初学者学习Pytorch系列
第一篇 Pytorch初学简单的线性模型 代码实操
第二篇 Pytorch实现逻辑斯蒂回归模型 代码实操
第三篇 Pytorch实现多特征输入的分类模型 代码实操
前言
- 本文的输入数据集是基于一个糖尿病预测的案例。输入的大概意思是,给病人测试8次身体情况,预测明年是否会病情加重。这个8次,就是作为多特征的输入,8个特征,是否加重(0表示不会加重,1表示加重)作为一个二分类问题。
一、先上代码
代码如下(解释已经写在代码中):
import numpy as np
import torch
xy = np.loadtxt('../data/diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, [-1]]) # 这里第二维度用[-1],可以使分割出来的是矩阵
# 不加[]是[1.0.2.0,3.0],加了后是[[1.0],[2.0],[3.0]],
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
# 定义损失函数
criterion = torch.nn.BCELoss(reduction='mean')
# 优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(10000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
if epoch > 9900:
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
二、测试结果
1. 数据结果
从9979 轮开始展示
轮数 损失
9979 0.4617641568183899
9980 0.46176356077194214
9981 0.4617629647254944
9982 0.461762398481369
9983 0.46176180243492126
9984 0.46176114678382874
9985 0.46176064014434814
9986 0.461760014295578
9987 0.46175938844680786
9988 0.4617588222026825
9989 0.46175816655158997
9990 0.4617575705051422
9991 0.4617570638656616
9992 0.4617564380168915
9993 0.4617558419704437
9994 0.46175524592399597
9995 0.4617546796798706
9996 0.46175411343574524
9997 0.4617534875869751
9998 0.46175292134284973
9999 0.4617522656917572
三、代码说明
1. 数据集引入
xy = np.loadtxt('../data/diabetes.csv.gz', delimiter=',', dtype=np.float32)
这里是导入数据集,文件的位置是相对位置。在项目中的位置如下:

数据来源:B站刘二大人课程资料
链接:https://pan.baidu.com/s/1_J1f5VSyYl-Jj2qIuc1pXw
提取码:wyhu
2.对Model类的理解
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
这里对初学者可能会很不理解为什么要从8维到6维再到4维再到1维?而且为什么每次都要通过sigmoid?
- 这里的维度的变化,没变化一次就是深度学习里面的一层 (对于层的理解,可以把它看成一个过滤网,一层层过滤掉信息),层数多可以进行精细化一点的处理,在这个例子中也可以从8维到5维到3维再到1维,但是选用哪种好,是另一个问题,但是并不是过滤得越多越好,过滤越多学习能力太强,可能会把一些噪声的特征也学习进来。
这里可能有人会问为什么每一层都需要应该sigmoid函数?
-
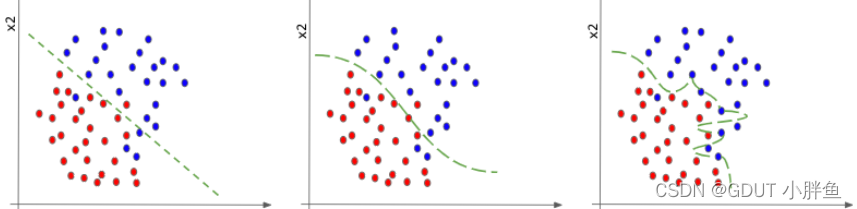
首先得了解sigmoid是什么,它是一个激活函数,是给我们的线性函数(linear直线模型)做非线性变化的,这里又涉及到一个问题:为什么要做非线性变化? 这里我找到一张图片,很好的表现的为什么线性模型不行。
-
下图又两种颜色的点,我们需要使用深度学习将下面两种点进行分割,在第一张图中,只是线性模型,进行区分的能力有限,如果图中的点再多点再乱点,是无法满足需求的,但是在第二张图中引入了非线性模型,就可以进行更加灵活的变化,达到更加好的区分度。图三是过度学习的一个案例,区分得太过于精细了。
-
那为什么用sigmoid能拟合呢??
sigmoid的函数式是1/(1+e-x),在例子中,x是代入我们的线性模型wx+b的值,相当于1/(1+ewx+b),而我们调整w和b,这个函数是可以变成不同形状的函数,以此才能拟合奇奇怪怪的函数,不会只能拟合直线。
-
所以回到问题本身,我们知道了为什么用sigmoid,但是为什么用多次呢 ,下面我画了一个简单的示意图(图与本文例子无关)
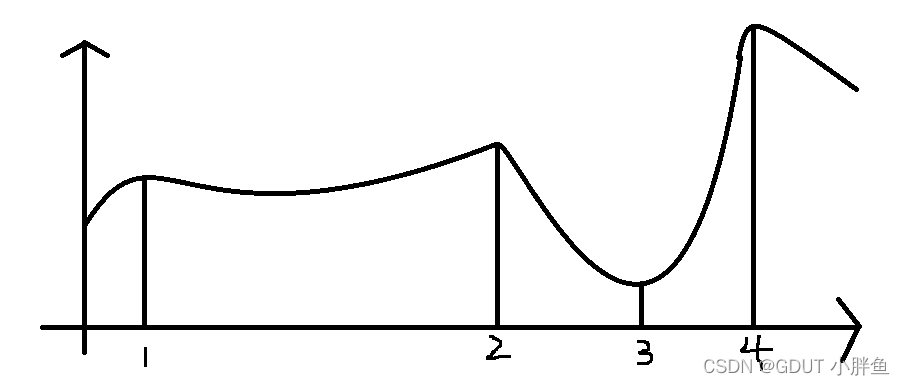 我们仅仅通过一个sigmoid,就算我们不断调整w和b,函数变化的形式依旧比较单一,所以在上图中只用一个sigmoid,我们可能可以拟合0-1-2这一段,但是拟合2-3这一段可能会有比较大误差,如果拟合了2-3这一段,又可能影响了0-1-2这一段,但是我们在使用多个sigmoid的时候,就可能可以拟合各段的函数形式。
我们仅仅通过一个sigmoid,就算我们不断调整w和b,函数变化的形式依旧比较单一,所以在上图中只用一个sigmoid,我们可能可以拟合0-1-2这一段,但是拟合2-3这一段可能会有比较大误差,如果拟合了2-3这一段,又可能影响了0-1-2这一段,但是我们在使用多个sigmoid的时候,就可能可以拟合各段的函数形式。
-
8维到6维对应的矩阵变化形式,这里的函数是向量函数,即对向量中每一个数代入后结果再放到向量中,结果还是一个函数。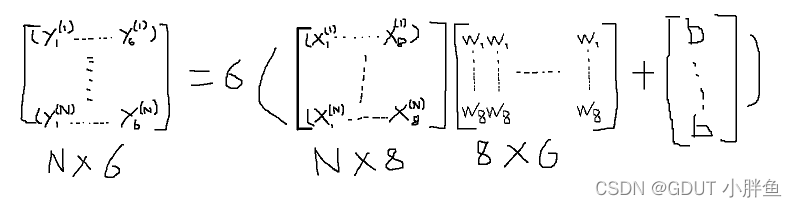
3.对优化器的理解
criterion = torch.nn.BCELoss(reduction='mean')
这里的reduction是一个属性,决定loss是要累加还是取平均,在本例中,如果不采用平均,会导致偏差很大。但是在前两篇文章中,使用累加没有影响。在实验后发现是lr是关系,lr是学习率,如果采用累加,可能需要把学习率调小一点。
总结
以上就是今天要讲的内容,本文仅仅是向初学者以通俗一点的方式介绍了pytorch实现多特征输入分类问题的基本使用。讲解过程属于个人理解,如有误,请谅解。