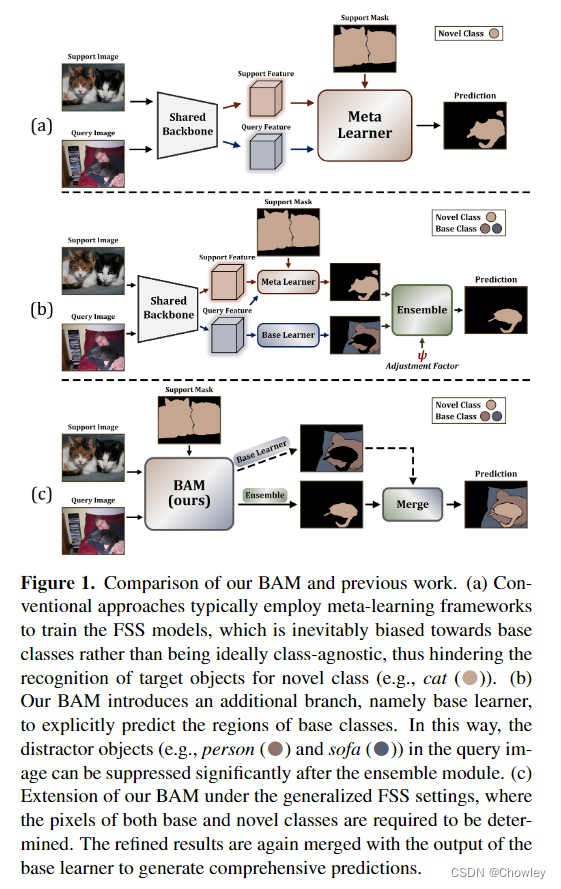
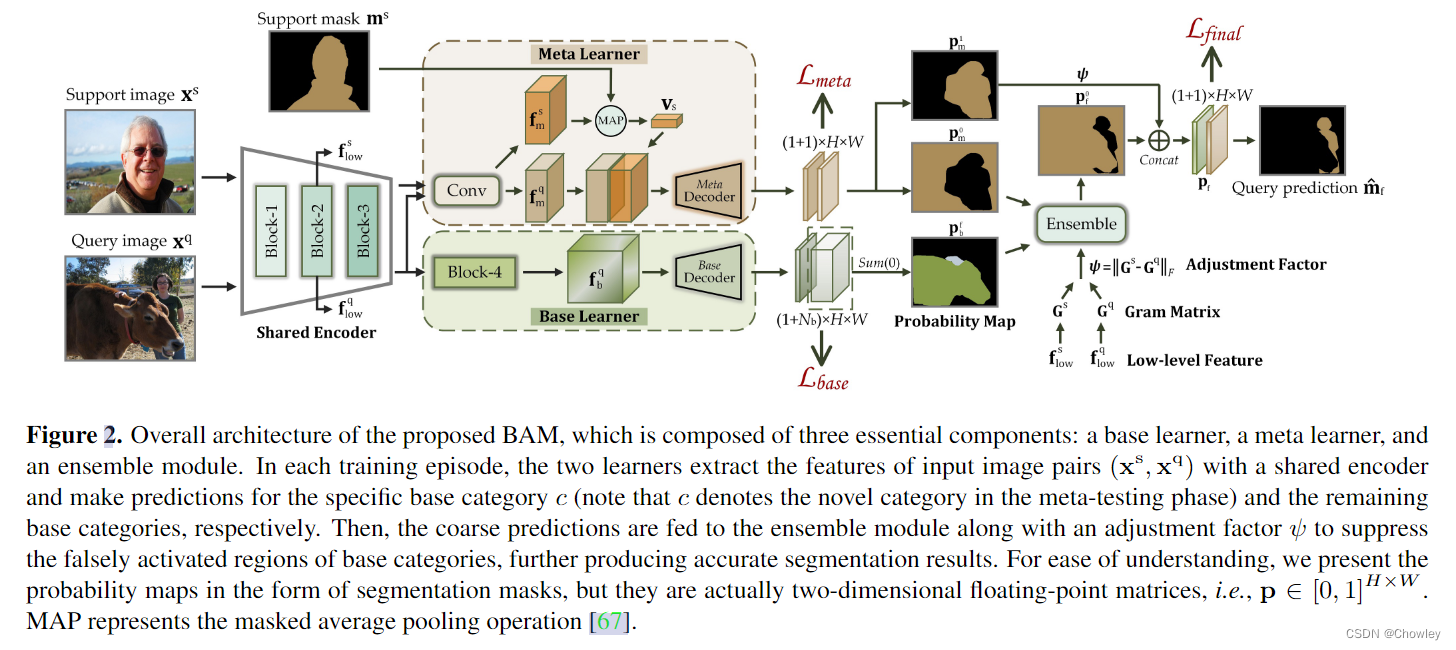
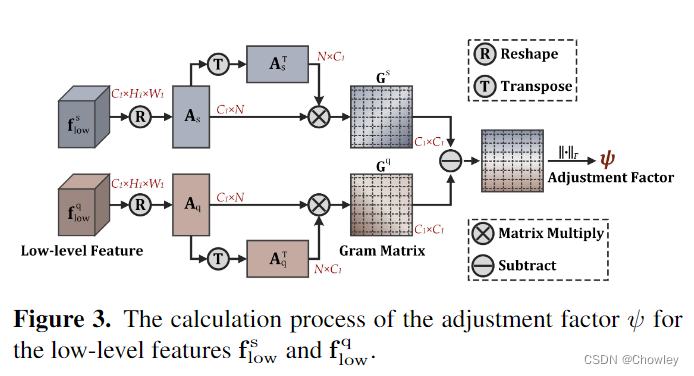
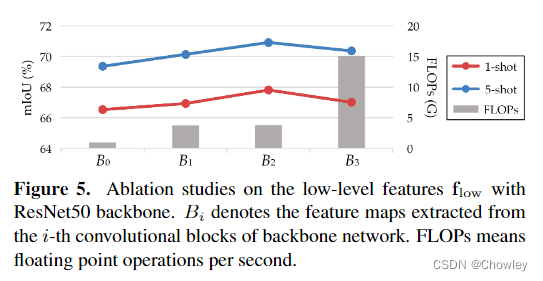
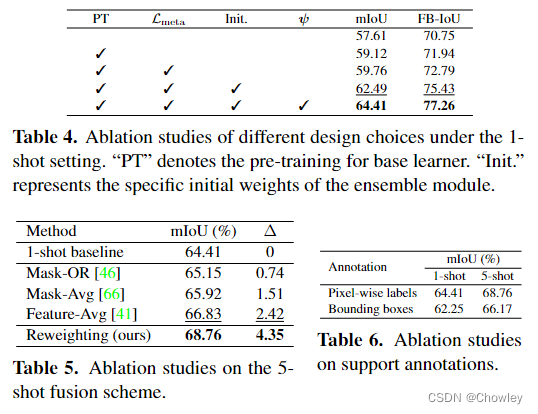
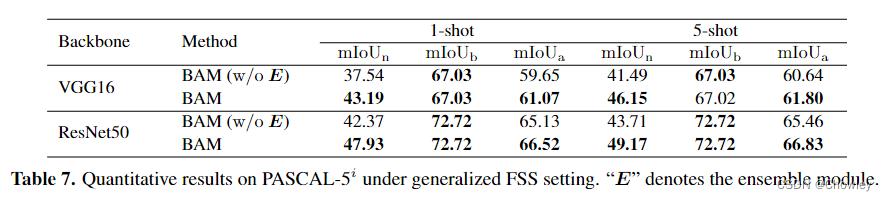
我们认为,除了设计更强大的特征提取模块外,调整包含足够训练样本的基础数据集的使用也是缓解上述偏差问题的一种替代方法,而这一问题在以往的工作中被忽视了。为此,我们在传统的FSS模型(元学习器)中引入了一个额外的分支(基本学习器)来显式预测基类的目标(见图1)。然后,这两个学习器并行输出的粗略结果被自适应地整合以生成准确的预测。这种操作背后的中心洞察力是通过在传统范例内训练的大容量分割模型来识别查询图像中的易混淆区域,从而进一步促进对新对象的识别。顺便提一句,该方案被命名为BAM,因为它由两个唯一的学习器组成,base and the meta.即基本学习器和元学习器。