import json
import requests
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
def get_url(url):
res=requests.get(url,headers=headers)
json_data=json.loads(res.text)
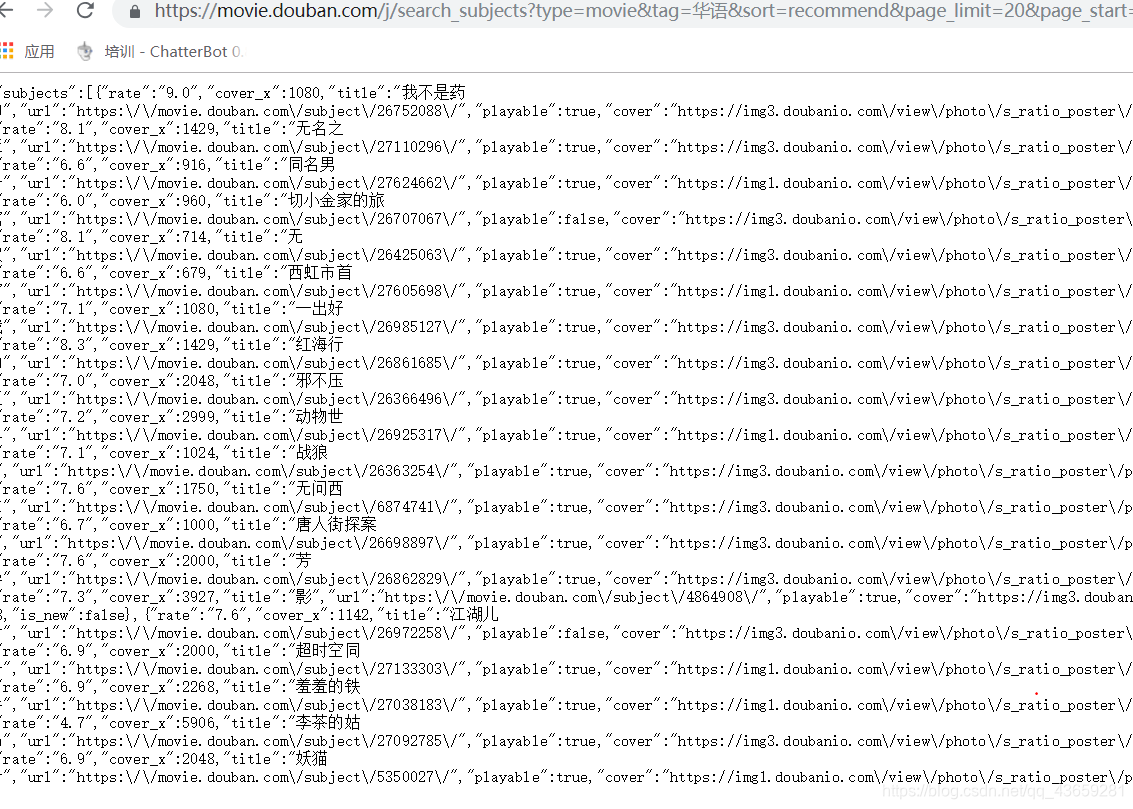
films=json_data.get('subjects')
for film in films:
try:
f.write(film['id']+'\t'+film['rate']+'\t'+film['title']+'\n')
except:
f.write('@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@'+'\n')
print(film['id'])
pass
if __name__=='__main__':
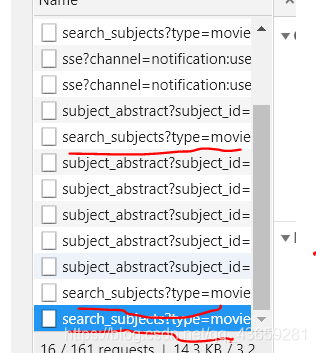
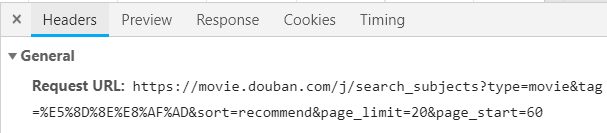
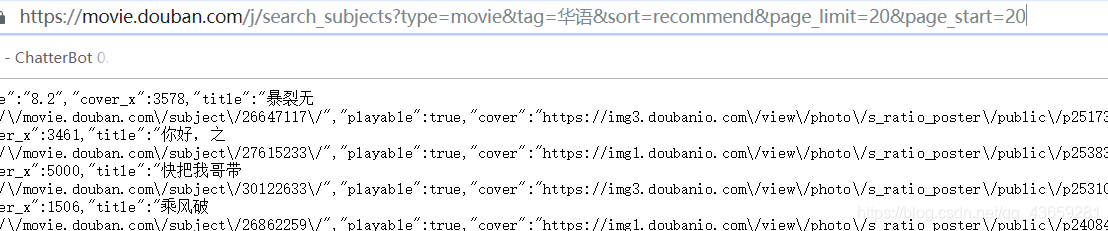
urls=['https://movie.douban.com/j/search_subjects?type=movie&tag=%E6%97%A5%E6%9C%AC&sort=recommend&page_limit=20&page_start={}'.format(str(i)) for i in range(0,220,20)]#在这里我爬取的是日语的电影
f=open('douban.txt','a+')
for url in urls:
get_url(url)
f.close()