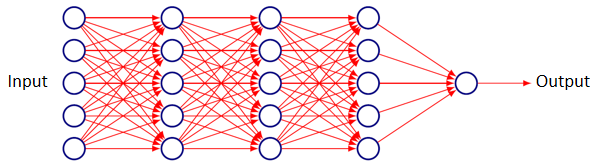
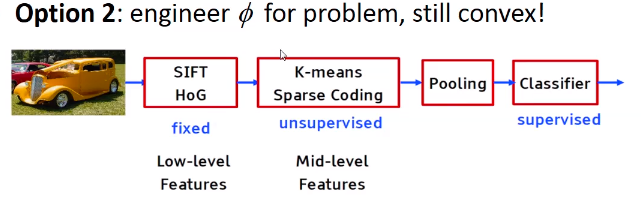
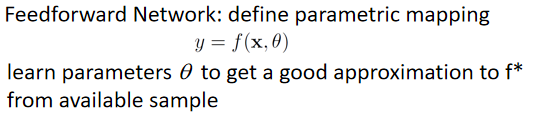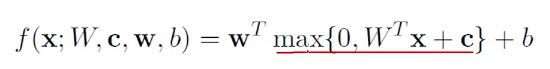ReLU函数 大块一致的梯度,容易优化 Positives: Gives large and consistent gradients (does not saturate) when active Efficient to optimize, converges much faster than sigmoid or tanh Negatives: Non zero centered output Units “die” i.e. when inactive they will never update (落到小于0的位置梯度死掉,参数不更新)