YOLOv5+PaddleOCR手写签名识别
介绍:
参加了一个中国移动的比赛,比赛的数据集是一个工单,上面有多个人的签名还有手写的时间。因为主办方不允许数据公开,所以在这一系列博客中,我主要讲一下实现的思路,在YOLO演示的时候我会用其他的数据代替。
要求:开发一个模型,对比赛提供的工单进行手写汉字(主要是签名)的截取和识别。
数据:
- 提供图片训练集467张,均带有标注结果。每张表单上有三个人的签名以及一些表单数据。
- 提供图像测试集118张,需提交在测试集的识别结果。
总结:
简单来说比赛主要由三部分组成:
- 从表单上将签名部分识别出来并进行切割
- 将切割的签名进行预处理
- 将签名进行训练并识别
目前手写汉字识别存在的问题:
- 字体多样:常见字体包括楷书、行书、草书等,字体结构各不相同
- 书写随意:由于各人书写风格不同,造成手写字差别过大或变形严重
- 形近字多︰如“土、士”、“往、住”等
检测模型的选择:
目前较好的检测模型有两种,分别是R-CNN和YOLO系列。下面简单介绍一下原理:
R-CNN:
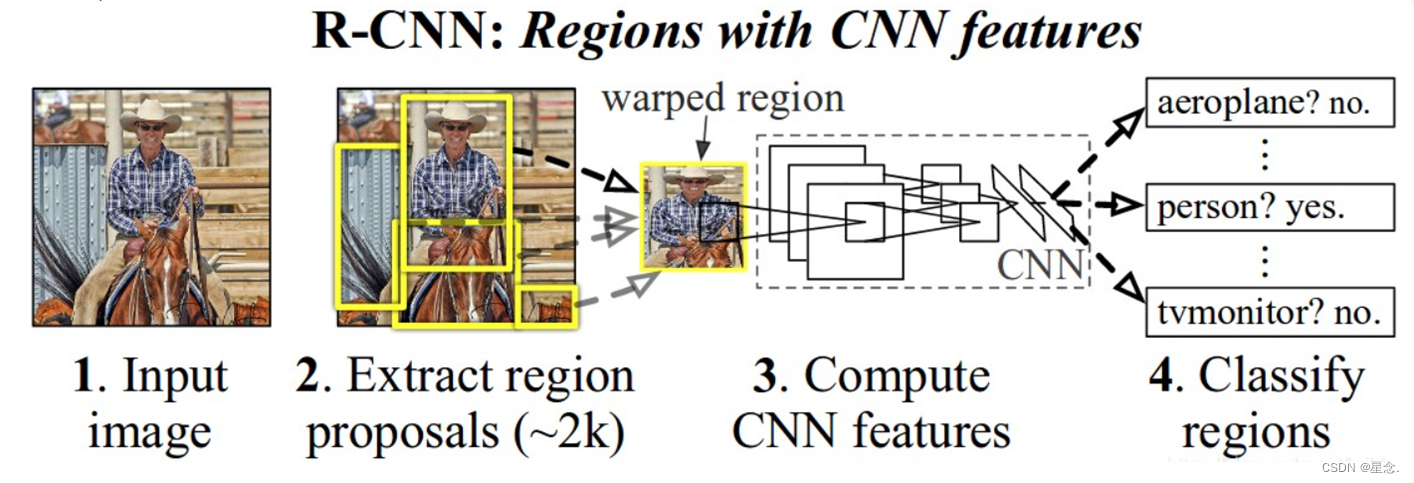
R-CNN的想法是很暴力的,就是从整个图片中随机切出来很多块区域,然后把这些区域进行特征提取,再放到分类器中进行分类。当然,只要切得区域足够多,那么一定可以切到我们需要识别的物体。具体步骤如下:
- 从图片中选出2000个独立的候选区域(Region Proposal),提出了一个叫做Selective Search的算法.
- 每一个区域提取一个固定长度(4096)的特征向量
- 对每个目标(类别)训练—分类器(类似于SVM)
- 训练一个回归器,修正候选区域中目标的位置
足够多的区域也加重了训练的消耗,资源的占用,所以提出了一个区域选择算法。也就是在有可能的区域进行搜索。但是这样的训练所需的资源仍然是巨大的。
YOLO:

YOLO这个系列也已经提出来了6,7年了,相比于以前的算法绝对是一个史无前例的创新。关于YOLO网上有很多大佬都做了解释,我就不再叙述。关于YOLO的原理可以参考下面的几篇文章:
写给小白的YOLO
目标检测|YOLO原理与实现
YOLO-YOLOV5算法原理及网络结构整理
本项目也是使用的YOLO。我感觉最大的特点就是快又准。在YOLO标注的时候我们将表单中的签名和日期分开标注,然后在获取最终数据的时候也是分为两个文件夹。在这个系列第二篇会推出我实现YOLOv5的步骤。
识别模型的选择:
OCR识别算法的输入数据一般是文本行﹐背景信息不多﹐文字占据主要部分﹐识别算法目前可以分为两类算法:
1.基于CTC的方法;即识别算法的文字预测模块是基于CTC的,常用的算法组合为CNN+RNN+CTC。目前也有一些算法尝试在网络中加入transformer模块等等。
2.基于Attention 的方法;即识别算法的文字预测模块是基于Attention的,常用算法组合是CNN+RNN+Attention。
我们使用的是基于百度飞桨的paddocr,其中的PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用传统的RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。为IJCAl 2022最新收录的文本识别算法SVTR(论文名称: SVTR:Scene Text Recognition with a Single Visual Model)
模型有以下特点:
- 利用Attention指导CTC训练,融合多种文本特征的表达,是一种有效的提升文本识别的策略。
- 在PP-OCRv3中,针对两个不同的SVTR_LCNet和Attention结构,对他们之间的PP-LCNet的特征图、SVTR模块的输出和Attention模块的输出同时进行监督训练
- 核心思想是利用高精度的文本识别大模型对无标注数据进行预测,获取伪标签,并且选择预测置信度高的样本作为训练数据,用于训练小模型。
根据YOLOv5切割出来的数据集,制作paddocr的数据集,然后进行模型训练。最终训练的准确度如下:

训练集的准确度达到了96.4%。最终我们利用九天提供的数据进行测试数据,得到的评分为95分。
如下所示:

模型的提升
- 加强去噪:型可提升空间不大。但是两种报告单的数据集存在有较大的差异,验收单的噪音较多。
- 增加更多的数据集:现在数据集比较少。增加数据集之后会对模型的泛化行,以及适用性有一个较好的提升
- 提高切割精度:减少图片数据中除手写字体外不必要的部分