文章源于工作内网原因只能记录在笔记本,最近打算换个工作环境,整理下资料,简单分个类,也顺便回顾下之前的内容,也相当于做个备份。
回头看看,有些问题现在看有点简单了,但是有些问题好久没有处理也快忘了。有些地方因为是流程图,就不再用绘图软件在画了,直接拍张图片凑合看看吧。
因为基本都是之前不懂的问题,肯定文章有些错误,如有人发现也希望能够指正。
学习路径:
持续集成服务(Continuous Integration,CI):只要有代码变更,就自动运行构建和测试,反馈运行结果。确保符合预期后,再将新代码集成到主干上。



.gitignore文件,列出要忽略的文件模式RT-Druid工具:集成OS oil文件配置,oil代码生成和编译的一个工具,可用于windows下的autosar代码开发的IDE。


RTOS(Real-Time Operating system):
Trampoline是小型的嵌入式系统的RTOS,其API与OSEK/VDK OS和AUTOSAR OS4.2标准保持一致。
Erika Enterorise 是一个开源的OSEK/VDK内核。

内核:

进程调度算法:不同环境的调度算法目标不同,因此需要针对不同环境来讨论调度算法。——参考资料
管程:使用信号量机制实现的生产者消费者问题需要客户端代码做很多控制,而管程把控制的代码独立出来,不仅不容易出错,也使得客户端代码调用更容易。在一个时刻只能由一个进程使用管程。进程在无法继续执行的时候不能一只占用管程,否则其他进程永远不能使用管程。
虚拟:虚拟技术把一个物理实体转换为多个逻辑实体。
虚拟技术:
在电脑内存中,数值是以补码的形式存在的,正数的补码不变,负数的补码是反码再+1(使用补码可以将符号位和数值域同一处理,同时,假发和减法也可以统一处理)
机器数:带符号,比如十进制数-3,计算机字长8位,二进制位10000011。
真值:因为第一位是符号位,所以机器数形式值并不等于真正数值。例如10000011,其最高位1代表负,其真正值为-3,而不是形式值131(1000 0011转换为十进制为131)
注意:按位取反 ≠ 反码,二进制在内存中以补码形式存储,负数以其正值的补码存储。(即 ~9 不等于 9的反码)
下面以计算正数 9 的按位取反为例,计算步骤如下(注:前四位为符号位):
- 原码 : 0000 1001
- 算反码 : 0000 1001 (正数反码同原码)
- 算补码 : 0000 1001 (正数补码同反码)
- 补取反 : 1111 0110 (全位0变1,1变0)
- 算反码 : 1111 0101 (末位减1)
- 算原码 : 1111 1010 (其他位取反)
总结规律: ~x = -(x+1)
计算机频率的产生:——参考文献
晶体振荡器:从一块晶体上按一定的方位角切下薄片(称为"晶片"),在晶片的两个表面上涂覆一层薄薄的银层后接上一对金属板,焊接引脚,并用金属外壳封装,就构成了石英晶体振荡器。
石英晶片之所以能当为振荡器使用,是基于它的压电效应:在晶片的两个极上加一电场,会使晶体产生机械变形;在石英晶片上加上交变电压,晶体就会产生机械振动,同时机械变形振动又会产生交变电场,虽然这种交变电场的电压极其微弱,但其振动频率是十分稳定的。
可是一只石英振荡器只能提供一种频率,所以主板制造商通常将这些原本散布在主机板上各处的振荡电路整合成一颗"频率合成器(Frequency Synthesizer)"芯片,对晶体振荡器产生的脉冲信号进行分频(或倍频),以便为不同运行速度的芯片(或设备)提供所需要的时钟频率。
时间片(timesilce):又称为量子(quantum)或 处理器片(processor slice),是分时操作系统分配给每个正在运行的进程微观上的一段CPU时间(在抢占内核中是从进程开始运行直到被抢占的时间)
时间片由操作系统内核的调度程序分配给每个进程。首先,内核会给每个进程分配相等的初始时间片,然后每个进程轮番地执行相应的时间,当所有进程都处于时间片耗尽的状态时,内核会重新为每个进程计算并分配时间片,如此往复。
为了满足应用和内核自己的需求,内核时间系统必须提供以下三个基本功能:
Linux 是一个通用操作系统,支持不同的硬件体系结构和时钟电路,支持平台的多样性导致时间系统必须包含各种各样的硬件处理和驱动代码。
早期 Linux 的时钟实现采用低精度时钟框架(ms 级别),随着硬件的发展和软件需求的发展,越来越多的呼声是提高时钟精度(ns 级别);经过若干年的努力,人们发现无法在早期低精度时钟体系结构上优雅地扩展高精度时钟。最终,内核采用了两套独立的代码实现,分别对应于高精度和低精度时钟。这使得代码复杂度增加。最后,来自电源管理的需求进一步增加了时间系统的复杂性。Linux 越来越多地被应用到嵌入式设备,对节电的要求增加了。当系统 idle 时,CPU 进入节电模式,此时一成不变的时钟中断将频繁地打断 CPU 的睡眠状态,新的时间系统必须改变以应对这种需求,在系统没有任务执行时,停止时钟中断,直到有任务需要执行时再恢复时钟,也就是低功耗时钟框架的由来。
早期 Linux 考虑两种定时器:内核自身需要的 timer,也叫做动态定时器;其次是来自用户态的需要, 即 setitimer 定时器,也叫做间隔定时器。2.5.63 开始支持 POSIX Timer。2.6.16 引入了高精度 hrtimer。
在 Linux 2.6.16 之前,内核只支持低精度时钟。内核围绕着 tick 时钟来实现所有的时间相关功能。Tick 是一个定期触发的中断,一般由 PIT (Programmable Interrupt Timer) 提供,大概 10ms 触发一次 (100HZ),精度很低。在这个简单体系结构下,内核如何实现三个基本功能? ——IBM <linux内核的工作> 刘明
提供 tick 中断:以 x86 为例,系统初始化时选择一个能够提供定时中断的设备 (比如 Programmable Interrupt Timer, PIT),配置相应的中断处理 IRQ 和相应的处理例程。当硬件设备初始化完成后,便开始定期地产生中断,这便是 tick 了。非常简单明了,需要强调的是 tick 中断是由硬件直接产生的真实中断,这一点在当前的内核实现中会改变,我们在第四部分介绍。
维护系统时间:RTC (Real Time Clock) 有独立的电池供电,始终保存着系统时间。Linux 系统初始化时,读取 RTC,得到当前时间值。
读取 RTC 是一个体系结构相关的操作,对于 x86 机器,定义在 arch\x86\kernel\time.c 中。可以看到最终的实现函数为 mach_get_cmos_time,它直接读取 RTC 的 CMOS 芯片获得当前时间。如前所述,RTC 芯片一般都可以直接通过 IO 操作来读取年月日等时间信息。得到存储在 RTC 中的时间值之后,内核调用 mktime ()将 RTC 值转换为一个距离 Epoch(既 1970 年元旦)的时间值。此后直到下次重新启动,Linux 不会再读取硬件 RTC 了。
虽然内核也可以在每次需要的得到当前时间的时候读取 RTC,但这是一个 IO 调用,性能低下。实际上,在得到了当前时间后,Linux 系统会立即启动 tick 中断。此后,在每次的时钟中断处理函数内,Linux 更新当前的时间值,并保存在全局变量 xtime 内。比如时钟中断的周期为 10ms,那么每次中断产生,就将 xtime 加上 10ms。
当应用程序通过 time 系统调用需要获取当前时间时,内核只需要从内存中读取 xtime 并返回即可。就这样,Linux 内核提供了第二大功能,维护系统时间。
软件定时器:能够提供可编程定时中断的硬件电路都有一个缺点,即同时可以配置的定时器个数有限。但现代 Linux 系统中需要大量的定时器:内核自己需要使用 timer,比如内核驱动的某些操作需要等待一段给定的时间,或者 TCP 网络协议栈代码会需要大量 timer;内核还需要提供系统调用来支持 setitimer 和 POSIX timer。这意味着软件定时器的需求数量将大于硬件能够提供的 timer 个数,内核必须依靠软件 timer。
简单的软件 timer 可以通过 timer 链表来实现。需要添加新 timer 时,只需在一个全局的链表中添加一个新的 Timer 元素。每次 tick 中断来临时,遍历该链表,并触发所有到期的 Timer 即可。但这种做法缺乏可扩展性:当 Timer 的数量增加时,遍历链表的花销将线形增加。如果将链表排序,则 tick 中断中无须遍历列表,只需要查看链表头即可,时间为 O(1),但这又导致创建新的 Timer 的时间复杂度变为 O(n),因为将一个元素插入排序列表的时间复杂度为 O(N)。这些都是可行但扩展性有限的算法。在 Linux 尚未大量被应用到服务器时,系统中的 timer 个数不多,因此这种基于链表的实现还是可行的。
但随着 Linux 开始作为一种服务器操作系统,用来支持网络应用时,需要的 timer 个数剧增。一些 TCP 实现对于每个连接都需要 2 个 Timer,此外多媒体应用也需要 Timer,总之 timer 的个数达到了需要考虑扩展性的程度。
timer 的三个操作:添加 (add_timer)、删除 (del_timer) 以及到期处理(tick 中断)都对 timer 的精度和延迟有巨大影响,timer 的精度和延迟又对应用有巨大影响。例如,add_timer 的延迟太大,那么高速 TCP 网络协议就无法实现。为此,从 Linux2.4 开始,内核通过一种被称为时间轮的算法来保证 add_timer()、del_timer() 以及 expire 处理操作的时间复杂度都为 O(1)。
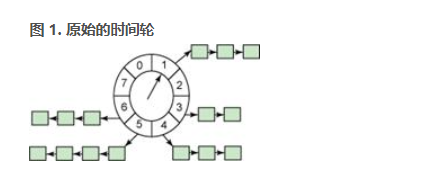
上图中的轮子有 8 个 bucket,每个 bucket 代表未来的一个时间点。我们可以定义每个 bucket 代表一秒,那么 bucket [1] 代表的时间点就是“1 秒钟以后”,bucket [8] 代表的时间点为“8 秒之后”。Bucket 存放着一个 timer 链表,链表中的所有 Timer 将在该 bucket 所代表的时间点触发。中间的指针被称为 cursor。
我们的这个时间轮有一个限制:新 Timer 的到期时间必须在 8 秒之内。这显然不能满足实际需要,在 Linux 系统中,我们可以设置精度为 1 个 jiffy 的定时器,最大的到期时间范围可以达到 (2^32-1/2 ) 个 jiffies(一个很大的值)。如果采用上面这样的时间轮,我们需要很多个 bucket,需要巨大的内存消耗。这显然是不合理的。
为了减少 bucket 的数量,时间轮算法提供了一个扩展算法,即 Hierarchy 时间轮。图 1 里面的轮实际上也可以画成一个数组,

这样的一个分层时间轮有三级,分别表示小时,分钟和秒。在 Hour 数组中,每个 bucket 代表一个小时。采用原始的时间轮,如果我们要表示一天,且 bucket 精度为 1 秒时,我们需要 246060=86,400 个 bucket;而采用分层时间轮,我们只需要 24+60+60=144 个 bucket。
根据其到期值,Timer 被放到不同的 bucket 数组中。比如当前时间为 (hour:11, minute:0, second:0),我们打算添加一个 15 分钟后到期的 Timer,就应添加到 MINUTE ARRAY 的第 15 个 bucket 中。这样的一个操作是 O(m) 的,m 在这里等于 3,即 Hierarchy 的层数。

为了处理 60 秒之外的那些保存在 MINUTES ARRAY 和 HOUR ARRAY中的 Timer,时钟中断处理还需要做一些额外的工作:每当 SECOND ARRAY处理完毕,即 cursor 又回到 0 时,我们应该将 MINUTE ARRAY的当前 cursor 加一,并查看该 cursor 指向的 bucket 是否为空,如果非空,则需要将这些 Timer 移动到前一个 bucket 中。此外 MINUTE ARRAY的 bucket[0] 的 Timer 这时候应该都移动到 SECOND ARRAY 中。同样,当 MINUTE ARRAY 的 cursor 重新回到 0 时,我们还需要对HOUR ARRAY 做类似的处理。这个操作是 O(m) 的,其中 m 是 MINUTE ARRAY 或者 HOUR ARRAY 的 bucket 中时钟的个数。多数情况下 m 远远小于系统中所有 active 的 Timer 个数,但的确,这还是一个费时的操作。
Linux 内核采用的就是 Hierarchy 时间轮算法,Linux 内核中用 jiffies 表示时间而不是时分秒,因此 Linux 没有采用 Hour/Minutes/Second 来分层,而是将 32bit 的 jiffies 值分成了 5 个部分,用来索引五个不同的数组(Linux 术语叫做 Timer Vector,简称 TV),分别表示五个不同范围的未来 jiffies 值。
这个时间轮的精度为 1 个 jiffy,或者说一个 tick。每个时钟中断中,Linux 处理 TV1 的当前 bucket 中的 Timer。当 TV1 处理完(类似 SECOND ARRAY 处理完时),Linux 需要处理 TV2,TV3 等。这个过程叫做 cascades。TV2 当前 bucket 中的时钟需要从链表中读出,重新插入 TV2;TV2->bucket[0] 里面的 timer 都被插入 TV1。这个过程和前面描述的时分秒的时间轮时一样的。cascades 操作会引起不确定的延迟,对于高精度时钟来讲,这还是一个致命的缺点。
时序保护:在RTOS实时操作系统中,时序错误时有发生,即任务或中断在规定时间内未完成。如果只是简单的监测任务或中断未能在截至时间到达前结束,就判定该任务或中断引发的时序错误是不正确的。因为这只是错误被发现的最早时间点,很可能是其他任务或中断在前期阻塞太久而导致的。
为了避免上诉错误,AutoSar提供了时间保护服务,AutoSar OS是支持抢占的固定优先级操作系统任务或中断是否满足截止时间主要由下述3个因素决定:
5. 任务或中断的执行时间
6. 任务或中断由于等待访问被抢占的资源或关中断导致的阻塞时间
7. 任务或中断的间隔达到时间
相应的,AutoSar操作系统引入了三个时间预算,规定了时间上限和最小时间间隔。
传统单片机与部分物联网硬件开发,直接跑裸机代码,主要采用下面两种编程方式:
高并发(high Concurrency):响应时间(response time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数。
内存是现代计算机最重要的组件之一,因此它的内容不能被任何错误的应用篡改,这个功能可以通过MMU(内存管理单元)或者MPU(内存保护单元)来实现。
region为单位的。一个region其实就是一段连续的地址,只是它们的位置和范围都要满足一些限制(对齐方式,最小容量等)。region可以相互交迭,MPU可以根据用户的需气球,设定每个region的访问权限,避免非法的访问。kinetis的MPU使用一个成为region的描述符的寄存器组来定义每个region的访问规则和权限;一个描述符对应一个region,每个region的大小也是可编程的,且多个region是可以叠加的。kinetis最多支持12个region,每个region对应的存储空间最小为32字节,最大为4GB,且必须是32的整数倍。
Cache Memory(CPU缓存)位于CPU与内存之间的临时存储器。
内存怎么控制访问权限?
寄存器与内存模型:CPU本身只负责运算,不负责存储数据,数据一般存储由硬盘外存或IO等介质由总线送入主存中,CPU要用就会走主存读取数据,但CPU处理速度远高于内存的读写速度,为了避免被拖慢,CPU都自带一级/二级缓存。基本上,CPU缓存都可以看作读写速度较快的内存。
但是CPU缓存速度还不够快,另外数据在缓存中的地址是不同的,CPU每次读写都要寻址也会拖慢速度,因此,除了缓存之外,CPU还自带了寄存器,用来存储最常用的数据。也就是说,那些最频繁的数据(比如循环变量)都会放在寄存器里面,CPU优先读写寄存器,再由寄存器更内存交换数据。
但是这也引出一个问题,在多任务时,某个任务修改了某个值,寄存器中却没有更新,被其他任务取出将是个未更新的值。为了避免这个情况,关键字Volatile可以避免这个情况。

内存管理中代码段、数据段、bss段、堆栈段和全局/静态区、常量区、代码区、堆栈区这些概念有什么区别?——参考
区section是编译器生成二进制文件的时候分的,一个二进制文件,分为文件头,代码区,数据区等等,等到执行的时候,被加载进内存,内存管理可以是段式的。你可以理解成二进制文件被加载进内存后,他的区变成了内存的段(segment)。
ELF文件里有若干个section,进程的虚拟地址空间又有若干个segment,其中有些segment(比如text segment和data segment)是由一些section直接复制到内存。段(segment)和区(section)已经是比较好的翻译方式了,像有些资料就一律都叫段,阅读时还得根据上下文自己区分。
- 内存为什么要分段?
内存是随机读写设备,即访问其内部任何一处,不需要从头开始找,只要直接给出其地址便可。如访问内存OxCO0,只要将此地址写入地址总线便可。问题来了,分段是内存访问机制,是给CPU用的访问内存的方式,只有CPU才关注段,那为什么CPU要用段呢,也就是为什么CPU非得将内存分成一段一段的才能访问呢?
说来话长,现实行业中有很多问题都是历史遗留问题,计算机行业也不能例外。分段是从CPU 8086开始的,限于技术和经济,那时候电脑还是非常昂贵的东西,所以CPU和寄存器等宽度都是16位的,并不是像今天这样寄存器已经扩展到64位,当然编译器用的最多的还是32位。16位寄存器意味着其可存储的数字范围是2的16次方,即65536字节,64KB。那时的计算机没有虚拟地址之说,只有物理地址,访问任何存储单元都直接给出物理地址。
编译器在编译程序时,肯定要根据CPU访问内存的规则将代码编译成机器指令,这样编译出来的程序才能在该CPU上运行无误,所以说,在直接以绝对物理地址访问内存的CPU上运行程序,该程序中指令的地址也必须得是绝对物理地址。总之,要想在该硬件上运行,就要遵从该硬件的规则,操作系统和编译器也无一例外。
若加载程序运行,不管其是内核程序,还是用户程序,程序中的地址若都是绝对物理地址,那该程序必须放在内存中固定的地方,于是,两个编译出来地址相同的用户程序还真没法同时运行,只能运行一个。于是伟大的计算机前辈们用分段的方式解决了这一问题,让CPU采用“段基址+段内偏移地址”的方式来访问任意内存。这样的好处是程序可以重定位了,尽管程序指令中给的是绝对物理地址,但终究可以同时运行多个程序了。
所以说,程序分段首先是为了重定位,我说的是首先,下面还有其他理由呢。
偏移地址也要存入寄存器,而那时的寄存器是16位的,也就是一个段最多可以访问到64KB。而那时的内存再小也有1MB,改变段基址,由一个段变为另一个段,就像一个段在内存中飘移,采用这种在内存中来回挪位置的方式可以访问到任意内存位置。所以说,程序分段又是为了将大内存分成可以访问的小段,通过这样变通的方法便能够访问到所有内存了。
但想一想,1M是2的20次方,1MB内存需要20位的地址才能访问到,如何做到用16位寄存器访问20位地址空间呢? 这是因为CPU设计者在地址处理单元中动了手脚,该地址部件接到“段基址+段内偏移地址”的地址后,自动将段基址乘以16,即左移了4位,然后再和16位的段内偏移地址相加,这下地址变成了20位了吧,行
对于在代码中的分段,有的是操作系统做的,有的是程序员自己划分的。如果是在多段模型下编程,我们必然会在源码中定义多个段,然后需要不断地切换段寄存器所指向的段,这样才能访问到不同段中的数据,所以说,在多段模型下的程序分段是程序员人为划分的。如果是在平坦模型下编程,操作系统将整个4GB内存都放在同一个段中,我们就不需要来回切换段寄存器所指向的段。对于代码中是否要分段,这取决于操作系统是否在平坦模型下。
- 代码中为什么分为代码段、数据段? 这和内存访向机制中的段是一回事吗?
首先,程序不是一定要分段才能运行的,分段只是为了使程序更加优美。就像用饭盒装饭菜一样,完全可以将很多菜和米饭混合在一起,或者搅拌成一体,哈哈,但这样可能就没什么胃口啦。如果饭盒中有好多小格子,方便将不同的菜和饭区分存放,这样会让我们胃口大开增加食欲。
程序中的指令都是挨着的,彼此之间无空隙。有同学可能会问,程序中不是有对齐这回事吗?为了对齐,编译器在程序中塞了好多0。是的,对齐确实是让程序中出现了好多空隙,但这些空隙是数据间的空隙,指令间不存在空隙,下一条指令的地址是按照前面指令的尺寸大小排下来的,这就是Intel 处理器的程序计数器cs: eip能够自动获得下一条指令的原理,即将当前eip中的地址加上当前指令机器码的大小便是内存中下一条指令的起始地址。即使指令间有空隙或其他非指令的数据,这也仅仅是在物理上将其断开了。依然可以用jmp指令将非指令部分跳过以保持指令在逻辑上连续。
为了让程序内指令接连不断地执行,要把指令全部排在一起,形成一片连续的指令区域,这就是代码段。这样CPU肯定能接连不断地执行下去。指令是由操作码和操作数组成的,这对于数据也一样,程序运行不仅要有操作码,也得有操作数,操作数就是指程序中的数据。把数据连续地并排在一起存储形成的段落就称为数据段。
data segment //数据段
:
:
data end
stack segment // 栈段
:
:
stack end
code Segment // 代码段
start:
mov ds, ax
mov ax, stack // 将栈数据送入ax寄存器
mov sp, 20H
示例:

现在大伙儿明白为什么CPU能源源不断获取到指令了吧,如前所述,原因首先是指令是连续紧凑的,其次是通过指令机器码能够判断当前指令长度,当前指令地址+当前指令长度=下一条指令地址。
上面给出的例子,其指令在物理上是连续的,其实在CPU眼里,只要指令逻辑上是连续的就可以,没必要一定得是物理上连续。所以,明确一点,即使数据和代码在物理上混在一起,程序也是可以运行的,这并不意味着指令被数据“断开”了。只要程序中有指令能够跨过这些数据就行啦,最典型的就是用jmp跳过数据区。
比如这样的汇编代码:

这几行代码没有实际意义,只是为了解释清楚问题,咱们只要关注在第2行的定义变量var之前为什么要jmp start。如果将上面的汇编代码按纯二进制编译,如果不加第1行的jmp,CPU也许会发出异常,显示无效指令,也许不知道执行到哪里去了。因为CPU 只会执行cs: ip中的指令,这两个寄存器记录的是下一条待执行指令的地址,下一个地址var 处的值为1,显然我们从定义中看出这只是数据,但指令和数据都是二进制数字,CPU 可分不出这是指令,还是数据 保不准某些“数据”误打误撞恰恰是某种指令也说不定。既然var是我们定义的数据,那么必须加上jmp start跳过这个var所占的空间才可以。
加个jmp指令,这样做一点都不影响运行,只不过这样写出来的程序,其中引用的地址大部分是不连续的,也就是程序在取地址时会显得跳来跳去。就美观层面上看,这样的结构显得很凌乱,不利于程序员阅读与维护。如果把第2行的var换到第1行,数据和代码就分开了,没有混在一起,标号都不用了,代码简洁多了,如下。

将数据和代码分开的好处有三点。
例如数据本身是需要修改的,所以数据就需要有可写的属性,不让数据段可写,那程序根本就无法执行啦。程序中的代码是不能被更改的,这样就要求代码段具备只读的属性。真要是在运行过程中程序的下一条指令被修改了,谁知道会产生什么样的灾难。
大伙儿知道,缓存起作用的原因是程序的局部性原理。在 CPU内部也有缓存机制,将程序中的指令和数据分离,这有利于增强程序的局部性。CPU内部有针对数据和针对指令的两种缓存机制,因此,将数据和代码分开存储将使程序运行得更快。
程序中存在一些只读的部分,比如代码,当一个程序的多个副本同时运行时(比如同时执行多个ls命令时),没必要在内存中同时存在多个相同的代码段,这将浪费有限的物理内存资源,只要把这一个代码段共享就可以了。
后两点较容易理解,咱们深入讨论下第一点,不知您有没有想过,数据段或代码段的属性是谁给添加上的呢,是谁又去根据属性保护程序的呢,是程序员吗?是编译器吗?是操作系统吗?还是CPU一级的硬件支持?
首先肯定不是程序员,人家操作系统设计人员为了让程序员编写程序更加容易,肯定不会让他们分心去处理这些与业务逻辑无关的事。看看编译器为我们做了什么,它将程序中那些只读的代码编译出来后,放在一片连续的区域,这个区域叫代码段。将那些已经初始化的数据也放在一片连续的区域,这个区域叫数据段,那些具有全局属性的但又未初始化的数据放在bss 段。总之,程序中段的类型可多了,用“readelf-e elf”命令便可以看到很多段的类型。
接着看操作系统为我们做了什么。
操作系统在让CPU进入保护模式之前,首先要准备好GDT,也就是要设置好GDT的相关项,填写好段描述符。段描述符填写成什么样,段具备什么样的属性,这完全取决于操作系统了,在这里大家只要知道.段描述符中的S字段和TYPE字段负责该段的属性,也就是该属性与安全相关。说到这里,答案似乎浮出水面了。
(1)编译器负责挑选出数据具备的属性,从而根据属性将程序片段分类,比如,划分出了只读属性的代码段和可写属性的数据段。再补充一下,编译器并没有让段具备某种属性,对于代码段,编译器所做的只是将代码归类到一起而已,也就是将程序中的有关代码的多个section合并成一个大的 segment(这就是我们所说的代码段),它并没有为代码段添加额外的信息。
(2)操作系统通过设置GDT全局描述符表来构建段描述符,在段描述符中指定段的位置、大小及属性(包括S字段和TYPE字段)。也就是说,操作系统认为代码应该是只读的,所以给用来指向代码段的那个段描述符设置了只读的属性,这才是真正给段添加属性的地方。
(3)CPU 中的段寄存器提前被操作系统赋予相应的选择子(后面章节会讲什么是选择子,暂时将其理解为相当于段基址),从而确定了指向的段。在执行指令时,会根据该段的属性来判断指令的行为,若有返回则发出异常。
总之,编译器、操作系统、CPU三个配合在一起才能对程序保护,检测出指令中的违规行为。如果GDT中的代码段描述符具备可写的属性,那编译器再怎么划分代码段都没有用,有判断权利的只有CPU。
以上说明了程序按内容分段的原因,那么编译器编译出来的段和内存访问中的段是一回事吗?
其实算一回事,也不算一回事。怎么说呢,我觉得当初Intel公司在设计CPU时,其采用分段机制访问内存的原因,肯定不是为了上层软件的优美,毕竟那只是逻辑上的东西。那为什么也算一回事呢?
分析一下,编译出来的代码段是指一片连续的内存区域。这个段有自己的起始地址,也有自己的大小范围。用户进程中的段,只是为了便于管理,而编译器或程序员在“美学方面”做出的规划,本质上它并不是CPU用于内存访问的段,但它们都是描述了一段内存,而且程序中的段,其起始地址和大小可以理解为CPU访问内存分段策略中的“段基址:段内偏移地址"”,这么说来,至少它们很接近了,让我们更近一步:程序是可以被人为划分成段的,并且可以将划分出来的段地址加载到段寄存器中,见下面的代码。

代码0-1是实模式下运行的程序,其中自定义了三个段,为了和标准的段名(.code、.data等)有所区别,这里代码段取名为my_code,数据段取名为my_data,栈段取名为my_stack。这段代码是由MBR加载到物理内存地址0x900后,mbr通过“jmp 0x900”跳过来的,我们的想法是让各段寄存器左移4位后的段基址与程序中各分段实际内存位置相同,所以对于代码段,希望其基址是0x900,故代码段CS 的值为0x90(在实模式下,由CPU的段部件将其左移4位后变成Ox900,所以要初始化成左移4位前的值)。
但没有办法直接为CS寄存器赋值,所以在代码0-1开头,用jmp O0x90: 0初始化了程序计数器CS和IP。这样段寄存器CS就是程序中咱们自己划分的代码段了。
在此提醒一下,各section中的定义都有align=16和vstart=0,这是用来指定各section 按16位对齐的,各section的起始地址是16的整数倍,即用十六进制表示的话,最后一位是0。所以右移操作如第9行的shr ax,4,结果才是正确的,只是把0移出去了。否则不加 align=16的话,section的地址不能保证是16的整数倍,右移4位可能会丢数据。vstart=0是指定各section内数据或指令的地址以0为起始编号,这样做为段内偏移地址时更方便。具体vstart内容请参阅本书相应章节。
第6~10行是初始化数据段寄存器DS,是用程序中自已划分的段my_data的地址来初始化的。由于代码0-1本身是脱离操作系统的程序,是MBR将其加载到0x900后通过跳转指令mp 0x900跳入执行的,所以要将my_data在文件内的地section.my_data.start加上0x900才是最终在内存中的真实地址。右移4位的原因同代码段相同,都是CPU的段部件会自动将段基址左移4位,故提前右移4位。此地址作为段基址赋值给DS,这样段寄存器DS 中的值是程序中咱们自己划分的数据段了。
第12~17行是初始化栈段寄存器,原理和数据段差不多,唯一区别是栈段初始化多了个针指针SP,为它初始化的值 stack_top是最后一行,因为栈指针在使用过程中指向的地址越来越低,所以初始化时一定得是栈段的最高地址。

我想大家应该已经搞清楚了内存分段和程序分段的关系,其实就是一回事:

对于代码段,编译器所做的只是将代码归类到一起而已,也就是将程序中有关代码的多个section合并成一个大的segment。
注意区分 物理内存的栈 和 代码中的栈

注意啦,如图3-9所示,虽然栈是向下发展的,但栈也是内存,访问内存依然是从低地址往高地址,假如当前栈顶是0x1233E,栈
顶数据占2字节的话,其范围是0x1233E~Ox1233F。
个人觉得,这个硬件中的栈让人感到神秘,主要有两方面原因。
一方面是栈指针不是自己维护,这不像咱们在高级语言中自己创建的栈那样,指针的一举一动都是自己在操作。不直接受控的东西往往让人心存忧虑和有点小恐慌。其实即使是这里的硬件栈,咱们也可以自己维护指针,如 push ax 可以这样代替:

bp默认的段寄存器就是SS,用bp 的时候直接操作的便是栈。bp就相当于栈指针啦,自己维护毕竟太麻烦,有直接省事的干吗不用呢。
另一方面,栈就是一片内存区域,只不过“经常”操作这片内存的指令不是mov,而是push、pop,这两条指令无非是自动维护存取数据的位置(SP寄存器的值)而已,大家用mov来操作这片内存,不是也得要给出存取地址吗。这样看来,它和普通的数据段没什么不同,不要觉得它比金字塔还神秘。

实现方式:一般既可以基于伙伴系统实现,也可以使用链表实现。
那么内存从哪里来呢?两种方式: ——参考文章:malloc和free的实现原理解析
在Linux中进程由进程控制块(PCB)描述,用一个task_struct 数据结构表示,这个数据结构记录了所有进程信息,包括进程状态、进程调度信息、标示符、进程通信相关信息、进程连接信息、时间和定时器、文件系统信息、虚拟内存信息等. 和malloc密切相关的就是虚拟内存信息,定义为struct mm_struct *mm 具体描述进程的地址空间。mm_struct结构是对整个用户空间(进程空间)的描述
///include/linux/sched.h
struct mm_struct {
struct vm_area_struct * mmap; /* 指向虚拟区间(VMA)链表 */
rb_root_t mm_rb; /*指向red_black树*/
struct vm_area_struct * mmap_cache; /* 指向最近找到的虚拟区间*/
pgd_t * pgd; /*指向进程的页目录*/
atomic_t mm_users; /* 用户空间中的有多少用户*/
atomic_t mm_count; /* 对"struct mm_struct"有多少引用*/
int map_count; /* 虚拟区间的个数*/
struct rw_semaphore mmap_sem;
spinlock_t page_table_lock; /* 保护任务页表和 mm->rss */
struct list_head mmlist; /*所有活动(active)mm的链表 */
unsigned long start_code, end_code, start_data, end_data; /* 代码段、数据段 起始地址和结束地址 */
unsigned long start_brk, brk, start_stack; /* 栈区 的起始地址,堆区 起始地址和结束地址 */
unsigned long arg_start, arg_end, env_start, env_end; /*命令行参数 和 环境变量的 起始地址和结束地址*/
unsigned long rss, total_vm, locked_vm;
unsigned long def_flags;
unsigned long cpu_vm_mask;
unsigned long swap_address;
unsigned dumpable:1;
/* Architecture-specific MM context */
mm_context_t context;
};
其中start_brk和brk分别是堆的起始和终止地址,我们使用malloc动态分配的内存就在这之间。start_stack是进程栈的起始地址,栈的大小是在编译时期确定的,在运行时不能改变。而堆的大小由start_brk和brk决定,但是可以使用系统调用sbrk()或brk()增加brk的值,达到增大堆空间的效果,但是系统调用代价太大,涉及到用户态和内核态的相互转换。
所以,实际中系统分配较大的堆空间,进程通过malloc()库函数在堆上进行空间动态分配,堆如果不够用malloc可以进行系统调用,增大brk的值。(malloc只知道start_brk 和brk之间连续可用的内存空间它可用任意分配,如果不够用了就向系统申请增大brk。)
由于brk/sbrk/mmap属于系统调用,如果每次申请内存,都调用这三个函数中的一个,那么每次都要产生系统调用开销(即cpu从用户态切换到内核态的上下文切换,这里要保存用户态数据,等会还要切换回用户态),这是非常影响性能的;
其次,这样申请的内存容易产生碎片,因为堆是从低地址到高地址,如果低地址的内存没有被释放,高地址的内存就不能被回收。鉴于此,malloc采用的是内存池的实现方式,malloc内存池实现方式更类似于STL分配器和memcached的内存池,先申请一大块内存,然后将内存分成不同大小的内存块,然后用户申请内存时,直接从内存池中选择一块相近的内存块即可。
背景:ARM有两个栈指针PSP和MSP,通过Control寄存器来决定SP(R13)使用哪个栈。

当CONTROL[1]=1时,线程模式不再使用MSP,而改用PSP(handler模式永远使用MSP),这样做的好处是,在OS使用环境下,只要OS内核仅在handler模式下运行,用户程序仅在用户模式下运行,这种双堆栈机制排上用场——防止用户程序的堆栈错误破坏OS使用的堆栈

PC寄存器:
1. CS寄存器(Code Segment):存放代码段段基址
2. IP寄存器:存放代码段段内偏移地址
DS寄存器(Data Segment):存放数据段地址
ES寄存器(Extra Segment):附加段地址
SS寄存器(Stack Segment):栈段地址,堆栈段首地址
SP寄存器:堆栈段偏移量
FS、GS附加段寄存器是在32位CPU新增的


SS:SP 指向栈顶元素
在编译器连接过程中分为了两部:
但对于DS、ES、FS、GS这类sreg,CPU中不能之间给它们赋值,没有从立即数到段寄存器的电路实现,只有通过其他寄存器来中转。
读写一个磁盘块的时间的影响因素有:——参考文章
其中,寻道时间最长,因此磁盘调度的主要目标是使磁盘的平均寻道时间最短。

按照磁盘请求的顺序进行调度。优点是公平和简单。缺点也很明显,因为未对寻道做任何优化,使平均寻道时间可能较长。
优先调度与当前磁头所在磁道距离最近的磁道。
虽然平均寻道时间比较低,但是不够公平。如果新到达的磁道请求总是比一个在等待的磁道请求近,那么在等待的磁道请求会一直等待下去,也就是出现饥饿现象。具体来说,两端的磁道请求更容易出现饥饿现象。
 3. 电梯算法(SCAN)
3. 电梯算法(SCAN)
电梯总是保持一个方向运行,直到该方向没有请求为止,然后改变运行方向。
电梯算法(扫描算法)和电梯的运行过程类似,总是按一个方向来进行磁盘调度,直到该方向上没有未完成的磁盘请求,然后改变方向。
因为考虑了移动方向,因此所有的磁盘请求都会被满足,解决了 SSTF 的饥饿问题。

虚拟内存的目的是为了让物理内存扩充成更大的逻辑内存,从而让程序获得更多的可用内存。
为了更好的管理内存,操作系统将内存抽象成地址空间。每个程序拥有自己的地址空间,这个地址空间被分割成多个块,每一块称为一页。这些页被映射到物理内存,但不需要映射到连续的物理内存,也不需要所有页都必须在物理内存中。当程序引用到不在物理内存中的页时,由硬件执行必要的映射,将缺失的部分装入物理内存并重新执行失败的指令。
从上面的描述中可以看出,虚拟内存允许程序不用将地址空间中的每一页都映射到物理内存,也就是说一个程序不需要全部调入内存就可以运行,这使得有限的内存运行大程序成为可能。例如有一台计算机可以产生 16 位地址,那么一个程序的地址空间范围是 0~64K。该计算机只有 32KB 的物理内存,虚拟内存技术允许该计算机运行一个 64K 大小的程序。



一个虚拟地址分成两个部分,一部分存储页面号,一部分存储偏移量。
下图的页表存放着 16 个页,这 16 个页需要用 4 个比特位来进行索引定位。例如对于虚拟地址(0010 000000000100),前 4 位是存储页面号 2,读取表项内容为(110 1),页表项最后一位表示是否存在于内存中,1 表示存在。后 12 位存储偏移量。这个页对应的页框的地址为 (110 000000000100)。

在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
页面置换算法和缓存淘汰策略类似,可以将内存看成磁盘的缓存。在缓存系统中,缓存的大小有限,当有新的缓存到达时,需要淘汰一部分已经存在的缓存,这样才有空间存放新的缓存数据。
页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)。
所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。其是一种理论上的算法,因为无法知道一个页面多长时间不再被访问。
举例:一个系统为某进程分配了三个物理块,并有如下页面引用序列:
7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1
开始运行时,先将 7, 0, 1 三个页面装入内存。当进程要访问页面 2 时,产生缺页中断,会将页面 7 换出,因为页面 7 再次被访问的时间最长。
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU 将最近最久未使用的页面换出。为了实现 LRU,需要在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的。
因为每次访问都需要更新链表,因此这种方式实现的 LRU 代价很高。
4,7,0,7,1,0,1,2,1,2,6
每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置 M=1。其中 R 位会定时被清零。可以将页面分成以下四类:
R=0,M=0
R=0,M=1
R=1,M=0
R=1,M=1
当发生缺页中断时,NRU 算法随机地从类编号最小的非空类中挑选一个页面将它换出。
NRU 优先换出已经被修改的脏页面(R=0,M=1),而不是被频繁使用的干净页面(R=1,M=0)。
选择换出的页面是最先进入的页面。该算法会将那些经常被访问的页面换出,导致缺页率升高。
FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问题,对该算法做一个简单的修改:
当页面被访问 (读或写) 时设置该页面的 R 位为 1。需要替换的时候,检查最老页面的 R 位。如果 R 位是 0,那么这个页面既老又没有被使用,可以立刻置换掉;如果是 1,就将 R 位清 0,并把该页面放到链表的尾端,修改它的装入时间使它就像刚装入的一样,然后继续从链表的头部开始搜索。

时钟(Clock)
第二次机会算法需要在链表中移动页面,降低了效率。时钟算法使用环形链表将页面连接起来,再使用一个指针指向最老的页面。

虚拟内存采用的是分页技术,也就是将地址空间划分成固定大小的页,每一页再与内存进行映射。
下图为一个编译器在编译过程中建立的多个表,有 4 个表是动态增长的,如果使用分页系统的一维地址空间,动态增长的特点会导致覆盖问题的出现。

分段的做法是把每个表分成段,一个段构成一个独立的地址空间。每个段的长度可以不同,并且可以动态增长。

程序的地址空间划分成多个拥有独立地址空间的段,每个段上的地址空间划分成大小相同的页。这样既拥有分段系统的共享和保护,又拥有分页系统的虚拟内存功能。
分页与分段的比较
出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
页表就像一个函数,输入的页号,输出的是页帧,实现从页号到物理地址的映射。操作系统给每一个进程维护一个页表。所以不同进程的虚拟地址可能一样,页表给出了进程中每一页所对应的页帧的位置。
Volatile:用它声明的类型变量表示可以被某些编译器未知因素更改。用它声明的类型变量表示可以被某些编译器未知因素更改。它提醒编译器它后面定义的变量随时可以改变,因此编译后的程序每次需要存储或读取这个变量的时候,告诉编译器对该变量不做优化,都会直接从变量内存地址中读取数据,从而可以提供对特殊地址的稳定访问。
如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的进程更新了的话,将出现不一致的现象。有以下几种情况需要额外注意:
需要注意的是,volatile可以保证可见性和顺序性,不能保证操作的原子性。因为volatile只作用在编译器层面,处理器并不感知volatile的存在与作用。volatile并不是用来解决多线程竞争问题的,而是用来修饰一些因为程序不可控因素导致变化的变量,比如访问底层硬件设备的变量,以提醒编译器不要对该变量的访问擅自进行优化。
i++ 是否是线程安全的(原子操作)?否!因为 i++操作可以分为三步:
用volatile保证原子操作,只是确保了第一步load i一定从存储器中读取数据。无法保障进行三步操作的过程中会不会被其他任务/中断 分离抢占(原子性)。所以使用lock或者Atomic才是唯一正确的选择。(C++11标准中明确指出解决多线程的数据竞争问题应该使用原子操作或者互斥锁。)
原子(ATOM)本意是"不能被进一步分割的最小粒子"。
原子操作(atomic operation) 是不需要synchronized(同步)。所谓原子 操作是指不会被线程调度机制打断的操作。这种操作一旦开始,就一直运行到结束,中间不会有任何context switch(切换到另一个线程),其可能是多个操作,但不可被打断和分割。
Linux原子操作问题来源与中断、进程的抢占以及多核SMP系统中程序的并发执行。对于临界区的操作,可以加锁来保证原子性,对与全局变量或者静态变量的操作则需要依赖硬件平台的原子变量操作。
因此,原子操作有两类:一类是各种临界区的锁,一类是操作原子变量的函数。
对于ARM来说,单汇编指令都是原子的,多核SMP也是,因为有总线仲裁,所以CPU可以单独占用总线直到指令结束。
多核系统中的原子操作通常使用内存屏障(memory barrirer)来实现。即一个CPU核在执行原子操作时,其他CPU核必须停止对内存操作或者不对指定的内存进行操作。这样才能避免数据竞争问题。 但是对于load update store这个过程可能被中断、抢占,所以ARM指令集有增加了Idrex / Strex 操作实现 load update store 的原子操作。
Load-Link(LL)和Store-Conditional(SC)的操作,通常简称为LL/SC。LL操作返回一个内存地址上当前存储的值,后面的SC操作,会向这个内存地址写入一个新值,但是只有在这个内存地址上存储的值,从上个LL操作开始直到现在都没有发生改变的情况下,写入操作才能成功,否则都会失败。这个操作非常重要,是很多平台实现基本原子操作的基础。对于ARM平台来说,也在硬件层面上提供了对LL/SC的支持,LL操作用的是LDREX指令,SC操作用的是STREX指令。 - 参考文章
但是Linux对于C/C++程序(一条C语言可能被编译成多条汇编),由于上诉提到的原因,不能保证原子性,因此Linux提供了一套函数来操作全局变量或静态变量。
而在其他平台,我们比较常用的两个常用的方法:TAS(test and set)和CAS (compare and swap)。
很多语言都提供了封装后的TAS和CAS调用方法。
以C++ 11为例,atomic标准库提供了相关方法:
std::atomic_flag::test_and_set和std::atomic::compare_exchange_strong
GCC编译器也内置了相关方法:
__atomic_test_and_set和__atomic_compare_exchange_n.
Java也提供了例如:
java.util.concurrent.atomic.AtomicReference.compareAndSet等方法。
由于处理器优化和指令重排等,CPU还可能对输入代码进行乱序执行,比如load->add->save 有可能被优化成load->save->add 。这就是可能存在有序性问题。
static volatile int a = 0;
static volatile int b = 0;
void func1()
{
a = 10;
b = 11;
}
void func2()
{
if(b == 11)
{
int c = a;
}
}
func1与func2分别再线程1与线程2执行,由于CPU优化后(volatile只能阻止编译器优化顺序)func1里的b可能先赋值,func2的判断条件满足时,a的值可能为0。从而导致执行结果与我们预期的不一致。
内存屏障其实就是一个CPU指令,在硬件层面上来说可以分为两种:Load Barrier 和 Store Barrier即读屏障和写屏障。主要有两个作用:

synchronized是Java提供的一个并发控制的关键字。主要有两种用法,分别是同步方法和同步代码块。被synchronized修饰的代码块及方法,在同一时间,只能被单个线程访问。Synchronized同时保证了线程的原子性、可见性、有序性。
软件架构(体系结构)就是一个设计方案将用户的不同需求抽象成抽象件,并且能够描述这些抽象组件之间的同行和调用。
复杂指令集计算机CISC(Complex Instruction Set Computer)(早期):用最少的机器语言指令来完成所需的计算任务(依赖大量CPU中设计的逻辑)。这种架构会增加CPU结构的复杂性和对CPU工艺的要求,但对于编译器的开发十分有利。目前只有Intel及其兼容CPU还在使用CISC架构。 ——参考文献
精简指令集计算机RISC:针对流水线化的处理器优化,设计思路是一条指令完成一个基本“动作”,多条指令组合完成一个复杂的基本功能。
框架:框架不是架构,框架比架构更具体,更偏向技术,而架构偏向设计,架构可以通过多种框架实现。
框架可以说是一个半成品的应用,其具有针对性,内部元素之间紧密程序远远大于类库元素之间关系。




BSW架构:
服务层被分为三部分:
ECU抽象层被分为四部分:I/O硬件抽象层,通行硬件抽象层,内层硬件抽象层,车载设备抽象层。
微控制层抽象层被分为四部分:I/O驱动、通信驱动、内存驱动、微处理驱动。
Linux文件系统

什么是微服务架构? ——参考文章
Linux 下内存检测工具:asan
linux 暂停继续进程
通常,一个任务是一个程序的一次执行,一个任务包含一个或多个完成独立功能的子任务,这个独立的子任务就是进程或线程。
Linux 2.6 开发人员为了提高对交互程序的调度性能映入了新的进程调度算法,其中最著名的是“反转楼梯最后期限调度算法(RSDL)”,该算法吸取了队列理论,将公平调度的概念引入了Linux调度程序,并在最终的2.6.23内核版本提单了O(1)调度算法,它此刻被称为CFS(完全公平调度算法)。
《Linux内核设计与实现——第4章.进程调度》
文件描述符(file descriptor)在形式上是一个非负数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。
系统为维护文件描述符,建立了三个表:进程级的文件描述符,系统级的文件描述符,文件系统的i-node表(软硬连接)
每个文件描述符会与一个打开文件相对应,同时,不同的文件描述符也会指向同一个文件,相同的文件可以被不同进程打开也可以在同一进程中被多次打开。系统为每一个进程维护了一个文件描述符表,该表的值都是从0开始的,所以在不同的进程中你会看到相同的文件描述符,这种情况下相同文件描述符有可能指向同一个文件,也有可能指向不同的文件。
内核抢占:


进程是指一个具有独立功能的程序在某个数据集上的一次动态执行过程,它是系统进行资源分配和调度的基本单位,一次任务的允许可以并发激活多个进程,这些进程相互合作来完成该任务的一个最终目标。
进程不但包括程序的指令和数据,而且包括程序计数器的所有寄存器以及存储临时数据的进程堆栈。因此,正在执行的进程包括处理器当前的一切活动。
内核调度的对象是线程,而不是进程。Linux系统中的线程很特别,它对线程和进程并不做区分。进程的另一个名字叫任务(task)。有一种不成文的习惯,把用户空间允许的程序叫进程,把内核中允许的程序叫任务。
内核将所有进程存放在双向循环链表(进程链表/任务队列)中,其中链表头是init_task描述符,链表的每一项都是类型为task_struct的进程描述符的结构,该结构包含了一个进程相关的所有信息,定义在<include/linux/sched.h>头文件中。其中包含了status和pid等域。
Linux 通过slab分配器分配task_struct结构,这样能达到对象复用和缓存着色的目的。在2.6以前的内核中,各个进程的task_struct存放在它们内核栈的尾端。由于现在用slab分配器动态生成task_struct,所以只需在栈底或栈顶创建一个新的结构(struct thread_info),他在asm/thread_info.h中定义,需要的请具体参考。每个任务中的thread_info结构在它的内核栈中的尾端分配,结构中task域存放的是指向该任务实际task_struct指针。 ——参考文章
在内核中,访问任务通常需要获得指向其task_struct指针。实际上,内核中大部分处理进程的代码都是通过task_struct进行的。通过current宏查找到当前正在执行的进程的进程描述符就显得尤为重要。在x86系统上,current把栈指针的后13个有效位屏蔽掉,用来计算thread_info的偏移,该操作通过current_thread_info函数完成,汇编代码如下:
movl $-8192, %eax
andl %esp, %eax
最后,current再从thread_info的task域中提取并返回task_struct的值:current_thread_info()->task

每个进程都拥有自己的数据段、代码段、堆栈,这就造成了进程在切换等动作是需要较复杂的上下文切换动作。为了减少处理机的空闲时间,支持多处理器及减少上下文切换的开销,进程在演化中出现了另一种概念,也就是线程。
线程可以对进程的内存空间和资源分配进行访问,并与同一进程中其他线程共享。因此线程的上下文切换开销比创建进程小得多。
由于线程共享了进程的资源和地址空间,因此任何线程对系统资源的操作都会给其他进程带来影响,因此多线程的同步是一个非常重要的问题。
Linux采取虚拟内存管理技术,使得每个进程都有各自不干涉的进程地址空间。该地址空间是大小为4GB的线性虚拟空间。
4GB的进程空间会被分为两部分:用户空间和内核空间。用户地址空间是从0到3GB(0XC000 0000),内核地址空间占据3GB到4GB。用户进程通常情况下只能访问用户空间的虚拟地址,不能访问内核空间的虚拟地址。
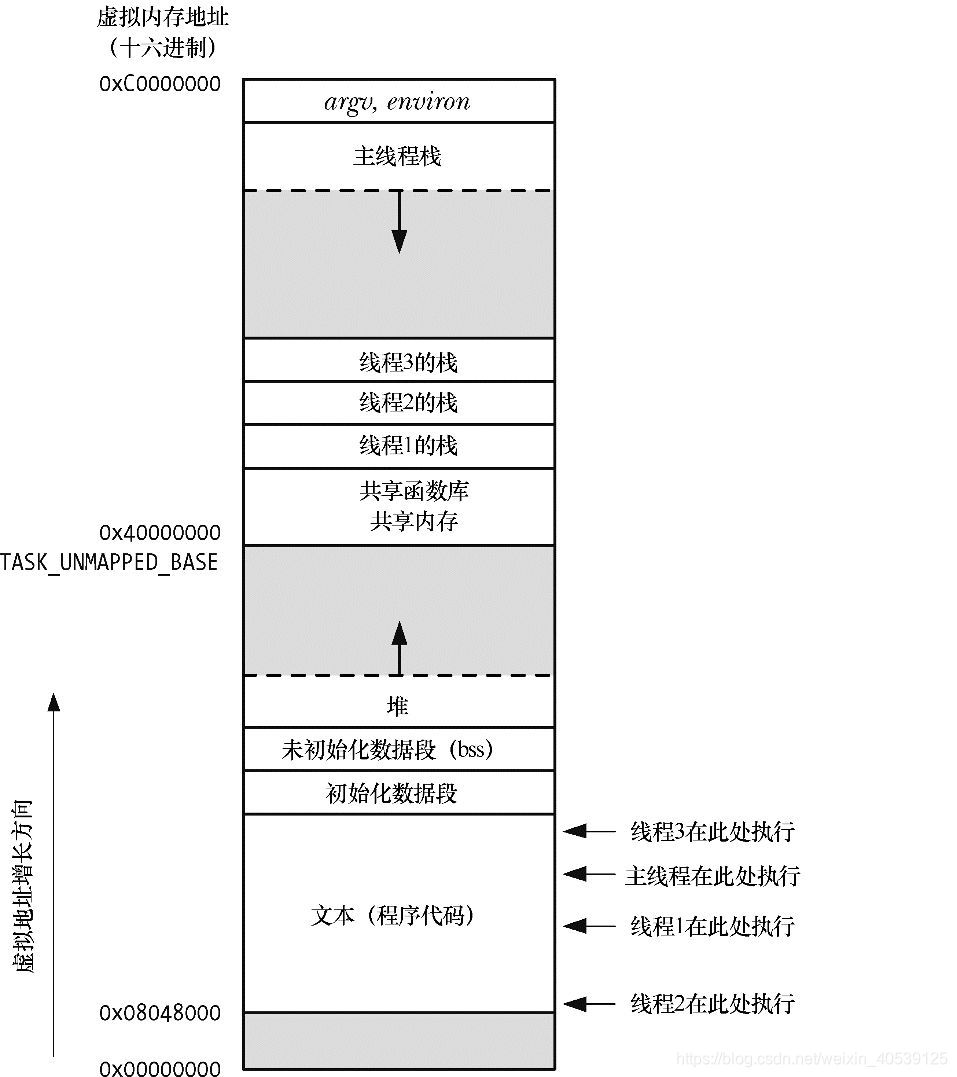
图29-1:同时执行4个线程的进程(Linux/x86-32)
图29-1其实做了一些简化。特别是,线程栈(thread stack)的位置可能会与共享库和共享内存区域混杂在一起,这取决于创建线程、加载共享库,以及映射共享内存的具体顺序。而且,对于不同的Linux发行版,线程栈地址也会有所不同。
线程解决了上述两个问题。
除了全局内存之外,线程还共享了一干其他属性(这些属性对于进程而言是全局性的,而并非针对某个特定线程),包括以下内容:
各线程所独有的属性,如下列出了其中一部分。
如图29-1 所示,所有的线程栈均驻留于同一虚拟地址空间。这也意味着,利用一个合适的指针,各线程可以在对方栈中相互共享数据。这种方法偶尔也能派上用场,但由于局部变量的状态有效与否依赖于其所驻留栈帧的生命周期,故而需要在编程中谨慎处理这一问题。(当函数返回时,该函数栈帧所占用的内存区域有可能为后续的函数调用所重新使用。如果线程终止,那么新线程有可能会对已终止线程的栈所占用的内存空间重新加以利用)。若无法正确处理这一依赖关系,由此而产生的程序bug将难以捕获。——参考文章
由于在Linux系统每一个进程都会有/proc文件系统下与之对应的一个目录,因此通过/proc文件系统可以查看某个进程的地址空间的映射情况。例如运行一个应用程序,如果它的PID为13707,输入 cat /proc/13707/maps命令,可以查看该进程的内存映射情况。
对于连续(joinable)和 分离(detached)最重要的规则:
一直以来,Linux内核并没有严格区分线程进程的概念,每一个执行实体都是一个task_struct结构,一般称之为进程。通过系统调用clone创建子进程时,可以有选择的让子进程共享父进程所引用的资源。这样的子进程通常称为轻量级进程(lightweight process)。
Linux上的线程就是基于轻量级进程,由用户态的pthread库实现的。 使用pthread以后,在用户看来,每一个task_struct就对应一个线程,而一组线程及它们共同引用的一组资源就是一个进程。 ——参考文章
每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间(可通过task_struct 中的stack变量访问)。当进程在用户空间运行时,CPU堆栈指针寄存器里面的内容是用户堆栈地址;当进程在内核空间时,CPU堆栈指针寄存器里的内容是内核栈空间地址,使用内核栈。
当进程通过系统调用、或是发生中断异常陷入内核态时,进程使用的堆栈也要从用户栈转到内核栈。进程陷入内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;
当进程从内核态恢复到用户态之行时,在内核态之行的最后将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈和用户栈的互转。
在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为,当进程在用户态运行时,使用的是用户栈。当进程陷入到内核态时,内核栈保存进程在内核态运行的相关信息,但是一旦进程返回到用户态后,内核栈中保存的信息无效,会全部恢复,因此每次进程从用户态陷入内核的时候得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以。
所有进程的祖先叫做进程0idle进程,也称为init_task,因为其task_struct类型变量名字叫做init_task),在系统初始化阶段由start_kernel()函数从无到有手工创建的一个内核线程。0号进程一直处于“内核态”。
idle进程的工作(运行逻辑):
进程1又称为init进程,是所有用户进程的祖先。
由进程0在start_kernel调用rest_init,然后在rest_init中调用kernel_thread函数创建。init进程PID为1,当调度程序选择到init进程时,init进程开始执行kernel_init ()函数
init是个普通的用户态进程,它是Unix系统内核初始化与用户态初始化的接合点,它是所有用户进程的祖宗。在运行init以前是内核态初始化,该过程(内核初始化)的最后一个动作就是运行/sbin/init可执行文件。
init 进程的工作(运行逻辑):
Linux中进程状态:
进程的创建和执行:Linux中进程的创建很特别,它分成了两个单独函数去执行,fork函数 和 exec函数族。
fork()通过拷贝当前进程创建一个子进程。使用fork()函数得到的子进程是父进程的一个复制品,它从父进程继承了整个进程的地址空间,包括进程上下文、代码段、进程堆栈、内存星系、打开的文件描述符、进程优先级、组号、当前工作目录等。子进程与父进程的区别仅仅在与PID(每个进程唯一)、PPID(父进程的进程号,子进程将其设置为被拷贝进程的PID)和某些资源和统计量(例如,挂起的信号,它没有必要被继承)。exec()负责读取可执行文件并将其载入地址空间开始运行。把这两个函数合起来使用的效果跟其他系统使用的单一函数的效果相似。现在的Linux操作系统采用了copy-on-write技术(COW),即:如果父进程和子进程中任意一个尝试修改某些区域的值,那么内核会为修改区域的那部分内存制作一个副本,一般都是虚拟内存的一页。否则不进行复制操作,比如在fork的子进程中只是调用exec函数来执行另外一个可执行文件,那么事实上就没有必要复制父进程的资源,这样会造成大量的开销浪费。
wait()函数用于使父进程(也就是调用wait()的进程)阻塞,直到一个子进程结束或者该进程收到了一个指定的信号为止。如果该父进程没有子进程,或者它的子进程已经结束,则wait()函数就会立即返回。
waitpid()的作用和wait()一样,但它并不一定要等待第一个终止的子进程(它可以指定需要哦等待终止的子进程),它还有若干选项,如可提供一个非阻塞版本的wait()功能,也能支持作业控制。实际上,wait()函数只是 waitpid()函数的一个特例,在Linux 内部实现 wait()函数时直接调用的就是waitpid()函数。

进程的终止:linux首先把终止的进程设置为僵尸状态,这是进程无法投入运行,它的存在只为父进程提供信息,申请死亡。父进程得到消息后,开始调用wait函数族,最后终止了子进程,子进程占用的资源被全部释放。

优先级反转:


守护进程(Daemon进程),是Linux中的后台服务进程。它是一个生存期较长的进程,通常独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。守护进程常常在系统引导装入时启动,在系统关闭时终止。Linux系统有很多守护进程,大多数服务都是通过守护进程实现的,同时,守护进程还能完成许多系统任务,例如,作业规划进程crond、打印进程lqd等(这里的结尾字母d就是Daemon的意思)。
由于在Linux中, 每一个系统与用户进行交流的界面称为终端,每一个从此终端开始运行的进程都会依附于这个终端,这个终端就称为这些进程的控制终端,当控制终端被关闭时,相 应的进程都会自动关闭。但是守护进程却能够突破这种限制,它从被执行开始运转,直到整个系统关闭时才退出。如果想让某个进程不因为用户或终端或其他地变化 而受到影响,那么就必须把这个进程变成一个守护进程。
孤儿进程:父进程在子进程前面结束,子进程将失去父亲成为一个孤儿进程,被托孤给Init进程(PID=1),很多应用利用这点创建守护进程。
编写守护进程步骤:



多线程是为了同步完成多项任务,不是为了提高数据处理效率,而是为了提高资源使用率达到提高系统的效率。

主线程和子线程的默认关系是:无论子线程执行完毕与否,一旦主线程执行完毕退出,所有子线程执行都会终止。这时整个进程结束或僵死,部分线程保持一种终止执行但还未销毁的状态,而进程必须在其所有线程销毁后销毁,这时进程处于僵死状态。(怎么防止这种内存泄漏情况,要么在你创建的线程退出时让系统回收资源detached,要么自己主动回收joined)
线程函数执行完毕退出,或以其他非常方式终止,线程进入终止态,但是为线程分配的系统资源不一定释放,可能在系统重启之前,一直都不能释放,终止态的线程,仍旧作为一个线程实体存在于操作系统中,什么时候销毁,取决于线程属性。通常,这种终结方式并非我们期待的结果。而且一个潜在的问题是未执行也不一定释放完就终止的子线程,除了作为线程实体占用的资源外,其线程函数占用的资源(动态内存,网络端口)。
在这种情况下,主线程和子线程通常定义以下两种关系:
可会合(joinable):这种关系下,主线程需要明确执行等待操作,在子线程结束后,主线程的等待操作执行完毕,子线程和主线程会合,这时主线程继续执行等待操作之后的下一步操作。(当使用join方式时,会阻当前代码等待线程完成退出后,才会继续向下执行)主线程必须会合可会合的子线程。在主线程的线程函数内部调用子线程对象的wait函数实现,即使子线程能够在主线程之前执行完毕,进入终止态,也必须执行会合操作,否则,系统永远不会主动销毁线程,分配给该线程的系统资源也永远不会释放。
相分离(detached):表示子线程无需和主线程会合,也就是相分离的,这种情况下,子线程一旦进入终止状态,这种方式常用在线程数较多的情况下,有时让主线程逐个等待子线程结束,或者让主线程安排每个子线程结束的等待顺序,是很困难或不可能的,所以在并发子线程较多的情况下,这种方式也会经常使用。
在任何一个时间点上,线程是可结合(joinable)或者是可分离的(detached),一个可结合的线程能够被其他线程回收资源和杀死,在被其他线程回收之前,它的存储器资源如栈,是不释放的,相反,一个分离的线程是不能被其他线程回收或杀死的,它的存储器资源在它终止时由系统自动释放。
超线程(Hyper-Threading,简称“HT”)技术,其利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能使用线程级并行计算。
超线程技术就是在一颗CPU同时执行多个程序而共同分享一颗CPU内的资源,理论上要像两颗CPU一样在同一时间执行两个线程,虽然采用超线程技术同时执行两个线程,但它并不像两个真正的CPU那样,每个CPU都有独立资源。当两个线程都同时需要某一个资源时,其中一个要暂停使用,让出资源,直到资源闲置后继续。

pthread_create()。在线程创建后,就开始运行相关的线程函数。pthread_exit(),这是线程的主动行为。这里要注意的是,在使用线程函数时,不能随意使用exit()退出函数来进行出错处理。由于exit()的作用是使调用进程终止,而一个进程往往包含多个线程,因此,在使用exit()之后,该进程中的所有线程都终止了。在线程中就可以使用pthread_exit()来代替进程中的exit()。wait()系统调用来同步终止并释放资源一样,线程之间也有类似机制,那就是pthread_join()函数。pthread_join()用于将当前进程挂起来等待线程的结束。这个函数是一个线程阻塞的函数,调用它的函数将一直等待到被等待的线程结束为止,当函数返回时,被等待线程的资源就被收回。pthread_exit()函数主动终止自身线程,但是在很多线程应用中,经常会遇到在别的线程中要终止另一个线程的问题,此时调用pthread_cancel()函数来实现这种功能,但在被取消的线程的内部需要调用pthread_setcancel()函数和pthread_setcanceltype()函数设置自己的取消状态。例如,被取消的线程接收到另一个线程的取消请求之后,是接受函数忽略这个请求;如果是接受,则再判断立刻采取终止操作还是等待某个函数的调用等。pthread_exit()或者从线程函数中return都将使线程正常退出,这是可预见的退出方式;非正常终止是线程在其它线程的干预下,或者由于自身运行出错(比如访问非法地址)而退出,这种退出方式是不可预见的。不论是可预见的线程终止还是异常终止,都回存在资源释放的问题,如何保证线程终止时能顺利地释放掉自己所占用的资源,是一个必须考虑的问题。pthread_cleanup_push()的调用点到pthread_cleanup_pop()之间的程序段中的终止动作(包括调用pthread_exit()和异常终止,不包括return)都将执行pthread_cleanup_push()所指定的清理函数。注:线程的执行顺序和代码顺序是无关的。
粒度:

临界资源是同一时刻只允许有限个(通常只有一个)进程可以访问(读)或修改(写)的资源。通常包括硬件资源(处理器、内存、存储器以及其他外设等)和软件资源(共享代码段、共享结构和变量等)。访问临界资源的代码叫做临界区,临界区本身也称为临界资源。
在linux系统,使用信号量来控制临界资源访问:
semget()函数),不同进程通过使用同一个信号量的键值来获得同一个信号量。semctl()函数的SETVAL操作。当使用二维码信号量时,通常将信号量初始化为1。semop()函数,这一步是实现进程间的同步和互斥的核心工作部分。semctl()函数的IPC_RMID操作。需要注意的是,在程序中不应该出现对已经删除的信号量的操作。{
// 设R为某种资源,S为资源R的信号量
INIT_VAL(S); // 信号量S初始化
非临界区;
P(S); //进行P操作,信号量减一
临界区(资源R); // 只有有限个(通常只有一个)进程被允许进入该区
V(S); // 进行V操作,信号量加一
非临界区:
}
当我们把S的初始值设为1,当线程A第一个调用P(S)后,S值就变成了0,A成功进入临界区,在A退出临界区之前,线程B如果调用P(S),S就会变为-1,满足S<0的判断条件,线程B就被阻塞了。等A调用V(S)后,S值又变成0,满足S<=0,就会把线程B唤醒,B就能进入临界区了。
自旋锁(spin lock)与互斥锁(mutex)类似,也是独占锁,也就是任意时刻只有一个线程能够获得锁。当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取,直到获取到锁才会退出循环。
在获取锁的过程中,线程一直处于活跃状态。因此与mutex不同,spinlock不会导致线程的状态切换(用户态->内核态),一直处于用户态,即线程一直都是active的;不会使线程进入阻塞状态,减少了不必要的上下文切换,执行速度快。
由于自旋时不释放CPU,如果持有自旋锁的线程一直不释放自旋锁,那么等待该自旋锁的线程会一直浪费CPU时间。因此,自旋锁主要适用于被持有时间短,线程不希望在重新调度上花过多时间的情况。
自适应自旋锁:如果在同一对象上锁,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行,那么虚拟机(JVM)就会认为这次自旋也很有可能再次成功,进而它将运行自旋等待持续更长的时间,比如100个循环。相反的,如果对于某个锁,自旋很少成功获得过,那再以后要获得这个锁时可能减少自旋时间甚至省略自旋过程,以免浪费处理器资源。
自旋锁的目标是降低线程切换的成本。如果锁竞争激烈,我们不得不依赖于重量级锁,让竞争失败的线程阻塞;如果完全没有实际的锁竞争,那么申请重量级锁都是浪费的。轻量级锁的目标是,减少无实际竞争情况下,使用重量级锁产生的性能消耗,包括系统调用引起的内核态与用户态切换、线程阻塞造成的线程切换等。——参考资料
顾名思义,轻量级锁是相对于重量级锁而言的。使用轻量级锁时,不需要申请互斥量,仅仅将Mark Word中的部分字节CAS更新指向线程栈中的Lock Record,如果更新成功,则轻量级锁获取成功,记录锁状态为轻量级锁;否则,说明已经有线程获得了轻量级锁,目前发生了锁竞争(不适合继续使用轻量级锁),接下来膨胀为重量级锁。
Mark Word是对象头的一部分;每个线程都拥有自己的线程栈(虚拟机栈),记录线程和函数调用的基本信息。二者属于JVM的基础内容,此处不做介绍。
当然,由于轻量级锁天然瞄准不存在锁竞争的场景,如果存在锁竞争但不激烈,仍然可以用自旋锁优化,自旋失败后再膨胀为重量级锁。
在没有实际竞争的情况下,还能够针对部分场景继续优化。如果不仅仅没有实际竞争,自始至终,使用锁的线程都只有一个,那么,维护轻量级锁都是浪费的。偏向锁的目标是,减少无竞争且只有一个线程使用锁的情况下,使用轻量级锁产生的性能消耗。轻量级锁每次申请、释放锁都至少需要一次CAS,但偏向锁只有初始化时需要一次CAS。
“偏向”的意思是,偏向锁假定将来只有第一个申请锁的线程会使用锁(不会有任何线程再来申请锁),因此,只需要在Mark Word中CAS记录owner(本质上也是更新,但初始值为空),如果记录成功,则偏向锁获取成功,记录锁状态为偏向锁,以后当前线程等于owner就可以零成本的直接获得锁;否则,说明有其他线程竞争,膨胀为轻量级锁。
偏向锁无法使用自旋锁优化,因为一旦有其他线程申请锁,就破坏了偏向锁的假定。
互斥锁的底层原理是什么?——参考文章 、参考文章2
基于计算机的原子操作。比如物理内存为1则表示该锁锁住,这时CPU想获得锁,先往寄存器填1,然后将寄存器的值与该内存通过xchg指令互换(原子操作),如果换完后,寄存器值为0,则表示CPU成功获得锁,并防止其他CPU获得该锁。
相关函数:
其中,互斥锁又可以分为快速互斥锁、递归互斥锁和检错互斥锁。这3种锁的区别主要在于其它未占有互斥锁的线程在希望得到互斥锁时是否需要阻塞等待。
挂起: 一般是主动的,由系统或程序发出,因此回复也应主动完成。
阻塞:一般是被动的,在抢占资源中得不到资源,被动的挂起,等待某种资源释放或信号将它唤醒,你不知道它什么时候阻塞,也不清楚什么时候恢复。
与互斥锁不同,条件变量是用来等待而不是用来上锁的。条件变量用来自动阻塞一个线程,直到重新唤醒。通常条件变量和互斥锁同时使用。条件变量(cond)是在多线程程序中用来实现"等待->唤醒"逻辑常用的方法。——参考文章
为什么有互斥锁,还需要条件变量?
引入条件变量的目的:在使用互斥锁的基础上引入条件变量可以使程序的效率更高,因为条件变量的引入明显减少了线程取竞争互斥锁的次数。执行pthread_cond_wait或pthread_cond_timedwait函数的线程明显知道了条件不满足,因此在其释放锁之后就没有必要再跟其它线程去竞争锁了,只需要阻塞等待signal或broadcast函数将其唤醒。这样提高了效率。
互斥锁用于上锁,条件变量用于等待。条件变量使我们可以睡眠等待某种条件出现。条件变量是利用线程间共享的全局变量进行同步的一种机制,主要包含两个动作:
举个例子:
不加条件变量
/*
* Assume we have global variables:
* int iCount == 0;
* pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
*/
//thread 1:
thread 1 () {
while(1)
{
pthread_mutex_lock(&mutex);
iCount++;
pthread_mutex_unlock(&mutex);
}
}
//thread 2:
thread 2 () {
while(1) {
pthread_mutex_lock(&mutex);
iCount++;
while (iCount >= 100) //忙等待,线程一直处于运行,耗费资源
{
printf("iCount >= 100\r\n");
break;
}
pthread_mutex_unlock(&mutex);
}
}
添加条件变量:
//thread1 :
thread 1 () {
while (1)
{
pthread_mutex_lock(&mutex);
iCount++;
pthread_mutex_unlock(&mutex);
while (iCount >= 100)
{
pthread_cond_signal(&cond);
}
}
}
//thread2:
thread 2 () {
while(1)
{
pthread_mutex_lock(&mutex);
iCount++;
while (iCount < 100) { //由于调用pthread_cond_wait()而被阻塞的线程在被唤醒时,
//其需要等待的条件可能依然是未被满足的(这种情况被称为//spurious wakeup),
//所以需要在循环里继续做检查,如果真的发生了这种情况就继续等待。
pthread_cond_wait(&cond, &mutex); // 线程被阻塞挂起,等待信号来临,并且释放mutex
}
pthread_mutex_unlock(&mutex);
printf("iCount >= 100\r\n");
}
}
为了防止竞争,条件变量的使用总是和一个互斥锁结合在一起,线程在改变条件状态前必须锁住互斥量,函数pthread_cond_wait把自己放到等待条件的线程列表上,然后对互斥锁解锁,在函数返回时,互斥锁再次被锁住。
在thread 2 调用 pthread_cond_wait() 的时刻到 thread 2真正进入 wait 状态时,是存在着时间差的。如果在这段时间差内 thread1 调用了 pthread_cond_signal() 那这个 signal 信号就丢失了。给 wait 加锁可以防止同时有另一个线程在 signal。
信号量就是操作系统中多用到的PV原子操作,它广泛应用于进程或线程间的同步与互斥。信号量本质上是一个非负的整数计数器,包括一个称为信号量的变量和在该信号量下等待资源的进程等待队列,以及对信号量进行的两个原子操作(P/V操作)。其中,信号量对应于某一种资源,取一个非负的整形值。信号量值(常用sem_id表示)指的是当前可用的该资源的数量,若等于0则意味着目前没有可用的资源。
相关函数:
初始化:sem_init()
P操作:sem_wait() / sem_trywait() :当信号量<0时,阻塞 / 当信号量<0时,立即返回,信号量-1
V操作:sem_post():信号量
PV原子操作是对整数计数器信号量sem的操作。一次P操作使sem减1,而一次V操作使sem加1。进程(或线程)根据信号量的值来判断是否对公共资源具有访问权限。当信号量sem的值≥0时,该进程(或线程)具有公共资源的访问权限;相反,当信号量sem的值<0时,该进程(或线程)就将阻塞直到信号量sem的值≥0为止。
PV原子操作主要用于进程或线程间的同步和互斥这两种典型情况。若用于互斥,几个进程(或线程)往往只设置一个信号量sem,其操作是无序的,流程如图1所示。
当信号量用于同步操作时,往往会设置多个信号量,并安排不同的初始值来实现它们之间的顺序执行,其操作耦合了顺序性,流程如图2所示。

Linux实现了Posix的无名信号量,主要用于线程间的互斥与同步。这里主要介绍几个常见函数:
经典"生产者-消费者"问题
问题描述如下:
有一个有限缓冲区(这里用有名管道实现FIFO式缓冲区)和两个线程:生产者和消费者,它们不停地把产品放入缓冲区和从缓冲区拿走产品。**一个生产者在缓冲区满的时候必须等待,一个消费者在缓冲区空的时候也必须等待。**另外,因为缓冲区是临界资源,所以生产者和消费者之间必须互斥执行。它们之间的关系如下图1所示:

这里要求使用有名管道来模拟有限缓冲区,并且使用信号量来解决“生产者—消费者”问题中的同步和互斥问题。
Amdahl定律:在增加计算资源的情况下,程序在理论上能够实现最高加速比,这个值取决于程序中可并行组件与串行组件所占的比重。 假设F是必须串行执行的部分,那么根据Amdahl定律,在包含N个处理器的机器中,最高的加速比为:
Speedup ≤ 1 / (F + (1-F) / N)
当N趋近无穷大时,最大的加速比趋近于1/F。因此,如果程序有50%的计算需要串行执行,那么最高的加速比只能是2。
在所有的并发程序中都包含一些串行部分。如对并行结果进行处理。——参考文章
竞争锁是造成多线程应用程序性能瓶颈的主要原因。
如果一个锁被多个线程使用过,但是在任意时刻,都只有一个线程尝试获取锁,那么它的开销要大一些。我们将以上两种锁称为非竞争锁。而对性能影响最严重的情况出现在多个线程同时尝试获取锁时。
很多开发人员因为担心同步带来的性能损失,而尽量减少锁的使用,甚至对某些看似发生错误概率极低的临界区不使用锁保护。这样做往往不会带来性能提高,还会引入难以调试的错误。因为这些错误通常发生的概率极低,而且难以重现。
因此,在保证程序正确性的前提下,解决同步带来的性能损失的第一步不是去除锁,而是降低锁的竞争。
降低锁竞争的方法:
相互独立的状态变量,应该使用独立的锁进行保护。有时开发人员会错误地使用一个锁保护所有的状态变量。这些技术减小了锁的粒度,实现了更好的可伸缩性(可伸缩性是指:当增加计算资源时(如CPU、内存、存储容量或I/O带宽),程序的吞吐量或处理能力能相应地增加)。但是,这些锁需要仔细地分配,以降低发生死锁的危险。
如果一个锁守护多个相互独立的状态变量,你可能能够通过分拆锁,使每一个锁守护不同的变量,从而改进可伸缩性。通过这样的改变,使每一个锁被请求的频率都变小了。分拆锁对于中等竞争强度的锁,能够有效地把它们大部分转化为非竞争的锁,使性能和可伸缩性都得到提高。
当一个锁竞争激烈时,将其分拆成两个,很可能得到两个竞争激烈的锁。尽管这可以使两个线程并发执行,从而对可伸缩性有一些小的改进。但仍然不能大幅地提高多个处理器在同一个系统中的并发性。
分拆锁有时候可以被扩展,分成若干加锁块的集合,并且它们归属于相互独立的对象,这样的情况就是分离锁。如果在锁上存在适中且不是很激烈的竞争时,通过将一个锁分解为两个锁,能最大限度地提升性能。如果对竞争并不激烈的锁进行分解,那么在性能和吞吐量等方面带来的提升将非常有限,但也会提升性能,但随着竞争变得激烈,而下降到拐点值。对竞争适中的锁进行分解时,实际上是将这些锁转变为非竞争的锁,从而有效地提高性能和可伸缩性。
而在某些情况下,可将锁分解技术进一步扩展为对一组独立对象上的锁进行分解,这种情况被称为锁分段。但锁分段有一个劣势:
在某些应用中,我们会使用一个共享变量缓存常用的计算结果。每次更新操作都需要修改该共享变量以保证其有效性。例如,队列的 size,counter,链表的头节点引用等。在多线程应用中,该共享变量需要用锁保护起来。当每个操作都请求多个变量时,锁的粒度将很难降低。这是在性能和可伸缩性之间相互制衡的另一个方面。
这种在单线程应用中常用的优化方法会成为多线程应用中的“热点域 (hot field) ”,从而限制可伸缩性。如果一个队列被设计成为在多线程访问时保持高吞吐量,那么可以考虑在每个入队和出队操作时不更新队列 size 。 ConcurrentHashMap 中为了避免这个问题,在每个分片的数组中维护一个独立的计数器,使用分离的锁保护,而不是维护一个全局计数。
替代独占锁:第三种降低竞争锁的影响的技术是放弃使用独占锁,从而有助于使用一种友好并发的方式来管理共享状态。如使用并发容器、读-写锁、不可变对象以及原子变量
使用线程常常是为了充分利用多核的能力,因此在并发程序的性能讨论中,将侧重点放在吞吐量和可伸缩性上,而不是服务时间。根据Amdahl定律,程序的可伸缩性取决于在所有代码中必须被串行执行的代码比例。因为Java程序中串行操作的主要来源是独占式访问(锁或资源),因此通常可以通过以下方式来提高可伸缩性:减少锁的持有时间,降低锁的粒度,采用非独占的锁或非阻塞锁来代替独占锁。






重入一般可理解为一个函数在同时多次调用。例如:操作系统在进程调度过程中,或者单片机、处理器等的中断时候会发生重入的现象。
在多任务系统下,中断可能在任务执行的任何时间发生;如果一个函数的执行期间被中断后,到重新恢复到断点进行执行的过程中,函数所依赖的环境没有发生改变,那么这个函数就是可重入的,否则就不可重入。
在中断前后不都要保存和恢复上下文吗,怎么会出现函数所依赖的环境发生改变了呢?
众所周知,在进程中断期间,系统会保存和恢复进程的上下文,然而回复的上下文仅限于返回地址、CPU、寄存器等之类的少量上下文,而函数内部的诸如全局或静态变量、Buffer等不在保护之列,所以若这些值在重点期间发生了改变,那么当函数回到断点继续执行时,结果将无法预料.
可重入的函数必须满足三个条件:
可重入的函数可以在任意时刻中断,稍后再继续执行,不会丢失数据。
而满足下面条件之一的多数是不可重入函数:
不可重入的函数不能超过一个任务所共享,除非能保证函数的互斥。(或者使用信号量,或者在代码的关键部分禁用中断)
通常,以下几种情况会受到可重入性的制约:
预防不可重入的几个原则:
malloc/free。# !/bin/sh 指定脚本解释器
变量:
your_name="zhang" , 注意,变量名和等号中间不能有空格。echo $yourname或 echo ${yourname},加花括号是为了帮助解释器识别变量的边界,防止与其它单词连接在一起,调用了其他变量(变量替换$行)文件包含:
Source 和 .关键字,如 Source ./function.sh 或 . ./function.sh
. $real_path
if语句:
-d filename:若filename为目录,则为真。-f filename:若filename为常规文件,则为真。-L filename:若filename符号链接,则为真。-r.w.x filename:若filename可读写执行,则为真。-s filename:若filename长度不为0,则为真。-h filename:若filename是软连接,则为真。-nt/-ot filename2:若filename比filename2新/旧,则为真。整形变量表达式:
-eq :等于-ne :不等于-gt :大于-ge :大于等于-it :小于ie:小于等于字符变量表达式:
比较表达式:
特殊符号:
;;(Terminator):专用在case的选项,担任Terminator终结者的角色'(single quote):被单引号括住的内容,被视为单一字符。在引号内的代表变数的$符号,没有作用,也就是说,它被视为一般符号处理,防止任何变量替换。"(double quote):被双引号括住的内容,被视为单一字符。它防止通配符扩展,但允许变量扩展,这点和单引号的处理方式不同。\\ :在交互模式下的escape 字元,有几个作用;放在指令前,有取消 aliases的作用;放在特殊符号前,则该特殊符号的作用消失;放在指令的最末端,表示指令连接下一行。? (wild card) :在文件名扩展(Filename expansion)上扮演的角色是匹配一个任意的字元,但不包含 null 字元&: 后台工作$* :代表所有引用变量的符号。@与 $*具有相同作用的符号,不过她们两者有一个不同点。 符号 $*将所有的引用变量视为一个整体。但符号$@则仍旧保留每个引用变量的区段观念$#:这也是与引用变量相关的符号,她的作用是告诉你,引用变量的总数量是多少。$? 状态值 (status variable) :一般来说,UNIX(linux) 系统的进程以执行系统调用exit()来结束的。这个回传值就是status值。回传给父进程,用来检查子进程的执行状态。文本处理三剑客(都可以配合正则表达式使用):
make -j8 : 开启多线程的编译,同时允许8个任务。
命令替换:$() 和 ``(反引号) 都可以用作命令替换。例: version = $(uname -r) 或 version = `uname -r`
正则表达式匹配的三种模式:贪婪模式Greedy、懒惰模式Reluctant、独占模式Possessive
五层协议



TCP/IP协议:它只有四层,相当于五层协议中数据链路层和物理层合并为网络接口层。TCP/IP 体系结构不严格遵循 OSI 分层概念,应用层可能会直接使用 IP 层或者网络接口层。




根据信息在传输线上的传送方向,分为以下三种通信方式:
信道分类:
广播信道:一对多通信,一个节点发送的数据能够被广播信道上所有的节点接收到。所有的节点都在同一个广播信道上发送数据,因此需要有专门的控制方法进行协调,避免发生冲突(冲突也叫碰撞)。
主要有两种控制方法进行协调,一个是使用信道复用技术,一是使用 CSMA/CD 协议。
点对点信道:一对一通信。因为不会发生碰撞,因此也比较简单,使用 PPP 协议进行控制。
信道复用技术:
频分复用:频分复用的所有主机在相同的时间占用不同的频率带宽资源。

时分复用:时分复用的所有主机在不同的时间占用相同的频率带宽资源。

使用频分复用和时分复用进行通信,在通信的过程中主机会一直占用一部分信道资源。但是由于计算机数据的突发性质,通信过程没必要一直占用信道资源而不让出给其它用户使用,因此这两种方式对信道的利用率都不高。
统计时分复用:是对时分复用的一种改进,不固定每个用户在时分复用帧中的位置,只要有数据就集中起来组成统计时分复用帧然后发送。

波分复用:光的频分复用。由于光的频率很高,因此习惯上用波长而不是频率来表示所使用的光载波。
码分复用:为每个用户分配 m bit 的码片,并且所有的码片正交。

CSMA/CD 协议:CSMA/CD 表示载波监听多点接入 / 碰撞检测。
记端到端的传播时延为 τ,最先发送的站点最多经过 2τ 就可以知道是否发生了碰撞,称 2τ 为 争用期 。只有经过争用期之后还没有检测到碰撞,才能肯定这次发送不会发生碰撞。
当发生碰撞时,站点要停止发送,等待一段时间再发送。这个时间采用 截断二进制指数退避算法 来确定。从离散的整数集合 {0, 1, …, (2k-1)} 中随机取出一个数,记作 r,然后取 r 倍的争用期作为重传等待时间。

PP 协议:互联网用户通常需要连接到某个 ISP 之后才能接入到互联网,PPP 协议是用户计算机和 ISP 进行通信时所使用的数据链路层协议。

因为网络层是整个互联网的核心,因此应当让网络层尽可能简单。网络层向上只提供简单灵活的、无连接的、尽最大努力交互的数据报服务。——参考文章
使用 IP 协议,可以把异构的物理网络连接起来,使得在网络层看起来好像是一个统一的网络。

与 IP 协议配套使用的还有三个协议:

网络层只把分组发送到目的主机,但是真正通信的并不是主机而是主机中的进程。传输层提供了进程间的逻辑通信,传输层向高层用户屏蔽了下面网络层的核心细节,使应用程序看起来像是在两个传输层实体之间有一条端到端的逻辑通信信道。


文件传送协议(FTP):
FTP 使用 TCP 进行连接,它需要两个连接来传送一个文件:
主动模式:服务器端主动建立数据连接,其中服务器端的端口号为 20,客户端的端口号随机,但是必须大于 1024,因为 0~1023 是熟知端口号。

被动模式:客户端主动建立数据连接,其中客户端的端口号由客户端自己指定,服务器端的端口号随机。

主动模式要求客户端开放端口号给服务器端,需要去配置客户端的防火墙。被动模式只需要服务器端开放端口号即可,无需客户端配置防火墙。但是被动模式会导致服务器端的安全性减弱,因为开放了过多的端口号。
动态主机配置协议(DHCP):DHCP (Dynamic Host Configuration Protocol) 提供了即插即用的连网方式,用户不再需要手动配置 IP 地址等信息。
DHCP 配置的内容不仅是 IP 地址,还包括子网掩码、网关 IP 地址。
DHCP 工作过程如下:

Web 页面请求过程:
短连接(short-lived connection)与长连接(persistent connections):
HTTP协议是建立在TCP协议基础上的,当浏览器需要从服务器获取网页数据的时候,会发出一次HTTP请求。HTTP会通过TCP建立其一个服务器的连接通信,当本次请求的数据完毕后,HTTP会通过TCP建立起一个服务器的连接通信,当本次请求的数据完毕后,HTTP会通过TCP建立起一个服务器的连接通信,当本次请求的数据完毕后,HTTP会立即将TCP连接断开,这个过程是短的,所以HTTP连接是一种短连接,是一种无状态的连接。
随着时间推移,HTML页面变得复杂,里面可能包含多张图片,除了请求访问的HTML页面资源,还会请求图片资源。如果每进行一次HTTP通信就要新建一个TCP连接,那么开销就会很大,这时长连接就应运而生。
长连接只需要建立一次 TCP 连接就能进行多次 HTTP 通信。

Pipelining 流水线:默认情况下,HTTP 请求是按顺序发出的,下一个请求只有在当前请求收到响应之后才会被发出。由于受到网络延迟和带宽的限制,在下一个请求被发送到服务器之前,可能需要等待很长时间。
流水线是在同一条长连接上连续发出请求,而不用等待响应返回,这样可以减少延迟。
Cookie:HTTP 协议是无状态的,主要是为了让 HTTP 协议尽可能简单,使得它能够处理大量事务。HTTP/1.1 引入 Cookie 来保存状态信息。
Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一浏览器。由于之后每次请求都会需要携带 Cookie 数据,因此会带来额外的性能开销(尤其是在移动环境下)。
Cookie 曾一度用于客户端数据的存储,因为当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie 渐渐被淘汰。新的浏览器 API 已经允许开发者直接将数据存储到本地,如使用 Web storage API(本地存储和会话存储)或 IndexedDB。
HTTP 有以下安全性问题:
HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)/ TLS 通信,再由 SSL 和 TCP 通信,也就是说 HTTPS 使用了socket进行通信。
通过使用 SSL,HTTPS 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)。

加密
公开密钥所有人都可以获得,通信发送方获得接收方的公开密钥之后,就可以使用公开密钥进行加密,接收方收到通信内容后使用私有密钥解密。
非对称密钥除了用来加密,还可以用来进行签名(防止中间人攻击)。因为私有密钥无法被其他人获取,因此通信发送方使用其私有密钥进行签名,通信接收方使用发送方的公开密钥对签名进行解密,就能判断这个签名是否正确。

认证: 通过使用证书对通信方进行认证。
证书安全性怎么保证?为什么黑客不能做一个假证书?通常,证书签发机构审核非常严格,如果你请求的域名与返回的证书不一致,浏览器会拒绝访问请求(但证书签发机构是否良心是不可控的)
同步和异步关注的是消息通信机制,并发和并行其实是异步线程实现的两种方式。并行其实是真正的异步,并发是个伪异步。
同步通信:发送发发出数据后,等待接收方发回响应以后,才发下一个数据包的通讯方式。同步通信要求接受端时钟频率与发送端时钟频率一致,发送端发送连续的比特流。
同步通信是阻塞模式,代表有SPI,IIC协议,特点是通信效率高,但较为复杂。
异步通信:发送方发出数据后,不等待接收方发回响应,接着发送下个数据包的通讯方式。异步不需要时钟同步,发送端发完一个字节后,可经任意长的时间间隔再发下一个字节。
异步通信是非阻塞模式,代表有UART协议(需要开始位和结束位),传输效率低。
linux下经典五位哲学家吃面模型分析:——参考资料1,参考资料2
进程同步与进程通信很容易混淆,它们的区别在于:——参考资料
进程通信是一种手段,而进程同步是一种目的。也可以说,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
#include <unistd.h>
int pipe(int fd[2]);
它具有以下限制:

2. FIFO:也称为命名管道,去除了管道只能在父子进程中使用的限制。
#include <sys/stat.h>
int mkfifo(const char *path, mode_t mode);
int mkfifoat(int fd, const char *path, mode_t mode);
FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户进程和服务器进程之间传递数据。

3. 消息队列
相比于 FIFO,消息队列具有以下优点:
允许多个进程共享一个给定的存储区。因为数据不需要在进程之间复制,所以这是最快的一种 IPC。大多时候需要使用信号量用来同步对共享存储的访问。多个进程可以将同一个文件映射到它们的地址空间从而实现共享内存。另外 XSI 共享内存不是使用文件,而是使用内存的匿名段。
进程间通信之共享内存shm 和 Socket 通信 payload (有效负载大小)。
我们知道两个进程如果需要进行通讯最基本的一个前提能能够唯一的标示一个进程,在本地进程通讯中我们可以使用PID来唯一标示一个进程,但PID只在本地唯一,网络中的两个进程PID冲突几率很大,这时候我们需要另辟它径了,我们知道IP层的ip地址可以唯一标示主机,而TCP层协议和端口号可以唯一标示主机的一个进程,这样我们可以利用ip地址+协议+端口号唯一标示网络中的一个进程。
socket(套接字)是应用层和传输层的一个抽象层,它把TCP/IP层的复杂关系的操作抽象为几个简单的接口供应用层调用已实现进程在网络中的通信。
Packet(包): 在包交换网络里,单个消息被划分为多个数据块,这些数据块称为包,它包含发送者和接收者的地址信息,这些包沿着不同路径在一个或多个网络中传输,并且在目的地重新组合。
socket 进行TCP通信丢包:
TCP协议下Socket有可能丢包吗?(分包/片)

strean(流):流是字节流(Byte stream)的简称,也就是长长的一串字节。其特征是连续,可以没有头没有尾,没有绝对的位置,但是由于流是连续的,所以有相对位置。
流媒体:整包分开分段发包,使数据包得以像流水一样发送,读一点数据就处理一点数据,而不用在使用前下载整个包文件。
使用流的核心是底层有个缓冲区BUFFER,这样不至于因为写的太快不及读取或相反的情况发生,从而协调了读写的不同速度的问题。
TCP协议 保证了数据通信的完整性和可靠性,IP协议解决了多个局域网互通,Ethernet以太网协议解决了局域网点对点通信。
慢启动(slow start)和 ACK(acknowledgement,携带了两个信息):期待要收到下一个数据包的编号和接收方的接收窗口的剩余容量。通过检查ACK编号信息,可以实现丢包重发。
资源竞争:多线程程序可以并行运行,可是IDE输出结果有时不如预期,原因在于控制台只有一个,只有一个线程拥有这一个唯一的控制台将数字输出。由于控制台是系统资源,这里控制台拥有的管理是操作系统完成的。但是,假如是多个线程共享空间的数据,这就需要自己写代码去控制,每个线程何时能够拥有共享数据进行操作。共享数据的管理以及线程间通信时多线程两核心。
多线程程序是并发执行,对多线程的公用资源不能保证能被正确利用,即不保证能被独占。并发执行的时候,哪个线程得到运行的机会是随机的,也是不可预测的。为了解决多线程中某个程序对资源的独占,只允许一个线程拥有共享资源的独占。
进程拥有独立资源,进程之间交换数据需要考虑通信。线程之间共享资源,需要考虑资源的同步与互斥。
多进程之间的通信方式(Inter-Process communication,IPC):
多线程之间的通信方式:
消息同步互斥机制:

自旋锁:自旋锁加锁失败后,线程会忙等待,直到它拿到锁。线程一直是running(加锁->解锁),死循环检测锁的标志位。缺点是一直占用CPU,并且有可能造成死锁。(若资源被占用,申请着就一直循环在那查看该自旋锁占用者是否已经释放了锁)——参考文章
所以,如果你能确定被锁住的代码执行时间很短,就不应该用互斥锁,而应该选用自旋锁,否则使用互斥锁。
自旋锁死锁:嵌套拥有自旋锁。
a进入自旋锁,b等待a释放并开始自选忙等待
int a() {
spinLock();
b();
unLock();
}
int b() {
spinLock();
unLock();
}
互斥锁:互斥锁加锁失败后,线程会释放 CPU ,给其他线程。线程会从sleep(加锁)->running(解锁),过程有上下文的切换,CPU的抢占,信号的发送等开销(若资源已被占用,资源申请者只能进入睡眠状态)。
对于互斥锁加锁失败而阻塞的现象,是由操作系统内核实现的。所以,互斥锁加锁失败时,会从用户态陷入到内核态,让内核帮我们切换线程,虽然简化了使用锁的难度,但是存在一定的性能开销成本(两次上下文的切换)。
互斥锁死锁:假设A线程持有锁a,B线程持有锁b,而线程访问临界的条件是同时具有锁a和锁b,那么A就会等待B释放锁b,B也会等待A释放锁a。
互斥锁死锁产生的情况:1.系统资源不足。如果系统资源足够,每个申请锁的线程都能后获得锁,那么锁情况就会大大降低。 2.申请锁顺序不当。当两个线程按照不同的顺序申请,释放锁资源时也会产生死锁。
互斥锁死锁产生的条件:1.互斥属性:即每次只能有一个线程占用资源。2.请求与保持:即已经申请到锁资源的线程可以继续申请。在这种情况下,一个线程也可以产生死锁情况,即抱着锁找锁。3.不可剥夺:线程已经得到锁资源,在自己没有主动释放之前,不能被强制剥夺,只能由自己释放。 4.循环等待:多个线程形成环路等待,每个线程都在等待相邻线程的所资源。
自旋锁和互斥锁使用的不同场景:
临界区
互斥量
临界区和互斥量都有"线程所有权"概念,所以它们是不能用来实现线程间的同步的,只能用来实现互斥。
原因是由于创建临界区或互斥量的线程不用等待leaveCriticalSectional(),setevent就可以无条件进入保护的程序段,因为它拥有这个权力。另外,互斥器可以很好的处理”遗弃“操作。若线程在未释放对向象的时候就意外终止的,其它线程可以等待到一个WAIT_ABANDONED_0。但是事件和信号量都不能做到。
信号量
事件
事件和信号量都可以实现线程和进程间的互斥和同步。就使用效率来说,临界区的效率是最高的,因为它不是内核对象,而其它的三个都是内核对象,调用要进入内核态,效率相对来说就比较低。但如果要跨进程使用还是要用到互斥器、事件对象和信号量。
必要条件:——参考资料

死锁检测与死锁恢复:不试图阻止死锁,而是当检测到死锁发生时,采取措施进行恢复。

图 a 可以抽取出环,如图 b,它满足了环路等待条件,因此会发生死锁。
每种类型一个资源的死锁检测算法是通过检测有向图是否存在环来实现,从一个节点出发进行深度优先搜索,对访问过的节点进行标记,如果访问了已经标记的节点,就表示有向图存在环,也就是检测到死锁的发生。

进程 P1 和 P2 所请求的资源都得不到满足,只有进程 P3 可以,让 P3 执行,之后释放 P3 拥有的资源,此时 A = (2 2 2 0)。P2 可以执行,执行后释放 P2 拥有的资源,A = (4 2 2 1) 。P1 也可以执行。所有进程都可以顺利执行,没有死锁。
算法总结如下:
每个进程最开始时都不被标记,执行过程有可能被标记。当算法结束时,任何没有被标记的进程都是死锁进程。
在程序运行之前预防发生死锁。
在程序运行时避免发生死锁。

图 a 的第二列 Has 表示已拥有的资源数,第三列 Max 表示总共需要的资源数,Free 表示还有可以使用的资源数。从图 a 开始出发,先让 B 拥有所需的所有资源(图 b),运行结束后释放 B,此时 Free 变为 5(图 c);接着以同样的方式运行 C 和 A,使得所有进程都能成功运行,因此可以称图 a 所示的状态时安全的。
定义:如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得每一个进程运行完毕,则称该状态是安全的。
安全状态的检测与死锁的检测类似,因为安全状态必须要求不能发生死锁。下面的银行家算法与死锁检测算法非常类似,可以结合着做参考对比。

上图 c 为不安全状态,因此算法会拒绝之前的请求,从而避免进入图 c 中的状态。

上图中有五个进程,四个资源。左边的图表示已经分配的资源,右边的图表示还需要分配的资源。最右边的 E、P 以及 A 分别表示:总资源、已分配资源以及可用资源,注意这三个为向量,而不是具体数值,例如 A=(1020),表示 4 个资源分别还剩下 1/0/2/0。
检查一个状态是否安全的算法如下:
如果一个状态不是安全的,需要拒绝进入这个状态。




共享内存是一种最为高效的进程间通信方式,因为进程可以直接访问内存,不需要进行任何数据的复制。为了在多个进程间交换信息,内核专门留出了一块内存区,这段内存区可以由需要访问的进程将其映射到自己的私有地址空间。因此,进程就可以直接读写这一段内存而不需要进行数据的复制,从而提高效率。
shmget()。shmatI()。shmdt()。因为共享内存自身并不提供同步机制,所以应额外实现不同进程间的同步。
消息队列就是一些消息的队列,具有一定的FIFO特性,但是它可以实现消息的随机查询,比FIFO具有更大的优势。同时,这些消息又是存在内核中的,由队列ID来标识。
消息队列的实现操作:
系统建立IPC(Interprocess Communication)通信时必须指定一个ID值。该ID值可以通过ftok函数获得,它可以更具不同的路径和关键字来产生标准的key。
消息队列和命令管道类似,但少了打开和关闭管道方面的复杂性,但使用消息队列并未解决我们在使用命名管道时遇到的一些问题。
管道没有“消息”的概念,它只是通往write字节和read字节之间的管道,接收方必须有一种方法知道程序中哪些数据构成"消息",并且您必须自己实现。此外,还定义了字节的顺序:字节按照您放入它们的顺序出现。通常,它具有一个输入和一个输出。
消息队列用于传输具有类型和大小的“消息”,因此,接收端可以只等待某种类型的“消息”,而不必担心它是否完整。多个进程可能会发送到同一队列或同一队列接受(管道一旦关闭,就需要双方进行一定程度的合作以重新建立它们。消息队列可以在任一一侧关闭和重新打开,而无需另一侧的配合)
I/O 值得是读入/写出数据的过程和等待读入/写出的过程,一旦拿到数据后,就变成了数据操作了,就不是I/O了。拿网络I/O来说,等待的过程就是数据从网络到主机再到内核空间,读写的过程就是内核空间和用户空间的相互拷贝。
一个输入操作通常包括两个阶段:
应用程序都是运行在用户空间的,所以它们能操作的数据也都在用户空间,按这样理解,只要数据没有到达用户空间,用户线程就操作不了。
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待数据到达时,它被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区。
Unix有五种 I / O 模型 :
我们知道两个进程如果需要通讯,最基本的一个前提就是能够唯一的标识一个进程,在本地进程通讯中,我们可以使用PID来唯一标识一个进程,但PID只在本地唯一,网络中的两个进程冲突几率很大,但是IP层的ip地址是可以唯一标识主机,而TCP层协议和端口号可以唯一标识主机的一个进程,这样我们就可以利用它唯一标识网络中的一个进程了。(201.37.146.1:23)
能唯一标识网络中的进程后,它们就可以利用socket进行通信了。什么是Socket呢?Socket就是在应用层和传输层之间的一个抽象层,它把TCP/IP层复杂操作抽象为几个简单的接口供应用层调用已完成进程在网络中通信。

应用进程被阻塞,直到数据从内核缓冲区复制到应用进程缓冲区中才返回。
应该注意到,在阻塞的过程中,其它应用进程还可以执行,因此阻塞不意味着整个操作系统都被阻塞。因为其它应用进程还可以执行,所以不消耗 CPU 时间,这种模型的 CPU 利用率会比较高。
下图中,recvfrom() 用于接收 Socket 传来的数据,并复制到应用进程的缓冲区 buf 中。这里把 recvfrom() 当成系统调用。
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);

应用进程执行系统调用之后,内核返回一个错误码。应用进程可以继续执行,但是需要不断的执行系统调用来获知 I/O 是否完成,这种方式称为轮询(polling)。
由于 CPU 要处理更多的系统调用,因此这种模型的 CPU 利用率比较低。

使用 select 或者 poll 等待数据,并且可以等待多个套接字中的任何一个变为可读。这一过程会被阻塞,当某一个套接字可读时返回,之后再使用 recvfrom 把数据从内核复制到进程中。
它可以让单个进程具有处理多个 I/O 事件的能力。又被称为 Event Driven I/O,即事件驱动 I/O。
如果一个 Web 服务器没有 I/O 复用,那么每一个 Socket 连接都需要创建一个线程去处理。如果同时有几万个连接,那么就需要创建相同数量的线程。相比于多进程和多线程技术,I/O 复用不需要进程线程创建和切换的开销,系统开销更小。


应用进程使用 sigaction 系统调用,内核立即返回,应用进程可以继续执行,也就是说等待数据阶段应用进程是非阻塞的。内核在数据到达时向应用进程发送 SIGIO 信号,应用进程收到之后在信号处理程序中调用 recvfrom 将数据从内核复制到应用进程中。
相比于非阻塞式 I/O 的轮询方式,信号驱动 I/O 的 CPU 利用率更高。

应用进程执行 aio_read 系统调用会立即返回,应用进程可以继续执行,不会被阻塞,内核会在所有操作完成之后向应用进程发送信号。
异步 I/O 与信号驱动 I/O 的区别在于,异步 I/O 的信号是通知应用进程 I/O 完成,而信号驱动 I/O 的信号是通知应用进程可以开始 I/O。

同步 I/O 包括阻塞式 I/O、非阻塞式 I/O、I/O 复用和信号驱动 I/O ,它们的主要区别在第一个阶段。非阻塞式 I/O 、信号驱动 I/O 和异步 I/O 在第一阶段不会阻塞。

编程:
四组不同而相辅相成的编程泛型(programming paradigms):
契约式设计(Design by contract): 一种设计计算机软件的方法,方法要求软件者为软件组件定义正式的,精准的并可验证的接口。这样为传统的抽象结构类型由增加了先决条件,后验条件和不变式。这种方法的名字里用的“契约”只是一种比喻,因为它和商业契约的情况有点类似。
契约作用域两方,每一方都会完成一些任务,从而促进契约的达成。但同时,每一方也会接受一些义务,作为契约的前提,在任意一方无视了必尽的义务,则契约失败。契约式编程可以严格区分责任,让每个人都不必为了迁就他人错误而进行【艰难的编码】,每个人按契约处理好自己的事情,让损毁契约的人承担责任。
防御式编程:人类都是不安全的,不值得信赖的,所有人都会犯错误,而你写的代码,应该考虑到所有可能发生的情况,让你的程序不会因为他人的错误而发生错误。
程序需对可能的错误输入作出兼容,其手段可以有如下两种:
ANSI C:第一个 C 语言在 1989 年被称为 ANSI 的机构标准化,这就是它被称为 c89 的原因。ANSI C 是一个过时的标准,只有过时的文档才会引用它。
C99 :应开发者的要求,在1999-2000年进一步或附加的关键字和特性已包含在C99中(例如:inline、boolean…添加了浮点数学库函数)。
C标准协议之上的厂商拓展:
POSIX:全称可移植操作系统接口。故名思议,由于当时Unix诞生之后,由于各个厂商都实现自己的Unix(都敢使用Unix,由于版权的问题),接口的不统一,导致在各个厂商下基于不同的操作系统开发变得很乱,为了解决这一问题,便有了POSIX标准。
GNU:GNU C叫做glibc是Linux上的一个基础库,glibc C实现了POSIX C标准的库函数功能,有些POSIX标准是单独的库函数存在的
我们一般说的C 语言称为 ISO C,或者如果您将其称为 ISO/IEC 9899:2011。
原语(primitives): ——参考资料
“石头、剪刀、布”这三样东西,除了“石头”是原语,而“剪刀”和“布头”不算,为什么呢?因为剪刀和布头都是人工合成的,而石头是浑然天成的。因此“原语”这个单词的定义还是要从它的英文原词 primitive 出发,也就是“原始”的意思。
计算机是一门人造科学,因此真正意义上的“原语”是不存在的。操作系统层面上的“原语”(比如 write 之类的系统调用)对程序员来讲的确是不可分割的最小单位,是在操作系统中调用核心层子程序的指令。与一般广义指令的区别在于它是不可中断的,而且总是作为一个基本单位出现。
inline关键字:解决一些频繁调用的小函数消耗栈空间的问题。
类内数组如何初始化:跳转
数组名不能作为左值 !!! 编译器会认为数组名作为左值代表的是a的首元素的首地址,但是这个地址开始的一块内存是一个整体,我们只能访问数组的某个元素,而无法把数组数组当做一个整体来进行访问。 所以,我们可以把a[i]当左值,无法把a当左值。
sizeof(string) = 4:字符串所占的空间是从堆中动态分配的,与sizeof()无关,其大小的值可能因编译器不同而不同。
宏(Macro)属于编译器预处理的范畴,属于编译期概念(而非运行期概念)
\是用来续行的,分段可以防止一行代码太长影响阅读,#用来把参数转换为字符串,相当给参数加上双引号,## 用来连接前后的两个参数,把它们变成一个字符串,#@给参数加上单引号。__FILE__ 在预编译时会替换成当前的源文件名,__LINE__ 在预编译时会替换成当前的行号,__FUNCTION__ 在预编译时会替换成当前的函数名称,__TIME__在源文件中插入当前编译时间,__DATE__在源文件中插入当前的编译日期.问:为什么应该使用模块(Module)替代头文件(Header)?
模块是什么?
使用“import”导入已命名的模块,import会在源文件中忽略预处理状态,并且选择性导入,所以弹性(resilience)非常好。
使用“import”会导入什么?
耦合性(coupling): 耦合性越强,则独立性越差,划分模块的一个准则就是高内聚(块内联系)低耦合(块与块之间)。
XML(Extensible Markup Language):被设计用来传输和存储数据,焦点在于数据的内容(存储配置信息)
HTML:被设计用来显示数据,焦点在于数据的外观
类中静态成员 / 函数:
size_t 类型:int小于等于数据线宽度,size_t大于等于地址线宽度。size_t存在的最大原因可能是因为:地址线宽度历史中经常都是大于数据线宽度的。使用size_t可能会提高代码的可移植性、有效性或者可读性,或许同时提高这三者。
size_t是标准C库中定义的无符号类型,在64位系统中为long long unsigned int,非64位系统中为long unsigned int。通常我们用sizeof(XXX)操作,这个操作所得到的结果就是size_t类型。size_t还经常出现在C++标准库中,此外,C++库中经常会使用一个相似的类型size_type,用的可能比size_t还要多。
元组tuple 是C++的一种容器,可以容纳不同类型,可以直接使用,在某些情况比结构体更加方便,简洁,直观。
std::pair是一个类模板,它可以将两个数据合成一个数据,如STL中的Map就是将Key和Value放在一起保存。
std::pair <std::string,double> product1; // default constructor
std::pair <std::string,double> product2 ("tomatoes",2.30); // value init
product2.first = "shoes"; // the type of first is string
product2.second = 39.90; // the type of second is double
元编程(Meraprogramming)是指某类计算机程序的编写。这些计算机编写或者操作其他程序(或者自身)作为它们的数据。或者在运行完成部分本应在编译时完成的工作。很多情况下与手工编写全部代码相比工作效率更高。
C++ 使用模板进行元编程: 跳转
特化/偏特化:
template<>
class compare<char *> //特化char*,当传入参数为char* 调用特化版本,而非通用模板
{
}
template<class Allocator>
class compare<bool, Allocator> //一个参数被绑定到bool类型,而另一个参数任未绑定而需要用户指定
{
}
注意区分深拷贝与浅拷贝,以及浅拷贝造成的内存泄漏。
常量不能被引用符引用:试图将一个const类型转换为非const类型是非法的,因为const变量存储在常量区。
虚表是属于类的,而不是属于某个具体的对象,一个类只需要一个虚表即可。同一类的所有对象都使用同一虚表。
B b; // B是A的子类
A *p = &b;
虽然P是基类指针,是只能指向基类的部分,但是虚表指针亦属于基类部分,所以p可以访问对象b的虚表指针。b的虚表指针指向类B的虚表,所以p可以访问B的vtbl。
结构体可以用块直接赋值(代码测试)
Linux 结构体成员变量加点赋值好处:
struct tst_key {
const char* name;
int good;
int bad;
}
static struct mem = {
"hello", 10 , 20
};
static struct tst_key member[] {
{ .name = "hello",
.good = 0 },
{ .name = "this is world",
.good = 1,
.bad = 2 },
{ .bad = 10,
.good = 20,
.name = "mini" }
};
位域:有些信息在存储时,并不需要一个完整的字节,而只需占几个或一个二进制位,例如在存放一个开关量时,只需要0和1两种状态,用一位二进制位即可。为了节省存储空间,并使处理简便,C语言又提供了一种数据结构,称为"位域"或"位段"。
所谓"位域"是一个字节中的二进制划分为几个不同的区域,并说明每个区域的位数。每个域都有一个域名,允许在程序中按位域名进行操作。这样就可以把几个不同的对象用一个字节的二进制位域来表示。
struct 位域结构名 {
位域列表;
}
一个位域必须存储在同一个字节中,不能跨两个字节。若一个字节所剩空间不足存放另一个位域,应从另一个单位存放。

热补丁:


类
构造、拷贝、移动和析构函数提供了对象的生命周期的方法。
为避免隐式切换(生成临时匿名对象),将单参数构造函数声明为explict。
如果不需要拷贝函数/移动函数,请明确禁止!
继承:基类的析构函数应该声明为virtual(当derived class对象经由一个base class指针被删除,而该base class带有一个non-virtual析构函数,其结果未有定义——实际执行时通常是对象的derived成员没有被销毁)(eg.effective c++条款07)
只有基类析构函数是virtual,通过多态调用的时候才能保证派生类的析构函数被调用。
重写虚函数时请使用override关键字:override保证函数是虚函数且重写了基类的虚函数,如果子类函数与基类函数原型不一致,则产生编译告警。
局部范围使用的Lambdas优先使用引用捕获,非局部范围使用Lambdas,避免使用引用捕获。
如果捕获this,则显示捕获所有变量(Lambdas表达式):
[=]看起来是按值捕获,但因为是隐式的按值获取了this指针,并且能够操作所有成员变量,数据成员实际是按引用捕获的,一般情况下建议避免。若的确需要这么做,明确写出对this的捕获。多重继承
问题:
优点:多重继承提供了一种简单的组合来实现多种接口和类的组装与复用。
对于多重继承只有下面几种情况才允许使用多重继承:
赋值操作符的重载引入的隐式转换会隐藏很深的BUG,可以定义类似Equals()、CopyFrom()等函数来替代=、==操作符。
函数参数(建议)
禁止用Memcpy_s,memset_s 初始化非POD(plain old data)对象,由于非POD类型比如非聚合类型的Class对象可能存在虚函数,内存布局不明确,和编译器有关,滥用内存拷贝可能导致严重问题。
避免构造函数做复杂的初始化可以使用init函数(建议),以下情况可以使用init函数进行初始化
强制类型转换
算数转换(c++11支持):对于那些算数转换,并且类型信息并没有丢失,比如。float到double,int32到int64转换,推荐使用大括号的初始化方式。
double d {some float};
int64_t i{some int32};
避免使用dynamic_cast:
避免使用reinterprete_cast:
避免使用const_cast:
// 不好的例子
const int i = 1024;
int *p = const_cast<int*>(&i);
*p = 2048; //未定义行为
// 不好的例子2
class foo {
public:
foo : i(3) {}
void func(int v)
{
i = v;
}
private:
int i;
}
int main(void)
{
const foo f;
foo *p = const_cast<foo*>(&f);
p->func(8); //未定义行为
}
智能指针
标准库:
std::string的c_str()返回的指针。string::c_str()指针持久有效,因此特定STL实现完全可以在调用string::c_str()时返回一个临时存储区并很快释放,所以为了保证程序的移植性,一定不要保存string::c_str()的结果,而是在每次需要时直接调用。auto_ptr。std::auto_ptr具有一个隐式的所有权转移行为。auto_ptr采用copy语义来转移指针资源,转移指针资源的所有权的同时将原指针置为NULL,这跟通常理解的copy行为是不一致的(不会修改原数据),而这样的行为在有些场合下不是我们希望看到的,即多个auto_ptr不能管理同一片内存, 执行=的时候,就把原来的auto_ptr给干掉。
例如参考《Effective STL》第8条,sort的快排实现中有将元素复制到某个局部临时对象中,但对于auto_ptr,局部临时对象指向资源同时,却将原元素置为`NULL,这就导致最后的排序结果中可能有大量的null。
转移所有权的行为通常不是期望的结果。对于必须转移所有权的场景,也不应该使用隐式转移的方式。这往往需要程序员对使用auto_ptr的代码保持额外的谨慎,否则出现对空指针的访问。
对于必须转移所有权的场景,也不应该使用隐式转移的方式。这往往需要程序员对使用auto_ptr的代码保持额外的谨慎,否则出现对空指针的访问。使用auto_ptr常见的有两种场景,一是作为智能指针传递到产生auto_ptr的函数外部,二是使用auto_ptr作为RAII管理类,在超出auto_ptr的生命周期时自动释放资源。对于第1种场景,可以使用std::shared_ptr来代替。对于第2种场景,可以使用C++11标准中的std::unique_ptr来代替。其中std::unique_ptr是std::auto_ptr的代替品,支持显式的所有权转移。
例外:在C++11标准得到普遍使用之前,在一定需要对所有权进行转移的场景下,可以使用std::auto_ptr,但是建议对std::auto_ptr进行封装,并禁用封装类的拷贝构造函数和赋值运算符,以使该封装类无法用于标准容器。
也正是基于C++11的对move语义的支持,使得这样的资源转移通常只会在必要的场合发生,例如转移一个临时变量(右值)给某个named variable(左值),或者一个函数的返回(右值)这也就是用unique_ptr代替auto_ptr的原因,本质上来说,就是unique_ptr禁用了copy,而用move替代。 ——参考资料
之所以说通常,是因为,也可以用std:move来实现左值move给左值,例如:
std::unique_ptr<bar> b0(new bar());
std::unique_ptr<bar> b1(std::move(b0));
unique_ptr而不是share_ptr
share_ptr引入计数的原子操作存在可测量的开销,大量使用影响性能。std::make_unique而不是new创建unique_ptr,使用std::make_shared而不是new创建shared_ptr异常
异常的优点:
缺点:
例如,如果使用C++的new,STL或者第三方代码中有异常机制的,在函数调用的时候可以使用try_catch进行异常处理,但是不要将异常继续抛出,而是内部处理掉异常。
结论:
从表面上看来,使用异常利大于弊, 尤其是在新项目中. 但是对于现有代码, 引入异常会牵连到所有相关代码. 如果新项目允许异常向外扩散, 在跟以前未使用异常的代码整合时也将是个麻烦.
模板
模板编程有时候能够实现更简洁更易用的接口, 但是更多的时候却适得其反. 因此模板编程最好只用在少量的基础组件, 基础数据结构上, 因为模板带来的额外的维护成本会被大量的使用给分担掉。
如果你使用模板编程, 你必须考虑尽可能的把复杂度最小化, 并且尽量不要让模板对外暴漏. 你最好只在实现里面使用模板, 然后给用户暴露的接口里面并不使用模板, 这样能提高你的接口的可读性. 并且你应该在这些使用模板的代码上写尽可能详细的注释. 你的注释里面应该详细的包含这些代码是怎么用的, 这些模板生成出来的代码大概是什么样子的. 还需要额外注意在用户错误使用你的模板代码的时候需要输出更人性化的出错信息. 因为这些出错信息也是你的接口的一部分, 所以你的代码必须调整到这些错误信息在用户看起来应该是非常容易理解, 并且用户很容易知道如何修改这些错误
std::optional
程序员经常碰到的一个问题是;一个函数有可能返回一个对象,也有可能返回失败,这种函数如何声明?以前通常有两种方法:
C++17标准库给出了一个更好的解决方法:std::optional模板。
函数返回std::optional时,表示即可能含值,也可能不含值。调用者可以用bool表达式来判断其是否含值,也可以用value_or函数来提供一个当不含值时的默认值。内部对象的生命周期由std::optional管理,当std::optional对象被释放时,其内部管理的对象也自动释放。



建议:
nullptr而不是null或0gsl::not_null明确指针不会为nullptr
noexcept
class Foo {
private:
Foo(const Foo&); //case : 只看头文件不知道拷贝构造函数是否被删除
public:
Foo& operator=(const Foo&) = delete; //明确删除拷贝赋值函数
}
template<class T>
void process(T value);
template<>
void process<void> (void) = delete; // delete关键字还支持删除非成员函数
安全编程规范:


函数常见问题:
字符串操作不当带来的风险:
buffer overflow攻击中,攻击者会将大于缓冲区的恶意数据传入某个程序,然后程序会将这些恶意数据存储到目标堆栈缓冲区中。结果目标堆栈上的数据就会被覆盖。如果函数返回地址被恶意代码所覆盖,那当函数返回时,函数的控制权便会转移给包含攻击者数据的恶意代码中。
strcpy()、strcat()等,由于没有对字符串进行长度检查,是被禁止使用的,应使用strcpy_s等安全版本函数来进行替代。\0结束符写入数组的位置,添加结束符时可能导致写溢出。memcpy_s不能操作重叠内存,memmove_s可以。格式化缺陷的风险(参数类型不匹配、数目不匹配)
举例:
%n 用于把前面打印的字符数记录到一个变量中,也用于统计格式化的字节数,这需要一个空间来存储这个数字。结合%p以用户的输入来构造格式化字符串来打印内存,构造恶意代码。%s、%d等符号作为控制台输入参数传入入参,达到改变入参个数目的。正确使用安全函数:
典型错误:
整数操作不当的场景:
uintptr表示指针的整数类型整数操作不当的风险:
5. 内存分配出错。
6. 执行任意代码:整数溢出错误,可导致内存破坏,并可能被用于执行任意代码。
7. 有符号整数溢出->影响符号位,无符号整数反转->最高位进退位失效(回绕)。
无符号操作数的计算不会溢出,因为结果不能被无符号类型表示的时候,就会对比结果类型能表示的最大值加一再执行求模操作。

两数相乘溢出问题:将两个32位的int型相乘,将结果赋值给long型变量。
long a = 111111 * 111111;
分析:对于编译器来说,int和int相乘,结果也是先存在int中,跟被赋给long或long long数据类型字段没有关系。
解决:想要不溢出,就要把两个32位数强转为long类型,再相乘。


典型错误:
alloca函数申请内存:alloca()不具备平台适用性,且在栈上申请内存,可能大小越界。realloc函数调整内存大小。不安全函数:
creatProcess函数或POSIX的exec系列替代或使用硬编码的函数或对外部输入中的命令分隔符进行过滤、转义)strtok、printf和 cout 混用。 2.信号处理程序中的使用异步不安全函数:IO函数,自定义的异步不安全函数。printf和 cout 混用错误:
printf没有缓冲区, cout 有),而且对于标准输出的加锁时机也略有不同(printf对标准输出做任何处理前加锁, cout 在实际向标准输出打印时方才加锁)。std::cout的标准流输出时带有缓冲区的,如果没有及时清理缓冲区而在期间采用了其他系统的输出函数,可能会暴露两种输出函数的不兼容,从而出现非预期的错误。


目录遍历
利用目录穿越进行“权限突破”。
典型问题:
典型错误:输入文件路径没有进行标准化。
说明:1. 打开外部文件时,需要对文件路径进行标准化(转换为绝对路径),确保打开的文件是符合预期的。如果必要使用相对路径(比如对应用安装目录不确定),需要对文件中特殊字符进行过滤,如果“.” 和 “/”。
2. 内部文件名最好能硬编码参数到应用程序中。如果出于更高的安全要求,需对文件的完整性进行校验。
敏感信息处理:session ID、明文口令、密钥。
任何一个进程(init除外)在exit()之后并非马上消失,而是留下一个成为Zombie的数据结构,等待父进程处理,这是每个子进程结束时都要经历的过程。若子进程exit后,父进程没有及时处理,使用PS命令可以看到子进程的状态是’Z’。
补救方法:杀死僵尸进程的父进程,让Init进程回收清理(此时僵尸进程变成孤儿进程)
*(ptr-1) 的值int a[5] = {1, 2, 3, 4, 5};
int *ptr = (int *)(&a+1);
&a是对象(整个数组)首地址,&a+1是下个对象的地址,所以*(ptr-1)是a[4]=5。
a与&a的地址是一样的,但意义不同。 *(a+1)=a[1]=2,*(&a+1)=a[5]。
设计原则:
观察者模式(订阅模式):被观察对象状态改变,所有观察它的对象得到通知。被观察者不依赖观察者,通过依赖注入达到控制反转。
事件
通知:事件发生后,通知所有这个事件的对象。与观察者模式相比,可理解成所有对象都只以来事件系统。一半对象观察事件系统,等待特定通知;一般对象状态变化就通过事件系统发出事件。
观察者也不依赖被观察对象,他只关心事件,不需要到被观察对象那儿注册自己。
被观察者也只是普通对象,状态改变,通过事件系统发出事件就行了。
消息队列:将消息排成队列,逐步分发通知。
与事件通知对比,可理解成事件不是立即通知,而是保存到队列里,稍后通知。这个可以达到时间解耦的效果。Windows的消息循环就是一个应用。多线程情况下,消息队列优先于事件系统。
1. 观察者模式
以上课铃声为例子。上课铃声响,同学们回教室。
class 上课铃{
function 响()
for 学生 in 学生们 do
学生->回教室()
end
end
}
这样写有问题:
class 学生{
function update()
if 上课玲响 then
回教室()
end
end
}
这样上课铃只管按时响就行了,也有问题:
class 上课铃: Subject{
function 响()
NotifyObservers()
end
}
class 学生: Observer{
function init()
上课玲->AddObserver(this.回教室)
end
function 回教室() ... end
function un_init()
上课玲->RemoveObserver(this.回教室)
end
}
这样,上课铃只要响的时候发个通知,学生们就等通知好了。老师也类似,等通知就行了。
小结:
2. 事件系统
观察者模式有两个问题:
上课铃的例子里,学生只关心铃声,不关心上课铃这个物体。用事件模式就可以换个写法
class 事件系统{
function register(事件类型, handle);
function remove(事件类型, handle);
function trigger(事件类型, 数据);
}
class 上课铃{
function 响()
事件系统->trigger("上课铃声")
end
}
class 学生{
function init()
事件系统->register("上课铃声", this->回教室)
end
function 回教室() ... end
function un_init()
事件系统->remove("上课铃声", this.回教室)
end
}
小结:
3. 消息队列
消息队列和事件系统很像。但是消息队列不是立即通知,而是把消息先放到队列里再通知。
上课铃的例子:
class 消息队列{
function register(消息类型, handle);
function remove(消息类型, handle);
function sendMsg(消息);
function process();
}
class 上课铃{
function 响()
消息队列->sendMsg("上课铃声")
end
}
class 学生{
function init()
消息队列->register("上课铃声", this->回教室)
end
function 回教室() ... end
function un_init()
消息队列->remove("上课铃声", this.回教室)
end
}
main{
while(有消息) do
消息队列->process()
end
}
从伪代码也可以看出,消息队列和事件系统的使用基本是一样的。如果消息队列不延后处理,就是事件系统了。
消息队列可以用于多线程,接受处理消息的handle们在主线程里。发送消息的可以在其他线程里。
简单总结
上下文:“当前场景”、变量、对象都有作用域,上下文不仅指作用域,就算再相同作用域下也会因为当前程度的其他变量不同而不同的表现。
为什么那么多框架都设计有上下文?(把所有环境上的东西都挂在到context,有点类似与全局变量的作用?)
为什么有上下文这种概念? ——参考文献
处理器总是处于以下状态的一种:
系统的两种不同运行状态,才有了上下文的概念。用户空间的应用程序,如果想请求系统服务,比如操作某个物理设备,映射设备的地址到用户空间,必须通过系统调用来实现。(系统调用是操作系统提供给用户空间的接口函数)。
通过系统调用,用户空间的应用程序就会进入内核空间,由内核代表该进程运行于内核空间,这就涉及到上下文的切换,用户空间和内核空间具有不同的 地址映射,通用或专用的寄存器组,而用户空间的进程要传递很多变量、参数给内核,内核也要保存用户进程的一些寄存器、变量等,以便系统调用结束后回到用户空间继续执行。
进程上下文:
线程上下文:当进程只有一个线程时,可以认为进程等于线程,拥有多个线程,共享相同的虚拟内存和全局变量等资源,这些资源在上下文切换无需修改,只需切换线程的私有数据寄存器等不共享的数据。
操作系统必须对上面提到的全部信息进行切换,新调度的进程才能运行。而系统调用进行的是模式切换(mode switch)。模式切换与进程切换比较起来,容易很多,而且节省时间,因为模式切换最主要的任务只是切换进程寄存器上下文的切换。
中断上下文:
事实上,对于A进程希望等待的中断信号,可能在B进程执行期间发生。例如,A进程启动写磁盘操作,A进程睡眠后B进程在运行,当磁盘写完后磁盘中断信号打断的是B进程,在中断处理时会唤醒A进程。
进程上下文 VS 中断上下文
reentrant(可被并行或递归调用的例程):因为中断发生时,preempt和irq都被disable,直到中断返回。所以中断上下文和进程上下文不一样,中断处理例程的不同实例,是不允许在SMP上并发运行的。原子上下文
#define in_irq() (hardirq_count()) 在处理硬中断中#define in_softirq() (softirq_count()) 在处理软中断中#define in_interrupt() (irq_count())在处理硬中断或软中断中#define in_atomic() ((preempt_count() & ~PREEMPT_ACTIVE) != 0) 包含以上所有情况spin_lock/spin_unlock修改,或程序员强制修改,同时表明内核容许的最大抢占深度是256。8-15位是软中断计数,通常由local_bh_disable/local_bh_enable修改,同时表明内核容许的最大软中断深度是256。16-27位是硬中断计数,通常由enter_irq/exit_irq修改,同时表明内核容许的最大硬中断深度是4096。第28位是PREEMPT_ACTIVE标志。用代码表示就是:
PREEMPT_MASK: 0x000000ff
SOFTIRQ_MASK: 0x0000ff00
HARDIRQ_MASK: 0x0fff0000
凡是上面4个宏返回1得到地方都是原子上下文,是不容许内核访问用户空间,不容许内核睡眠的,不容许调用任何可能引起睡眠的函数。而且代表thread_info->preempt_count不是0,这就告诉内核,在这里面抢占被禁用。
对于in_atomic()来说,在启用抢占的情况下,它工作的很好,可以告诉内核目前是否持有自旋锁,是否禁用抢占等。但是,在没有启用抢占的情况 下,spin_lock根本不修改preempt_count,所以即使内核调用了spin_lock,持有了自旋锁,in_atomic()仍然会返回 0,错误的告诉内核目前在非原子上下文中。所以,凡是依赖in_atomic()来判断是否在原子上下文的代码,在禁抢占的情况下都是有问题的。
编译选项(gcc)
gcov 是 Linux 下进行代码覆盖测试的工具
lcov 是 gcov的图形化前端工具,根据gcov生产的内容,处理一颗完整的html树,包括概括覆盖率百分比,图标等轻便直观内容。
GDB调试:
cmakelist.txt : add_subdirectory(…) 将子目录添加到构筑中。
OOPS :不是首字母缩写词,它不代表“object-oriented programming and systems” or “out of procedural specs”;实际上,它的意思是“哎呀”,就像您刚踩到猫一样。糟糕!“ oops”的复数形式是“ oopses”。
oops表示系统上运行的某些内容违反了内核有关适当行为的规则。也许代码试图采用不允许的代码路径或使用了无效的指针。无论是什么,内核(总是在寻找进程异常的内核)很可能会停止其进程中的特定进程,并向控制台/ var / log / dmesg或/var/log/kern.log file中写入一些有关该进程的消息。 what-is-a-linux-oops
OOM(out of memory killer):在linux中内核内存是有限的,而为了最大限度的利用内存采用了分页的机制,进程被分配虚拟地址空间,虚拟地址空间映射真实的物理内存。
但是进程数据并不是全部加载到物理内存中的(写时复制),只有当用户访问的数据页不在物理内存中,通过请页机制进行加载数据到物理页。
踩内存:对不属于你的内存进行读写
魔术字(magic number):魔术字一般是指硬写到代码的整形常量数值,是编程者自己指定的,其他人不知道数值有什么具体意义。编程教程书用magic number指代初学者不定义常量直接写数的不良习惯。
断言(Assert)与 异常(exception)
浅析Linux中的.a、.so、和.o文件 ——参考文章
.o是目标文件,相当于windows中的.obj文件。当程序要执行时还需要链接(link).链接就是把多个.o文件链成一个可执行文件。.so为共享库,是shared object,用于动态连接的,相当于windows下的dll,是Linux中的可执行文件(MAC平台时dylib)。.a为静态库,说白了就是一堆.o合在一起,用于静态连接,效果和.o是一样的。文件的执行:
FILE *fp = fopen("vmlinux.bin", "rb");
fread(VMLINUX_START, 1, VMLINUX_SIZE, fp);
((void (*)(void))VMLINUX_START)();
现在知道了吧,uboot和Linux kernel启动的时候是没有ELF Loader的,所以烧在flash上的文件只能是raw binary格式的,即镜像文件image。

文件的转换:——参考文章
CC=ppc-gcc
LD=ppc-ld
OBJCOPY=ppc-objcopy
$(CC) -g $(CFLAG) -c boot.S
#先将boot.S文件生成boot.o
$(LD) -g -Bstatic -T$(LDFILE) \
-Ttext 0x12345600 boot.o \
--start-group -Map boot.map -o boot.elf
#再将boot.o生成boot.elf
$(OBJCOPY) -O binary -R .note -R .comment -S boot.elf boot.bin
#接着将 boot.elf 转换为 boot.bin
#使用 -O binary (或--out-target=binary) 输出为原始的二进制文件
#使用 -R .note (或--remove-section) 输出文件中不要.note这个section,缩小了文件尺寸
#使用 -S (或 --strip-all) 输出文件中不要重定位信息和符号信息,缩小了文件尺寸
编译完uboot后生成:
u-boot ELF文件可用来调试
u-boot.bin BIN文件用来烧在Flash上
编译linux生成:
vmlinux ELF文件可用来调试
vmlinux.bin BIN文件,没直接用过
zImage/vmlinuz/bzimage
将vmlinux.bin压缩,并加上一段解压代码得到的,不可和bootloader共存?
uImage
uboot专用的内核镜像,在zImage前加了一个64字节的头,描述内核版本、加载地址
生成时间,文件大小等等。 其0x40后的内容和zImage一样
它是由uboot的工具mkImage生成的。
uImage相对于zImage的优点在于:uImage可以和uboot共存。


前提:内存碎片
实质:“分离适配”,即将内存按2的幂次划分,相当于分离出若干块大小一致的空闲链表,搜索该链表并给出同需求最佳匹配的大小。
其优点是快速搜索合并(O(logN)时间复杂度)以及低外部碎片(最佳适配best-fit);其缺点是内部碎片,因为按2的幂划分块,如果碰上66单位大小,那么必须划分128单位大小的块。但若需求本身就按2的幂分配,比如可以先分配若干个内存池,在其基础上进一步细分就很有吸引力了。 ——参考文章
分配内存步骤:
释放内存:

后面的,B,C,D都这样,而释放内存时,则会把相邻的块一步一步地合并起来(合并也必需按分裂的逆操作进行合并)。我们可以看见,这样的算法,用二叉树这个数据结构来实现再合适不过了。酷壳_伙伴分配器的一个极简实现

在分配阶段,首先要搜索大小适配的块,假设第一次分配3,转换成2的幂是4,我们先要对整个内存进行对半切割,从16切割到4需要两步,那么从下标[0]节点开始深度搜索到下标[3]的节点并将其标记为已分配。第二次再分配3那么就标记下标[4]的节点。第三次分配6,即大小为8,那么搜索下标[2]的节点,因为下标[1]所对应的块被下标[3~4]占用了。
在释放阶段,我们依次释放上述第一次和第二次分配的块,即先释放[3]再释放[4],当释放下标[4]节点后,我们发现之前释放的[3]是相邻的,于是我们立马将这两个节点进行合并,这样一来下次分配大小8的时候,我们就可以搜索到下标[1]适配了。若进一步释放下标[2],同[1]合并后整个内存就回归到初始状态。
遗传算法是计算数学中用于解决最优化的搜索算法,是进化算法的一种。 跳转
Acronyms and abbreviations(缩略语)
AT (acceptance test)验收测试
BCC(Basic Conformance Class)基本一致性等级
BSW(Basic Software)基础软件
AutoSar(Automotive Open System Architecture)汽车开放系统架构
CI(Continuous instegration)持续集成
CRC (cyclic Redandancy check) 循环冗余校验
E2E(end to end) 测试流程(黑盒测试的一种)
ECC (Extended conformance clasee)扩展一致性等级
ECU(Electronic Control Unit)电子控制单元
EM (execution management)执行管理
FT (functional test)功能测试
HW(HardWare)硬件
IOC (Inter OS-Application communicator)应用程序通信器
ISR(Interrupted Service Routine)中断服务程序
IT (integration test)集成测试
LE(Locatable entity)可定位实体
MC(Multi-core)多核
MCU(Micro-controller Unit)微控制器
MMU(Memory Management Unit)内存管理单元
MPU(Memory Protection Unit)存储保护单元
OIL (OSEK Implementation Language)OSEK实施语言
OSA(Operating System Rountine)中断服务程序
OSEK(Open System and the corresponding interfances for automotive electronics)德国汽车电子类开放系统和对应接口标准
OSPF(Open Shortest PathFirst)开放式最短路径优先
PL - 项目组长 SE - 系统工程师 PG - 程序员 PM - 项目经理
Posix(portable operator system Interface)可以指操作系统接口
Pub(publisher)发布者,Sub(subscriber)订阅者
QM(质量标准证书)
ROS(Remote OPeration Service)远程操作服务
RPC(Remote Procedure Call)远程程序调用
RTE(Run-Time Environment)运行时环境
RTP(Real-Time Transport Protocol)实时传输协议(传输流媒体)
RTPS(Real-Time Programming System)实时编程系统
RTSP(Real-Time Transport control Protocol)实时传输控制协议(控制RTP)
DHCP(Dynamic Host Configuration Protocol)动态主机设置协议
SOAP(Simple Object Access Protocol)简单对象访问协议
SC(Single-core)单核
SLA(Software Layer Architecture)软件层架构
SR (service Router)业务路由器
ST (system test)系统测试
SWC(Software component)软件组件
SWFRT(Software Free Running Timer)软件运行时
UT (Unit test)单元测试
VDE(Vehicule Distributed Executive)车载分布式执行器
奇偶校验码(parity bit / check bit)
海明校验码(Hamming Code)

