第一部分 --- 基础概念


上面这个模型的是一个单向链表

优点:1.链表增加和删除节点的时候不需要进行vector数组那样的增完后进行后移,也不需要删完后前移,当它增加一个节点的时候,只需要将它插入的位置的上一个节点的指针域中的指针指向增加的节点,然后增加的节点指向该位置的下一个节点 --- 这样就增加完毕了
删除就更简单了,将删除位置的上一个节点的指针指向删除位置的下一个节点就完事了
2.当链表要去遍历遍历每一个节点的时候,由于节点都是分散的,访问节点的时候跳转幅度大,消耗时间长,而数组中的元素都是连续排列的,跳转幅度小,时间短
3.链表中的节点不仅要维护数据域还要维护指针域,所以消耗的空间比只要维护数据域的元素要大

1. 上面的这个模型是一个双向链表:它和单向相比具有的特点就是一个节点的指针域中维护着两个指针,第一个指针是prev指针,这个指针指向相对于它所处的节点的上一个节点
第二个指针是next指针,这个指针指向相对于它所处的节点的下一个节点
对于双向链表的第一个节点而言,它的prev指针为Null
对于双向链表的最后一个节点而言,它的next指针为Null
2.我们的STL库中提供的标准链表是一个双向循环链表,它和双向链表的区别是:
对于双向循环链表的第一个节点而言,它的prev指针指向链表的最后一个节点
对于双向循环链表的最后一个节点而言,它的next指针指针链表的第一个接待你
就这样实现了“循环”
链表的迭代器仅支持前移和后移,不支持跳跃访问,这是由链表的数据结构所决定的:
链表中的一个节点最多只能够访问到它的上一个节点和下一个节点(指针域限制),然后就无法访问其它节点了,所以我们无法实现跳转访问
优点:链表是动态存储节点的,是不会出现vector容器那样大容量少于元素的浪费内存空间的现象
这个重要性质是什么意思呢?
1.假设我们让一个迭代器指向节点a,只要节点a不消失,无论链表怎样变动,迭代器指向的内存空间始终不变,我们使用这个迭代器的时候依然能访问到这个节点a --- 迭代器不失效
2.但是当我们让一个迭代器指向vector容器中的一个元素a时,如果发生了容器扩大容量现象的话,迭代器指向的元素的旧数组就会被销毁(旧数组数据拷贝到新数组中),这就意味着迭代器指向的内存空间被释放,此时迭代器相当于一个野指针,我们无法通过它访问到元素a --- 迭代器失效
第二部分 --- 构造函数
1.使用容器前都要包含对应的容器头文件,list容器也不例外 
2.第二个方法的区间是其它容器内的区间
3.elem是我们要传入的数据,数据的类型要和容器的泛型参数类型一致
第三部分 --- 赋值与交换
1.注意这里的赋值操作就相当于将链表原来的节点都删除掉,然后再将赋值过来的新的节点全都存进来
2.交互直接就是两个链表的交换 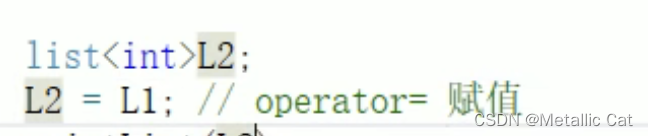
第四部分 --- list大小操作

1.填充的默认值是0,然后我们也可以用重载的方法来自定义用来填充的默认值
第五部分 --- 插入和删除

第六部分 --- 数据存取

1.list链表容器没有下标访问运算符重载(operator[ ])和at方法,只有上面这两个方法
2.对于迭代器a而言,a++不等于 a = a + 1 !!!!(前置++,前后置--同理)
对于迭代器a来说前后置 ++ 意味着访问当前迭代器指向的元素的下一个元素,前后置 -- 意味着访问当前迭代器指向的元素的上一个元素
3.对于能够随机访问的迭代器而言,a++/++a可以等价于a = a + 1 ,且两者的效果都是访问下一个元素,并且最重要的是迭代器还可以+2,+3,+4...等等,这些都意味着访问迭代器指向元素后面的第二个,第三个,第四个元素....
4.但是对于只支持前移和后移的迭代器a而言:1.它们不能够有 a = a +1 , a = a + 2这种操作,比如链表,它的每一个节点的地址都是随机分布的,第一个节点和第二个节点的内存空间的地址可能差很多也可能只差1,如果我们盲目的 a = a+1的话,得到的地址对应的内存空间可能是未分配的空间,这就会导致程序出错
总结:
如果迭代器a不支持随机访问:
则 a = a+1会报错
如果支持随机访问则 a = a + 1不会报错
如果支持后移:a的前后置++不会报错
如果支持前移:a的前后置 -- 不会报错
第七部分 --- list的反转和排序
1.反转就是将头部变为尾部,尾部变为头部 --- 12345 --> 54321 --- reverse(反转 )
2.排序都是按照从小到大的顺序排
3.调用排序算法时要引入标准算法头文件 --- #include <algorithm>
但是!!!我们这里的排序用的不是标准算法头文件中标准排序算法
只有拥有支持随机访问的迭代器的容器才能够使用标准排序算法进行排序
如果容器只拥有不支持随机访问的迭代器的话,这个容器的内部会专门内置一个排序的成员函数,且这个成员函数统一命名为 sort
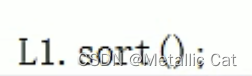
且这个方法的排序顺序是从小到大
那么我们如何从大到小排序呢? --- 这就需要我们向sort方法中传入一个比较规则了
这个比较规则用函数来表示 --- 且这个函数的返回值是bool类型
这个函数有两个参数,这两个参数的类型和容器的泛型参数类型一致
这个比较规则的意思是如果第一个参数大于第二个参数为真,就返回真,否则返回假
将这个比较规则函数的函数名作为参数传给sort方法后,sort方法就会进行从大到小的排序了

其实标准库中的sort排序方法都允许我们自定义其排序规则,那么我们该怎么自定义排序规则呢?
1.创建一个排序规则函数 , 函数的返回值类型是bool,函数有两个参数a和b,参数的类型和我们调用sort方法排序时要比较的元素的类型一致
2.在函数中写我们想要的排序规则,如果是想从大到小排,则函数:
return a > b --- 也就是说只有a > b的时候返回真,a < b则返回假,此时就实现了从大到小
从小到大则是:
return a < b
我们也可以在函数中增加if判断,循环等等实现高级排序规则
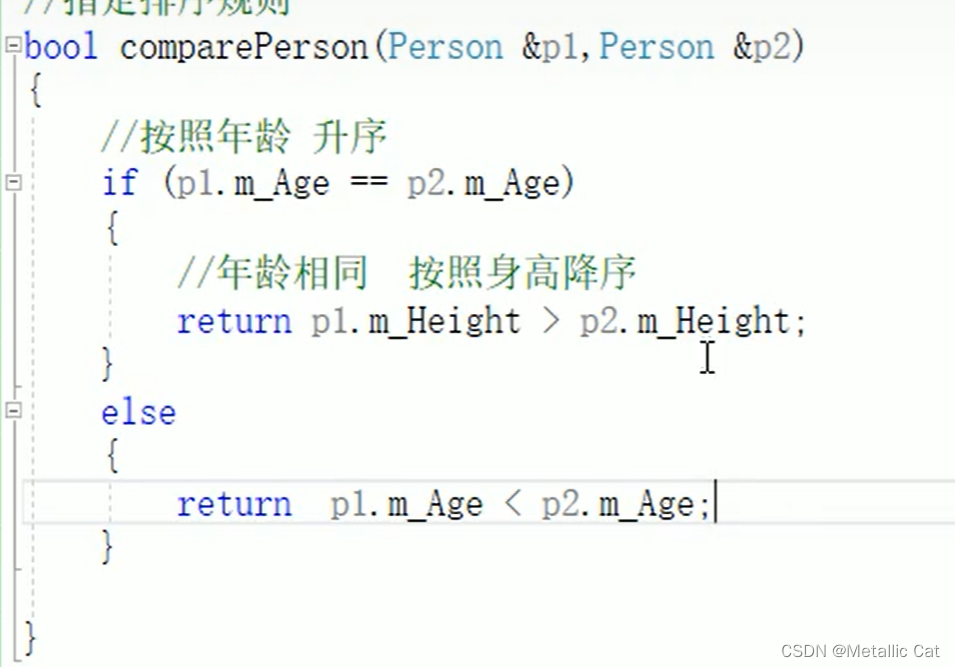
3.将我们创建好的排序规则函数的函数名作为参数传给我们调用的sort方法