内部,所有到容器的TCP和UDP端口是打开并关联到所有其它附加到overlay网络的容器。
web服务发布了8000端口,且routing mesh在所有Swarm群集主机上发布了8000端口。在浏览器中使用<host-A>:8000或<host-B>:8000来测试这个应用是否正在工作。
overlay的优点和使用案例
- 对于小型和大型的多主机连接部署都非常简单
- 无需额外配置或组件就可以提供服务发现和负载均衡
- overlay加密对于横向微分段很有用
- routing mesh可用于在整个群集中宣布服务
App教程: MACVLAN bridge 模式
在很多情况下,应用或网络环境要求容器有可以在低层物理网络上路由的IP地址。MACVLAN驱动使这成么现实。在MACVLAN架构章节中有描述。一个MACVLAN网络将自己绑定在主机接口上。这个接口可以是物理接口,逻辑子接口或绑定的组逻辑接口。它可以充当一个虚拟交换机并提供在同一MACVLAN网络上的容器之间的通迅。每个容器接收到唯一的附加节点的物理网络MAC地址和IP地址。
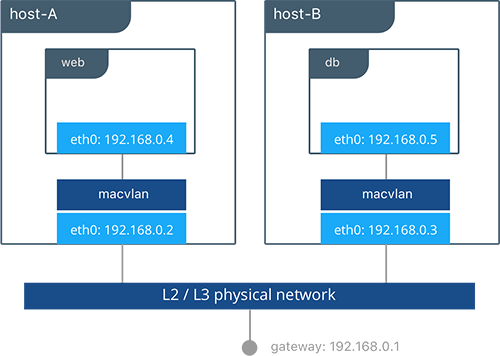
在此实例中,Pets应用被部署在Host-A和Host-B上。
#Creation of local macvlan network on both hosts
host-A $ docker network create -d macvlan --subnet 192.168.0.0/24 --gateway 192.168.0.1 -o parent=eth0 petsMacvlan
host-B $ docker network create -d macvlan --subnet 192.168.0.0/24 --gateway 192.168.0.1 -o parent=eth0 petsMacvlan
#Creation of db container on host-B
host-B $ docker run -d --net petsMacvlan --ip 192.168.0.5 --name db consul
#Creation of web container on host-A
host-A $ docker run -it --net petsMacvlan --ip 192.168.0.4 -e 'DB=192.168.0.5:8500' --name web chrch/docker-pets:1.0
由此可见与多主机bridge实例非常相似,但有以下值得注意的不同点:
- 从web到db使用db自己的IP相对于主机IP。请记住macvlan容器IP是可以在低层网络路由的。
- db或web没有发布任何端口,因为所有容器中的端口都是打开的,并可以使用容器的IP立即到达。
当macvlan驱动提供这个唯一特性时,一方面是牺牲了可移植性。低层MACVLAN配置和部署工作量很大,容器地址必须要附着在容器放置的物理位置,另外还要防止地址的重复分配。因此MACVLAN网络必须要使用外部的IPAM。重复的IP地址或不正确的子网将会导致容器丢失连接。
MACVLAN优点和使用案例
- 由于无需使用NAT所以macvlan驱动有非常低的应用延迟。
- 在有一些要求中,MACVLAN可以为每个应用提供一个IP。
- IPAM必须要谨慎考虑。
结论
Docker是一个快速发展的技术,而且连网选项的应用案例每天都会有显著的增加。现任网络供应商,纯粹的SDN供应商,和Docker自己都是这个领域的贡献者。与物理网络有牢固的一体化,网络监控,和加密对各个领域都很有利并带来革新。
这个文档详细说明了一些(但并不是所有)现在的CNM网络驱动可能的部署方式。当然还有很多其它驱动或其它更多方法去配置那些驱动,这里只是介绍了很少数的常规模型的部署方式。去很好地了解并权衡每一个模型才是长期成功的关键。