前言
-
模型剪枝(Model Pruning)是一种用于减少神经网络模型尺寸和计算复杂度的技术。通过剪枝,可以去除模型中冗余的参数和连接,从而减小模型的存储需求和推理时间,同时保持模型的性能。
- 模型剪枝的一般步骤:
- 训练初始模型:训练一个初始的神经网络模型
- 评估参数重要性:计算每个参数的重要性指标来评估参数的贡献程度
- 剪枝冗余参数:根据阈值将参数置零,或者直接将对应的连接删除,从而减小模型的大小。
- 微调(Feine-tune):以恢复或提高模型的性能。
- 模型剪枝策略可以大致分为两种:粗粒度剪枝(Coarse-Grained Pruning)和细粒度剪枝(Fine-Grained Pruning)
-
粗粒度剪枝:被选择剪枝的单元是以较大的粒度进行的。在神经网络模型中,这通常意味着选择剪枝整个通道、卷积核、层或其他结构化的模块。
-
细粒度剪枝:被选择剪枝的单元是以较小的粒度进行的。在神经网络模型中,这意味着选择剪枝单个参数或连接。
- 本文仅针对模型粗剪枝进行示例,如果这篇博客看的人多的话,后面会推出细剪枝教程。
- 需要
NNI库的支持,请先安装好(pip install nni)
简单示例
训练初始模型
import torch
import torch.nn.functional as F
from torch.optim import SGD
from nni_assets.compression.mnist_model import TorchModel, trainer, evaluator, device
# 定义模型
model = TorchModel().to(device)
# 打印模型框架
print(model)
TorchModel(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=256, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
(relu1): ReLU()
(relu2): ReLU()
(relu3): ReLU()
(relu4): ReLU()
(pool1): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(pool2): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
# 定义优化器和损失函数
optimizer = SGD(model.parameters(), 1e-2)
criterion = F.nll_loss
# 预训练模型在MNIST数据集上评估模型
for epoch in range(3):
trainer(model, optimizer, criterion)
evaluator(model)
Average test loss: 0.6671, Accuracy: 8105/10000 (81%)
Average test loss: 0.2894, Accuracy: 9108/10000 (91%)
Average test loss: 0.1751, Accuracy: 9459/10000 (95%)
修剪冗余参数
- 使用
L1NormPruner方法评估参数重要性并修剪冗余参数
-
L1NormPruner(L1 范数剪枝器):支持线性层和卷积层。L1 范数剪枝器计算第一个维度上层权重的 l1 范数,然后用较小的 l1 范数值修剪该维度上的权重块。即,计算卷积层中滤波器的l1范数作为度量值,计算线性层中行权重的l1范数作为度量值。
- 剪枝方法有很多,这里使用最简单的一种,后面微调Bert模型会使用
Taylor FO Weight Pruner和Movement Pruner。
-
L1NormPruner策略参数L1NormPruner(model, config_list, mode='normal', dummy_input=None):
| 参数 |
含义 |
model |
要修剪的模型 |
config_list |
策略设定 |
mode |
'normal'或 'dependency_aware'
|
dummy_input |
用于分析拓扑约束的虚拟输入 |
config_list |
含义 |
sparsity |
指定要压缩的配置中每一层稀疏性 |
sparsity_per_layer |
等于sparsity
|
op_types |
L1NormPruner 支持 Conv2d 和 Linear |
op_partial_names |
要修剪的操作名称 |
exclude |
设置为True则op_types和 op_names 图层将被排除在修剪之外 |
from nni.compression.pytorch.pruning import L1NormPruner
# 稀疏性为0.1,针对线性层和Conv2d层。不对fc3进行剪枝
config_list = [{
'sparsity_per_layer': 0.1,
'op_types': ['Linear', 'Conv2d']
}, {
'exclude': True,
'op_names': ['fc3']
}]
pruner = L1NormPruner(model, config_list)
# 显示被包裹的模型结构,`PrunerModuleWrapper`已经包裹了config_list中配置的层。
print(model)
输出:
TorchModel(
(conv1): PrunerModuleWrapper(
(module): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
)
(conv2): PrunerModuleWrapper(
(module): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
)
(fc1): PrunerModuleWrapper(
(module): Linear(in_features=256, out_features=120, bias=True)
)
(fc2): PrunerModuleWrapper(
(module): Linear(in_features=120, out_features=84, bias=True)
)
(fc3): Linear(in_features=84, out_features=10, bias=True)
(relu1): ReLU()
(relu2): ReLU()
(relu3): ReLU()
(relu4): ReLU()
(pool1): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(pool2): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
压缩模型
# 压缩模型并产生掩码(masks矩阵)
_, masks = pruner.compress()
# 展示掩码的稀疏性
for name, mask in masks.items():
print(name, ' sparsity : ', '{:.2}'.format(mask['weight'].sum() / mask['weight'].numel()))
输出:
conv1 sparsity : 1.0
conv2 sparsity : 0.94
fc1 sparsity : 0.9
fc2 sparsity : 0.9
# 在加速之前需要解开模型包装
pruner._unwrap_model()
# 加速模型
from nni.compression.pytorch.speedup import ModelSpeedup
ModelSpeedup(model, torch.rand(3, 1, 28, 28).to(device), masks).speedup_model()
# 打印模型
print(model)
输出:
TorchModel(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 15, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=240, out_features=108, bias=True)
(fc2): Linear(in_features=108, out_features=76, bias=True)
(fc3): Linear(in_features=76, out_features=10, bias=True)
(relu1): ReLU()
(relu2): ReLU()
(relu3): ReLU()
(relu4): ReLU()
(pool1): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(pool2): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
- 可以看到
Linear和Conv2层参数量减少。重新定义优化器,并再次训练模型。
optimizer = SGD(model.parameters(), 1e-2)
for epoch in range(3):
trainer(model, optimizer, criterion)
evaluator(model)
输出:
Average test loss: 0.1495, Accuracy: 9539/10000 (95%)
Average test loss: 0.1148, Accuracy: 9662/10000 (97%)
Average test loss: 0.0962, Accuracy: 9715/10000 (97%)
对Bert模型剪枝、蒸馏和微调
模型原理图
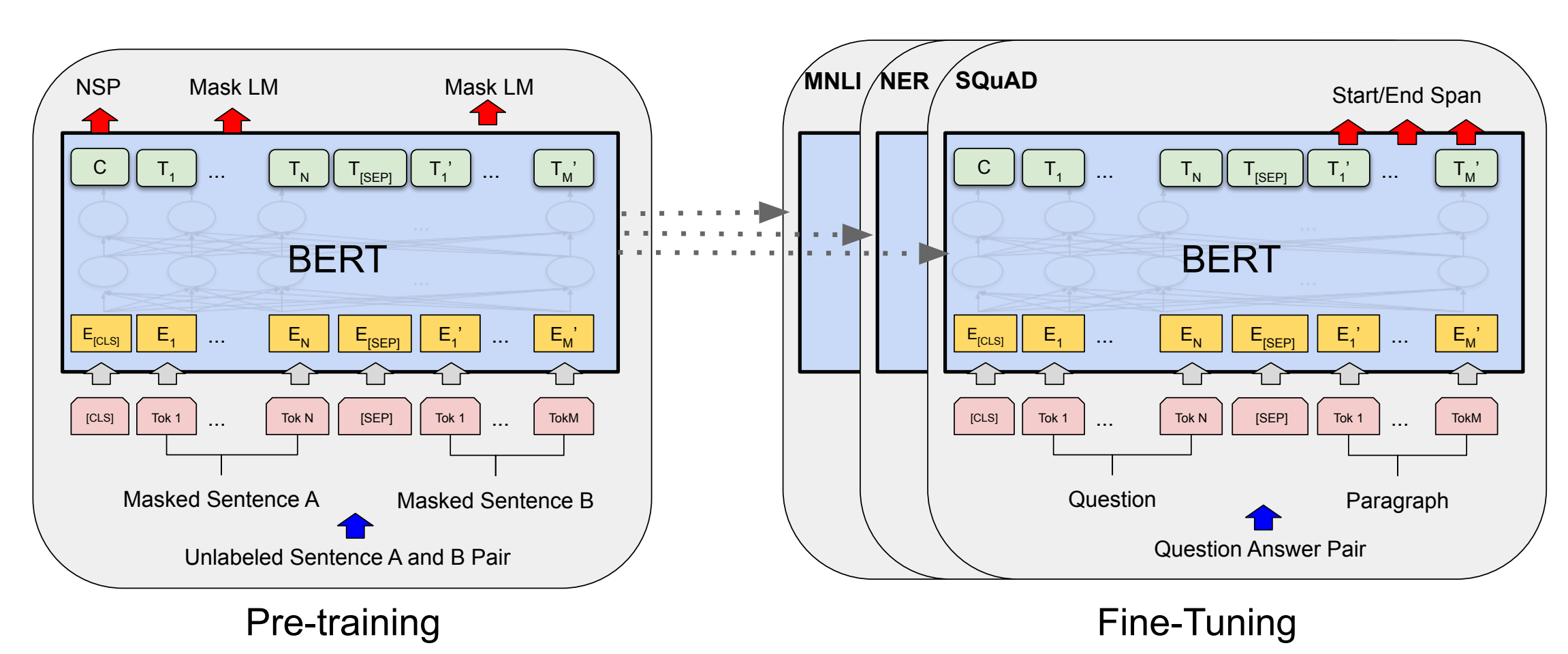
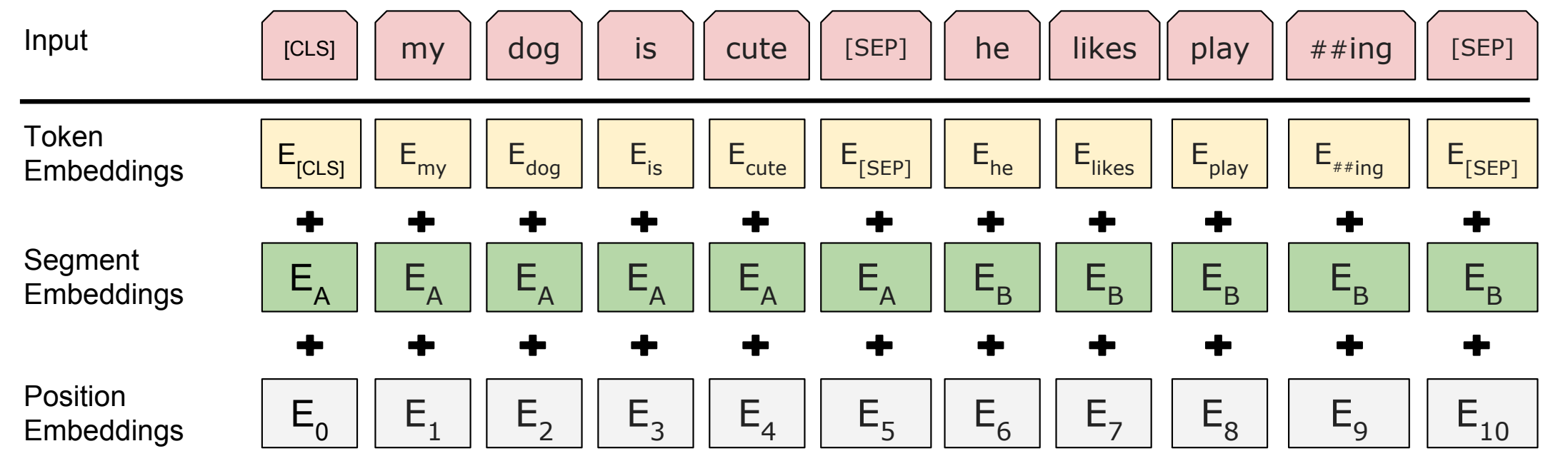
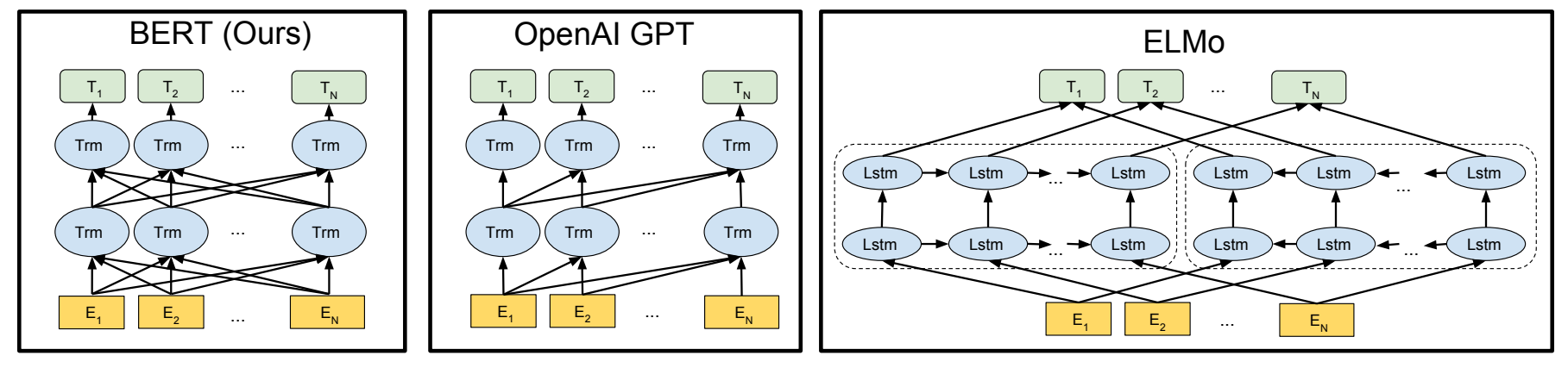
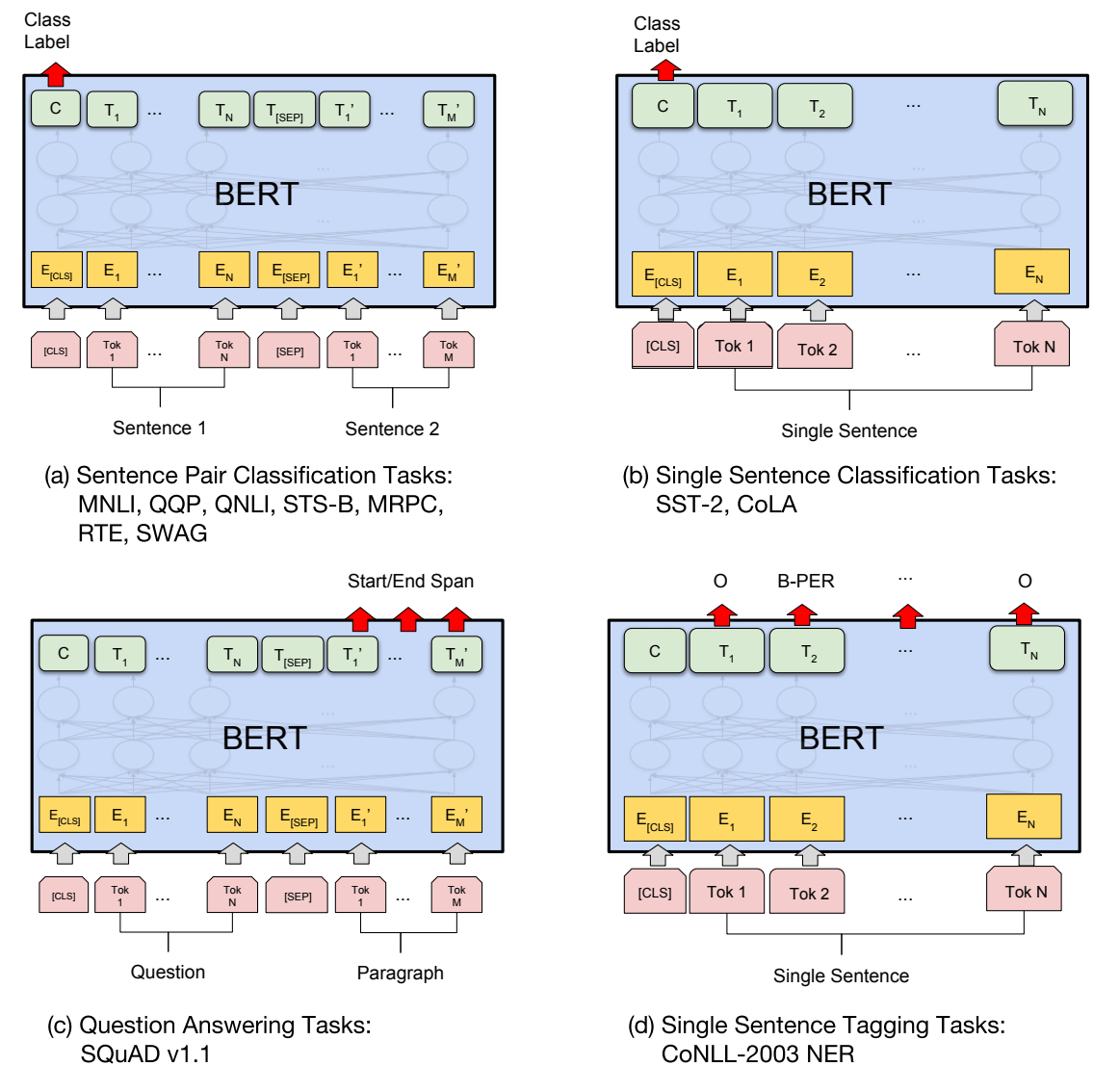
修剪过程
- 整个剪枝过程可以分为以下几个步骤:
- 在下游任务上微调预训练模型。根据经验,在微调模型上剪枝的最终性能优于直接在预训练模型上剪枝。同时,这一步得到的Finetuned模型也将作为后面蒸馏训练的teacher模型。
- 首先修剪注意力层。在这里,我们对注意力层权重应用块稀疏,如果头部被完全遮掩(mask),则直接修剪头部(压缩权重)。如果头部被部分遮盖,我们将不会修剪它并恢复其权重。
- 通过蒸馏重新训练头部修剪模型。在修剪FFN层前恢复模型精度
- 修剪FFN层。这里我们在第一层FFN层上应用输出通道修剪,由于第一层输出通道修剪,第二层FFN输入通道将被修剪。
- 通过蒸馏重新训练最终修剪后的模型。
- 在修剪Transformer过程中,我们获得了以下经验:
- 我们在注意力层上使用
Movement Pruner策略。在FFN层上使用Taylor FO Weight Pruner策略。这两个剪枝策略都是一些基于梯度的剪枝算法。
- 像
L1 Norm Pruner这样的基于权重的剪枝算法,但在这种场景下似乎效果不佳。
- 蒸馏是恢复模型精度的好方法。从结果来看,在MNLI任务上对Bert进行剪枝通常可以实现1~2%的精度提升。
- 有必要逐渐增加稀疏度,而不是一下子达到非常高的稀疏度。
实验
准备
- 在下游任务上得到一个微调模型(如果你熟悉如何在GLUE数据集上微调Bert,则可以跳过本节)
- 进行一些基本设置,详情请看代码注释
from pathlib import Path
from typing import Callable, Dict
# 是否生成文档,这里不生成False
dev_mode = False
# 预训练模型名称
pretrained_model_name_or_path = 'bert-base-uncased'
# 任务名称mnli(自然语言推理)
task_name = 'mnli'
# 实验名称
experiment_id = 'pruning_bert_mnli'
# head_num和layer_num参数应该与预训练模型一致
heads_num = 12
layers_num = 12
# 保存实验记录
log_dir = Path(f'./pruning_log/{pretrained_model_name_or_path}/{task_name}/{experiment_id}')
log_dir.mkdir(parents=True, exist_ok=True)
# 保存微调后的模型,并在具有相同预训练模型名称和任务名称实验之间共享。
model_dir = Path(f'./models/{pretrained_model_name_or_path}/{task_name}')
model_dir.mkdir(parents=True, exist_ok=True)
# 保存GLUE数据集
data_dir = Path(f'./data')
data_dir.mkdir(parents=True, exist_ok=True)
# 固定随机数种子
from transformers import set_seed
set_seed(1024)
import torch
# 获取运行设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- mnli(自然语言推理)数据的验证集有两个,通过将模型在这两个子集上的性能进行比较,可以获得更全面的评估结果,以便更好地了解模型的泛化能力和推理能力:
- validation_matched:与训练数据类似的子集,其中包含了与训练集中的句子相似的句子对。模型在这个子集上进行评估时,要对给定的前提和假设进行推理判断,并将其分类为"蕴含"、"矛盾"或"中立"的关系。
- validation_mismatched:与训练数据不同的子集,它包含了来自不同领域或流派的句子对。这个子集的目的是测试模型在面对与训练数据不同的文本类型时的泛化能力。模型在这个子集上的表现可以帮助评估其在不同上下文中的推理能力。
from torch.utils.data import DataLoader
from datasets import load_dataset
from transformers import BertTokenizerFast, DataCollatorWithPadding
# 不同任务关键词
task_to_keys = {
'cola': ('sentence', None),
'mnli': ('premise', 'hypothesis'),
'mrpc': ('sentence1', 'sentence2'),
'qnli': ('question', 'sentence'),
'qqp': ('question1', 'question2'),
'rte': ('sentence1', 'sentence2'),
'sst2': ('sentence', None),
'stsb': ('sentence1', 'sentence2'),
'wnli': ('sentence1', 'sentence2'),
}
def prepare_dataloaders(cache_dir=data_dir, train_batch_size=32, eval_batch_size=32):
# 加载预训练模型
tokenizer = BertTokenizerFast.from_pretrained(pretrained_model_name_or_path)
# 获取sentence1、sentence2关键词
sentence1_key, sentence2_key = task_to_keys[task_name]
# DataCollatorWithPadding将具有不同长度序列数据组合成相同长度的batch,以便进行模型训练和推理
data_collator = DataCollatorWithPadding(tokenizer)
# 预处理原始数据
def preprocess_function(examples):
args = (
(examples[sentence1_key],) if sentence2_key is None else (examples[sentence1_key], examples[sentence2_key])
)
result = tokenizer(*args, padding=False, max_length=128, truncation=True)
if 'label' in examples:
# 将列重命名为标签,因为模型模型输入格式要求
result['labels'] = examples['label']
return result
# 下载GLUE数据
raw_datasets = load_dataset('glue', task_name, cache_dir=cache_dir)
# 如果test关键字出现,删除
for key in list(raw_datasets.keys()):
if 'test' in key:
raw_datasets.pop(key)
# 将函数preprocess_function依次作用在raw_datasets的每个元素上
processed_datasets = raw_datasets.map(preprocess_function, batched=True,
remove_columns=raw_datasets['train'].column_names)
train_dataset = processed_datasets['train']
# 如果任务为mnli
if task_name == 'mnli':
# validation_matched:与训练数据类似的子集,其中包含了与训练集中的句子相似的句子对
# validation_mismatched:与训练数据不同的子集,它包含了来自不同领域或流派的句子对
validation_datasets = {
'validation_matched:': processed_datasets['validation_matched'],
'validation_mismatched': processed_datasets['validation_mismatched']
}
else:
validation_datasets = {
'validation': processed_datasets['validation']
}
# 训练数据加载器
train_dataloader = DataLoader(train_dataset, shuffle=True, collate_fn=data_collator, batch_size=train_batch_size)
# 验证数据加载器
validation_dataloaders = {
val_name: DataLoader(val_dataset, collate_fn=data_collator, batch_size=eval_batch_size) \
for val_name, val_dataset in validation_datasets.items()
}
return train_dataloader, validation_dataloaders
# 获得训练、验证数据加载器
train_dataloader, validation_dataloaders = prepare_dataloaders()
训练、评估模型
import functools
import time
import torch.nn.functional as F
from datasets import load_metric
from transformers.modeling_outputs import SequenceClassifierOutput
def training(model: torch.nn.Module,
optimizer: torch.optim.Optimizer,
criterion: Callable[[torch.Tensor, torch.Tensor], torch.Tensor],
lr_scheduler: torch.optim.lr_scheduler._LRScheduler = None,
max_steps: int = None,
max_epochs: int = None,
train_dataloader: DataLoader = None,
distillation: bool = False,
teacher_model: torch.nn.Module = None,
distil_func: Callable = None,
log_path: str = Path(log_dir) / 'training.log',
save_best_model: bool = False,
save_path: str = None,
evaluation_func: Callable = None,
eval_per_steps: int = 1000,
device=None):
# 检查训练加载器是否存在
assert train_dataloader is not None
# 将模型置为训练模式
model.train()
# 如果teacher_model不为空
if teacher_model is not None:
# 将teacher_model置为评估模式
teacher_model.eval()
# 当前step
current_step = 0
# 最佳结果
best_result = 0
# 总迭代次数,如果存在max_steps,则为max_steps // len(train_dataloader) + 1
# 如果存在max_epochs,则为max_epochs,否则,默认为 3。
total_epochs = max_steps // len(train_dataloader) + 1 if max_steps else max_epochs if max_epochs else 3
# 如果存在max_steps,则将max_steps赋值给total_steps。否则,为每个训练轮数迭代次数乘以总训练轮数
total_steps = max_steps if max_steps else total_epochs * len(train_dataloader)
print(f'Training {total_epochs} epochs, {total_steps} steps...')
for current_epoch in range(total_epochs):
# 取batch
for batch in train_dataloader:
# 如果当前step >= 总step
if current_step >= total_steps:
# 结束
return
# 将batch放入设备
batch.to(device)
# 得到输出
outputs = model(**batch)
# 得到loss
loss = outputs.loss
# 如果执行蒸馏操作
if distillation:
# 检查teacher_model是否存在
assert teacher_model is not None
# 不计算梯度
with torch.no_grad():
# 得到teacher网络的输出
teacher_outputs = teacher_model(**batch)
# 计算蒸馏loss
distil_loss = distil_func(outputs, teacher_outputs)
# loss等于0.1 * model_loss + 0.9 * distil_loss
loss = 0.1 * loss + 0.9 * distil_loss
loss = criterion(loss, None)
# 梯度清零
optimizer.zero_grad()
# 误差反向传播
loss.backward()
# 更新梯度
optimizer.step()
# 学习率策略更新
if lr_scheduler:
lr_scheduler.step()
# 当前step自增
current_step += 1
# 如果达到检查节点
if current_step % eval_per_steps == 0 or current_step % len(train_dataloader) == 0:
# 返回模型在验证集上的结果
result = evaluation_func(model) if evaluation_func else None
# 输出日志
with (log_path).open('a+') as f:
msg = '[{}] Epoch {}, Step {}: {}\n'.format(time.asctime(time.localtime(time.time())), current_epoch, current_step, result)
f.write(msg)
# 如果是最优模型,则保存
if save_best_model and (result is None or best_result < result['default']):
# 检查save_path是否为空
assert save_path is not None
torch.save(model.state_dict(), save_path)
best_result = None if result is None else result['default']
- 定义蒸馏模型loss
- 首先函数定义了一个空列表
encoder_hidden_state_loss,用于存储编码器隐藏状态的损失值。它使用一个循环来遍历encoder_layer_idxs的索引(除了最后一个索引),并计算学生模型输出的第i个隐藏状态与教师模型输出的第idx个隐藏状态之间的均方误差损失(MSE),并将其添加到encoder_hidden_state_loss列表中。
- 然后计算logits损失。并使用 KL 散度(Kullback-Leibler divergence)来度量学生模型输出的logits与教师模型输出的logits之间的差异。具体来说,先对学生模型logits和教师模型logits进行对数softmax处理(缩放因子为2),然后使用
F.kl_div函数计算它们之间的KL散度。reduction='batchmean'指定了计算KL散度的方式,并将结果乘以2 ** 2。
- 最后将
distil_loss初始化为0。然后,通过循环将encoder_hidden_state_loss列表中的每个损失值累加到distil_loss中。最后,将logits_loss加到distil_loss中,并返回最终蒸馏损失值。
# 蒸馏模型loss
def distil_loss_func(stu_outputs: SequenceClassifierOutput, tea_outputs: SequenceClassifierOutput, encoder_layer_idxs=[]):
# 存储编码器隐藏状态的损失值
encoder_hidden_state_loss = []
# 遍历encoder_layer_idxs的索引(除了最后一个)
for i, idx in enumerate(encoder_layer_idxs[:-1]):
# 计算学生模型输出的第i个隐藏状态与教师模型输出的第idx个隐藏状态之间的均方误差损失
encoder_hidden_state_loss.append(F.mse_loss(stu_outputs.hidden_states[i], tea_outputs.hidden_states[idx]))
# 计算logits_loss损失,使用KL散度度量学生模型输出的logits与教师模型输出的logits之间的差异
logits_loss = F.kl_div(F.log_softmax(stu_outputs.logits / 2, dim=-1), F.softmax(tea_outputs.logits / 2, dim=-1), reduction='batchmean') * (2 ** 2)
distil_loss = 0
# 将encoder_hidden_state_loss中loss累加
for loss in encoder_hidden_state_loss:
distil_loss += loss
# 再加上KL散度损失
distil_loss += logits_loss
return distil_loss
- 定义评估模型
- 值得注意的是预测结果的获取,如果
is_regression值为 False,即任务是分类任务,那么outputs.logits是一个张量,其形状为[batch_size, num_classes],表示模型对每个类别的预测分数。使用argmax(dim=-1)函数可以找到每个样本预测最大值所在的类别索引,这样可以得到模型对每个样本的分类预测。因此,predictions的形状是[batch_size],每个元素是一个整数,表示每个样本的预测类别。
- 如果
is_regression的值为True,即任务是回归任务,那么outputs.logits是一个张量,其形状为[batch_size, 1],表示模型对每个样本的回归预测值。使用squeeze()函数可以去除维度为1的维度,将outputs.logits形状变为[batch_size],这样得到每个样本的回归预测值。因此,predictions的形状是[batch_size],每个元素是一个实数,表示每个样本的回归预测值。
- 本示例任务类型为MNLI所以
is_regression值为 False,分类任务
# 定义评估函数
def evaluation(model: torch.nn.Module, validation_dataloaders: Dict[str, DataLoader] = None, device=None):
# 检查验证集数据加载器是否为空
assert validation_dataloaders is not None
# 指示当前模型是否处于训练模式,若为训练模式返回True
training = model.training
# 将模型置为评估模式
model.eval()
# 是否为回归
is_regression = task_name == 'stsb'
# 评估文本间文本相似性
metric = load_metric('glue', task_name)
result = {}
default_result = 0
for val_name, validation_dataloader in validation_dataloaders.items():
# 取batch
for batch in validation_dataloader:
batch.to(device)
outputs = model(**batch)
#得到预测值
predictions = outputs.logits.argmax(dim=-1) if not is_regression else outputs.logits.squeeze()
metric.add_batch(
predictions=predictions,
references=batch['labels'],
)
result[val_name] = metric.compute()
# 计算F1值和准确率
default_result += result[val_name].get('f1', result[val_name].get('accuracy', 0))
result['default'] = default_result / len(result)
# 将模型回归初始状态
model.train(training)
return result
- 使用
functools创建偏函数(Partial function),偏函数是指固定一个函数的部分参数,从而创建一个新的函数。这样可以将原始函数的部分参数值预先设置,以便在后续调用时只需提供剩余的参数值。
evaluation_func = functools.partial(evaluation, validation_dataloaders=validation_dataloaders, device=device)
def fake_criterion(loss, _):
return loss
预训练模型并微调
- 生成预训练模型。由于MNLI数据集包含三个类别的标签,分别是entailment(蕴含),contradiction(矛盾),neutral(中性),需要将
num_labels设置为 3,以确保模型的输出层能够适应这三个类别的分类任务。
- 设置模型
output_hidden_states为True,调用 BERT 模型,除了返回预测结果之外,还会返回一个包含所有隐藏层隐藏状态的列表。
from torch.optim import Adam
from torch.optim.lr_scheduler import LambdaLR
from transformers import BertForSequenceClassification
def create_pretrained_model():
# 判断是否为回归任务
is_regression = task_name == 'stsb'
# 若为回归任务设为1,若不为回归任务并且task_name为mnli设为3,其他情况设为2
num_labels = 1 if is_regression else (3 if task_name == 'mnli' else 2)
# 加载预训练模型,设定输出
model = BertForSequenceClassification.from_pretrained(pretrained_model_name_or_path, num_labels=num_labels)
model.bert.config.output_hidden_states = True
return model
# 创建微调模型
def create_finetuned_model():
# 将预训练模型赋给finetuned_model
finetuned_model = create_pretrained_model()
# 设置微调模型保存路径
finetuned_model_state_path = Path(model_dir) / 'finetuned_model_state.pth'
# 如果微调模型存在
if finetuned_model_state_path.exists():
# 直接加载模型,并指定模型在加载时应该被映射到的设备
finetuned_model.load_state_dict(torch.load(finetuned_model_state_path, map_location='cpu'))
# 转移模型到对应设备
finetuned_model.to(device)
elif dev_mode:
pass
# 如果微调模型不存在
else:
# 统计一个epoch中的steps
steps_per_epoch = len(train_dataloader)
# 训练epochs
training_epochs = 3
# 优化器为adam
optimizer = Adam(finetuned_model.parameters(), lr=3e-5, eps=1e-8)
# 学习率更新函数
def lr_lambda(current_step: int):
return max(0.0, float(training_epochs * steps_per_epoch - current_step) / float(training_epochs * steps_per_epoch))
# 学习率更新策略
lr_scheduler = LambdaLR(optimizer, lr_lambda)
# 微调模型为model,无teacher模型
training(finetuned_model, optimizer, fake_criterion, lr_scheduler=lr_scheduler,
max_epochs=training_epochs, train_dataloader=train_dataloader, log_path=log_dir / 'finetuning_on_downstream.log',
save_best_model=True, save_path=finetuned_model_state_path, evaluation_func=evaluation_func, device=device)
return finetuned_model
# 得到微调模型
finetuned_model = create_finetuned_model()
修剪
- 根据经验,分阶段剪枝
attention部分和FFN部分更容易取得好的效果。当然一起剪枝也可以达到类似的效果,只是需要更多的参数调整尝试。在本节中,我们分阶段进行剪枝。
修剪注意力层
- 使用
MovementPruner修剪策略修剪注意力层。MovementPruner是动态(Movement)修剪的一种实现。这是一种“微调”算法,这意味着掩码可能会在每个微调步骤中发生变化。在每一步中,每个权重元素将根据权重与其梯度的乘积之和的相反数进行评分。这意味着向零移动的权重元素将累积负分,远离零的权重元素将累积正分。得分较低的权重元素将在推理过程中被屏蔽。
-
MovementPruner函数参数:
| 参数 |
含义 |
model |
要修剪的模型 |
config_list |
策略设定 |
evaluator |
评估器 |
warm_up_step |
在开始修剪前预热step,该参数小于 cool_down_beginning_step
|
cool_down_beginning_step |
稀疏度停止增长的步数,请注意,稀疏度停止增长并不意味着掩码没有改变 |
training_epochs |
训练模型epoch,若同时设置了training_epochs和training_steps,则修剪将在达到其中一个时停止,该参数大于 cool_down_beginning_step
|
training_steps |
训练模型steps,若同时设置了training_epochs和training_steps,则修剪将在达到其中一个时停止,该参数大于 cool_down_beginning_step
|
regular_scale |
缩放运动分数常规损失在“软(soft)”模式下,更高的规则尺度意味着更高的最终稀疏度。 |
movement_mode |
“硬(hard)”或“软(soft)” |
config_list |
含义 |
sparsity |
指定要压缩的配置中每一层稀疏性 |
sparsity_per_layer |
等于sparsity
|
op_types |
L1NormPruner 支持 Conv2d 和 Linear |
op_partial_names |
要修剪的操作名称 |
exclude |
设置为True则op_types和 op_names 图层将被排除在修剪之外 |
import nni
from nni.algorithms.compression.v2.pytorch import TorchEvaluator
movement_training = functools.partial(training, train_dataloader=train_dataloader,
log_path=log_dir / 'movement_pruning.log',
evaluation_func=evaluation_func, device=device)
traced_optimizer = nni.trace(Adam)(finetuned_model.parameters(), lr=3e-5, eps=1e-8)
def lr_lambda(current_step: int):
if current_step < warmup_steps:
return float(current_step) / warmup_steps
return max(0.0, float(total_steps - current_step) / float(total_steps - warmup_steps))
traced_scheduler = nni.trace(LambdaLR)(traced_optimizer, lr_lambda)
evaluator = TorchEvaluator(movement_training, traced_optimizer, fake_criterion, traced_scheduler)
from nni.compression.pytorch.pruning import MovementPruner
# 统计一个epoch中的steps
steps_per_epoch = len(train_dataloader)
# 设定修剪steps或epochs
if not dev_mode:
total_epochs = 4
total_steps = total_epochs * steps_per_epoch
warmup_steps = 1 * steps_per_epoch
cooldown_steps = 1 * steps_per_epoch
else:
total_epochs = 1
total_steps = 3
warmup_steps = 1
cooldown_steps = 1
# 修剪,每一层encoder的attention中的Linear,稀疏率为0.1
config_list = [{
'op_types': ['Linear'],
'op_partial_names': ['bert.encoder.layer.{}.attention'.format(i) for i in range(layers_num)],
'sparsity': 0.1
}]
pruner = MovementPruner(model=finetuned_model,
config_list=config_list,
evaluator=evaluator,
training_epochs=total_epochs,
training_steps=total_steps,
warm_up_step=warmup_steps,
cool_down_beginning_step=total_steps - cooldown_steps,
regular_scale=10,
movement_mode='soft',
sparse_granularity='auto')
# 执行剪枝
_, attention_masks = pruner.compress()
# 展示剪枝权重
pruner.show_pruned_weights()
# 保存attention_masks权重
torch.save(attention_masks, Path(log_dir) / 'attention_masks.pth')
- 加载一个新的微调模型来做加速(
speedup),可以认为这是使用微调状态来初始化剪枝后的模型权重。注意nni speedup不支持替换attention module,所以这里我们手动替换attention module。
- 如果头部(head)被整个屏蔽,则对其进行物理修剪并为FFN修剪创建
config_list。
# 重新创建一个新的微调模型
attention_pruned_model = create_finetuned_model().to(device)
# 取上面通过MovementPruner得到的attention_masks矩阵
attention_masks = torch.load(Path(log_dir) / 'attention_masks.pth')
# 创建空列表
ffn_config_list = []
layer_remained_idxs = []
module_list = []
# 在模型初始设定部分,layers_nums = 12
for i in range(0, layers_num):
prefix = f'bert.encoder.layer.{i}.'
# 取各attention层mask矩阵权重
value_mask: torch.Tensor = attention_masks[prefix + 'attention.self.value']['weight']
# 观察头部是否被完全掩盖
head_mask = (value_mask.reshape(heads_num, -1).sum(-1) == 0.)
# 取head_mask下标
head_idxs = torch.arange(len(head_mask))[head_mask].long().tolist()
print(f'layer {i} prune {len(head_idxs)} head: {head_idxs}')
if len(head_idxs) != heads_num:
attention_pruned_model.bert.encoder.layer[i].attention.prune_heads(head_idxs)
# 加入module_list
module_list.append(attention_pruned_model.bert.encoder.layer[i])
# 最后的FFN剩余权重比率是attention剩余权重比率的一半
# 这只是一个经验性的配置,你可以使用任何其他方法来确定这个稀疏度
sparsity = 1 - (1 - len(head_idxs) / heads_num) * 0.5
# 稀疏性计划,我们将在12次迭代中修剪FFN,每次迭代修剪sparsity_per_iter
sparsity_per_iter = 1 - (1 - sparsity) ** (1 / 12)
# FFN修剪计划配置:修剪intermediate.dense
ffn_config_list.append({
'op_names': [f'bert.encoder.layer.{len(layer_remained_idxs)}.intermediate.dense'],
'sparsity': sparsity_per_iter
})
layer_remained_idxs.append(i)
# 将bert.encoder.layer替换为model_list
attention_pruned_model.bert.encoder.layer = torch.nn.ModuleList(module_list)
# 创建蒸馏损失偏函数
distil_func = functools.partial(distil_loss_func, encoder_layer_idxs=layer_remained_idxs)
if not dev_mode:
total_epochs = 5
total_steps = None
distillation = True
else:
total_epochs = 1
total_steps = 1
distillation = False
# teacher模型
teacher_model = create_finetuned_model()
# Adam优化器
optimizer = Adam(attention_pruned_model.parameters(), lr=3e-5, eps=1e-8)
# 学习率更新函数
def lr_lambda(current_step: int):
return max(0.0, float(total_epochs * steps_per_epoch - current_step) / float(total_epochs * steps_per_epoch))
# 学习率动态更新
lr_scheduler = LambdaLR(optimizer, lr_lambda)
# 模型保存路径
at_model_save_path = log_dir / 'attention_pruned_model_state.pth'
# student模型为attention_pruned_model,teacher模型为微调模型
training(attention_pruned_model, optimizer, fake_criterion, lr_scheduler=lr_scheduler, max_epochs=total_epochs,
max_steps=total_steps, train_dataloader=train_dataloader, distillation=distillation, teacher_model=teacher_model,
distil_func=distil_func, log_path=log_dir / 'retraining.log', save_best_model=True, save_path=at_model_save_path,
evaluation_func=evaluation_func, device=device)
if not dev_mode:
attention_pruned_model.load_state_dict(torch.load(at_model_save_path))
- 使用
TaylorFOWeightPruner策略在 12 次迭代中迭代修剪 FFN。每次修剪迭代后微调 3000 步,然后在修剪完成后微调 2 个 epoch。
# 设定修剪steps或epochs
if not dev_mode:
total_epochs = 7
total_steps = None
taylor_pruner_steps = 1000
steps_per_iteration = 3000
total_pruning_steps = 36000
distillation = True
else:
total_epochs = 1
total_steps = 6
taylor_pruner_steps = 2
steps_per_iteration = 2
total_pruning_steps = 4
distillation = False
# 创建TaylorFOWeightPruner评估器
from nni.compression.pytorch.pruning import TaylorFOWeightPruner
from nni.compression.pytorch.speedup import ModelSpeedup
distil_training = functools.partial(training, train_dataloader=train_dataloader, distillation=distillation,
teacher_model=teacher_model, distil_func=distil_func, device=device)
traced_optimizer = nni.trace(Adam)(attention_pruned_model.parameters(), lr=3e-5, eps=1e-8)
evaluator = TorchEvaluator(distil_training, traced_optimizer, fake_criterion)
# 当前step
current_step = 0
# 最好结果
best_result = 0
# 初始学习率
init_lr = 3e-5
dummy_input = torch.rand(8, 128, 768).to(device)
# 将模型置为训练模式
attention_pruned_model.train()
for current_epoch in range(total_epochs):
for batch in train_dataloader:
if total_steps and current_step >= total_steps:
break
# 用TaylorFOWeightPruner进行修剪,并重新初始化优化器
if current_step % steps_per_iteration == 0 and current_step < total_pruning_steps:
# 模型权重
check_point = attention_pruned_model.state_dict()
# 修剪
pruner = TaylorFOWeightPruner(attention_pruned_model, ffn_config_list, evaluator, taylor_pruner_steps)
# 得到FFN掩码(mask)矩阵
_, ffn_masks = pruner.compress()
renamed_ffn_masks = {}
# 重新命名掩码键,因为只是针对bert.encoder的速度
for model_name, targets_mask in ffn_masks.items():
renamed_ffn_masks[model_name.split('bert.encoder.')[1]] = targets_mask
# 将模型解包
pruner._unwrap_model()
# 加载模型权重
attention_pruned_model.load_state_dict(check_point)
# speedup操作
ModelSpeedup(attention_pruned_model.bert.encoder, dummy_input, renamed_ffn_masks).speedup_model()
# 重新定义优化器
optimizer = Adam(attention_pruned_model.parameters(), lr=init_lr)
batch.to(device)
# 学习率更新策略
for params_group in optimizer.param_groups:
params_group['lr'] = (1 - current_step / (total_epochs * steps_per_epoch)) * init_lr
# 得到输出
outputs = attention_pruned_model(**batch)
# 计算loss
loss = outputs.loss
# 蒸馏
if distillation:
assert teacher_model is not None
with torch.no_grad():
teacher_outputs = teacher_model(**batch)
distil_loss = distil_func(outputs, teacher_outputs)
loss = 0.1 * loss + 0.9 * distil_loss
# 梯度清零
optimizer.zero_grad()
# 误差反向传播
loss.backward()
# 梯度更新
optimizer.step()
current_step += 1
# 输出模型中间精度,保存最佳模型
if current_step % 1000 == 0 or current_step % len(train_dataloader) == 0:
result = evaluation_func(attention_pruned_model)
with (log_dir / 'ffn_pruning.log').open('a+') as f:
msg = '[{}] Epoch {}, Step {}: {}\n'.format(time.asctime(time.localtime(time.time())),
current_epoch, current_step, result)
f.write(msg)
if current_step >= total_pruning_steps and best_result < result['default']:
torch.save(attention_pruned_model, log_dir / 'best_model.pth')
best_result = result['default']