前言
这是沐神的第十节课。是讲多层感知机的,需要掌握牢固。以后会经常写的
代码讲解
跳过从零开始实现,直接进入简单代码的讲解
# 导入包
import torch
from torch import nn
from d2l import torch as d2l # 这个包是沐神自己写的,里面的方法前面都有讲过
net = nn.Sequential(nn.Flatten(), # 把图片展平,将输入数据展平,这里只保留第0维度
nn.Linear(784, 256), # 第一层
nn.ReLU(), # 激活
nn.Linear(256, 10)) # 第二层
def init_weights(m): # 初始化参数
if type(m) == nn.Linear: # 如果是Liner则。。。。。(因为后面有的不是Liner)
nn.init.normal_(m.weight, std=0.01) # m.weight未初始化之前是0
net.apply(init_weights) # 网络的每一层的权值都进行初始化
batch_size, lr, num_epochs = 256, 0.1, 10 # 一些超参数
loss = nn.CrossEntropyLoss(reduction='none') # 交叉熵损失函数
trainer = torch.optim.SGD(net.parameters(), lr=lr) # 训练器,也就是优化器,选择随机梯度下降
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) # 前面有讲过,是yeild小批量
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer) # 开始训练
d2l.plt.show() # 显示训练进程
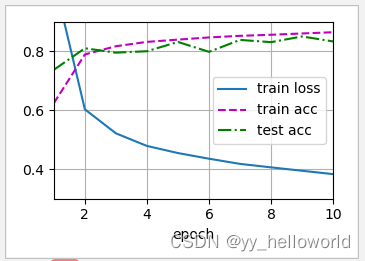
第11课的内容
训练误差:模型在训练数据上的误差
泛化误差:模型在新数据上的误差
训练数据集:训练模型(比如平时做的习题)
验证数据集:验证模型好坏(比如平时的考试)
测试数据集:只用一次的数据集(比如高考)
K-则交叉验证:当数据集不大的时候使用
过拟合、欠拟合
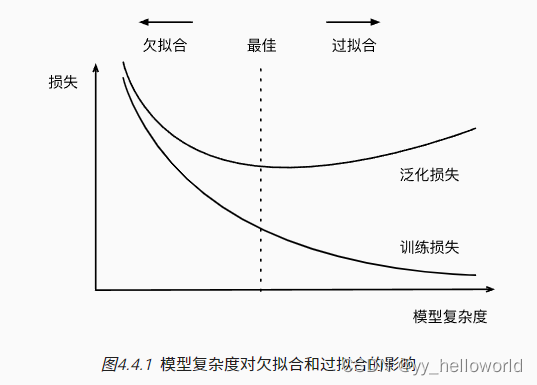
数据复杂度:样本个数、每个样本的元素个数、时空结构、多样性
第12课的内容
正则化:限制w的权重,防止过拟拟合
第13课的内容
丢弃法:dropout
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1 # assert:在不满足条件下,可以直接报错
# 在本情况中,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X) # 像x的shape一样的都是0的元素
# 在本情况中,所有元素都被保留
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float()
return mask * X / (1.0 - dropout) # 没有dropout的数据变大
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training == True:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
d2l.plt.show()
第14课的内容
数值稳定性
将每层的输出和梯度都看做随机变量,让他们的均值和方差保持一致