一、calico介绍
Calico是Kubernetes生态系统中另一种流行的网络选择。虽然Flannel被公认为是最简单的选择,但Calico以其性能、灵活性而闻名。Calico的功能更为全面,不仅提供主机和pod之间的网络连接,还涉及网络安全和管理。Calico CNI插件在CNI框架内封装了Calico的功能。
Calico是一个基于BGP的纯三层的网络方案,与OpenStack、Kubernetes、AWS、GCE等云平台都能够良好地集成。Calico在每个计算节点都利用Linux Kernel实现了一个高效的虚拟路由器vRouter来负责数据转发。每个vRouter都通过BGP1协议把在本节点上运行的容器的路由信息向整个Calico网络广播,并自动设置到达其他节点的路由转发规则。Calico保证所有容器之间的数据流量都是通过IP路由的方式完成互联互通的。Calico节点组网时可以直接利用数据中心的网络结构(L2或者L3),不需要额外的NAT、隧道或者Overlay Network,没有额外的封包解包,能够节约CPU运算,提高网络效率。
此外,Calico基于iptables还提供了丰富的网络策略,实现了Kubernetes的Network Policy策略,提供容器间网络可达性限制的功能。
calico官网:https://www.projectcalico.org/
二、calico架构

calico核心组件:
- Felix:运行在每个需要运行workload的节点上的agent进程。主要负责配置路由及 ACLs(访问控制列表) 等信息来确保 endpoint 的连通状态,保证跨主机容器的网络互通;
- etcd:强一致性、高可用的键值存储,持久存储calico数据的存储管理系统。主要负责网络元数据一致性,确保Calico网络状态的准确性;
- BGP Client(BIRD):读取Felix设置的内核路由状态,在数据中心分发状态。
- BGP Route Reflector(BIRD):BGP路由反射器,在较大规模部署时使用。如果仅使用BGP Client形成mesh全网互联就会导致规模限制,因为所有BGP client节点之间两两互联,需要建立N^2个连接,拓扑也会变得复杂。因此使用reflector来负责client之间的连接,防止节点两两相连。
Calico把每个操作系统的协议栈认为是一个路由器,然后把所有的容器认为是连在这个路由器上的网络终端,在路由器之间跑标准的路由协议——BGP的协议,然后让它们自己去学习这个网络拓扑该如何转发。所以Calico方案其实是一个纯三层的方案,也就是说让每台机器的协议栈的三层去确保两个容器,跨主机容器之间的三层连通性。
三、calico的两种网络方式简述
1)IPIP
把 IP 层封装到 IP 层的一个 tunnel。它的作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于mac层的,根本不需 IP,而这个 ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。ipip 的源代码在内核 net/ipv4/ipip.c 中可以找到。
2)BGP
边界网关协议(Border Gateway Protocol, BGP)是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议。
四、抓包
(1)环境准备
准备一个calico ipip模式的集群,部署两个测试用的应用pod

详细图如下,podA访问podB
podA的名称为nginx-sit-84ff75dbc9-x2rv4,ip为172.17.125.5,对应calico网卡为calif40523a0c80,所在主机节点名为k8s-node01,网卡为ens33,主机ip为192.168.0.91;
podB的名称为nginx-uat-64659d8985-tdg4l,ip为172.27.14.197,对应calico网卡为cali204e9f1206a,所在主机节点名为k8s-node02,网卡为ens33,主机ip为192.168.0.92;

进入容器podA,发出curl包,同时在podA所在节点监听calif40523a0c80网卡
curl 172.27.14.197:80
tcpdump -i calif40523a0c80 tcp and port 80


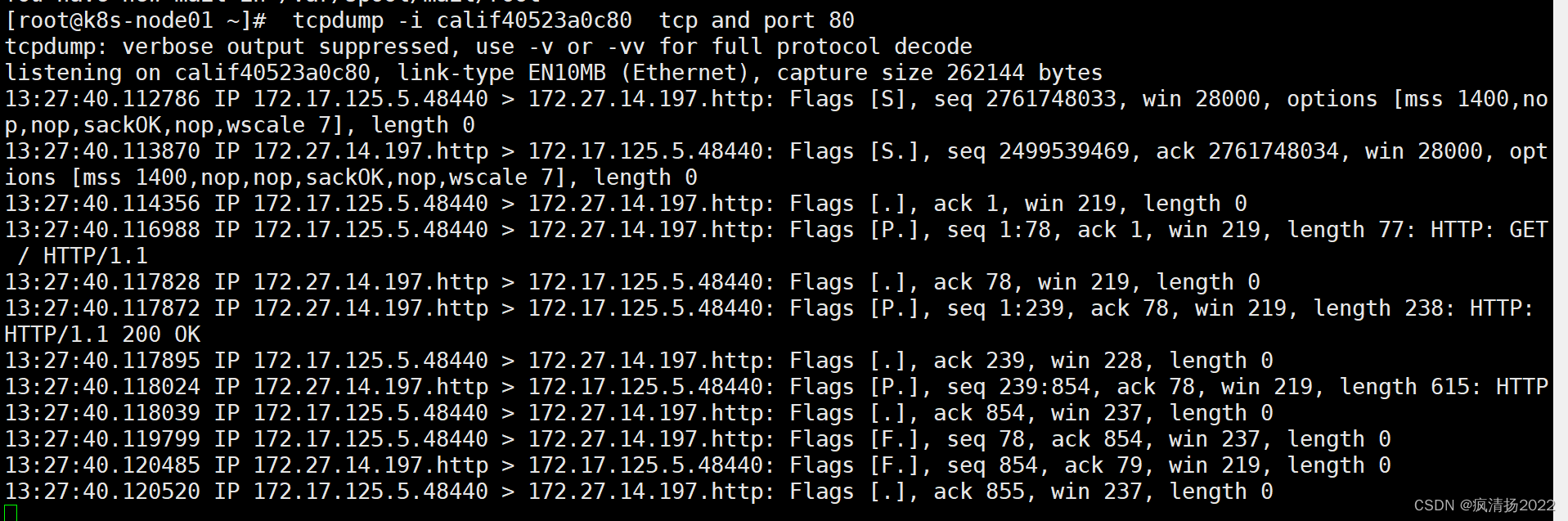
可以看到src ip是podA ip,dst ip是podB ip
pod发出的包出现在calif40523a0c80网卡之后,匹配完kube-proxy下发的prerouting等规则后,根据dst ip即podB ip查找节点路由表确定包如何转发

如上,匹配到的规则表示 下一跳via是 192.168.0.92(podB所在节点IP),由tunl0设备处理发出,tunl0作为一种隧道设置,会在原始包的基础上加上一层ip头,其中ip头中的目的ip就是匹配的路由规则中的下一跳地址。
节点k8s-node01的tunl0抓包
在podA内发起telnet请求,在k8s-node01节点监听tunl0


上面显示源ip为tunl0的ip,即172.17.125.0

节点k8s-node01的ens33抓包
节点间通信用的网卡ens33上的包已经是经过tunl0封包处理之后的(加上一层ip header),所以使用tcpdump抓包时需要注意指定协议为ip而不能是tcp,因为tcpdump指定为tcp协议时根据格式ip[tcp]解析raw ip包,但是经过ipip模块封包处理之后,raw包格式变成ip[ip[tcp]],所以这个时候指定tcp协议抓包会不到,指定tcp协议相关的过滤参数也会导致抓不到包,比如指定port 80,一个参考的方式是指定协议为ip,通过配合grep来过滤包(tcpdump会把第二层ip头信息打印出来),如下:

可以看到第一层ip header中:src ip是k8s-node01 nodeIP,dst ip是k8s-node02 nodeIP
第二层ip header中:src ip是tunl0 ip,而不是podA ip,dst ip是podB ip
当ip包被节点间已有的三层网络转发到目的节点k8s-node02时,内核会识别出该数据包是被IPIP驱动封包处理过的,驱动会进行解包,从而拿到原始ip包,再通过节点上的如下路由规则将包转发给cali204e9f1206a网卡,最终到达pod中

四、抓包分析
在nginx-sit-84ff75dbc9-x2rv4这个pod中ping nginx-uat-64659d8985-tdg4l这个pod,接着在nginx-uat-64659d8985-tdg4l这个pod所在的宿主机进行tcpdump


结束抓包后下载icmp_ping.cap到本地windows进行抓包分析
能看到该数据包一共5层,其中IP(Internet Protocol)所在的网络层有两个,分别是pod之间的网络和主机之间的网络封装。

s上面显示会把tunl0 ip作为原始ip包的src ip,原因是让目的节点回包时能够因为src ip(tunl0 ip)属于源节点的pod子网(calico也叫做ip block)而对回报也做ipip封包处理,否则如果src ip还是192.168.0.91的话,回包不经过目的节点的tunl0封包处理,最终在源节点看来就会出现混乱并被丢弃,也就是说:如果ip包在源节点经过ipip模块处理,那么需要保证回包时在目的节点也要经过ipip处理
回看最上面的calico中的natoutgoing配置,表示的是当在pod中访问其他非pod ip时,是否需要做snat,如果配置为true,calico会通过felix在节点中添加相关iptables规则来做snat
如果natoutgoing配置为false,会导致在pod中无法访问集群中的其他节点ip,原因刚好是上面的逆过程,即pod中访问其他的节点ip,如果不经过snat把src ip设置为自身节点的ip,那么在目的节点回包是因为src ip是podIP,那么就会根据路由表把包交由tunl0做封包出来,导致混乱,也就是说:如果ip包在源节点没有经过ipip模块处理,那么需要保证回包时在目的节点也不能经过ipip处理