一、为什么业界普遍关注RAG?
目前大语言模型(LLM)存在幻觉问题(来自人工智能研究中心的一篇研究论文《Survey of Hallucination in Natural Language Generation》,将LLM的幻觉定义为“生成的内容与提供的源内容不符或没有意义”)、不够专业的问题(大模型在通用领域训练时缺少某一专业性高的垂域知识)和生成不具时效性的问题(这源于通过训练更新模型参数,模型中只压缩了当前数据中已有的世界知识,对于新增长数据知识,模型更有可能生成不专业或毫无意义的内容)。
那么就存在幻觉和不够专业的大模型一个最新的研究问题,它的回答可能会让你百感交集。为了大模型的回答在某一领域更准确、更专业和更具时效性,检索增强生成的技术(RAG)被提出,并受到学术界和工业界的广泛关注。尤其是在算力有限的初创企业及研究所中因其可节省算力人力成本就可借助大模型能力和注入私有垂域数据而备受关注,其次因其能保证数据私有性和安全性在工业界开发落地也如火如荼。
RAG的特点可以总结以下几条
1、RAG 是一种相对较新的人工智能技术,可以通过允许大型语言模型 (LLM) 在无需重新训练的情况下利用额外的数据资源来提高生成式 AI 的质量。
2、RAG 模型基于组织自身的数据构建知识存储库,并且存储库可以不断更新,以帮助生成式 AI 提供及时的上下文答案。
3、使用自然语言处理的聊天机器人和其他对话系统可以从 RAG 和生成式人工智能中受益匪浅。
4、实施 RAG 需要矢量数据库等技术,这些技术可以快速编码新数据,并搜索该数据以输入给LLM模型。
通俗易懂讲解大模型系列
-
用通俗易懂的方式讲解:如何提升大模型 Agent 的能力?
-
用通俗易懂的方式讲解:使用 Mistral-7B 和 Langchain 搭建基于PDF文件的聊天机器人
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:结合检索和重排序模型,改善大模型 RAG 效果明显
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:ChatGLM3-6B 功能原理解析
-
用通俗易懂的方式讲解:使用 LangChain 和大模型生成海报文案
-
用通俗易懂的方式讲解:一个强大的 LLM 微调工具 LLaMA Factory
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:LangChain Agent 原理解析
-
用通俗易懂的方式讲解:HugggingFace 推理 API、推理端点和推理空间使用详解
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:使用 FastChat 部署 LLM 的体验太爽了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:使用 Docker 部署大模型的训练环境
-
用通俗易懂的方式讲解:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:LangChain 知识库检索常见问题及解决方案
-
用通俗易懂的方式讲解:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
-
用通俗易懂的方式讲解:代码大模型盘点及优劣分析
-
用通俗易懂的方式讲解:Prompt 提示词在开发中的使用
-
用通俗易懂的方式讲解:万字长文带你入门大模型
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
相关资料、数据、技术交流提升,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:来自CSDN + 技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:加群

二、RAG技术要怎么干?
检索增强生成,要解决两个问题,如何检索和如何生成?
其整体可划分为两个阶段:检索阶段和生成阶段。在检索阶段,算法搜索并检索与用户输入相关的信息片段,下图step1和step2从向量数据库中查询与query相关的信息片段 。生成阶段step3,大模型依据增强的提示和预训练的内部表示中提取信息,为用户量身定做生成答案,将答案发送给聊天机器人并附上出处链接。
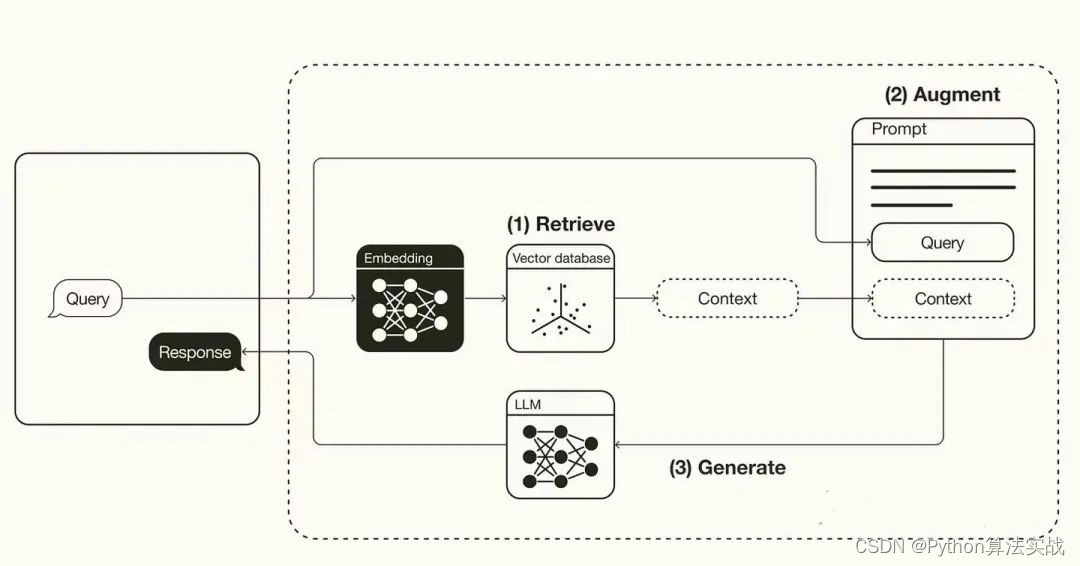
大模型本身并不知道这类知识,也没有见过这类新信息,我们通过“提示”的方式让大模型知道这个知识,了解这类新信息。然后大模型就能在已有能力的基础上,参考垂域知识和最新信息来应答。
1、加载文本切分片段
2、将片段灌入检索引擎
3、封装检索接口(LLM接口封装)
4、构建调用流程:Query -> 检索 -> Prompt -> Prompt -> LLM -> 回复
下面我们以基于pdf文本的检索增强生成技术来逐步讲解每一步流程:
(1)安装pdf解析库
!pip install pdfminer.six
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
def extract_text_from_pdf(filename,page_numbers=None, min_line_length=1):
#从 PDF 文件中(按指定页码)提取文字
paragraphs = []
buffer = ''
full_text = ''
# 提取全部文本
for i, page_layout in enumerate(extract_pages(filename)):
# 如果指定了页码范围,跳过范围外的页
if page_numbers is not None and i not in page_numbers:
continue
for element in page_layout:
if isinstance(element, LTTextContainer):
full_text += element.get_text() + '\n'
# 按空行分隔,将文本重新组织成段落
lines = full_text.split('\n')
for text in lines:
if len(text) >= min_line_length:
buffer += (' '+text) if not text.endswith('-')
elif buffer:
paragraphs.append(buffer)
buffer = ''
else:text.strip('-')
if buffer:
paragraphs.append(buffer)
return paragraphs
paragraphs=extract_text_from_pdf("llama2.pdf", min_line_length=10)
for para in paragraphs[:3]:
print(para+"\n")
(2)检索引擎
以一个检索引擎的基础实现案例展开。
# 安装 ES 客户端
!pip install elasticsearch7
# 安装NLTK(文本处理方法库)
!pip install nltk
from elasticsearch7 import Elasticsearch, helpers
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import nltk
import re
import warnings
warnings.simplefilter("ignore")
# 屏蔽 ES 的一些Warnings
nltk.download('punkt') # 英文切词、词根、切句等方法
nltk.download('stopwords') # 英文停用词库
def to_keywords(input_string):
'''(英文)文本只保留关键字'''
# 使用正则表达式替换所有非字母数字的字符为空格
no_symbols = re.sub(r'[^a-zA-Z0-9\s]', ' ', input_string)
word_tokens = word_tokenize(no_symbols)
# 加载停用词表
stop_words = set(stopwords.words('english'))
ps = PorterStemmer()
# 去停用词,取词根
filtered_sentence = [ps.stem(w) for w in word_tokens if not w.lower() in stop_words]
return ' '.join(filtered_sentence)
# 1. 创建Elasticsearch连接
es = Elasticsearch(hosts=['http://117.50.198.53:9200'], # 服务地址与端口
http_auth=("elastic", "FKaB1Jpz0Rlw0l6G"), # 用户名,密码
)
# 2. 定义索引名称
index_name = "teacher_demo_index123"
# 3. 如果索引已存在,删除它(仅供演示,实际应用时不需要这步)
if es.indices.exists(index=index_name):
es.indices.delete(index=index_name)
# 4. 创建索引
es.indices.create(index=index_name)
# 5. 灌库指令
actions = [
{
"_index": index_name,
"_source": {
"keywords": to_keywords(para),
"text": para
}
}
for para in paragraphs ]
# 6. 文本灌库
helpers.bulk(es, actions)
def search(query_string, top_n=3):
# ES 的查询语言
search_query = {
"match": {
"keywords": to_keywords(query_string)
}
}
res = es.search(index=index_name, query=search_query, size=top_n)
return [hit["_source"]["text"] for hit in res["hits"]["hits"]]
results = search("how many parameters does llama 2 have?", 2)
for r in results:
print(r+"\n")
(3)LLM 接口封装
from openai import OpenAI
import os
# 加载环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # 读取本地 .env 文件,里面定义了 OPENAI_API_KEY
client = OpenAI()
def get_completion(prompt, model="gpt-3.5-turbo"):
'''封装 openai 接口'''
messages = [{"role": "user", "content": prompt}]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 模型输出的随机性,0 表示随机性最小
)
return response.choices[0].message.content
(4)Prompt提示构建
#提示模版
def build_prompt(prompt_template, \*\*kwargs):
'''将Prompt模板赋值'''
prompt = prompt_template
for k, v in kwargs.items():
if isinstance(v, str):
val = v
elif isinstance(v, list) and all(isinstance(elem,
str) for elem in v):
val = '\n'.join(v)
else:
val = str(v)
prompt = prompt.replace(f"__{k.upper()}__", val)
return prompt
prompt_template = """
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
确保你的回复完全依据下述已知信息。不要编造答案。
如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
已知信息:
__INFO__
用户问:
__QUERY__
请用中文回答用户问题。
"""
接下来就可以小试牛刀了。
user_query = "how many parameters does llama 2 have?"
# 1. 检索
search_results = search(user_query, 2)
# 2. 构建 Prompt
prompt = build_prompt(prompt_template, info=search_results, query=user_query)
print("===Prompt===")
print(prompt)
# 3. 调用 LLM
response = get_completion(prompt)
print("===回复===")
print(response)
===Prompt===
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
确保你的回复完全依据下述已知信息。不要编造答案。
如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
已知信息:
Llama 2 comes in a range of parameter sizes—7B, 13B, and 70B—as well as pretrained and fine-tuned variations.
1. Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by 40%, doubled the context length of the model, and adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with 7B, 13B, and 70B parameters. We have also trained 34B variants, which we report on in this paper but are not releasing.
用户问:
how many parameters does llama 2 have?
请用中文回答用户问题。
===回复===
Llama 2有7B、13B和70B三种参数大小的变体。
同一个语义,用词不同,可能导致检索不到有效的结果。
# user_query="Does llama 2 have a chat
#version?"
user_query = "Does llama 2 have a conversational variant?"
search_results = search(user_query, 2)
for res in search_results:
print(res+"\n")
1. Llama
2, an updated version of Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by 40%, doubled the context length of the model, and adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with 7B, 13B, and 70B parameters. We have also trained 34B variants, which we report on in this paper but are not releasing.We report the violation percentage on single- and multi-turn conversations, respectively. A trend across models is that multi-turn conversations are more prone to inducing unsafe responses. That said, Llama 2-Chat still performs well compared to baselines, especially on multi-turn conversations. We also observe that Falcon performs particularly well on single-turn conversations (largely due to its conciseness) but much worse on multi-turn conversations, which could be due to its lack of supervised fine-tuning data.
三、总结
RAG 的流程
- 离线步骤:
-
文档加载
-
文档切分
-
向量化
-
灌入向量数据库
在线步骤:
-
获得用户问题
-
用户问题向量化
-
检索向量数据库
-
将检索结果和用户问题填入 Prompt 模版
-
用最终获得的 Prompt 调用 LLM
-
由 LLM 生成回复
2、我用了一个开源的 RAG,不好使怎么办?
(1)检查预处理效果:文档加载是否正确,切割的是否合理
(2)测试检索效果:问题检索回来的文本片段是否包含答案
(3)测试大模型能力:给定问题和包含答案文本片段的前提下,大模型能不能正确回答问题。
扩展阅读
Elasticsearch(简称ES)是一个广泛应用的开源搜索引擎:https://www.elastic.co/
关于ES的安装、部署等知识,网上可以找到大量资料,例如:https://juejin.cn/post/7104875268166123528
关于经典信息检索技术的更多细节,可以参考: https://nlp.stanford.edu/IR-book/information-retrieval-book.html