通常使用循环神经网络处理NLP(自然语言处理)问题,循环神经网络模型特点决定了输出与输入维度不同,但数量相同,这显然有违常识,比如分词后中文句子'我 去 上班'翻译成英文后是'i am going to work',源语言与目标语言在表达同一个意思时,单词的数量是不一样的,Minh-Thang Luong 于 2016 年发表了论文“Neural Machine Translation”,引入了编码器–解码器结构,seq2seq利用这个结构可实现机器翻译、对话系统、文摘功能。
一、seq2seq模型
处理NLP例如翻译问题时,seq2seq模型先使用编码器将源语言转为一个语义向量,将语义向量作为初始值输入到解码器后实现翻译,编码器和解码器通常主体是循环神经网络,如RNN,LSTM,GRU等。编码与解码过程借鉴了通讯信号技术,信号经过调制后将声音、图像这些模拟信号转为数字信号,这个过程可称为编码过程;而在信号接收端,比如我们的手机,通过解调将数字信号还原为模拟信号,这称为解码过程。信号转换的过程类似于NLP的语言翻译过程,下面以傅里叶变换、逆变换为例演示信号的编码-解码。
import numpy as np
import matplotlib.pyplot as plt
from scipy.fftpack import fft,ifft
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#采样频率
N=120
#加载信号
def loadsignal(N ):
x = np.linspace(0, 1, N)
y = 2 * np.sin(2 * np.pi * 50 * x) + 1.5 * np.sin(2 * np.pi * 30 * x) + 3.1 * np.sin(2 * np.pi * 20 * x)
return x,y
if __name__=='__main__':
x,y=loadsignal(N)
plt.subplot(311)
plt.title('原信号')
plt.plot(x,y,color='blue')
plt.subplot(312)
fft_y = fft(y)
#编码过程:利用傅里叶变换将时域信号变为频域信号
abs_y = abs(fft_y)
plt.title('编码:信号调制后')
x2 = np.arange(N)
x2 = x2[range(int(N / 2))]
y2 = 2*abs_y /N
y2 = y2[range(int(N / 2))]
plt.plot(x2, y2,color='red')
plt.subplot(313)
#解码过程:利用傅里叶逆变换将频域信号还原为时域信号
y3=ifft(fft_y)
plt.title('解码:信号解调后')
plt.plot(x , y3, color='blue')
plt.show()
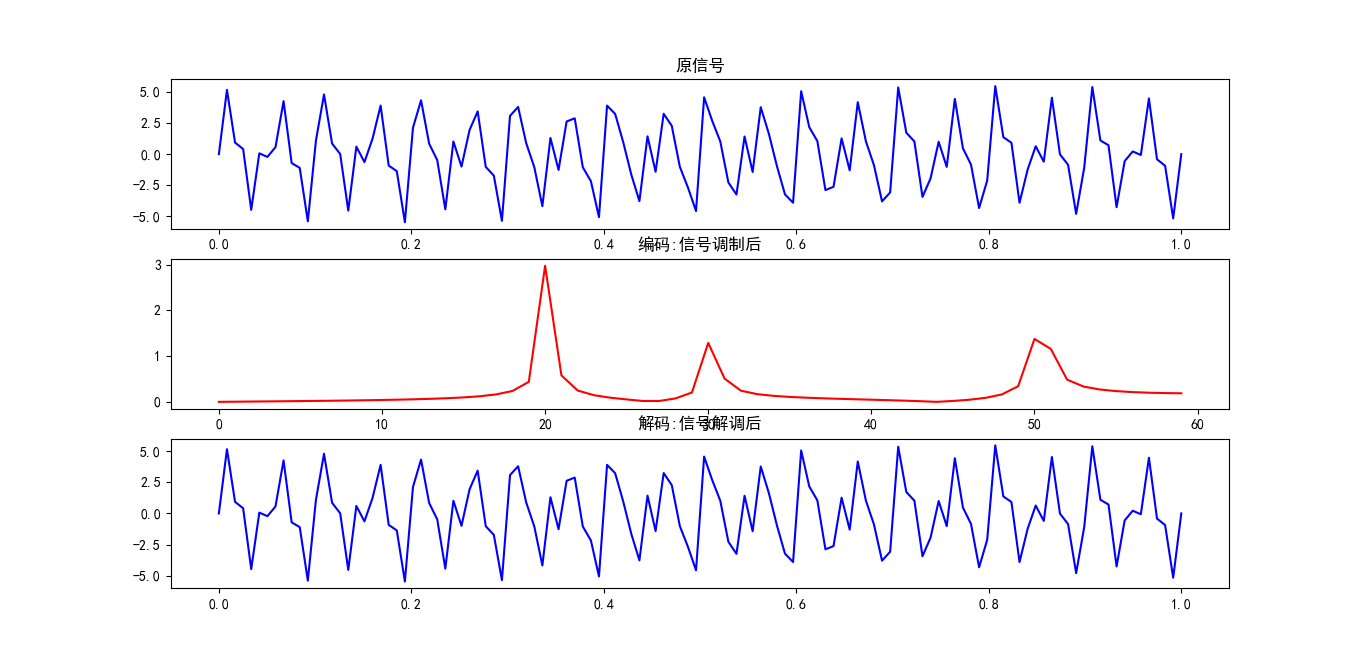
通过傅里叶变换/逆变换来类比seq2seq可以更好理解 seq2seq模型,上面第二张图代表傅里叶变换将时域的信号转换为频域的信号,第三张图代表利用傅里叶逆变换将频域的信号再还原为时域信号。常见的seq2seq模型如下图所示:
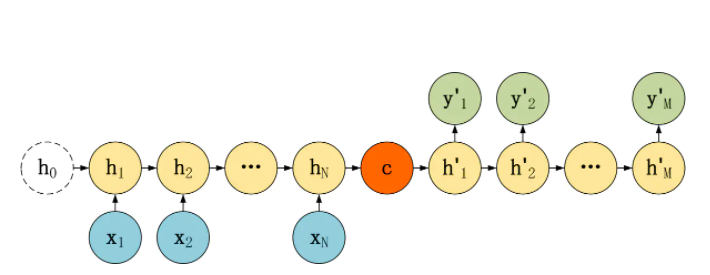
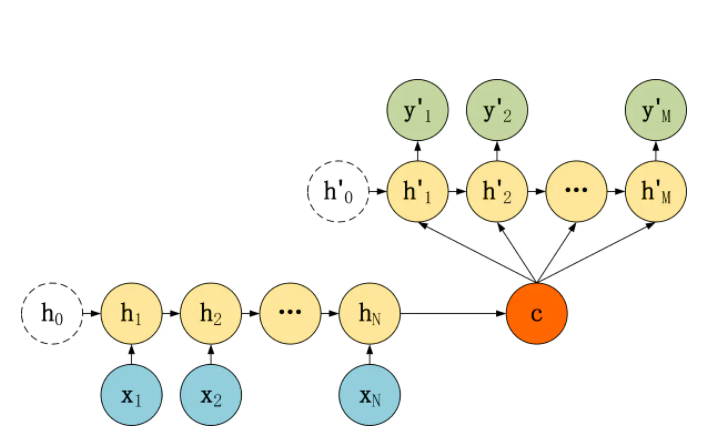
上图左侧是编码器,这是按时间展开的循环神经网络,输入向量x1,x2,x3以序列形式依次输入编码器,在每一个时刻除了接受输入外还接受上一时刻隐藏层的输入:h1,h2,h3,....,hN,并将最后时刻隐藏层的输出向量c作为语义向量,语义向量c作为初始隐藏层的值输入到解码器中;解码器每个时刻将上一时刻隐藏层的输出、目标语言序列向量作为输入,如实际目标语言序列是:y1,y2,y3,....,yM,而解码器产生序列输出y'1,y'2,y'3,....,y'M。一般利用交叉熵作为损失函数,从解码器端向编码器反向优化。以上并不是seq2seq模型的固定形式,解码器端也可以每次都接受编码器的语义变量c作为输入如下图:
接下来利用seq2seq模型实现法语翻译为英语,运行前下载英法训练文本文件:训练文件,并把训练文件放置到程序所在目录的data文件夹下。
import torch
import torch.nn as nn
import torch.optim as optim
import random
import math
import time
import unicodedata
import re
import torch.nn.functional as F
MAX_LENGTH=20
SOS_token = 0
EOS_token = 1
languiage_input='eng'
languiage_output='fra'
teacher_forcing_ratio = 0.5
device=None
hidden_size = 256
n_Iters=20000
#词汇表功能
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
class readTools:
def __init__(self):
pass
@staticmethod
def unicode2Ascii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
@staticmethod
def normalizeString(s):
s = readTools.unicode2Ascii(s.lower().strip())
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s
@staticmethod
def readLangs(lang1, lang2, reverse=False):
lines = open('data/%s-%s.txt' % (lang1, lang2), encoding='utf-8'). \
read().strip().split('\n')
pairs = [[readTools.normalizeString(s) for s in l.split('\t')] for l in lines]
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
@staticmethod
def prepareData(lang1, lang2, reverse=False):
input_lang, output_lang, pairs = readTools.readLangs(lang1, lang2, reverse)
for pair in pairs:
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
print("字典数量:")
print(input_lang.name, input_lang.n_words)
print(output_lang.name, output_lang.n_words)
return input_lang, output_lang, pairs
@staticmethod
def asMinutes(s):
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
@staticmethod
def timeSince(since, percent):
now = time.time()
s = now - since
es = s / (percent)
rs = es - s
return '%s (- %s)' % (readTools.asMinutes(s), readTools.asMinutes(rs))
@staticmethod
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
@staticmethod
def tensorFromSentence(lang, sentence):
indexes = readTools.indexesFromSentence(lang, sentence)
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)
@staticmethod
def tensorsFromPair(pair):
input_tensor = readTools.tensorFromSentence(input_lang, pair[0])
target_tensor = readTools.tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)
#编码器
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
input = embedded
output, hidden = self.gru(input, hidden)
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
#解码器
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super(DecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.torch = torch.tanh
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden ):
output = self.embedding(input).view(1, 1, -1)
output = self.torch(output)
output, hidden = self.gru(output, hidden)
output=self.out(output[0,:,:])
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
def train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=MAX_LENGTH):
encoder_hidden = encoder.initHidden()
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
input_length = input_tensor.size(0)
target_length = target_tensor.size(0)
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
loss = 0
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(input_tensor[ei], encoder_hidden)
encoder_outputs[ei] = encoder_output[0, 0]
decoder_input = torch.tensor([[SOS_token]], device=device)
decoder_hidden = encoder_hidden
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
if use_teacher_forcing:
# Teacher forcing: Feed the targer as the next input
for di in range(target_length):
decoder_output, decoder_hidden = decoder(
decoder_input, decoder_hidden )
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # Teacher forcing
else:
# Without teaching forcing: use its own predictions as the next input
for di in range(target_length):
decoder_output, decoder_hidden = decoder(
decoder_input, decoder_hidden )
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach() # detach from history as input
loss += criterion(decoder_output, target_tensor[di])
if decoder_input.item() == EOS_token:
break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_length
def trainIters(encoder, decoder, n_iters, print_every=100, plot_every=1000, learning_rate=0.001):
start = time.time()
print_loss_total = 0
plot_loss_total = 0
encoder_optimizer = optim.Adam(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.Adam(decoder.parameters(), lr=learning_rate)
training_pairs = [readTools.tensorsFromPair(random.choice(pairs)) for i in range(n_iters)]
criterion = nn.NLLLoss()
for iter in range(1, n_iters + 1):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion)
print_loss_total += loss
plot_loss_total += loss
if iter % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print('%s (%d %d%%) %.4f' % (readTools.timeSince(start, iter / n_iters),
iter, iter / n_iters * 100, print_loss_avg))
evaluateRandomly(encoder, decoder)
def evaluate(encoder, decoder, sentence, max_length=MAX_LENGTH):
with torch.no_grad():
input_tensor = readTools.tensorFromSentence(input_lang, sentence)
input_length = input_tensor.size()[0]
encoder_hidden = encoder.initHidden()
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(input_tensor[ei], encoder_hidden)
encoder_outputs[ei] += encoder_output[0, 0]
decoder_input = torch.tensor([[SOS_token]], device=device) # SOS
decoder_hidden = encoder_hidden
decoded_words = []
for di in range(max_length):
decoder_output, decoder_hidden = decoder(
decoder_input, decoder_hidden )
topv, topi = decoder_output.data.topk(1)
if topi.item() == EOS_token:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(output_lang.index2word[topi.item()])
decoder_input = topi.squeeze().detach()
return decoded_words
def evaluateRandomly(encoder, decoder, n=3 ):
for i in range(n):
pair = random.choice(pairs)
print('法 语:', pair[0])
print('英 语:', pair[1])
output_words = evaluate(encoder, decoder, pair[0])
output_sentence = ' '.join(output_words)
print('翻译结果:', output_sentence)
print('')
if __name__=='__main__':
#法文翻译为英文
input_lang, output_lang, pairs = readTools.prepareData(languiage_input, languiage_output, True)
encoder1 = EncoderRNN(input_lang.n_words, hidden_size).to(device)
decoder = DecoderRNN(hidden_size, output_lang.n_words).to(device)
trainIters(encoder1, decoder, n_Iters, print_every=100)
读取文本文件,利用类Lang实现不同语言词汇的属性,分别形成英语词典和法语词典,对每种语言的单词形成唯一的数字编号,这样就可以把句子向量化,比如单词i,am,student的索引分别是10,21,100,句号.索引是9,则句子i am student.可以向量话为[10,21,100,9],静态函数indexesFromSentence实现这样的功能。训练模型的时需要将每个句子中的单词处理成one-hot向量输入到编码器和解码器中。比如一个Lang类中单词库只有3个,则索引为2的单词可表示成[0,1,0]。本例中单词有几千个,可以想象每个单词向量处理成one-hot向量后,只有一个位置是1其他位置都是0,这样向量输入模型后非常占用存储空间,而大部分的内容其实是0,用one-hot表示的句子是一个稀疏矩阵。
为了处理稀疏矩阵,降低存储压力、提高运算效率,在解码器和编码器中利用embedding函数将one-hot向量线性映射成一个低维向量,这个线性映射的矩阵表示是一个均匀随机分布矩阵。本例中每个one-hot向量被处理成一个256维的向量,256同时也是循环神经网络隐藏层和输出层的维度,编码器和解码器都是使用gru循环神经网络,gru是循环神经网络LSTM简化模型。训练模型时每次取一个向量化后句子,句中每个单词逐个输入,编码器都是以自定义字符EOS作为输入结束标志;而解码器都是以自定义字符SOS作为输入开始,EOS作为输入结束标志。
在训练解码器过程中使用了Teacher forcing机制:按一定的概率,每次取目标句子相应的单词或取上一时刻解码器的输出作为下一时刻的输入。Teacher forcing机制曾在Google的一篇论文中提到,在实践中可以大大提高循环神经网络的鲁棒性。
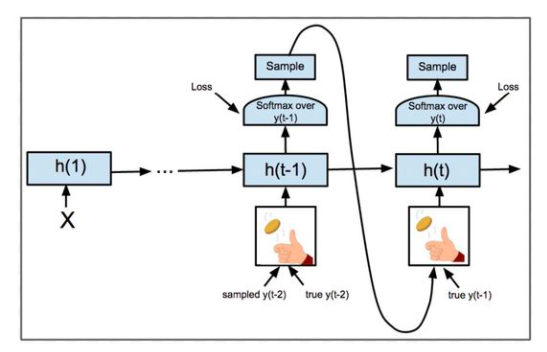
二、带attention机制的seq2seq
仍以傅里叶变换、逆变换为例,由数学分析知识可知,不同信号经过傅里叶变换后可能是相同的频域图,这样一来再经过傅里叶逆变换后,还原后的时域图像可能与源信号不一致。这是因为傅里叶变换后是一个频率汇总的信号结构,傅里叶变换后略去了不同信号在时序上各自特征。为了规避这个缺点,傅里叶变换时常采用缩小窗口的机制,具体来说,把采样时间缩短,把注意力集中在信号的各个时段的细节上。
上面的seq2seq模型也有同样的问题,以中译英为例,源句是中文‘机器学习’,目标句是英语‘mechine learnging',按上面的模型结构,编码器产生语义向量c,可以想象,语义向量c中融合了中文词‘机器‘、’学习’这两个词所有的信息,而在训练解码器时,当输入mechine时,显然需要c中偏重中文词‘机器’;同样,当输入learnging时显然希望c中'学习'的比重多一些,这在翻译中称为‘对齐’。上面的seq2seq模型无论采用何种结构,语义向量c在解码器所有时刻的输入都是一样的。先不考虑技术实施的细节,为了解决这个问题,如果能实现每次解码器输入时,有不同的语义向量c,且每个时刻的c能结合目前解码器的输入对源句中相对应的词有准确的侧重,这就是attention机制。对比傅里叶变换,attention机制缩小了对源句(源信号)采样窗口,生成了更有助于解码器理解的中间信息,带attention机制的seq2seq模型如下图所示:
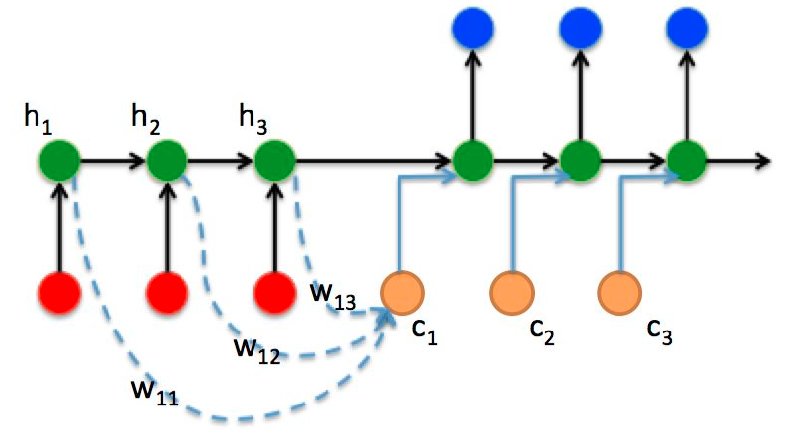
设编码器的输入为
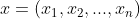
,每个时刻编码器隐藏层的输出为

,公式中RNN代表循环神经网络,可以为RNN、LSTM、GRU等。不带attention机制的seq2seq把最后一个时刻隐藏层输出作为语义向量c,而带attention机制的seq2seq要保存编码器所有时刻隐藏层输出。
文章余下部分请转至链接:seq2seq,attention注意力机制