目的
虽然比赛时间过去了,但还是可以拿来练一练优化问题的解决,加强自己对于优化算法的巩固。
文章目录
练题。
一、题目

二、思路
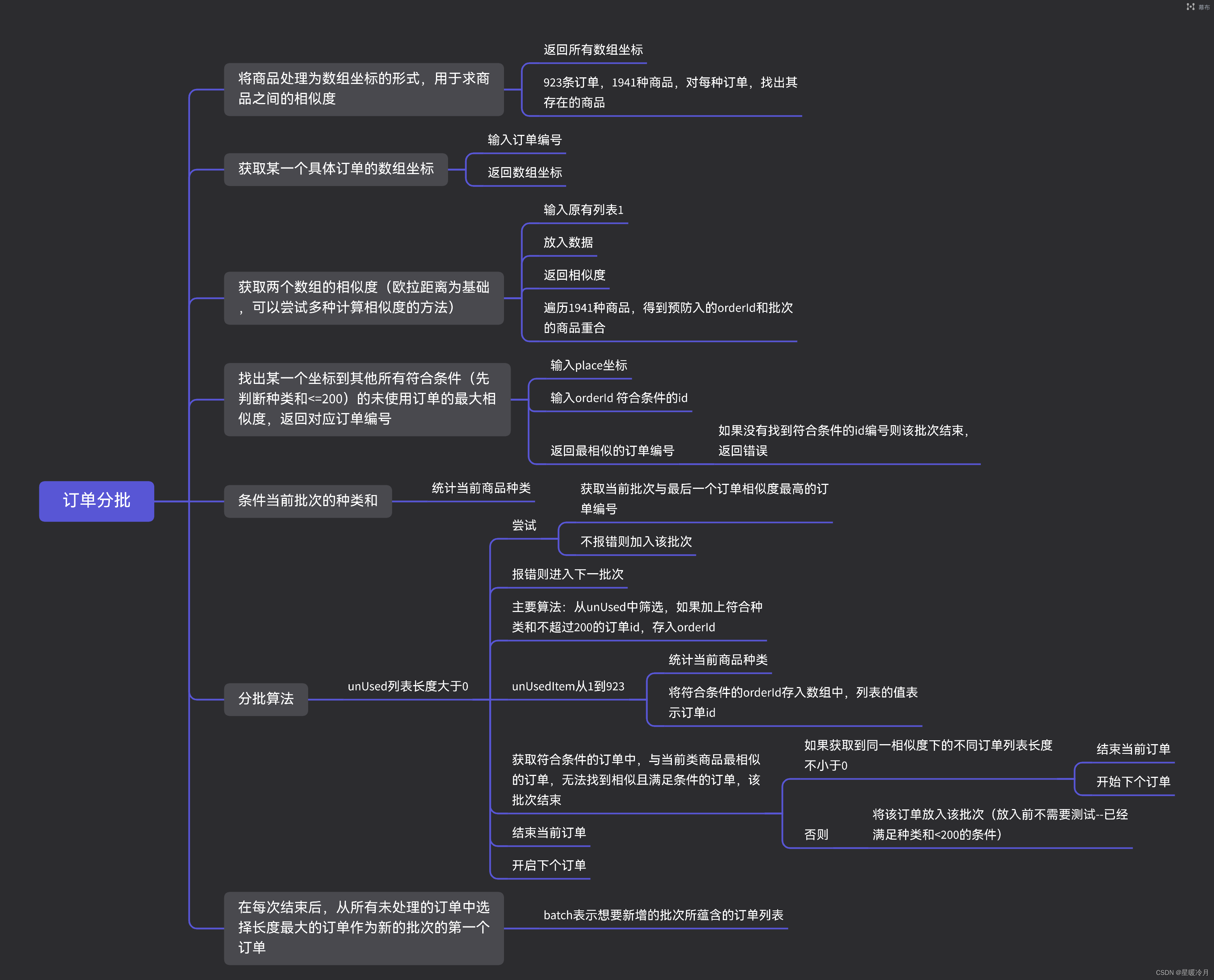
1.第一小题:分批算法
利用订单与订单之间经过去重后的商品种类的的相似度,即重合度,每批初始的第一个订单编号为未使用过订单列表中商品种类最多的订单。
程序思路
三、程序
导入需要的库
import random
import time
import pandas as pd
import math
from collections import Counter
import numpy as np
import os
os.chdir(r'D:\86176\Desktop\6月17日建 订单分拣')
from numba import jit
1.计算相似度的函数
def counter_cosine_similarity(c1, c2):
'''# 计算列表余弦相似度'''
c1 = Counter(c1)
c2 = Counter(c2)
terms = set(c1).union(c2)
dotprod = sum(c1.get(k, 0) * c2.get(k, 0) for k in terms)
magA = math.sqrt(sum(c1.get(k, 0)**2 for k in terms))
magB = math.sqrt(sum(c2.get(k, 0)**2 for k in terms))
return dotprod / (magA * magB)
def counter_euler_distance(x, y):
'''
输入两个等长数组,计算欧拉距离
:param x:
:param y:
:return: 两个数组之间的欧拉距离对应的相似度
'''
return 1 / (1 + np.sqrt(np.sum((x - y) ** 2)))
def two_array_similarity(x, y):
'''
通过识别两个相同长度的数组对应位置是否有值来计算相似度
'''
return np.sum((x > 0) * (y > 0)) / np.sum((y > 0))
2.分批算法主要部分
初始化
data = pd.read_csv('附件1:订单信息.csv')
OrderNo = list(pd.unique(data.loc[:, 'OrderNo']))
ItemNo = list(pd.unique(data.loc[:, 'ItemNo']))
Ot = len(OrderNo) # 订单种类
Gt = len(ItemNo) # 货物种类
N = 200 # 一个批次的最大货品种类数
print("列名:" + ' '.join(data.columns))
print("订单种类:", Ot, "种")
print("货品种类:", Gt, "种")
# Start = time.time()
Order_list = []
Order_nums = []
for i in range(Ot):
Order_list.append(list(data.loc[data['OrderNo'] == OrderNo[i], 'ItemNo']))
Order_nums.append(len(np.unique(Order_list[-1])))
(1)首先生成想要的相似度矩阵
对应函数保存数据
Similars = np.zeros((Ot, Ot))
for i in range(Ot):
for j in range(i + 1, Ot):
Similars[i, j] = counter_cosine_similarity(Order_list[i], Order_list[j])
Similars[j, i] = Similars[i, j]
np.save('Similars', Similars)
商品数据数组化
# 将商品处理为数组坐标的形式,用于求商品之间的相似度
Order_Goods = pd.DataFrame(np.zeros((Ot, Gt)))
Order_Goods.columns = list(pd.unique(data.loc[:, 'ItemNo']))
for i in range(Ot):
for j in Counter(Order_list[i]).items():
Order_Goods.loc[i, j[0]] += j[1]
Order_Goods.index = list(pd.unique(data.loc[:, 'OrderNo']))
欧拉距离为基础的相似度矩阵
Order_Goods_mat = Order_Goods.values
Eu_distance = np.zeros((Ot, Ot))
for i in range(Ot):
for j in range(i + 1, Ot):
Eu_distance[i, j] = counter_euler_distance(Order_Goods_mat[i, :], Order_Goods_mat[j, :])
Eu_distance[j, i] = Eu_distance[i, j]
np.save('Eu_distance', Eu_distance)
for循环加速(其实运行速度还行,就是想试试)
start = time.time()
Order_Goods_mat = Order_Goods.values
simple_similarity = np.zeros((Ot, Ot))
for i in range(Ot):
j_list = set(range(Ot)) - set([i])
for j in j_list:
simple_similarity[i, j] = two_array_similarity(Order_Goods_mat[i, :], Order_Goods_mat[j, :])
print(f"已完成第{i+1}个订单的相似度计算")
np.save('simple_similarity', simple_similarity)
end = time.time()
print("加速前:", end - start)
@jit(parallel=True)
def dump():
for i in range(10):
j_list = set(range(Ot)) - set([i])
for j in j_list:
simple_similarity[i, j] = two_array_similarity(Order_Goods_mat[i, :], Order_Goods_mat[j, :])
print(f"已完成第{i+1}个订单的相似度计算")
start = time.time()
dump()
end = time.time()
print("加速后:", end - start)
(2)主程序(可以将上述求相似度的部分都给注释掉)
所需函数
def Batch_size(path):
'''根据确定好的所有路径计算总批次'''
temp = []
batch = 1
for i in path:
temp.extend(Order_list[i])
temp = list(pd.unique(temp))
if len(temp) > 200:
batch += 1
temp = []
temp.extend(Order_list[i])
return batch
def copy_list(old_list):
'''用来复制列表,是新复制的变量不回改变被赋值的变量'''
new_list = []
for element in old_list:
new_list.append(element)
return new_list
主函数
# 下面两种函数功能一样,是我用来调试的,目的是用来观察while循环里嵌套什么语句较好
def get_best_orderId(orderId_list: [str], unUsed: list) -> str:
'''
找出某个订单对应符合条件的另一个订单Id,条件是:先判断种类和<=200,
再找到未使用订单的与其相似度最高的订单Id
:param orderId_list: 需要配对的订单Id列表
:param unUsed: 未被使用过的订单列表
:return: 订单编号
'''
# orderId = 'D0898'
# Start = time.time()
orderId_list = [OrderNo.index(i) for i in orderId_list]
orderId = orderId_list[-1]
# Eu_distance[OrderNo.index(orderId), 638]
unUsed = [OrderNo.index(i) for i in unUsed]
x = np.sort(Eu_distance[orderId, :])[::-1] # 降序
res = np.argsort(-Eu_distance[orderId, :]) # 降序,返回的结果是排完序后对应原先数组的索引值
for u in np.unique(x)[::-1]:
# flag = 0
idx = x == u
tlist = list(res[idx])
random.shuffle(tlist) # 在与该需要配对订单相似度相同的订单里随机选一个订单
# 求交集:保证所求Id在未被使用的Id列表中
tlist = list(set(tlist) & set(unUsed))
# print(len(tlist))
if len(tlist) == 0:
continue
t_len = []
for t in tlist:
# 先保证两个订单列表之中的货物种类不超过200
order_len = copy_list(orderId_list)
order_len.append(t)
order_len = get_batch_size(order_len)
if order_len <= 200:
t_len.append((t, order_len))
else:
continue
t_len = sorted(t_len, key=lambda x: x[1])
if len(t_len) > 0:
break
# End = time.time()
# print(End - Start)
assert (u != np.unique(x)[::-1][-1]), "遍历全部后找不到符合条件的订单编号"
return OrderNo[t_len[0][0]]
def get_best_orderId1(orderId_list: [str], unUsed: list) -> str:
'''
找出某个订单对应符合条件的另一个订单Id,条件是:先判断种类和<=200,
再找到未使用订单的与其相似度最高的订单Id
:param orderId_list: 需要配对的订单Id列表
:param unUsed: 未被使用过的订单列表
:return: 订单编号
'''
# orderId = 'D0898'
# Start = time.time()
orderId_list = [OrderNo.index(i) for i in orderId_list]
orderId = orderId_list[-1]
# Eu_distance[OrderNo.index(orderId), 638]
unUsed = [OrderNo.index(i) for i in unUsed]
x = np.sort(Eu_distance[orderId, :])[::-1] # 降序
res = np.argsort(-Eu_distance[orderId, :]) # 降序,返回的结果是排完序后对应原先数组的索引值
for u in np.unique(x)[::-1]:
# flag = 0
idx = x == u
tlist = list(res[idx])
random.shuffle(tlist) # 在与该需要配对订单相似度相同的订单里随机选一个订单
# 求交集:保证所求Id在未被使用的Id列表中
tlist = list(set(tlist) & set(unUsed))
# print(len(tlist))
if len(tlist) == 0:
continue
t_len = []
for t in tlist:
# 先保证两个订单列表之中的货物种类不超过200
order_len = copy_list(orderId_list)
order_len.append(t)
order_len = get_batch_size(order_len)
if order_len <= 200:
t_len.append((t, order_len))
else:
continue
t_len = sorted(t_len, key=lambda x: x[1])
if len(t_len) > 0:
break
# End = time.time()
# print(End - Start)
# assert (u != np.unique(x)[::-1][-1]), "遍历全部后找不到符合条件的订单编号"
return OrderNo[t_len[0][0]]
主程序
Eu_distance = np.load('Similars.npy')
# 减少变量
del data, ItemNo, Gt, N
# 数据框内容是每个订单对应的商品种类数
Order_nums = pd.DataFrame({'types': Order_nums})
Order_nums.index = OrderNo
Batches = []
# 防止等下列表变化时,原列表跟着变化
New_OrderNo = copy_list(OrderNo)
max_index = Order_nums.idxmax()[0]
print("最多货品种类的订单是:", max_index)
print(f"有{len(np.unique(Order_list[OrderNo.index(max_index)]))}种订单")
batch = [max_index]
New_OrderNo.remove(batch[-1])
print("开始搜寻……")
print('=' * 50)
print(f"第{len(Batches) + 1}批")
print(f"这批最多货物种类订单是-->{max_index},有{len(np.unique(Order_list[OrderNo.index(max_index)]))}种订单")
order_len = len(pd.unique(Order_list[OrderNo.index(max_index)]))
while len(New_OrderNo) > 0:
try:
# 尝试给当前批次添加新的订单,错误就说明没有符合条件的订单,需要转入下一批次
new_order = get_best_orderId1(batch, New_OrderNo)
batch.append(new_order)
order_len = get_batch_size([OrderNo.index(i) for i in batch])
print(f"{new_order}进入,此时批数种类数为{order_len}")
New_OrderNo.remove(new_order)
except:
Batches.append(batch)
print("进入订单列表:", batch)
print("未被使用订单列表:", New_OrderNo)
print('=' * 50)
print(f"第{len(Batches) + 1}批")
max_index = Order_nums.loc[New_OrderNo, :].idxmax()[0]
print(f"这批最多货物种类订单是-->{max_index},有{len(np.unique(Order_list[OrderNo.index(max_index)]))}种订单")
batch = [max_index]
New_OrderNo.remove(max_index)
Batches.append(batch)
print(len(set(sum(Batches, []))))
path = sum(Batches, [])
path = [OrderNo.index(p) for p in path]
print("总批次:", Batch_size(path))
四、结果
1、第一问
尽力了,57批。

漏了一个函数没给在这:
def get_batch_size(batch_num):
order_len = []
for o in batch_num:
order_len += Order_list[o]
return len(pd.unique(order_len))
总结
待我努力些,搞定后面题!