目录
Abstract
1.Introduction
2.Related work
2.1.Image Deblurring
2.2.Generative adversarial networks
3. DeblurGAN-v2 Architecture
3.1. Feature Pyramid Deblurring特征金字塔
3.2. Choice of Backbones:Trade-off between Performance and Efficiency
3.3. Double-Scale RaGAN-LS Discriminator
3.4. Training Datasets
4. Experimental evaluation
4.1. Quantitative Evaluation on GoPro Dataset
4.2. Quantitative Evaluation on Kohler dataset
4.3. Ablation Study and Analysis
4.4. Extension to General Restoration
5. Conclusion
Abstract
设计了一个新的端到端的生成对抗网络,为了解决运动中图像模糊问题,DeblurGAN-V2,基于relativistic conditional GAN(拥有双尺度鉴别器)
首次将特征金字塔引入到去模糊问题,作为生成器的核心模块。可以灵活搭配各种主干网络,选择Inception-ResNet-v2主干网络可以获得更高的图片质量,采用轻量级网络像MobileNet和他的变形体可以获得更快的速度。
DeblurGAN-v2 在去模糊质量以及效率方面在几个流行的基准测试中获得了非常有竞争力的性能。此外,该架构对于一般图像恢复任务也是有效的。
论文原文:https://arxiv.org/abs/1908.03826
论文原码:GitHub - VITA-Group/DeblurGANv2: [ICCV 2019] "DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better" by Orest Kupyn, Tetiana Martyniuk, Junru Wu, Zhangyang Wang
1.Introduction
基于 DeblurGAN 的成功,本文旨在进一步推动基于 GAN 的运动去模糊。 我们引入了一个新框架来改进 DeblurGAN,称为 DeblurGAN-v2,提高了去模糊性能、效率、质量、高灵活性。 创新总结:
- 框架方面:构建了一个新的条件 GAN 框架来进行去模糊。对于生成器,首次将特征金字塔网络 (FPN) 引入到图像恢复任务中。对于鉴别器,我们采用relativistic鉴别器 ,其中使用最小二乘损失,并有两个评估,全局(image)和局部(batch)尺度。
-
主干方面:虽然上述框架与生成器主干无关,但选择会影响去模糊质量和效率。为了追求高质量去模糊,我们使用Inception-ResNet-v2 主干。为了提高速度,我们采用了 MobileNet,并进一步创建了具有深度可分离卷积 (MobileNet-DSC) 的变体。后两者在尺寸上变得非常紧凑并且推理速度很快。
-
实验方面:我们在三个流行的基准测试中进行了非常广泛的实验,以展示 DeblurGANv2 性能(PSNR、SSIM 和 perceptual quality)。在效率方面,带有 MobileNet-DSC 的 DeblurGAN-v2 比 DeblurGAN 快 11 倍,比DeepDeblur 和 ScaleRecurrent Network (SRN) 快 100 多倍,并且模型大小仅为 4 MB,这意味着有可能实现实时视频去模糊。我们还对真实模糊图像的去模糊质量进行研究。最后,我们展示了我们的模型在一般图像恢复中的潜力,作为额外的灵活性。
-

2.1.Image Deblurring
单幅图像运动去模糊传统上被视为去卷积问题。 早期的模型依靠自然图像先验来规范去模糊, 然而大多数手工制作的先验不能很好地捕捉真实图像中复杂的模糊变化。
新兴的深度学习技术推动了图像恢复任务的突破。利用卷积神经网络(CNN)进行模糊核估计。 使用完全卷积网络来估计运动流。 除了那些基于内核的方法之外,还探索了端到端的无内核 CNN 方法,以直接从模糊输入中恢复干净的图像。将 Multi-Scale CNN 用于盲图像去模糊的 Scale-Recurrent CNN,结果令人印象深刻。
自 Ramakrishnan 等人以来,GAN 在图像恢复方面的成功也影响了单幅图像去模糊。
2.2.Generative adversarial networks
GAN 由两个模型组成:鉴别器 D 和生成器 G。详细的可以看前面的GAN简介
目标函数:![minGmaxD,V(D,G)=E_{x\sim p_{data}(x)}[logD(x)]+E_{z\sim p_{z}(z)}[log(1-D(G(z)))]](https://latex.csdn.net/eq?minGmaxD%2CV%28D%2CG%29%3DE_%7Bx%5Csim%20p_%7Bdata%7D%28x%29%7D%5BlogD%28x%29%5D+E_%7Bz%5Csim%20p_%7Bz%7D%28z%29%7D%5Blog%281-D%28G%28z%29%29%29%5D)
这样的目标函数很难优化,还会在训练时产生模式崩溃或梯度消失/爆炸。 为了修复消失的梯度并稳定训练,最小二乘 GAN 鉴别器(LSGAN)试图引入一个损失函数,提供更平滑和不饱和的梯度。 作者观察到 log-type loss 很快饱和,因为它忽略了 x 到决策边界之间的距离。 相比之下,L2 损失提供与该距离成比例的梯度,因此离边界越远的假样本会受到更大的惩罚。 提议的损失函数还最小化了 Pearson χ 2 散度,从而获得更好的训练稳定性。LSGAN目标函数如下:
![minD,V(D)=\frac{1}{2}E_{x\sim p_{data}(x)}[(D(x)-1)^2]+\frac{1}{2}E_{z\sim p_{z}(z)}[D(G(z))^2]](https://latex.csdn.net/eq?minD%2CV%28D%29%3D%5Cfrac%7B1%7D%7B2%7DE_%7Bx%5Csim%20p_%7Bdata%7D%28x%29%7D%5B%28D%28x%29-1%29%5E2%5D+%5Cfrac%7B1%7D%7B2%7DE_%7Bz%5Csim%20p_%7Bz%7D%28z%29%7D%5BD%28G%28z%29%29%5E2%5D)
![minG,V(G)=\frac{1}{2}E_{z\sim p_{z}(z)}[(D(G(z))-1)^2]](https://latex.csdn.net/eq?minG%2CV%28G%29%3D%5Cfrac%7B1%7D%7B2%7DE_%7Bz%5Csim%20p_%7Bz%7D%28z%29%7D%5B%28D%28G%28z%29%29-1%29%5E2%5D)
GAN 的另一个相关改进是 Relativistic GAN [16]。 它使用relativistic鉴别器来估计给定的真实数据比随机采样的假数据更真实的概率。relativistic鉴别器显示出更稳定和计算效率更高的训练。

3. DeblurGAN-v2 Architecture
3.1. Feature Pyramid Deblurring特征金字塔
FPN 包括自下而上和自上而下的路径。 自下而上的路径是用于特征提取的常用卷积网络,虽然空间分辨率被降采样,但更多的语义上下文信息被提取和压缩。 通过自上而下的路径,FPN 从语义丰富的层重建更高的空间分辨率。 自下而上和自上而下路径之间的横向连接补充了高分辨率细节并帮助定位对象。
本文所设计的FPN包含5个尺度的特征输出,这些特征被下采样到原始输入四分之一大小并拼接作为一个整体(它包含多尺度信息),然后连接两个上采样和卷基层以复原到原始图像大小并减少伪影。类似DeblurGAN,引入了全局残差连接。输入图像归一化到[-1, 1],在输出部分使用tanh激活以确保生成的图像在相同范围内。FPN除具有多尺度特征汇聚功能外,它还在精度与效率之间取得均衡。
新的 FPN 嵌入式架构与特征提取器主干的选择无关。 有了这种即插即用的特性,根据性能和效率我们可以灵活的选择不同的网络。 默认情况下,我们选择 ImageNet 预训练的主干来传达更多与语义相关的特征。 使用 Inception-ResNet-v2 来追求更好的去模糊性能。
由于移动设备图像增强的需求,作者选择 MobileNet V2 主干网络。 为了进一步降低复杂性,在 DeblurGANv2 和 MobileNet V2 之上尝试了另一个更积极的选择,通过用 Depthwise Separable Convolutions 替换整个网络中的所有正常卷积(包括不在主干中的那些)。 生成的模型表示为 MobileNet-DSC,可以提供极其轻量级和高效的图像去模糊。
3.3. Double-Scale RaGAN-LS Discriminator
DeblurGAN 中使用的是 WGAN-GP 鉴别器。作者在 LSGAN 上使用 relativistic ,创建新的 RaGAN-LS 损失函数:
![L_{D}^{RaLSGAN}=E_{x \sim P_{data}(x)} [ D(x)-E_{z\sim p_{z}(z)}[D(G(z)-1)^2]+E_{z\sim p_{z}(z)}[D(G(z))-E_{x\sim P_{data}(x)}(D(x)+1)^2]](https://latex.csdn.net/eq?L_%7BD%7D%5E%7BRaLSGAN%7D%3DE_%7Bx%20%5Csim%20P_%7Bdata%7D%28x%29%7D%20%5B%20D%28x%29-E_%7Bz%5Csim%20p_%7Bz%7D%28z%29%7D%5BD%28G%28z%29-1%29%5E2%5D+E_%7Bz%5Csim%20p_%7Bz%7D%28z%29%7D%5BD%28G%28z%29%29-E_%7Bx%5Csim%20P_%7Bdata%7D%28x%29%7D%28D%28x%29+1%29%5E2%5D)
与 WGAN-GP 相比,可以显着提高训练速度和稳定性。 我们还根据经验得出结论,生成的结果具有更高的感知质量和整体更清晰的输出。
作者观察到,对于高度不均匀的模糊图像,尤其是当涉及复杂的物体运动时,“全局”尺度对于鉴别器对于完整的空间信息非常有必要。 为了利用全局和局部特征,使用双尺度鉴别器,由一个局部分支组成,一个分支在batch级别上运行,另一个全局分支提供完整的输入图像。 这样的 DeblurGAN-v2 可以更好地处理更大和更复杂的的真实模糊。
像素空间损失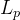 ,例如,最简单的
,例如,最简单的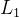 或
或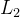 距离,使用往往会产生过度平滑的像素空间输出。使用感知距离,作为“内容”损失
距离,使用往往会产生过度平滑的像素空间输出。使用感知距离,作为“内容”损失 的一种形式。 与相比,它计算 VGG19 conv3_3 特征图上的欧几里得损失。 作者使用混合三项损失来训练 DeblurGAN-v2:
的一种形式。 与相比,它计算 VGG19 conv3_3 特征图上的欧几里得损失。 作者使用混合三项损失来训练 DeblurGAN-v2:

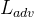 项包含全局和局部鉴别器损失。 此外,选择均方误差 (MSE) 损失作为:尽管 DeblurGAN 不包含项,但是它有助于纠正颜色和纹理失真。
项包含全局和局部鉴别器损失。 此外,选择均方误差 (MSE) 损失作为:尽管 DeblurGAN 不包含项,但是它有助于纠正颜色和纹理失真。
3.4. Training Datasets

GoPro 数据集使用 GoPro Hero 4 相机捕获每秒 240 帧 (fps) 的视频序列,并通过对连续短曝光帧进行平均来生成模糊图像。它是图像运动模糊的常用基准,包含 3,214 个模糊/清晰图像对。我们遵循相同的分割,使用 2,103 对进行训练,其余 1,111 对用于评估。
DVD 数据集收集了由 iPhone 6s、GoPro Hero 4 和 Nexus 5x 等各种设备以 240 fps 捕获的 71 个真实世界视频。然后,作者通过平均连续的短曝光帧来近似更长的曝光,生成了 6708 个合成的模糊和锐利对。该数据集最初用于视频去模糊,但后来也用于图像去模糊领域。
NFS 数据集最初被提议用于对视觉对象跟踪进行基准测试。它由 iPhone 6 和 iPad Pro 的高帧率相机拍摄的 75 个视频组成。此外,从 YouTube 收集了 25 个序列,这些序列以 240 fps 从各种不同的设备捕获。它涵盖了各种场景,包括运动、跳伞、水下、野生动物、路边和室内场景。
训练数据准备:通常,模糊帧是从连续的干净帧中平均而来的。然而,在观察直接平均帧时,我们注意到不切实际的鬼影效果,如图 3(a)(c) 所示。为了缓解这种情况,我们首先使用视频帧插值模型将原始 240-fps 视频增加到 3840 fps,然后在同一时间窗口(但现在有更多帧)执行平均池化(average pooling)。它导致更平滑和更连续的模糊,如图 3(b)(d) 所示。实验上,这种数据准备并没有显着影响 PSNR/SSIM,但观察到可以提高视觉质量结果。
4. Experimental evaluation
4.1. Quantitative Evaluation on GoPro Dataset
我们比较了标准性能指标(PSNR、SSIM)和推理效率(在单个 GPU 上测量的每个图像的平均运行时间)。结果总结在表1中。
在 PSNR/SSIM 方面,DeblurGAN-v2 (InceptionResNet-v2) 和 SRN 排名前 2:DeblurGAN-v2 (Inception-ResNet-v2) 的 PSNR 略低,这并不奇怪,因为它不是在纯 MSE 下训练的损失;但它在 SSIM 中优于 SRN。然而,DeblurGAN-v2 (InceptionResNet-v2) 比 SRN 的推理时间少 78%。此外,两个轻量级模型 DeblurGAN-v2 (MobileNet) 和 DeblurGAN-v2 (MobileNet-DSC) 显示 SSIM(0.925 和 0.922)与另外两个最新的深度去模糊方法 DeblurGAN (0.927) 和 DeepDeblur 相当(0.916),同时速度提高了 100 倍。

特别是,MobileNet-DSC 每张图像的成本仅为 0.04 秒,对于 25 fps 的视频,它甚至可以实现近乎实时的视频帧去模糊。DeblurGAN-v2 (MobileNet-DSC) 是迄今为止唯一可以同时实现(合理)高性能去模糊方法。
4.2. Quantitative Evaluation on Kohler dataset
Kohler 数据集由 4 个图像组成,每个图像用 12 个不同的内核进行模糊处理。它是评估盲去模糊算法的标准基准。该数据集是通过记录和分析真实相机运动生成的,然后在机器人平台上回放,以便记录一系列清晰的图像,对 6D 相机运动轨迹进行采样。

比较结果如表 2 所示。与 GoPro 类似,SRN 和 DeblurGAN-v2 (Inception-ResNetv2) 仍然是最好的两个 PSNR/SSIM 性能,但这次 SRN 在两者中都略胜一筹。但是 DeblurGAN-v2 (Inception-ResNet-v2) 的成本仅为 SRN 推理复杂度的 1/5。此外,DeblurGAN-v2 (MobileNet) 和 DeblurGAN-v2 (MobileNet-DSC) 在 Kohler 数据集上的 SSIM 和 PSNR 都优于 DeblurGAN:鉴于前两者的权重要轻得多,这令人印象深刻。
图 4 显示了 Kohler 数据集上的可视化示例。 DeblurGAN-v2 有效地恢复了边缘和纹理,没有明显的伪影。这个特定示例的 SRN 在放大时显示了一些颜色伪影。

论文原文中还对在DVD dataset,Lai dataset数据集上进行了分析。感兴趣的可以去看看。
4.3. Ablation Study and Analysis
我们对 DeblurGAN-v2 每一部分进行单独研究Ablation Study。从最初的 DeblurGAN(ResNet G、局部尺度补丁 D、WGAN-GP + 感知损失)开始,逐步修改生成器(添加 FPN)、鉴别器(添加全局尺度)和损失(替换 WANGP RaGAN-LS 损失,并添加 MSE 项)。结果总结在表 6 中。我们可以看到,我们提出的所有组件都在稳步提高 PSNR 和 SSIM。特别是,FPN 模块的贡献最为显着。此外,添加 MSE 或感知损失对训练稳定性和最终结果都有好处。

4.4. Extension to General Restoration
真实世界的自然图像通常会同时经历多种退化(噪声、模糊、压缩等),作者还研究了 DeblurGAN-v2 的效果在一般图像恢复任务上。
作者合成了一个新的具有挑战性的恢复数据集。我们从 GoPRO 中拍摄了 600 张图像,从 DVD 中拍摄了 600 张图像,两者都已经带有运动模糊。然后,使用albumentations library进一步向这些图像添加高斯和斑点噪声、JPEG 压缩和放大伪影。最终,拆分了 8000 张图像用于训练,1200 张用于测试。训练并比较 DeblurGAN-v2 (Inception-ResNet-v2)、DeblurGANv2 (MobileNet-DSC) 和 DeblurGAN。如表 6 和图 6 所示,DeblurGAN-v2 (Inception-ResNet-v2) 实现了最佳的 PSNR、SSIM 和视觉质量。


5. Conclusion
本文介绍了 DeblurGAN-v2,这是一种强大而高效的图像去模糊框架,具有良好的定量和定性结果。 DeblurGAN-v2 能够在不同的主干之间切换,以在性能和效率之间进行灵活的权衡。 作者提到有计划将其适用于视频增强领域以更好处理混合降质问题。