复旦邱锡鹏组最新综述:A Survey of Transformers
A Survey of Transformers
Transformers已经在人工智能诸多领域,如NLP.CV,声音处理等方面取得进展,也受到学术界和工业界的广泛关注。目前也已经提出了一系列Transformer的变体,称之为X-Formers,但是却没有对这些X-formers进行系统、全面的综述文章。因此本文对这方面的工作进行综述,本文从三个方面对这些变体进行介绍,分别是:结构改进、预训练和应用。最终,为下一步的研究提出一些可考虑的方向。
Section I Introduction
Transformer是一种广泛应用于诸多领域的深度学习模型,如自然语言处理、计算机视觉和语音处理。Transformer最初作为一种用于机器翻译的序列模型,后来的研究表明,基于Transformers的一系列预训练模型在不同任务中均取得了SOTA,因此Transformer已经成为NLP中尤其是PTM中首选的模型;还在计算机视觉、语音处理甚至如化学、生命科学等领域得到了应用。
由于Transformers获得的巨大成功,近年来提出了一系列Transformers的变体,从不同方面对原始的Transformer进行了改进。
(1)模型的效率。限制Transformer的一个关键原因是在处理长序列时自注意力模块计算和内存的复杂度。改进的方法包括轻量级注意力(如稀疏注意力)和分治法(采用循环和分层的思想)。
(2)模型的泛化性。鉴于Transformer结构很灵活,假定输入数据的偏差很小,因此难以在小规模数据集上训练。改进的方法包括引入结构偏差或加入正则化、对大规模无标记数据的预训练等。
(3)模型的适应性。这一类工作主要聚焦于将Transformer应用于特定的下游任务。
本文将对Trnasformer及其变体进行较为全面的综述。尽管本文可以按照对Transformer的改进来介绍X-Formers,但是许多变体聚焦于以上一个或几个问题。 比如sparse attention系数注意力不仅仅降低了计算复杂度,还缓解了小规模数据集的过拟合问题。
因此本文按照变体们改进Transformer的方式:结构改进预训练还是应用来组织全文。
鉴于读者所处领域的多样性,本文主要聚焦于对Transformer的结构改进,并简要介绍在预训练和一些应用中的特定改进。
文章其余内容包括:Sec2介绍了Transformer的结构和关键部分;Sec3介绍了Transformer的变体;Sec4-5介绍模块级别的改进,如注意力模块、位置编码模块、层归一化、前馈网络层;Section 6介绍整体结构层面上的改进;Sec7介绍一些具有代表性的基于Transformer的预训练网络;Sec8介绍了Ttransformer在不同领域的应用情况;Sec9对一些有趣、有前景的方向进行了讨论并总结全文。
Section II Background
Part I Transformer
原始的Transformer是一个seq2seq模型,包括编码和解码部分,每一部分都堆叠了L个相同个模块。
在Encoder部分,每一个block内主要包括一个多头自注意力模块(multi-head self-attention)和一个位置相关前馈网络(position-wise feed-forward network)。借助残差连接可以搭建层次更深的模块。
在Decoder部分,每一个block内在multi-head self-attention 和FFN之间插入落入一个人交叉注意力模块(cross-attention module);此外还在decoder block使用mask保证结果的因果性,防止将还未产生的后续结果影响当前结果。
Fig 1展示了Transformer的基本结构。

接下来本节将会介绍Transformer中的关键模块。
2.1.1Attention Modules
Transformer
通过计算Q-K-V矩阵引入注意力机制,首先对输入进行线性变换,获得三个不同的Q,K,V:
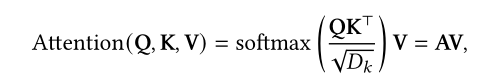
Q:Query
K:Key
V:Value
其中Q,K先进行匹配,计算(dor product)出的结果与V进行计算,获得注意力系数α,最后经过softmax获得最终输出A(attention Matrix)。
其中N,M分别代表Q和K的长度,D代表维度信息;以及除以维度是为了减轻梯度消失问题。
此外,Transformer使用的是多头注意力,即进一步将K,Q,V拆分成多个矩阵进行学习,类似多通道的思想,每一个head关注的点都是不一样的。
因此表述为:

Transformer中使用了三种注意力机制,分别是:
(1)Self-attention。
在Transformer的encoder部分设置为Q=K=V=X,X则是前一时间步的输出
(2)带mask的self-attention
在Transformer的decoder部分,使用的是带mask的sekf-attention,从而使得query的计算只关注当前位置及之前的输入,主要通过一个mask 函数实现,对于当前位置之后的序列罩上mask。这种带mask的attention通常称之为自回归或因果注意力。
(3)cross attention交叉注意力。
在decoder部分会使用前一个序列的输出的query和key,以及对应encoder部分
2.1.2位置相关的前馈神经网络
position-wise FFN是一个全连接层会在每一个位置执行:
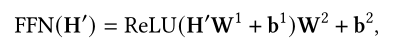
2.1.3Residual connection and Normalization
残差连接和正则化
Transformer在每一个模块进行layer normalization层归一化后使用了残差连接,从而可以搭建更深层次的网络。因此每一个encoder block的输出可以表述为:

2.1.4 Position Encodings
因为Transformer本身并不包含序列的顺序信息因此需要额外嵌入位置信息,这一部分将在sec5.1详细讲解。
Part II Model Usage
通常Transformer主要有以下三种使用方式:
(1)Encoder-Decoder 在序列模型中作为编码-解码结构使用,比如用来处理NLP
(2)Encoder 只是用其Encoder不问对输入序列进行编码,这种可以用来处理分类或序列标签问题
(3)Decoder 只是用Decoder部分,并且原来的cross-attention部分也被移除,主要用于序列生成,如语言简建模问题。
Part III Model Analysis
本文主要分析了Ttransformer两部分核心模块(self-attention和FFN)的复杂度和参数量。

其中T为输入序列长度,D为模型维度。结果如Table I所示。
当输入序列较短时(T)小,D占主要因素,因此计算瓶颈是FFN全连接层的计算;随着输入序列变长,T成为时间复杂度和参数量的主要影响因素。需要存储T*T的attention matrix,因此不适合处理超长序列。
因此可以想到,提升Transformer的效率主要是提升其自注意力对长序列的见同行,以及如何减少FFN部分的参数量和计算量。
Part IV 与其他网络的对比
Self-attention作为Transformer的核心部分,可以灵活的处理变长序列。可以将其看做是一个全连接层,其中权重由输入的序列关系动态生成。Table II展示了与常见一些网络层的对比,如每层的计算量、最长路径长度等。可以看到self-attention有以下优势:
(1)与FC层具有同样的最大路径长度,因此可以捕捉长程依赖关系,但是却比FC层参数量更小以及可以灵活地处理输入的长度;
(2)鉴于卷积层感受野范围有限,需要通过堆叠逐步扩大感受野;而self-attention可以通过固定的层数就建立全局的依赖关系;
(3)固定的序列操作和最长路径长度使得self-attention比RNN更易并行化。

此外,Transformer常与CNN和RNN进行比较,CNN通过权重共享实现平移不变性,RNN类似的基于Markovian结构传递了时间和空间的不变性,而Transformer并未对输入数据的结构做过多限定,因此Transformer结构更灵活,但一个副作用就是缺少结构信息使得Transformer在小规模数据集上的过拟合问题。
与Transformers密切相关的另一种网络是图神经网络GNN,Transformers可以看做是GNN的一种,其中每个输入都是图中的一个节点,二者的关键区别在于Transformer没有引入任何关于输入的先验知识,信息的传递仅仅依赖内容之间的相似性度量。
Section III Transformer的分类
Fig2按类别展示了Transformers的一些变体。有module-level,Arch-level,PTMs和Applications四方面。
Fig 3是不同分类下的具体内容。
本文主要聚焦于结构方面的改变,以及鉴于attention是Transformer的核心模块,因此本文在Sec4单独介绍attention相关的变体,其他变体在Sec5中介绍。


Section IV Attention
self-attention在Transformer中至关重要,但在实际应用中主要由以下两方面的挑战:
(1)复杂性
前文介绍了self-attention的时间复杂度,在处理长序列时self-attention就会成为瓶颈。
(2)结构的先验信息。self-attention没有考虑输入的位置信息,因此顺序信息也需要从训练数据中学习。
Transformer很容易在中小型规模数据上过拟合。
有以下改进方向:
(1)Sparse Attention
将稀疏性bias引入到注意力机制中,从而降低计算复杂度;
(2)Linearized Attention
在该系列工作中将注意力矩阵与特征图谱解耦,然后以逆序计算注意力,从而达到线性的时间复杂度。
(3)模型或内存压缩
这一类工作通过减少query或者k-v对从而减少attention matrix的大小。
(4)低秩self-attention
主要用于捕获self-atten的低秩特征
(5)带有先验知识的注意力
主要是探究如何补充或使用带有先验知识的注意力分布替换保准的注意力
(6)优化多头机制
主要探究不同的多头机制
Part 1 Sparse Attention
在原始的self-attention中每一个token都需要将其他token考虑在内,然而就会导致学习到的attention matrix较为稀疏。因此,可以通过合并一些结构bias或者减少k-v对的数目来降低计算的复杂度。
按照这种思路,只需要基于预定义的方法来计算k-v的相似性得分:
就可以获得未归一化的attention matrix;
另一方面,self-attention也可以看做是一个二分图,其中每一次query都会从参考所有节点的信息来更新自己的结果,sparse attention可以看做是移除了一些节点之间连接的稀疏图。
根据如何判定稀疏连接的指标,本文将sparse的方法分为两类:基于位置的稀疏注意力和基于内容的稀疏注意力。
1.1Position-base Sparse Attention
会根据预定义的规则限制attention matrix,虽然这些规则各不相同,但都可以分解为以下的一些原子操作(5种):
(1)global attention
为了减少attention对长程依赖关系建模的退化,可以在节点之间增加一些global node来增强信息传递,这些global node可包含所有节点信息,如Fig4(a)所示。
(2)band attention(如滑窗注意力、局部注意力)
由于大多数数据有很强的局部性,因此自然想到限定每一个query关注其临近节点,广泛采用的就是band attention,如Fig4(b)所示。
(3)Dilated Attention。参考空洞卷积,通过使用带有膨胀率的窗口不断扩大注意力的范围,这种方法还可以进一步扩展成为步长注意力,即窗口大小不做限制但是膨胀率设置为较大的值;
(4)Random attention。为了增强对一些非局部信息的捕捉,可以在每次query中随机采样。主要是基于一些观察到的结果,即随机图具有和常规图类似的特性但随机行走所需时间更短。
(5)Block Local Attention
这类注意力会将输入序列分割成几个无重叠的block,每一个block都与一个本地内存相关联,在计算query时也只是基于这一块的信息,细节参见Fig 4(e)

1.2 Compound Sparse Attention
现在的Sparse Attention通常包含上述一种或多种基本操作,Fig 5展示了一些具有代表性的sparse attention。

Star-Transformer联合使用了band attention和global attention,更细节是使用了一个全局节点和一个宽度为3的局部节点,因此任意一个节点通过全局节点相连,通过band attention与邻近接节点相连;这样在节点之间形成一个星形的图。
在Longformer中则融合了band attention和internal global node,其中global node用CLS标记,主要用于分类,而其他的question token主要用于question answering;Longformer中还将一些band attention 替换为了dialated window从而在不增加计算量的前提下扩大感受野。
在ETC中,ETC是Longformer的recurrent版本,则是使用了band attention和external global attention;
BigBird中则是使用了random attention来近似full attention.
以上工作的理论分析显示出使用sparse encoder和sparse decoder可以近似任何图灵机,这也解释了sparse model为什么有用。
1.3 Extended Sparse Attention
除了上述sparse attention,还有一些工作研究了对特定数据类型的sparse attention。
对于文本数据,BP-Transformer建立了一个二叉树结构,将所有token作为叶子结点,而internal node可以跨越多个结点,叶子结点也可以和更高层次或者其他结点相连,这种方式可以看做是global attention的一种扩展,在global attention中全局节点是分层组织的,架构图参见Fig 6(a)
对于图像数据,Image-Transformer探索了两种类型的注意力,分别是:
(a)block local sparse attention
局部块状稀疏注意力
(b)2D block local attention

而在Axial Transformer中则在每个轴上应用独立的注意力模块,即每个module沿着某一个轴融合信息。而保持信息沿其他轴是独立的,类似于垂直和水平扫描图像像素点然后分别对图像高度和宽度施加注意力。
1.4 Content Attention
另一类是基于输入的内容content决定稀疏的连接。
最直接的一种方法就是选择相似性分数很大的key进行稀疏。为了高效的计算出稀疏图,就是不断计算MIPS问题(最大内积搜索),也就是在不计算所有点乘项的前提下找到具有最大内积的key。
Routing Transformer使用的是k-means聚类,每次只对属于同一簇的key进行query;并在训练过程中不断更新中心点的坐标。
Reformer则是基于局部敏感哈希法(LSH)选择需要进行query的key,也就是每次只关注同一哈希值的key,而相似的key会被哈希到同一个桶中。
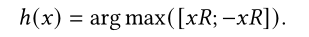
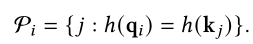
SAC(Sparse Adaptive Connection)将输入序列视作一张图,使用自适应稀疏连接学习边的连接关系从而达到最佳的性能;由于没有ground truth,因此是通过强化学习训练edge predictor。
Sparse Sinkhorn Attention则是将k,v分成不同block,并且给每一个query block分配一个key block.query只能和配对的key进行attention的计算;而key block的分配是由一个排序网络决定的,该网络使用Sinkhorn normalization来产生一个随机矩阵代表随机分配的结果。
Part 2 Linearized Attention
在Fig7(a)中显示self-attention中softmax的时间复杂度是序列长度T的平方,如果可以将softmax的计算分解到Q’K’TV中则可以将时间复杂度降到O(T).
Linearized Attention(线性化注意力)就是将Q,K按行拆分,对未归一化的的attention matrix进行近似或替换,从而使得计算可以线性化进行,如Fig 7(b)所示。

常规的注意力向量可以表示为:
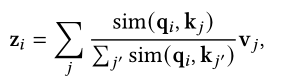
主要会计算q,k之间的相似性分数,通常使用的核函数为:
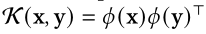
这样注意力向量就可以写作:
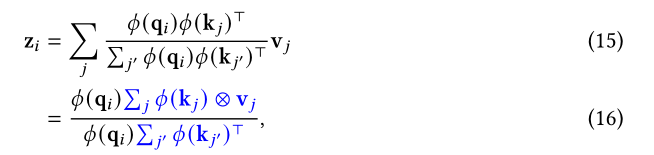
计算出的注意力系数会与v做外积。这种方式非常适合计算自回归注意力,因为累加和sum和v都可以在常数时间完成,从而使得Transformer的decoder部分可以像RNN一样运行。
可以这样理解quation 16:
transformer的attention实际是维护了一个memory matrix(记忆矩阵),该矩阵是通过聚合相关特征,即key和value的外积表征的不同feature得到的;随后将记忆矩阵乘以value并进行适当的归一化得到最后的输出。
这一方法包含关键的两部分:特征图谱(feature map)和聚合规则(aggregation rule)。
Feature Maps
特征映射的近似
Linear Transformer中使用了一种十分简易的feature map:
该特征图并不是dot product attention的近似,但是经验证明与标准的Transformer性能相当。
Performer中则是使用随机的feature map来近似Transformer中的得分函数(scoring function)。
这种方法灵感最初来源于使用随机傅里叶的featuremap近似高斯核函数,这种方法也被用于随机特征注意力(RFA)中。
虽然这种近似是一种无偏估计,但并不能保证注意力分数一定是非负的,因此容易有不稳定或异常的结果。
为了减轻这一问题,在第二版本的Performer中改进了h(x)函数,保证attention的计算结果一直是非负的,这样使得计算结果更加稳定。
performer version 1
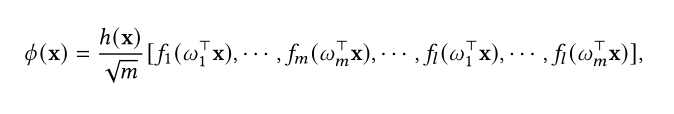
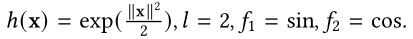
performer version 2
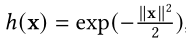
Aggregation Rule
聚合规则
一些研究参照Equation 16通过简单的求和获得最终的memory matrix,但是如果向网络中有选择的加入或舍弃一些关联被证明更加有效。
RFA(Random Feature Attention)中引入了一种门机制,向memory matrix中加入了序列数据的局部依赖信息,主要是通过加入一个标量(g)来表征输入依赖性,这样前序的依赖关系会以指数衰减的大小加入到当前的输入中。
还有的学者(Schlag)认为通过简单的加和 限制了memory matrix的能力,因此提出以write-and-remove写后移除的方式来提升memory matrix的能力具体实现时给定新的k-v对,会使用矩阵乘法先检索与当前k相关联的v的值。
Schlag:
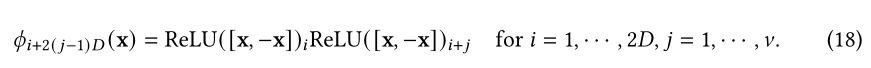
Part 3 Query Prototyping and Memory Compression
内存压缩
除了使用稀疏注意力或者使用线性注意力,还可以通过减少见识对的数量来降低attention的计算复杂度。
3.1 Attention with Prototype Queries
使用Query原型计算注意力
在Attention的计算中通常使用几种query的原型(模型)作为计算注意力分布的主要来源;要不然将分布复制到需要查询的位置,要么使用离散的均匀分布填充要查询的位置。
Fig 8(a)展示了query prototype的流程。

在Clustered Attention中将queries分成几簇,然后计算每一个聚簇中心的注意力分布;
在Informer中则是使用显式稀疏度量从queries选择一些原型,然后基于K-L散度得到注意力分布的近似,只计算注意力分布的top-k,其余则使用离散的均匀分布。
3.2 Attention with Compressed K-V Memory
使用压缩的K-V对计算Attention
除了通过query prototyping来减少q的数量,还可以通过减少k-v对的数目达到降低计算复杂度的目的,示意图参见Fig 8(b)。
在Memory Compressed Attention(MCA)这项工作中,通过带步长的卷积减少k-v的数量;同时也补充了global attention.这种方法可以将K-V数量减少kernel size(k),从而可以比原始的Transformer处理更长的序列。
在Set Transformer中则是通过加入一些外部可训练的节点作为对输入信息的总结,用这些总结的表征作为压缩后的内存表示,这种方法将attention的时间复杂度从T的平方降到线性。
在Linformer中则是使用投影的方法将长度为k的k,v投影到更小的维度,从而将self-attention降到线性复杂度。这种方法的局限性在于必须要事先知道序长度,因此无法适用于自适应注意力。
Poolingformer则使用了两级注意力,将滑窗注意力和压缩的memory注意力结合到了一起,compressed memory 模块位于滑窗注意力之后,主要用来增大感受野。研究发现通过池化可以减少k-v的数量。
Part 4 Low-rank Self-Attention
低秩注意力
通过理论或基于经验发现Transformer的self-attention matrix一般都是低秩的,这一特性透露出两方面的信息:一是这种低秩矩阵可以使用参数化的方式显式建模,二是self-attention 矩阵可以使用低秩近似。
4.1 Low-rank parameterization
因为self-attention matrix是低秩矩阵也就是矩阵的秩会小于序列长度。当输入序列较短的时候(维度D>T)容易产生过拟合现象,此时通过限制维度D,即将self-attention matrix分解成一个低秩注意力模块可以有效捕获长程的非局部的交互信息,再使用一个band attention用于捕捉局部依赖关系。
4.2低秩近似
对于self-attention matrix是低秩矩阵的另一种应用就是使用低秩近似来降低self-attention matrix的复杂性,常用的是使用核矩阵的低秩近似,也是受这一方法的启发有了前面random feature maps方面的优化工作。
比如Performer中使用随机傅里叶变换去近似高斯核函数;Nystrom则是对输入进行下采样(采用带步长的均值池化),选取m个节点然后近似计算self-矩阵。
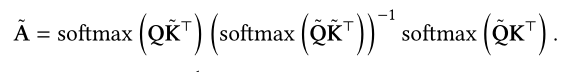
Part 5 先验注意力
注意力机制就是将预期的注意力的值通过加权和的形式算出,权重就是注意力分布。通常注意力分布是基于输入计算出来的,在Transformer中就是这么计算出来的。
而注意力分布还可以有其他来源,比如根据先验知识,基于先验知识计算出的注意力分布可以补充根据输入计算得到的注意力分布。

Fig 9展示了先验注意力如何辅助补充当前注意力分布。两种注意力分布的混合通常在进行softmax操作之前进行。
5.1模块位置先验
一些特定的数据类型如文本的位置信息十分关键,因此可以将位置信息设计成先验注意力。常用的就是对位置进行高斯分布建模,这样就对输入产生的注意力增加位置的先验知识。
比如在Gaussian Transformer中认为输入序列复合正态分布,即越靠近中心的权重越高,远离中心的权重越低。
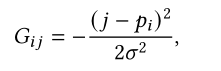
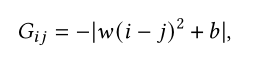
5.2底层模块先验
在Transformer中认为相邻层的注意力分布是相似的,因此自然会想到将前层的注意力分布作为先验知识加入到当前注意力的计算中,因此attention的计算公式可以表示为:
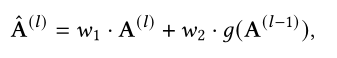
在Predictive Attention Transformer中提出对前层的attention score使用二维卷积处理,然后加入到当前层注意力的计算。
Realformer则是直接将前层的attention score加到当前层的注意力上,实验显示比BERT效果更好,对预训练的要求也降低了。
而Lazyformer则是更极端的情况,直接在相邻层中共享attention maps。也就是attention matrix计算一次后可以多次复用,从而显著降低计算成本。实验表明这种方法在提升计算效率的同时所获得的的模型性能依旧不错。
5.3 多任务先验
根据不同任务训练得到的适配器adapter通过附加在预训练网络的特定位置,这种参数共享的方式可以提升跨任务的效率。
Pilault等人提出了一个条件自适应多任务学习框架,会对不同任务训练得到的注意力进行编码,然后使用不同任务得到的注意力作为先验知识,对多任务进行知识迁移。
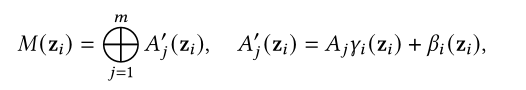
5.4只基于先验知识
有的研究尝试使用独立于输入的注意力分布,也就是只使用了先验知识的注意力分布。
比如Zhang等人提出了一种叫做均衡注意网络的高效的Transformer decoder结构,将离散的均一分部作为注意力分布的唯一来源。
将所有值的累加均值作为最后的值;为了进一步提升网络的性能,有额外增加了一个前馈的门控层。这样做的好处是使得Transformer decoder可以并行训练并且降低了decoder O(T^2)的复杂度。
You等人则是采用高斯分布进行注意力分布的计算,认为attention应该聚焦于中心窗口的部分,并且仅使用这部分作为self-attention的计算。并且实验显示仅使用这种分布计算的注意力最终效果与基线模型在机器翻译任务中性能相当。
Synthesizer则将attention socre替换为一个可训练的、随机初始化的注意力分数,仅将query作为输入,取以query作为输入的一个前馈网络的输出作为attention score。实验表明在机器翻译和语言建模任务中取得了和原始Transformer相近的性能。虽然没有解释原因,但实验证明这是有效的。
Part 6 优化多头注意力
多头注意力的多头机制可以关注不同方面的特征/信息,但是目前还没有任何机制确保多头的使用确实捕捉到了不同的特征。
6.1注意力头部行为建模
使用多头注意力的目的是希望模型关注不同位置不同子空间的信息,但是原始Transformer中没有确切的方法保证做到这一点。因此一系列工作尝试引入更复杂的机制来指导不同头的行为或者允许attention heads之间的交互。
Li等人在损失函数中引入了一个辅助项确保不同注意力头的多样性,两个正则化项一个会最大化输入和输出的余弦距离,一个则是尽量将不同的注意力头分散。
Talking-head Attention则是会对生成的注意力分数进行投影,投影到某个维度上进行聚合,聚合的值作为最后的value,这样有利于不同注意力头之间的信息交互。
6.2限制多头注意力的跨度
原始Transformer中注意力的跨度是全局的,即每一个query可以查询所有的k-value;但是实验观察到一些注意力往往聚焦于局部信息,一些注意力则关注更广泛的范围。
因此可以对注意力的跨度进行限制:
Locality:限制注意力头的跨度 可以引入局部的先验知识
Efficiency:通过调控可以在不显著增加显存和计算的前提下关注更长序列

限制attention的跨度可以看做对注意力分布增加mask然后重新归一化。
Fig 10展示了三种mask方程 分别是无限制跨度、自适应的跨度和恒定跨度。
自适应跨度会对较低的层使用较小的跨度,较高的层使用更大的跨度。
Multi-Scale Transformer虽然使用的是固定的跨度,但是对于不同层的不同head则会使用不同的跨度范围,是通过一个缩放因子w实现的。
6.3聚合多头注意力
在原始Transformer中会将多头注意力每一个输出进行级联,将级联后的结果进行线性变换后得到最终的输出表示。
部分研究人员认为仅通过简单的求和聚合并没有充分利用多头注意力提取到的表征信息,希望获得更加复杂的聚合结果。
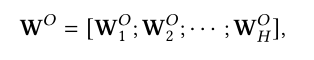
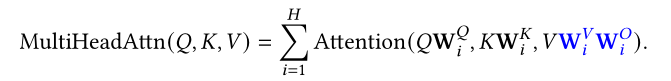
因此Gu,Feng,Li等人提出使用胶囊网络,将不同头的输出作为胶囊网络的输入,将胶囊网络的输出拼接在一起作为最后多头注意力的输出。
这两份工作分别使用不同的路由算法:dynamic routing动态路由和EM路由,前者引入了额外的参数和计算开销,后者实验发现仅对低层网络进行路由可以较好的平衡性能和计算成本。
6.4 其他改进
Shazeer提出了mulit-query attention,所有的注意力头共享k-v对,这样可以减少内存带宽需求以及提升解码速度;这样只会使得精度有些许下降。
Bhojanapalli发现key的尺寸会影响其表征分布的能力,因此将注意力头的尺寸和注意力头的数量解耦,从而将注意力头的大小调整为D/h,这种将注意力头大小设置为输入序列长度 是有一定效果的。
Section V 其他模块级别的改进
Part 1 位置表征
Permutation Equivariant置换不变的定义是:
即输入与输出顺序无关。
可以验证卷积神经网络和递归神经网络不是置换不变的。
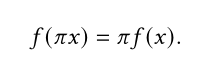
而Transformer中的self-attention模块和位置相关的前馈层(FFN)都是置换不变的。因此进行建模时可能会产生问题,因为需要参考输入的结构信息。
例如进行文本建模时,文本中单词的顺序是至关重要的,因此需要在Transformer中加入编码后的位置信息。常规的做法是将单词位置编码成positional vector append到输入中。
1.1绝对位置编码
原始Transformer中采用的就是绝对位置编码:
另一种绝对位置编码则是使用一个可训练的embedding层来对位置信息进行编码。
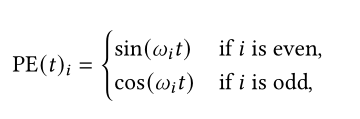
这样学习的嵌入更灵活,因为可以通过反向传播进行调整,但是嵌入的数量被限制在序列的最大长度内,也就是不能处理比训练时最大长度更长的序列。
Wang等人则提出使用正弦位置编码,但是每个频率是通过学习得到的。这种方法保留了一定的归纳性但是比人工的正弦编码更加灵活。
但是通过将位置信息嵌入到输入token中在transformer中传播时,位置信息可能会丢失。后续也有研究发现将位置表征添加到每一层Transformer layer中更有益。
1.2 相对位置编码
相对位置指的是不同token之间的关系。考虑相对位置编码是因为在self-attention中,输入单词之间的关系(方向和距离)可能比元素本身的位置更有用。
比如Show等人提出在sttention计算时增加一个可学习的相对位置编码项:
rij就是表示ij的相对位置信息,K则决定最大偏移多少,通常K设置为输入序列的长度;如果需要更关注局部信息可以将K设置为较小的值。
Music Transformer则借助相对位置减少中间内存的需求;而Transformer-XL则是借助正弦编码表征相对位置关系并将位置信息加入到注意力分数的计算中:
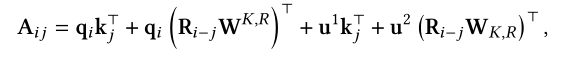
R是正弦编码矩阵,W,u都是需要学习的参数。
DeBERTa也使用了相对位置信息加入到注意力分数的计算当中,并将注意力解释为内容部分和未知部分。
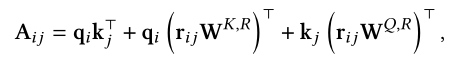
1.3混合位置编码
也有的研究研究了同时使用绝对位置和相对位置信息。在TUPE中重新设计了注意力分数的计算公式,增加了content-to-content项、绝对位置项和代表相对位置的偏置项:
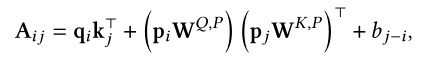
Roformer则是通过向量的旋转表示相对位置信息:
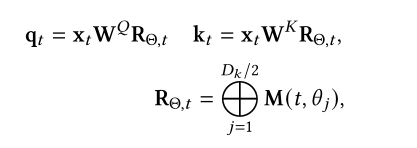
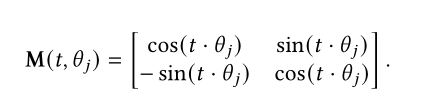
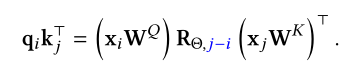
实际操作可以将嵌入的矩阵乘法通过两个element-wise乘法实现从而减少对内存的需求。
1.4隐式位置编码
除了对位置进行显式编码,还可以对位置进行隐式编码。比如Wang等人提出通过word embedding从而在单词嵌入位置编码后的信息。
R-Transformer则会将输入先经过一个局部RNN在送入self-attention,RNN模块就会给输入加上位置编码信息,捕捉局部的依赖性作为对self-attention的补充。
在CPE中则是通过一个2D卷积引入的位置信息,主要是因为0填充可以隐式编码绝对位置信息。
1.5Transformer Decoder中的位置编码
需要知道的是Transformer Decoder部分并不是置换不变的,因此Decoder部分能够感知位置信息但却无法对位置进行编码。一些语言建模任务中的实验结果证明了这一观点,研究人员发现删除位置编码信息甚至能够提升性能。
Part 2 Layer Normalization
层归一化和残差连接都被认为是稳定深层网络训练的一种机制,可以有效地减轻梯度消失、模型退化等问题,因此也有诸多研究致力于分析和改进LN模块。
2.1LN层放置的位置
原始的Transformer中LN位于残差模块之间被称为post-LN;随后也有研究将LN放在残差连接前面,以及在最后一层之后也放一个LN用来控制最终输出的幅度,这种被称之为pre-LN。
post-LN和pre-LN的差别参见Fig 11.

Xiong等人通过对Transformer的梯度进行理论分析发现使用post-LN会使得输出层附近的梯度更大,因此解释了使用post-LNde Transformer如果不采用warm-up学习率的方式会出现训练不稳定的情况。
虽然post-LN经常会导师训练不稳定、梯度弥散,当通常性能比pre-LN更好。
Liu等人通过理论分析发现post-LN不会存在梯度不均衡的问题,因此他们推测梯度问题并不是导致post-LN训练不稳定的原因;而是post-LN中的方法效应导致的训练不稳定,初始化后由于严重依赖于残差分支导致经过post-LN后Transformer的输出唯一更大,从而导致训练不稳定。
基于以上发现,他们为post-LN引入额外的参来控制对残差连接的依赖性,这些参数会根据采样数据的激活程度进行初始化,从而使得post-LN后的输出不会偏移的太大,这种方法保证了训练的稳定性,加快了收敛。
2.2 LN的替代方案
Xu等人观察到LN模块中学习的参数在实验中并没什么作用,甚至会增加过拟合的风险。Xu等人从控制变量实验中得到结论,能够提供前馈归一化并不是LN起作用的原因,LN的作用在于重新调整方差和均值从而调整梯度。因此他们提出AdaNorm:
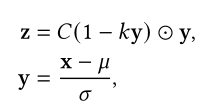
Nguyen等人则提出将LN替换为L2范数:
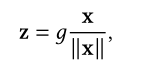
这样涉及到的参数更少,在机器翻译数据集上表现也不出,非常适合资源有限的场景。
Shen等人研讨了为什么BN在Transformer表现不佳的原因,主要是因为其批数据的不稳定性,因此他们提出PowerNorm,主要对BN进行了以下修改:
(1)驰预了对0均值化的限制
(2)使用输入的二次均值而不是方差
(3)使用的是当前统计数据的均值 而不是每批次的数据统计结果,即moving everage coefficient
2.3不使用LN
ReZero中使用一个可学习的残差连接来代替LN,也就是对于每一个模块ReZero会将输出变成:
这种方案被证明动态性更好、收敛速度更快。
Part 3 Position-wise FFN
虽然结构很简洁,但是位置感知的前馈层(potion-wise FFN)对Transformer的性能十分重要。
Dong等人观察到仅靠堆叠self-attention module会导致rank collapse,加入FFN层可以有效减轻这一问题。
3.1 FFN中的激活函数
原始Transformer中FFN层的激活函数用的是ReLU来增加非线性性,也有研究探索了其他激活函数。
Ramachandran等人尝试用Swish函数替换ReLU,在特定任务上获得了性能提升;
GPT则是使用了GELU;Shazeer等人则是使用了GLU(Gated Linear Units).
3.2提升FFN的容量
也有的研究是尝试使用具有更多参数的相似结构替换FFN,提升这部分的表征能力。
Lample等人使用product-key memory layers来替代FFN中的一部分。product-key memory主要由三部分组成:
(1)query network,
(2)包含两组sub-key子集的选择模块
(3)
一个value查找表。
首先输入通过query network映射到隐空间,随后将生成的q-k对 与 两组sub-key的笛卡尔积进行比较,获得k个最近邻对应的key,取他们聚合的结果作为key,从而得到最终的输出。
这种方式计算的注意力综合了多个key的结果,有效扩充了module的能力,并且进一步提出了使用这种key-product memory的多头注意力机制,在复杂语言建模任务中显著提高了性能,同时没有明显增加计算开销。
也有的研究借鉴混合专家的思想(MoE,Mixture of Experts)来提升FFN的性能,Gshard使用稀疏的MoE层替代FFN,每一层MoE包含多个专家(FFN),而输出则是这多个FFN的加权和。门控值是通过一个路由函数g计算得到的,通过学习这一门控函数来平衡引入专家增加的负载和对长序列预测的效率问题,通过将专家分布在多个设备上可以解决。以及对于每一个MoE层,只有top-k的专家会被激活。
Section VI Transformer架构级别的变体
除了在Transformer不同模块之间进行的改进带来的性能提升、效率的提升,还有的工作尝试在Transformer整体结构层面做改进。
Part 1 轻量级Transformer
与低秩self-attention思路近似,Lite Transformer将每一个attention module替换成一个二分支结构,一个分支基于注意力机制捕获长程依赖关系,第二个分支基于深度卷积捕捉局部依赖关系。这样使得网络结构更简洁、计算量更小,更适合用于移动端设备。
Funnel Transformer则是使用了漏斗型的encoder结构,通过下采样逐渐减少输入序列的长度,然后通过上采样恢复回原始维度。这种结构有效减少了计算量和内训需求,在同等算力下可以搭建更深层次或更宽的网络。
DeLightT则是设计了新的DeLighT模块代替原始的模块,DeLighT做了以下改进:
(1)DeLighT采用 先expand再reduce的结构
(2)使用单头注意力学习pair之间的交互
(3)FFN也是一种先expand再reduce的结构
这种思路与原始Transformer正好相反
Part 2 增强跨层连接性
原始Transformer中每一个模块将前一模块的输出作为输入,其他工作有探索引入更多的连接路径,如Realformer和Predictive Attention Transformer就会复用前层的注意力分布来指导当前模块的注意力分布,这样相当于增加了相邻模块之间的路径。
在较深的Transformer 其encoder-decoder中,只用了最后一个block的输出作为cross-attention的计算,这就容易引起Transformer的优化问题。
Transparant Attention的cross attention采用的是所有encoder模块的加权和:
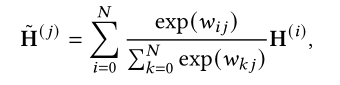
这样有效减少了不同层到输出的路径,也有利于模型的优化。
原始Transformer的另一个问题,每一个位置只能关注较低层的历史信息,Feedback Transformer提出在decoder部分引入反馈机制,也就是每个位置都能以加权和的形式获得所有层的历史信息。
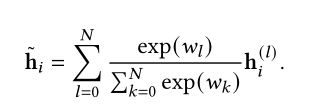
Part 3 自适应计算时间
原始Transformer和大多数神经网络模型一样采用固定的计算步骤,一个有趣的探索方向是根据输入情况来自适应的调整计算时间,即ACT(Adaptive Computation Time)。
引入ACT有以下优点:
(1)加深对难学习样本的特征学习。对于一些较难学习的样本,浅层表征往往不足以完成任务,需要花费更多的时间学习其深层次的表征;
(2)提升对简单样本的训练效率。同理对于较简单的样本,浅层的表征就足够,此时就可以减少网络的计算时间。
Universal Transformer采用一种在深度上迭代的机制逐步的精炼特征表达,参见Fig 12(a)。
UT使用了一种动态刹车机制,当某个位置的刹车概率超过阈值时就不会更新当前这一位置,只有当所有symbol都刹车停止或者到预定义的最大步骤后迭代过程就停止了。
Conditional Computation Transformer(CCT)则是在self-attention和FFN层中增加了一个门控模块,来决定是否跳过当前层,具体参见Fig12(b).
在DeeBERT及PABEE中则是引入了早停的思想,在达到一定的标准后就停止认为已经达到了要求,参见Fig 12©.

Part 4 Transformer中的分治策略
Transformer中self-attention的计算复杂度大大限制了Transformer在某些任务中的应用。比如语言建模往往输入的序列很长,除了参考Sec4中的简化策略,另一种有效的方法是采用分支策略处理长序列。基于分治策略可以分为两大类Transformer,分别是:
recurrent循环Transformer和hierarchical层级Transformer。
Fig13是这两类的示意图。

4.1Recurrent Transformer
在Recurrent Transformer中使用了一个缓存cache来存储历史信息。每次处理一段文本时,网络会从cache中读取作为额外的输入;处理完成后会将网络隐层输出重新写入cache。
Transformer-XL中认为通过将前一时间步的输出作为缓存并作为后续时间步的额外输入可以解决固定上下文这一限制。
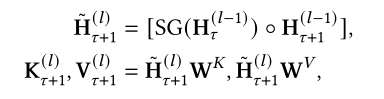
Compressive Transformer则进一步将cache分成两级memory,因为在Transformer-XL中仅缓存了前一个时间步的激活情况,再之前的就直接被丢弃了;而Compressive Transformer则通过下采样操作(卷积、池化)将更早的激活结果存储至压缩缓存中(compressed memory)。
除了引入压缩操作,将可缓存的上下文长度扩大到:
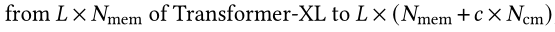
Compressive Transformer还提出使用局部损失函数来压缩反向传播更新时间。
Memformer将循环机制从decoder扩展到encoder-decoder结构中,通过向encoder部分加入cross attention memory实现;并且在encoder输出顶部显式的加了一个slot用来写入缓存。此外为了避免反向传播更新时间太久,Memformer还提出了Memory Replay Back-Propagation (MRBP) 算法,通过在每一时间步上回放内存实现在长时间序列中进行反向传播。
4.2 Hierarchical Transformer
层级Transformer会将输入分解成更细粒度的段落,较低层次的特征首先被送入Transformer Encoder进行编码,这部分结果聚合后得到更高层次特征,再送入Transformer进行处理。这一过程就可以理解为以一定层级送入Transformer进行处理,这种方法的优点在于:
(1)可以在有限的资源内处理更长序列
(2)有可能获得更丰富的特征表达
4.2.1较长序列的层次化
对于一些任务的输入序列很长,可以使用hierarchical Transformer来捕获长程依赖关系。比如Miculicich等人使用注意力机制来聚合底层信息,辅助完成机器翻译任务,
HIBERT则是先学习句子的表征然后基于句子的表征获得文本级别的表征;Hi-Transformer则是同时使用了句子级别的Transformer和文本级别 的Transformer来层次化的学习文本表征,句子层级的表征会再次送入另一个句子层级Transformer来提升句子的建模效果。
4.2.2更多特征的层次化
也可通过层次化的方法获得更丰富的特征表达。TENER会使用一个低层次的encoder来编码字符级别特征,然后通过词嵌入的方式级联后作为高层次Transformer的输入,这样输入包含更丰富的特征,减轻了数据稀疏以及不再词汇表内的问题。
在Vision Transformer中则是将输入切分成多个patch,以patch作为输入的基本单位,但patch可能会丢失一些本征像素级别的信息。为了解决这一问题TNT(Transformer in Transformer)则是在每一层又引入了一个层内的Transformer和一个外部Tansformer,取像素级别和patch级别的融合结果作为输入。
Part 5 探索其他可替换结构
Lu等人将Transformer视作一个常微分方程的数学模型,提出了FFN-attention-FFN模块替换每一个Transformer block来解决动力学问题。
Switch Transformer则重新组织了attention module和FFN module,attention 模块主要放在低层,FFN主要放顶层;这种方式在不增加参数、内存和训练时间的前提下提升了多语言建模的迷惑性。
Mask Attention Network则是为self-attention增加了一个动态的mask,mask取决于当前特征、token之间的相关性以及head指数。mask的使用有效的增强了对局部文本的建模,适合做机器翻译和摘要总结任务。
同时,还有一系列工作使用NAS神经架构搜索来搜索Transformer的替代方案。比如ET基于的是进化算法,DARTSformer则是基于DARTS结合一个多分割可逆网络和反向重建算法来压缩内存,与ET比显著降低了搜索成本。
Section VII预训练Transformer
Transformer与CNN,RNN的关键区别在于,没加入任何先验知识偏置,因此Transformer是一个更通用的架构,可以捕获不同范围内的依赖关系;但是在数据有限的情况下却容易导致过拟合。解决办法之一就是引入一些先验知识。
有研究表明将在大型语料库上预训练的Transformer可以适用于下游任务。
主要的预训练方法主要有以下三个方向:
(1)仅预训练Encoder
BERT使用Masked Language Modeling和Next Sentence Prediction作为自监督训练目标用于自然语言理解任务;RoBERTa则借鉴了BERT的训练但是移除了NSP部分,因为实验发现NSP会影响下游任务的性能。
(2)仅预训练Decoder
Generative Pre-trained Transformer(GPT)系列则致力于通过缩放预训练好的decoder部分,解决不同规模的语言建模任务。
(3)预训练的Encoder-Decoder
BART则是在BERT基础上加入去噪作为训练目标,使用预训练Encoder-Decoder的好处是既可以有较好的语言理解也可以有较好的语言生成能力。
Section VIII Transformer的应用
Transformer最初是为机器翻译任务而设计的,目前已经在NLP,CV,语音处理等领域有广泛应用。
(1)NLP
在机器翻译、语言建模、命名实体识别等均有应用,主要原因是其适合于大规模的语料库。
(2)CV
在图像分类、目标检测、图像生成以及视频处理等领域均有应用。
(3)语音处理
包括语音识别、语音合成、语音增强、音乐生成
(4)多模态
包括VQA,视觉常识推理、字母生成、语音-文本翻译,文本-图像生成
Section VIIII 总结全文及展望未来
本文对Transformer及其变体X-former进行了全面概述,现有工作从不同方面对Transformer进行了改进,如提升计算效率、提升泛化性或扩展应用;从改进方面有结构曾从、模型层次、轻量级层次、预训练等。
虽然Transformer的应用已经取得了一定成果,但仍然存在一定局限性,目前的关注点在:效率、泛化性等,未来的改进有以下三大方向:
(1)理论分析
虽然实验已经证明Transformer能够支持大规模训练数据集,在训练数据充分的情况下,Transformer比CNN和RNN具有更强的表征能力。一种解释是Transformer没有引入数据的先验知识,但是其背后的原因还缺乏理论支撑。
(2)超越Attention的更好的全局交互机制
Transformer一个主要优势是采用注意力机制对输入数据的全剧以来进行有效建模,但是也有研究发现大多数节点无需得到过多注意力,但也无法分门别类的对节点施加注意力。
因此在如何构建更好的全局交互机制这方面仍然有很大的优化空间。一方面self-attention可以视为具有动态权重连接的全连接神经网络,通过动态路由来聚合非局部信息,因此在路由算法方面值得进一步探索;另一方面也可以通过其他模型来建立全局交互,如memory-enhanced model。
(3)处理多模态数据的统一框架
在诸多应用场景,需要结合多模态数据提升性能,也就是AI需要有能力捕获不同模态信息的语义关联。自从Transformer在文本、图像、视频、音频等方面均取得了成功,那就可以尝试建立一个统一的框架,更好的捕捉多模态数据之间的内在连接。这方面探索的方向在于如何设计模态内和模态间的attention。
行文至此,我们希望本文可以为更好的理解Transformer提供参考,也帮助读者进一步优化、改进Transformer。
1010 全文完