目录
1 参数
2 算例实现
2.1 算例
2.2 单目标预测-DecisionTreeRegressor
2.3 多目标预测MultiOutputRegressor
1 参数

n_estimators:森林中决策树的数量。默认100
表示这是森林中树木的数量,即基基评估器的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators越大,模型的效果往往越好。但是相应的,任何模型都有决策边界,n_estimators达到一定的程度之后,随机森林的精确性往往不在上升或开始波动,并且,n_estimators越大,需要的计算量和内存也越大,训练的时间也会越来越长。对于这个参数,我们是渴望在训练难度和模型效果之间取得平衡。
criterion:分裂节点所用的标准,可选“gini”, “entropy”,默认“gini”。
max_depth:树的最大深度。如果为None,则将节点展开,直到所有叶子都是纯净的(只有一个类),或者直到所有叶子都包含少于min_samples_split个样本。默认是None。
min_samples_split:拆分内部节点所需的最少样本数:如果为int,则将min_samples_split视为最小值。如果为float,则min_samples_split是一个分数,而ceil(min_samples_split * n_samples)是每个拆分的最小样本数。默认是2。
min_samples_leaf:在叶节点处需要的最小样本数。仅在任何深度的分割点在左分支和右分支中的每个分支上至少留下min_samples_leaf个训练样本时,才考虑。这可能具有平滑模型的效果,尤其是在回归中。如果为int,则将min_samples_leaf视为最小值。如果为float,则min_samples_leaf是分数,而ceil(min_samples_leaf * n_samples)是每个节点的最小样本数。默认是1。
min_weight_fraction_leaf:在所有叶节点处(所有输入样本)的权重总和中的最小加权分数。如果未提供sample_weight,则样本的权重相等。
max_features:寻找最佳分割时要考虑的特征数量:如果为int,则在每个拆分中考虑max_features个特征。如果为float,则max_features是一个分数,并在每次拆分时考虑int(max_features * n_features)个特征。如果为“auto”,则max_features = sqrt(n_features)。如果为“ sqrt”,则max_features = sqrt(n_features)。如果为“ log2”,则max_features = log2(n_features)。如果为None,则max_features = n_features。注意:在找到至少一个有效的节点样本分区之前,分割的搜索不会停止,即使它需要有效检查多个max_features功能也是如此。
max_leaf_nodes:最大叶子节点数,整数,默认为None
min_impurity_decrease:如果分裂指标的减少量大于该值,则进行分裂。
min_impurity_split:决策树生长的最小纯净度。默认是0。自版本0.19起不推荐使用:不推荐使用min_impurity_split,而建议使用0.19中的min_impurity_decrease。min_impurity_split的默认值在0.23中已从1e-7更改为0,并将在0.25中删除。
bootstrap:是否进行bootstrap操作,bool。默认True。如果bootstrap==True,将每次有放回地随机选取样本,只有在extra-trees中,bootstrap=False
oob_score:是否使用袋外样本来估计泛化精度。默认False。
n_jobs:并行计算数。默认是None。
random_state:控制bootstrap的随机性以及选择样本的随机性。
verbose:在拟合和预测时控制详细程度。默认是0。
class_weight:每个类的权重,可以用字典的形式传入{class_label: weight}。如果选择了“balanced”,则输入的权重为n_samples / (n_classes * np.bincount(y))。
ccp_alpha:将选择成本复杂度最大且小于ccp_alpha的子树。默认情况下,不执行修剪。
max_samples:如果bootstrap为True,则从X抽取以训练每个基本分类器的样本数。如果为None(默认),则抽取X.shape [0]样本。如果为int,则抽取max_samples样本。如果为float,则抽取max_samples * X.shape [0]个样本。因此,max_samples应该在(0,1)中。是0.22版中的新功能。
2 算例实现
2.1 算例
熔喷非织造材料是口罩生产的重要原材料,具有很好的过滤性能,其生产工艺简单、成本低、质量轻等特点,受到国内外企业的广泛关注。但是,由于熔喷非织造材料纤维非常细,在使用过程中经常因为压缩回弹性差而导致其性能得不到保障。因此,科学家们创造出插层熔喷法,即通过在聚丙烯(PP)熔喷制备过程中将涤纶(PET)短纤等纤维插入熔喷纤维流,制备出了“Z型”结构的插层熔喷非织造材料。插层熔喷非织造材料制备工艺参数较多,参数之间还存在交互影响,加上插层气流之后更为复杂,因此,通过工艺参数(接收距离和热空气速度)决定结构变量(厚度、孔隙率、压缩回弹性),而由结构变量决定最终产品性能(过滤阻力、过滤效率、透气性)的研究也变得较为复杂。如果能分别建立工艺参数与结构变量、结构变量和产品性能之间的关系模型,则有助于为产品性能调控机制的建立提供一定的理论基础。请查阅相关文献,了解专业背景,研究题目数据
,回答下列问题:
问题:请研究工艺参数与结构变量之间的关系。表1给了8个工艺参数组合,请将预测的结构变量数据填入表1将图画为表格形式中。

2.2 单目标预测-DecisionTreeRegressor
这里以单目标预测为例,使用决策树进行预测,只预测压缩回弹性率:
import pandas as pd
from sklearn.tree import DecisionTreeRegressor#决策树
#第一步正常读取数据:
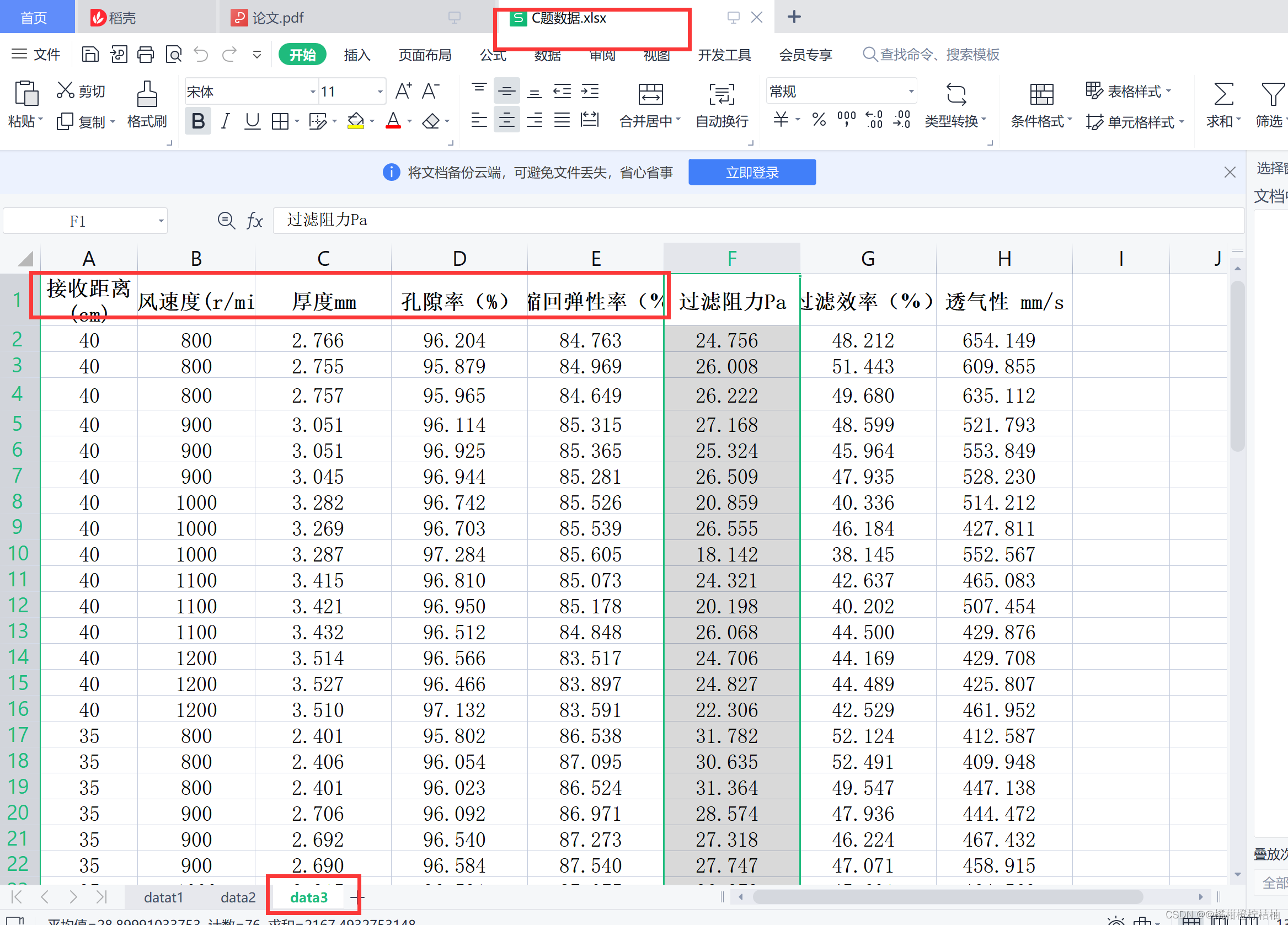
data=pd.read_excel('C题数据.xlsx',sheet_name=2)
chuli=data.iloc[:,:5]
chuli.columns=['接收距离','热风速度','厚度','孔隙率','压缩回弹性率']
#chuli
#第二步:提取变量
X=chuli.drop(['压缩回弹性率','孔隙率','厚度'],axis=1)
y=chuli['压缩回弹性率']
#X
#第三步:分割数据
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(X, y, test_size= 0.2, random_state=0)
#第四步:建立决策树模型、训练模型
model= DecisionTreeRegressor(max_depth=2) # 设树深度为2
dtr_fit = model.fit(x_train, y_train)
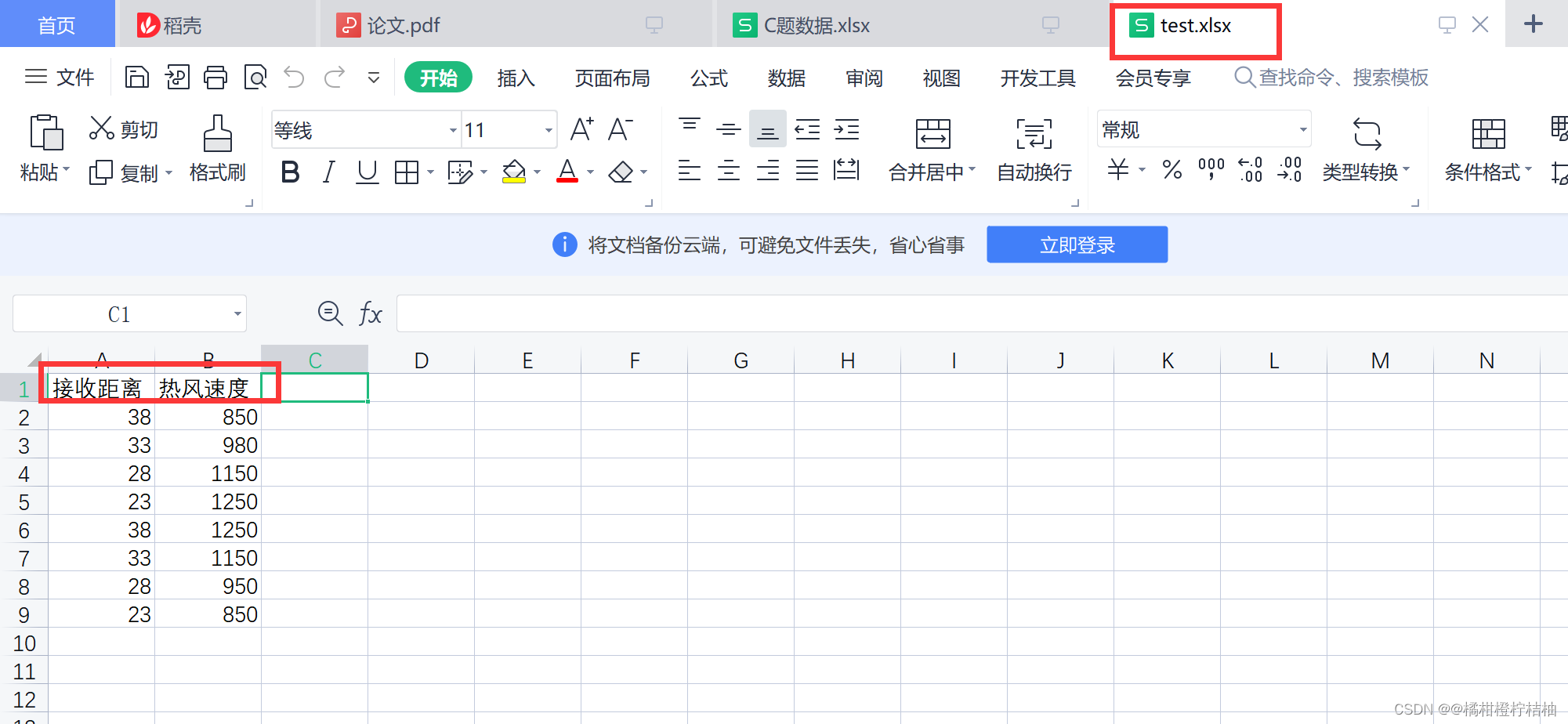
#第五步:读取我们需要预测的数据,整理好了自己下载:test.xlsx
test1=pd.read_excel('test.xlsx')
#test1
#第六步:使用训练好的模型预测数据
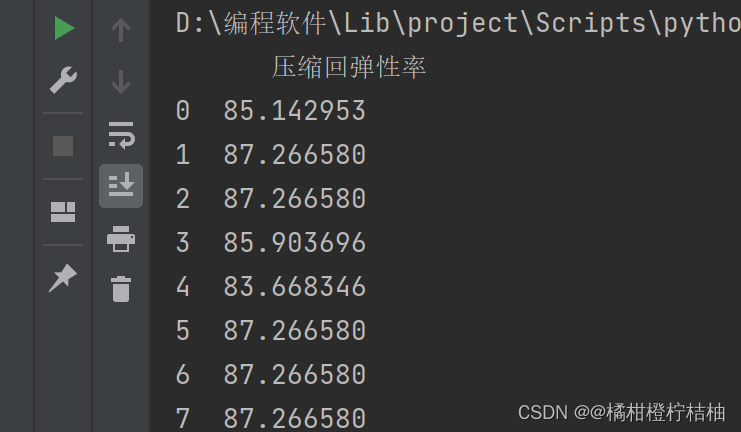
ya=dtr_fit.predict(test1)
print(pd.DataFrame(ya,columns=['压缩回弹性率']))
 结果:
结果:
2.3 多目标预测MultiOutputRegressor
这就是单目标预测的实现,下面再试试多输入多输出,就是一次性全部预测出来。接着上面代码,现在,让我们使用 MultiOutputRegressor预测压缩回弹性率','孔隙率','厚度’
有些时候 我们需要通过相同的feature来预测多个目标,这个时候就需要使用MultiOutputRegressor包来进行多回归。
import pandas as pd
from sklearn.tree import DecisionTreeRegressor#决策树
#第一步正常读取数据:
data=pd.read_excel('C题数据.xlsx',sheet_name=2)
chuli=data.iloc[:,:5]
chuli.columns=['接收距离','热风速度','厚度','孔隙率','压缩回弹性率']
#chuli
#第二步:提取变量
X=chuli.drop(['压缩回弹性率','孔隙率','厚度'],axis=1)
y=chuli['压缩回弹性率']
#X
#第三步:分割数据
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(X, y, test_size= 0.2, random_state=0)
#第四步:建立决策树模型、训练模型
model= DecisionTreeRegressor(max_depth=2) # 设树深度为2
dtr_fit = model.fit(x_train, y_train)
#第五步:读取我们需要预测的数据,整理好了自己下载:test.xlsx
test1=pd.read_excel('test.xlsx')
#test1
#第六步:使用训练好的模型预测数据
ya=dtr_fit.predict(test1)
print(pd.DataFrame(ya,columns=['压缩回弹性率']))
#display(pd.DataFrame(ya,columns=['压缩回弹性率']))
#第七步:重新读取变量值
X2=chuli.drop(['压缩回弹性率','孔隙率','厚度'],axis=1)
y2=chuli[['压缩回弹性率','孔隙率','厚度']]
#y2
#第八步:对提取到的数据做分割
from sklearn.model_selection import train_test_split
x_train2, x_test2, y_train2, y_test2= train_test_split(X2, y2, test_size= 0.2, random_state=0)
#第九步:采用对输入多输出模型,结合XGBoost算法模型进行训练(如果你觉得效果不够好,自行修改XGBoost参数)
from sklearn.multioutput import MultiOutputRegressor
from xgboost import XGBRegressor
mor = MultiOutputRegressor(XGBRegressor(objective='reg:linear'))
mor.fit(x_train2, y_train2)
#mor
#第十步:预测
pre=mor.predict(test1)
print(pd.DataFrame(pre,columns=['压缩回弹性率','孔隙率','厚度']))
结果:
