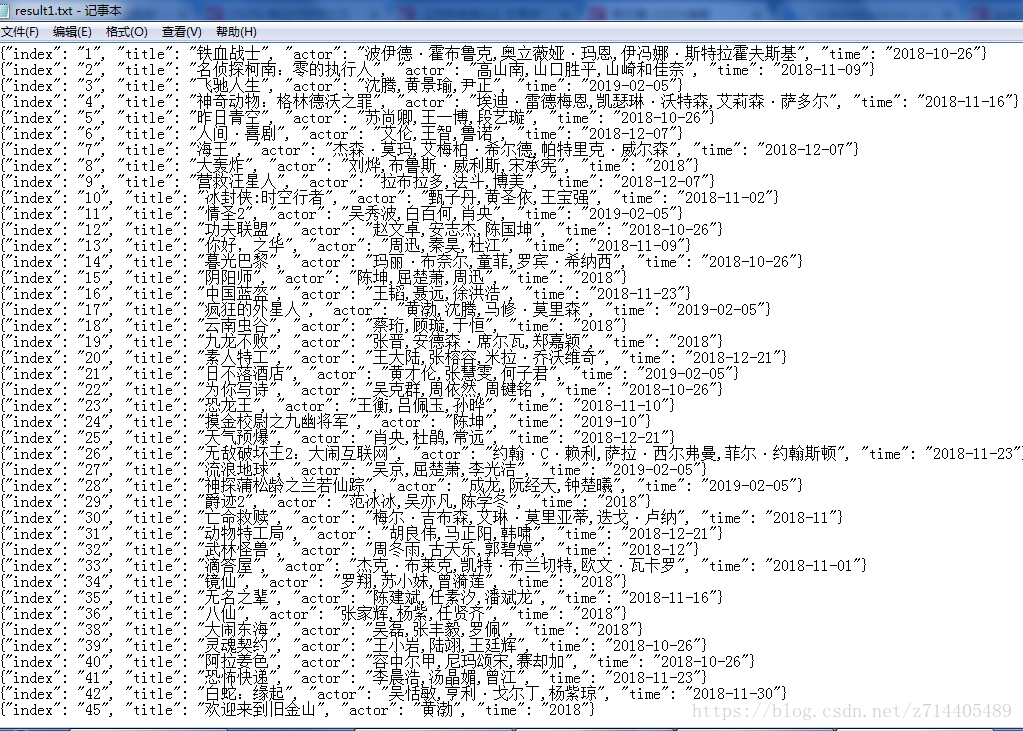
目标站点分析
目标站点(猫眼榜单TOP100):
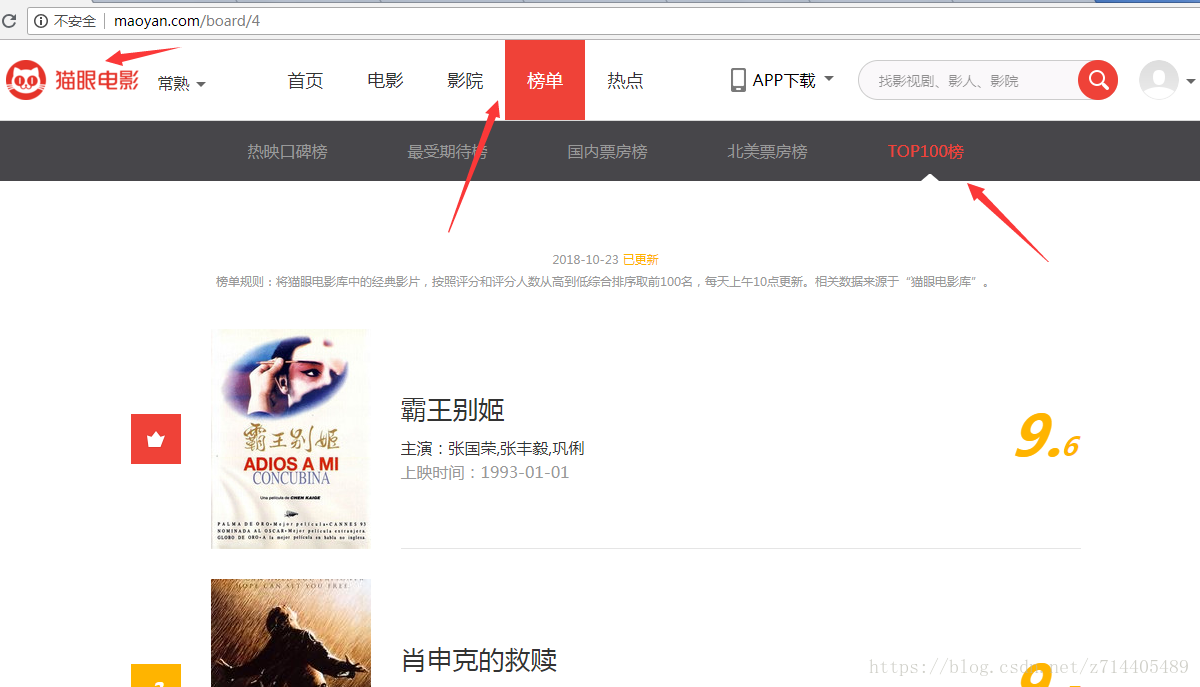
如下图,猫眼电影的翻页offset明显在URL中,所以只要搞定第一页的内容加上一个循环加上offset就可以爬取前100。


流程框架
1、抓取单页内容
利用requests请求目标站点,得到单个网页HTML代码,返回结果。
2、正则表达式分析
根据HTML代码分析得到电影的排名、地址、名称、主演、上映时间、评分等信息。
3、保存至文件
通过文件的形式将结果保存,每一部电影一个结果一行Json字符串。
4、开启循环及多线程
对多页内容遍历,开启多线程提高抓取速度。
实战
1、抓取单页内容
兴致勃勃地码了一段代码,用来获得第一页的内容:
import requests
from requests.exceptions import RequestException
#提取单页内容,用try,except方便找bug
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:#如果状态码为200,说明请求成功
return response.text
return response.status_code#否则请求失败,返回状态码果
except RequestException:
return None
def main():
url= 'http://maoyan.com/board/4'
html = get_one_page(url)
print(html)
if __name__ == '__main__':
main()
结果很尴尬,直接来了个403状态码,说明请求失败了。

回顾一下之前学的知识:使用Requests库来进行爬虫的详解
headers在爬虫中是非常必要的,很多时候如果请求不加headers,那么你可能会被禁掉或出现服务器错误…
解决办法:加入headers试试看(做一个浏览器的伪装),只需要向get方法传入headers参数就好了,具体的headers内容直接就用文中给出的例子就行。
import requests
from requests.exceptions import RequestException
headers = {'User-Agent':'Mozilla/5.0(Macintosh;Intel Mac OS X 10_11_4)AppleWebKit/537.36(KHTML,like Gecko)Chrome/52.0.2743.116 Safari/537.36'}
#提取单页内容,用try,except方便找bug
def get_one_page(url):
try:
response = requests.get(url, headers=headers)#传入headers参数
if response.status_code == 200:
return response.text
return response.status_code
except RequestException:
return None
def main():
url= 'http://maoyan.com/board/4'
html = get_one_page(url)
print(html)
if __name__ == '__main__':
main()

呼呼,打印出了一堆内容,说明这回已经请求成功了。再次说明了请求时加入headers参数的重要性。
2、正则表达式分析
我们想要从爬取到的内容中提取6个信息:排名,封面(超链接),标题,演员,上映时间,评分。
先来看看每一个电影在网页中的结构是怎样的,这样才能知道该怎么写正则表达式:
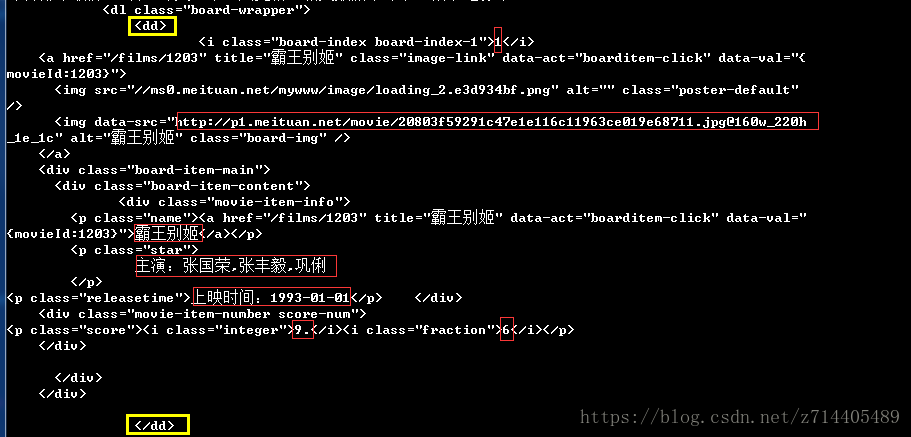
仔细研究上图,红框中的正是我们要提取的信息,那么只要将它们置于正则表达式的7个括号中(最后的评分是分开的,所以需要2个括号来选中),并且在括号两旁做出正确的限定,那么这个正则表达式还是很好写的。
代码如下(注意要导入re库):
def parse_one_page(html):#定义一个函数用来解析html代码
#生成一个正则表达式对象
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a' #此处换行
+'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+'.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S)
items = re.findall(pattern,html)
对输出的结果再进行格式化处理,使输出更美观:
#items是一个list,其中的每个内容都是一个元组
#将杂乱的信息提取并格式化,变成一个字典形式
for item in items:
yield { #构造一个字典
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],#做一个切片,去掉“主演:”这3个字符
'time': item[4].strip()[5:],#做一个切片,去掉“上映时间:”这5个字符
'score': item[5]+item[6]#将小数点前后的数字拼接起来
}
再修改一下main函数:
def main():
url= 'http://maoyan.com/board/4'
html = get_one_page(url)
for item in parse_one_page(html):#item是一个生成器
print(item)
运行一下看看:

效果还可以吧~
3、保存至文件
定义一个函数用来将上面提取的信息保存到文件中:
def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
#a表示模式是“追加”;采用utf-8编码可以正常写入汉字
f.write(json.dumps(content, ensure_ascii = False) + '\n')#不允许写入ascii码
#content是一个字典,我们需要转换成字符串形式,注意导入json库
f.close()
再修改一下main函数:
def main():
url= 'http://maoyan.com/board/4'
html = get_one_page(url)
for item in parse_one_page(html):#item是一个生成器
print(item)
write_to_file(item)
运行一下看看:
成功保存为文件啦,看看内容,没问题:
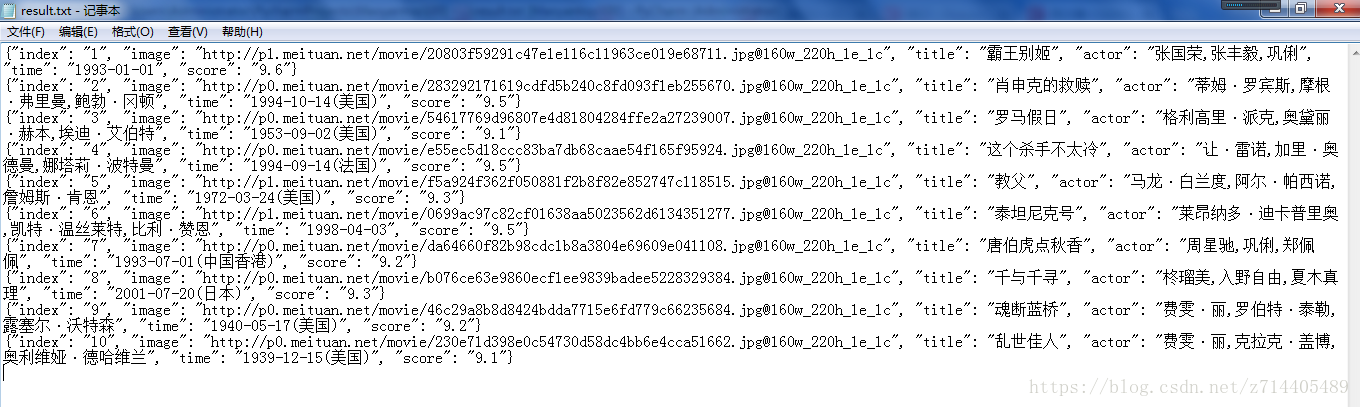
4、开启循环及多线程
循环:
再看看网页的特点,点击下一页时,offset这个参数会增加10:
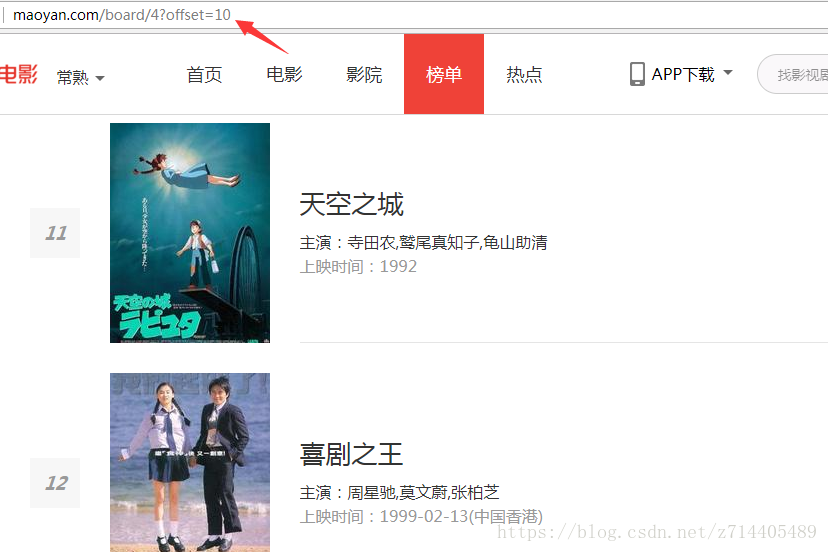
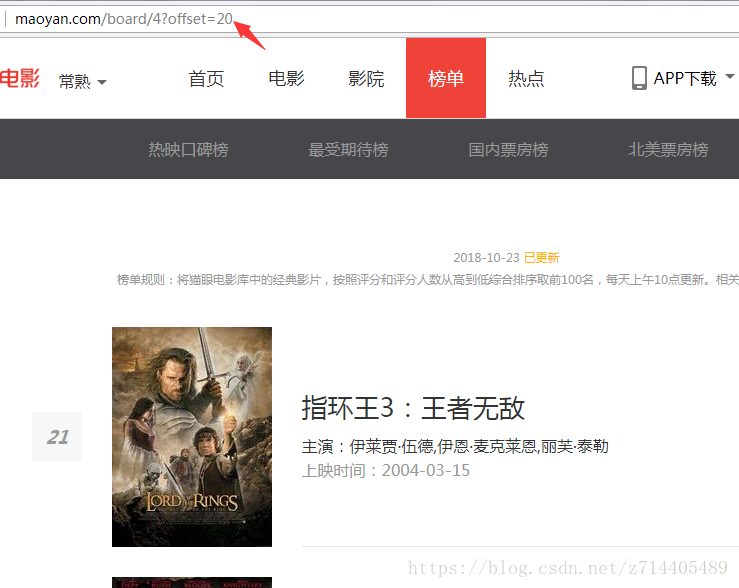
我们只需要修改一下主函数就可以了,给它添加一个offset参数,实现10个页面的抓取:
def main(offset):
url= 'http://maoyan.com/board/4?offset='+str(offset)#把offset参数以字符串形式添加到url中
html = get_one_page(url)
for item in parse_one_page(html):#item是一个生成器
print(item)
write_to_file(item)
还有起始部分:
if __name__ == '__main__':
for i in range(10):#构造一个数组实现0,10,20,...,90的循环
main(i*10)
运行看看结果(为了展示更美观,在代码中把超链接这个信息去掉了):
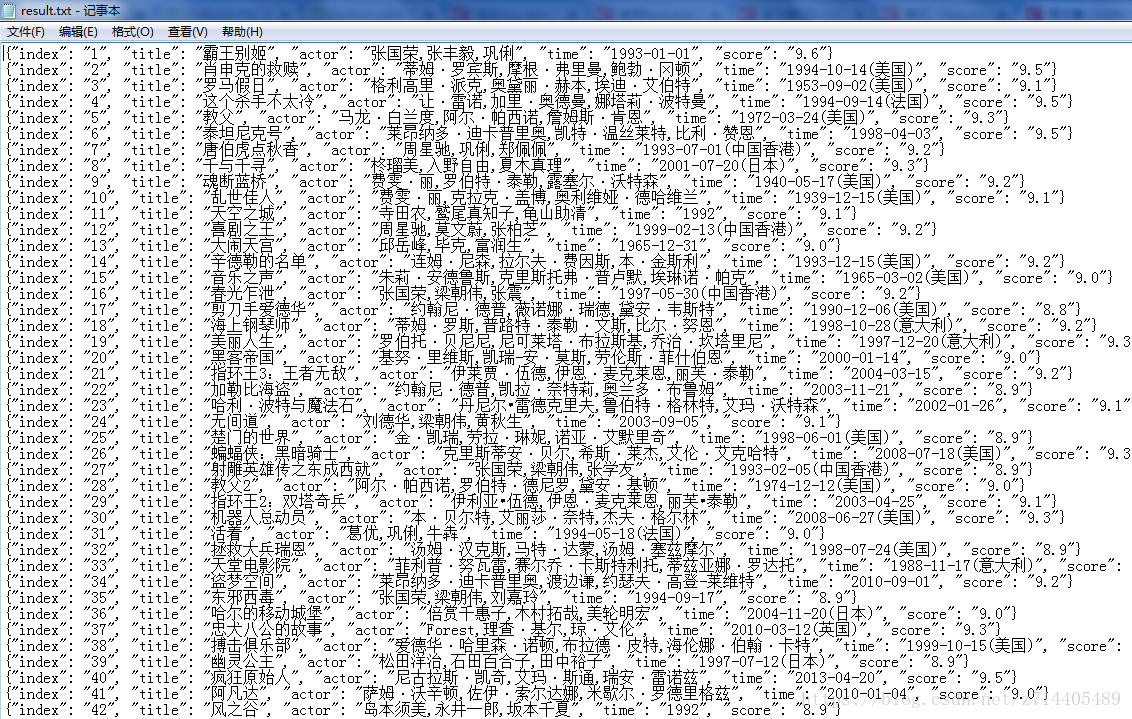
很棒!
多进程
采用多进程的方法可以提高运行的效率:
from multiprocessing import Pool
if __name__ == '__main__':
pool = Pool()#创建一个进程池
pool.map(main,[i*10 for i in range(10)])#map方法创建进程(不同参数的main),并放到进程池中
总结
非常顺利的爬取了猫眼电影TOP100,关键在于正则表达式的写法。
全部代码如下:
import requests
from requests.exceptions import RequestException
import re
import json
from multiprocessing import Pool
headers = {'User-Agent':'Mozilla/5.0(Macintosh;Intel Mac OS X 10_11_4)AppleWebKit/537.36(KHTML,like Gecko)Chrome/52.0.2743.116 Safari/537.36'}
#提取单页内容,用try,except方便找bug
def get_one_page(url):
try:
response = requests.get(url, headers=headers)#传入headers参数
if response.status_code == 200:
return response.text
return response.status_code
except RequestException:#捕获这个类型的异常
return None
def parse_one_page(html):#定义一个函数用来解析html代码
#生成一个正则表达式对象
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a' #此处换行
+'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+'.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S)
items = re.findall(pattern,html)
#items是一个list,其中的每个内容都是一个元组
#将杂乱的信息提取并格式化,变成一个字典形式
for item in items:
yield { #构造一个字典
'index': item[0],
#'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],#做一个切片,去掉“主演:”这3个字符
'time': item[4].strip()[5:],#做一个切片,去掉“上映时间:”这5个字符
'score': item[5]+item[6]#将小数点前后的数字拼接起来
}
def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
#a表示模式是“追加”;采用utf-8编码可以正常写入汉字
f.write(json.dumps(content, ensure_ascii = False) + '\n')#不允许写入ascii码
#content是一个字典,我们需要转换成字符串形式,注意导入json库
f.close()
def main(offset):
url= 'http://maoyan.com/board/4?offset='+str(offset)#把offset参数以字符串形式添加到url中
html = get_one_page(url)
for item in parse_one_page(html):#item是一个生成器
print(item)
write_to_file(item)
if __name__ == '__main__':
pool = Pool()#创建一个进程池
pool.map(main,[i*10 for i in range(10)])#map方法创建进程(不同参数的main),并放到进程池中
爬取最受欢迎榜
原理还是一样的,只需要确定一下要筛选什么信息(因为这和TOP100略有不同),并且修改一下正则表达式和一些小细节即可。
def parse_one_page(html):#定义一个函数用来解析html代码
pattern = re.compile('<dd>.*?"board-index.*?">(\d+)</i>.*?href.*?data-src.*?</a>.*?board-item-main.*?name">.*?title.*?">(.*?)</a>.*?star">(.*?)</p>.*?'
+'releasetime">(.*?)</p>.*?</dd>', re.S)
items = re.findall(pattern, html)
#items是一个list,其中的每个内容都是一个元组
#将杂乱的信息提取并格式化,变成一个字典形式
for item in items:
yield { #构造一个字典
'index': item[0],
#'image': item[1],
'title': item[1],
'actor': item[2].strip()[3:],#做一个切片,去掉“主演:”这3个字符
'time': item[3].strip()[5:],#做一个切片,去掉“上映时间:”这5个字符
}
结果: