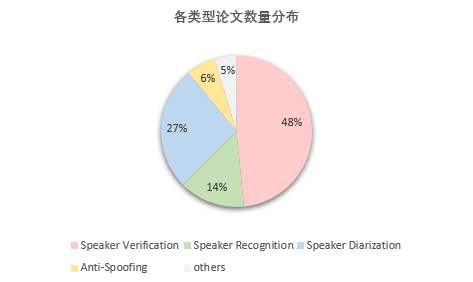
今年入选 ICASSP 2023 的论文中,说话人识别(声纹识别)方向约有64篇,初步划分为Speaker Verification(31篇)、Speaker Recognition(9篇)、Speaker Diarization(17篇)、Anti-Spoofing(4篇)、others(3篇)五种类型。
本文是 ICASSP 2023说话人识别方向论文合集系列的最后一期,整理了Speaker Recognition(9篇)、Anti-Spoofing(4篇)、Others(3篇)部分的论文简述共16篇。
Speaker Recognition
1.A Study on Bias and Fairness in Deep Speaker Recognition
标题:深度说话人识别中的偏见与公平性研究
作者:Amirhossein Hajavi, Ali Etemad
单位:Dept. ECE and Ingenuity Labs Research Institute, Queen’s University, Canada
链接:https://ieeexplore.ieee.org/document/10095572
摘要:随着使用说话人识别系统作为个人身份验证和个性化服务手段的智能设备的普及,说话人识别系统的公平性已经成为一个重要的焦点。在本文中,我们基于3个流行的相关定义,即统计均等、均等赔率和均等机会,研究了最近SR系统中的公平概念。我们研究了训练SR系统中5种流行的神经架构和5种常用的损失函数,同时评估了它们对性别和国籍群体的公平性。我们详细的实验揭示了这一概念,并证明更复杂的编码器架构更好地符合公平性的定义。此外,我们发现损失函数的选择会显著影响SR模型的偏差。
With the ubiquity of smart devices that use speaker recognition (SR) systems as a means of authenticating individuals and personalizing their services, fairness of SR systems has becomes an important point of focus. In this paper we study the notion of fairness in recent SR systems based on 3 popular and relevant definitions, namely Statistical Parity, Equalized Odds, and Equal Opportunity. We examine 5 popular neural architectures and 5 commonly used loss functions in training SR systems, while evaluating their fairness against gender and nationality groups. Our detailed experiments shed light on this concept and demonstrate that more sophisticated encoder architectures better align with the definitions of fairness. Additionally, we find that the choice of loss functions can significantly impact the bias of SR models.
2.An Improved Optimal Transport Kernel Embedding Method with Gating Mechanism for Singing Voice Separation and Speaker Identification
标题:针对联合学习中自动说话人验证模型的后门攻击
作者:1 Weitao Yuan,1 Yuren Bian,1 Shengbei Wang,2 Masashi Unoki,3 Wenwu Wang
单位:1 Tianjin Key Laboratory of Autonomous Intelligence Technology and Systems, Tiangong University, China
2 Japan Advanced Institute of Science and Technology, Japan
3 Centre for Vision, Speech and Signal Processing, University of Surrey, Guildford, UK
链接:https://ieeexplore.ieee.org/document/10096651
摘要:
歌唱声分离和说话人识别是语音信号处理中的两个经典问题。深度神经网络(DNN)通过从输入混合中提取目标信号的有效表示来解决这两个问题。由于信号的本质特征可以很好地反映在特征分布的潜在几何结构上,因此提取目标信号的几何感知和分布相关特征是解决SVS/SI的自然方法。为此,本工作引入了SVS/SI的最优传输(OT)概念,并提出了一种改进的最优传输核嵌入(iOTKE)来提取目标分布相关特征。iOTKE基于从所有训练数据中学习到的参考集,从输入信号学习到目标信号的OT。这样既能保持特征的多样性,又能保持目标信号分布的潜在几何结构。为了进一步提高特征选择能力,我们将提出的iOTKE扩展到一个门控版本,即门控iOTKE (G-iOTKE),通过合并轻量级的门控机制。门控机制控制有效的信息流,并使所提出的方法能够选择特定输入信号的重要特征。我们在SVS/SI上对所提出的G-iOTKE进行了评估。实验结果表明,该方法比其他模型具有更好的效果。
Singing voice separation (SVS) and speaker identification (SI) are two classic problems in speech signal processing. Deep neural networks (DNNs) solve these two problems by extracting effective representations of the target signal from the input mixture. Since essential features of a signal can be well reflected on its latent geometric structure of the feature distribution, a natural way to address SVS/SI is to extract the geometry-aware and distribution-related features of the target signal. To do this, this work introduces the concept of optimal transport (OT) to SVS/SI and proposes an improved optimal transport kernel embedding (iOTKE) to extract the target-distribution-related
features. The iOTKE learns an OT from the input signal to the target signal on the basis of a reference set learned from all training data. Thus it can maintain the feature diversity and preserve the latent geometric structure of the distribution for the target signal. To further improve the feature selection ability, we extend the proposed iOTKE
to a gated version, i.e., gated iOTKE (G-iOTKE), by incorporating a lightweight gating mechanism. The gating mechanism controls effective information flow and enables the proposed method to select important features for a specific input signal. We evaluated the proposed G-iOTKE on SVS/SI. Experimental results showed that the proposed method provided better results than other models.
3.HiSSNet:Sound Event Detection and Speaker Identification via Hierarchical Prototypical Networks for Low-Resource Headphones
标题:HiSSNet:低资源耳机的声音事件检测和说话人识别的分层原型网络
作者:N Shashaank 1,2, Berker Banar 1,3, Mohammad Rasool Izadi 1, Jeremy Kemmerer 1, Shuo Zhang 1, Chuan-Che (Jeff) Huang 1
单位:1 Bose Corporation, MA, USA
2 Department of Computer Science, Columbia University, NY, USA
3 School of Electronic Engineering and Computer Science, Queen Mary University of London, UK
链接:https://ieeexplore.ieee.org/document/10094788
摘要:现代降噪耳机通过消除不必要的背景噪音,大大改善了用户的听觉体验,但它们也会屏蔽对用户重要的声音。用于声音事件检测(SED)和说话人识别(SID)的机器学习(ML)模型可以使耳机选择性地通过重要的声音;然而,为以用户为中心的体验实现这些模型会带来一些独特的挑战。首先,大多数人花有限的时间定制他们的耳机,所以声音检测应该在开箱即用的情况下工作得相当好。其次,随着时间的推移,模型应该能够根据用户的隐式和显式交互来学习对用户重要的特定声音。最后,这样的模型应该有一个小的内存占用,以运行在低功耗耳机与有限的芯片内存。在本文中,我们建议使用HiSSNet(分层SED和SID网络)来解决这些挑战。HiSSNet是一种SEID (SED和SID)模型,它使用分层原型网络来检测感兴趣的一般和特定声音,并表征类似警报的声音和语音。研究表明,HiSSNet比使用非分层原型网络训练的SEID模型高出6.9 - 8.6%。与专门为SED或SID训练的最先进(SOTA)模型相比,HiSSNet实现了类似或更好的性能,同时减少了支持设备上多种功能所需的内存占用。
Modern noise-cancelling headphones have significantly improved users’ auditory experiences by removing unwanted background noise, but they can also block out sounds that matter to users. Machine learning (ML) models for sound event detection (SED) and speaker identification (SID) can enable headphones to selectively pass through important sounds; however, implementing these models for a user-centric experience presents several unique challenges. First, most people spend limited time customizing their headphones, so the sound detection should work reasonably well out of the box. Second, the models should be able to learn over time the specific sounds that are important to users based on their implicit and explicit interactions. Finally, such models should have a small memory footprint to run on low-power headphones with limited on-chip memory. In this paper, we propose addressing these challenges using HiSSNet (Hierarchical SED and SID Network). HiSSNet is an SEID (SED and SID) model that uses a hierarchical prototypical network to detect both general and specific sounds of interest and characterize both alarm-like and speech sounds. We show that HiSSNet outperforms an SEID model trained using non-hierarchical prototypical networks by 6.9 – 8.6%. When compared to state-of-the-art (SOTA) models trained specifically for SED or SID alone, HiSSNet achieves similar or better performance while reducing the memory footprint required to support multiple capabilities on-device.
4.Jeffreys Divergence-Based Regularization of Neural Network Output Distribution Applied to Speaker Recognition
标题:基于Jeffreys散度的神经网络输出分布正则化在说话人识别中的应用
作者:Pierre-Michel Bousquet, Mickael Rouvier
单位:LIA - Avignon University
链接:https://ieeexplore.ieee.org/document/10094702
摘要:提出了一种新的基于Jeffreys Divergence的深度神经网络说话人识别损失函数。将这种散度添加到交叉熵损失函数中,可以使输出分布的目标值最大化,同时平滑非目标值。这个目标函数提供了高度判别的特征。除了这种影响之外,我们提出了其有效性的理论证明,并试图理解这种损失函数如何影响模型,特别是对数据集类型的影响(即域内或域外w.r.t训练语料库)。我们的实验表明,Jeffreys loss始终优于最先进的说话人识别,特别是在域外数据上,并有助于限制误报。
A new loss function for speaker recognition with deep neural network is proposed, based on Jeffreys Divergence. Adding this divergence to the cross-entropy loss function allows to maximize the target value of the output distribution while smoothing the non-target values. This objective function provides highly discriminative features. Beyond this effect, we propose a theoretical justification of its effectiveness and try to understand how this loss function affects the model, in particular the impact on dataset types (i.e. in-domain or out-of-domain w.r.t the training corpus). Our experiments show that Jeffreys loss consistently outperforms the state-of-the-art for speaker recognition, especially on out-of-domain data, and helps limit false alarms.
5.Privacy-Preserving Occupancy Estimation
标题:保护隐私的占用估计
作者:Jennifer Williams, Vahid Yazdanpanah, Sebastian Stein
单位:School of Electronics and Computer Science University of Southampton, UK
链接:https://ieeexplore.ieee.org/document/10095340
摘要:在本文中,我们引入了一个基于音频的入住率估计框架,包括一个新的公共数据集,并在“鸡尾酒会”场景中评估入住率,该场景通过混合音频来产生具有重叠谈话者(1-10人)的语音来模拟派对。为了估计音频片段中说话者的数量,我们探索了五种不同类型的语音信号特征,并使用卷积神经网络(CNN)训练了我们模型的几个版本。此外,我们通过对音频帧进行随机扰动来隐藏语音内容和说话者身份,从而使该框架具有隐私保护性。我们证明了我们的一些隐私保护特征在占用估计方面比原始波形表现得更好。我们使用两个对抗性任务:说话人识别和语音识别来进一步分析隐私。我们的隐私保护模型可以在0.9-1.6的均方误差(MSE)范围内估计1-2人的模拟鸡尾酒会片段中的说话人数量,在保持语音内容隐私的情况下,我们的分类准确率高达34.9%。然而,攻击者仍然有可能识别单个说话者,这激励了该领域的进一步工作
In this paper, we introduce an audio-based framework for occupancy estimation, including a new public dataset, and evaluate occupancy in a ‘cocktail party’ scenario where the party is simulated by mixing audio to produce speech with overlapping talkers (1-10 people). To estimate the number of speakers in an audio clip, we explored five different types of speech signal features and trained several versions of our model using convolutional neural networks (CNNs). Further, we adapted the framework to be privacy-preserving by making random perturbations of audio frames in order to conceal speech content and speaker identity. We show that some of our privacy-preserving features perform better at occupancy estimation than original waveforms. We analyse privacy further using two adversarial tasks: speaker recognition and speech recognition. Our privacy-preserving models can estimate the number of speakers in the simulated cocktail party clips within 1-2 persons based on a mean-square error (MSE) of 0.9-1.6 and we achieve up to 34.9% classification accuracy while preserving speech content privacy. However, it is still possible for an attacker to identify individual speakers, which motivates further work in this area.
6.Quantitative Evidence on Overlooked Aspects of Enrollment Speaker Embeddings for Target Speaker Separation
标题:用于目标说话人分离的注册说话人嵌入忽略方面的定量证据
作者:Xiaoyu Liu,Xu Li,Joan Serra`
单位:Dolby Laboratories
链接:https://ieeexplore.ieee.org/document/10096478
摘要:单通道目标说话人分离(TSS)旨在从多个说话人的混合中提取说话人的声音,并给出该说话人的注册话语。一个典型的深度学习TSS框架由上游模型和下游模型组成,上游模型获取注册说话人嵌入,下游模型根据嵌入条件进行分离。在本文中,我们研究了注册嵌入的几个重要但被忽视的方面,包括广泛使用的说话人识别嵌入的适用性,对数滤波器组和自监督嵌入的引入,以及嵌入的跨数据集泛化能力。我们的研究结果表明,由于次优度量、训练目标或常见的预处理,说话人识别嵌入可能会丢失相关信息。相比之下,滤波器组和自监督嵌入都保留了说话人信息的完整性,但前者在跨数据集评估中始终优于后者。之前被忽视的滤波器组嵌入的竞争性分离和泛化性能在我们的研究中是一致的,这需要未来对更好的上游特征进行研究。
Single channel target speaker separation (TSS) aims at extracting a speaker’s voice from a mixture of multiple talkers given an enrollment utterance of that speaker. A typical deep learning TSS framework consists of an upstream model that obtains enrollment speaker embeddings and a downstream model that performs the separation conditioned on the embeddings. In this paper, we look into several important but overlooked aspects of the enrollment embeddings, including the suitability of the widely used speaker identification embeddings, the introduction of the log-mel filterbank and self-supervised embeddings, and the embeddings’ cross-dataset generalization capability. Our results show that the speaker identification embeddings could lose relevant information due to a sub-optimal metric, training objective, or common pre-processing. In contrast, both the filterbank and the self-supervised embeddings preserve the integrity of the speaker information, but the former consistently outperforms the latter in a cross-dataset evaluation. The competitive separation and generalization performance of the previously overlooked filterbank embedding is consistent across our study, which calls for future research on better upstream features.
7.Representation of Vocal Tract Length Transformation Based on Group Theory
标题:基于群论的声道长度变换表示
作者:Atsushi Miyashita, Tomoki Toda
单位:Nagoya University, Japan
链接:https://ieeexplore.ieee.org/document/10095239
摘要:音素的声学特性取决于单个说话者的声道长度(VTL)。对于自动语音识别和说话人识别等任务来说,将这些说话人信息从语言信息中分离出来是非常重要的。本文重点研究了构成群的声道长度变换(VTLT)的特性,并基于群论分析导出了新的语音表示方式VTL谱,其中VTLT只改变了VTL谱的相位,即简单的线性移位。此外,我们还提出了一种方法来解析解析VTL对VTL光谱的影响。我们使用TIMIT数据集进行了实验,以阐明该特征的性质,结果表明:1)对于ASR,在随机VTLT下,VTL频谱的归一化将音素识别错误率降低了1.9; 2)对于说话人识别,去除VTL频谱的幅度成分提高了说话人分类性能。
The acoustic characteristics of phonemes vary depending on the vocal tract length (VTL) of the individual speakers. It is important to disentangle such speaker information from the linguistic information for various tasks, such as automatic speech recognition (ASR) and speaker recognition. In this paper, we focus on the property of vocal tract length transformation (VTLT) that forms a group, and derive the novel speech representation VTL spectrum based on group theory analysis, where only the phase of the VTL spectrum is changed by VTLT, which is a simple linear shift. Moreover, we propose a method to analytically disentangle the VTL effects on the VTL spectrum. We conducted experiments with the TIMIT dataset to clarify the property of this feature, demonstrationg that 1) for ASR, normalization of the VTL spectrum reduced the phoneme recognition error rate by 1.9 under random VTLT, and 2) for speaker recognition, removal of the amplitude component of the VTL spectrum improved speaker classification performance.
8.Speaker Recognition with Two-Step Multi-Modal Deep Cleansing
标题:基于两步多模态深度清洗的说话人识别
作者:Ruijie Tao 1, Kong Aik Lee 2, Zhan Shi 3 and Haizhou Li 1,3,4,5
单位:1 National University of Singapore, Singapore
2 Institute for Infocomm Research, A⋆STAR, Singapore
3 The Chinese University of Hong Kong, Shenzhen, China
4 University of Bremen, Germany
5 Shenzhen Research Institute of Big Data, Shenzhen, China
链接:https://ieeexplore.ieee.org/document/10096814
摘要:近年来,基于神经网络的说话人识别技术取得了显著的进步。稳健的说话人表示从训练集中的难易样本中学习有意义的知识,以获得良好的性能。然而,训练集中有噪声的样本(即带有错误标签的样本)会导致混淆,并导致网络学习到错误的表示。在本文中,我们提出了一个两步视听深度清洗框架来消除说话人表征学习中噪声标签的影响。该框架包含一个粗粒度清洗步骤来搜索复杂样本,然后是一个细粒度清洗步骤来过滤掉有噪声的标签。我们的研究从一个高效的视听说话人识别系统开始,该系统在Vox-O、E和H测试集上实现了接近完美的等错误率(EER),分别为0.01%、0.07%和0.13%。采用所提出的多模态清洗机制,四种不同的说话人识别网络平均提高了5.9%。
Neural network-based speaker recognition has achieved significant improvement in recent years. A robust speaker representation learns meaningful knowledge from both hard and easy samples in the training set to achieve good performance. However, noisy samples (i.e., with wrong labels) in the training set induce confusion and cause the network to learn the incorrect representation. In this paper, we propose a two-step audio-visual deep cleansing framework to eliminate the effect of noisy labels in speaker representation learning. This framework contains a coarse-grained cleansing step to search for the complex samples, followed by a fine-grained cleansing step to filter out the noisy labels. Our study starts from an efficient audio-visual speaker recognition system, which achieves a close to perfect equal-error-rate (EER) of 0.01%, 0.07% and 0.13% on the Vox-O, E and H test sets. With the proposed multi-modal cleansing mechanism, four different speaker recognition networks achieve an average improvement of 5.9%. Code has been made available at: https://github.com/TaoRuijie/AVCleanse.
9.Universal Speaker Recognition Encoders for Different Speech Segments Duration
标题:通用说话人识别编码器不同的语音段持续时间
作者:Sergey Novoselov 1,2, Vladimir Volokhov 1, Galina Lavrentyeva 1
单位:1 ITMO University, St.Petersburg, Russia
2 STC Ltd., St.Petersburg, Russia
链接:https://ieeexplore.ieee.org/document/10096081
摘要:创建对不同的声学和语音持续时间条件具有鲁棒性的通用说话人编码器是当今的一大挑战。根据我们的观察,在短语音片段上训练的系统对于短的短语说话者验证是最优的,而在长片段上训练的系统对于长片段验证是优越的。在合并的短和长语音段上同时训练的系统不能给出最佳验证结果,并且通常对于短和长段都会降级。本文解决了为不同的语音段持续时间创建通用说话人编码器的问题。我们描述了我们为任何类型的选定神经网络架构训练通用说话人编码器的简单配方。根据我们为NIST SRE和VoxCeleb1基准获得的基于wav2vec TDNN的系统的评估结果,所提出的通用编码器在不同注册和测试语音段持续时间的情况下提供了说话人验证改进。所提出的编码器的关键特征是它与所选神经网络结构具有相同的推理时间。
Creating universal speaker encoders which are robust for different acoustic and speech duration conditions is a big challenge today. According to our observations systems trained on short speech segments are optimal for short phrase speaker verification and systems trained on long segments are superior for long segments verification. A system trained simultaneously on pooled short and long speech segments does not give optimal verification results and usually degrades both for short and long segments. This paper addresses the problem of creating universal speaker encoders for different speech segments duration. We describe our simple recipe for training universal speaker encoder for any type of selected neural network architecture. According to our evaluation results of wav2vec-TDNN based systems obtained for NIST SRE and VoxCeleb1 benchmarks the proposed universal encoder provides speaker verification improvements in case of different enrollment and test speech segment duration. The key feature of the proposed encoder is that it has the same inference time as the selected neural network architecture.
Anti-Spoofing
1.Identifying Source Speakers for Voice Conversion Based Spoofing Attacks on Speaker Verification Systems
标题:识别基于语音转换的说话人身份验证系统欺骗攻击的源说话人
作者:Danwei Cai 1, Zexin Cai 1, Ming Li 1,2
单位:1 Department of Electrical and Computer Engineering, Duke University, Durham, USA
2 Data Science Research Center, Duke Kunshan University, Kunshan, China
链接:https://ieeexplore.ieee.org/document/10096733
摘要:一种自动说话人验证系统,目的是验证语音信号的说话人身份。然而,语音转换系统可以操纵一个人的语音信号,使其听起来像另一个说话者的声音,并欺骗说话者验证系统。大多数针对基于语音转换的欺骗攻击的对策被设计为区分真实语音和欺骗语音,用于说话人验证系统。在本文中,我们研究了源说话人的识别问题-在给定语音转换后的语音中推断源说话人的身份。为了进行源说话人识别,我们只需在说话人嵌入网络训练时将带有源说话人身份标签的语音转换语音数据添加到真实语音数据集中即可。实验结果表明,使用同一语音转换模型转换后的语音进行训练和测试时,源说话人识别是可行的。此外,我们的研究结果表明,从各种语音转换模型中转换更多的话语进行训练有助于提高对未见过的语音转换模型转换的话语的源说话人识别性能。
An automatic speaker verification system aims to verify the speaker identity of a speech signal. However, a voice conversion system could manipulate a person’s speech signal to make it sound like another speaker’s voice and deceive the speaker verification system. Most countermeasures for voice conversion-based spoofing attacks are designed to discriminate bona fide speech from spoofed speech for speaker verification systems. In this paper, we investigate the problem of source speaker identification – inferring the identity of the source speaker given the voice converted speech. To perform source speaker identification, we simply add voice-converted speech data with the label of source speaker identity to the genuine speech dataset during speaker embedding network training. Experimental results show the feasibility of source speaker identification when training and testing with converted speeches from the same voice conversion model(s). In addition, our results demonstrate that having more converted utterances from various voice conversion model for training helps improve the source speaker identification performance on converted utterances from unseen voice conversion models.
2.Leveraging Positional-Related Local-Global Dependency for Synthetic Speech Detection
标题:利用位置相关的局部-全局依赖关系进行合成语音检测
作者:Xiaohui Liu 1, Meng Liu 1, Longbiao Wang 1, Kong Aik Lee 2, Hanyi Zhang 1, Jianwu Dang 1
单位:1 Tianjin Key Laboratory of Cognitive Computing and Application, College of Intelligence and Computing, Tianjin University, Tianjin, China
2 Institute for Infocomm Research, A⋆STAR, Singapore
链接:https://ieeexplore.ieee.org/document/10096278
摘要:自动说话人验证(ASV)系统容易受到欺骗攻击。与自然语音相比,合成语音表现出局部和全局伪像,因此结合局部-全局依赖关系将带来更好的抗欺骗性能。为此,我们提出了利用位置相关的局部-全局依赖关系进行合成语音检测的Rawformer。在我们的方法中分别使用二维卷积和Transformer来捕获本地和全局依赖。具体来说,我们设计了一种新的位置聚合器,通过添加位置信息和平坦化策略来集成局部全局依赖,减少了信息损失。此外,我们提出了挤压激励Rawformer (SE-Rawformer),它引入了挤压激励操作以更好地获取局部依赖性。结果表明,我们提出的SE-Rawformer与asvspoof2019 LA上最先进的单一系统相比,具有37%的相对改进,并且在asvspoof2021 LA上具有良好的泛化性。特别是,在SE-Rawformer中使用位置聚合器平均提高了43%。
Automatic speaker verification (ASV) systems are vulnerable to spoofing attacks. As synthetic speech exhibits local and global artifacts compared to natural speech, incorporating local-global dependency would lead to better anti-spoofing performance. To this end, we propose the Rawformer that leverages positional-related local-global dependency for synthetic speech detection. The twodimensional convolution and Transformer are used in our method to capture local and global dependency, respectively. Specifically, we design a novel positional aggregator that integrates localglobal dependency by adding positional information and flattening strategy with less information loss. Furthermore, we propose the squeeze-and-excitation Rawformer (SE-Rawformer), which introduces squeeze-and-excitation operation to acquire local dependency better. The results demonstrate that our proposed SE-Rawformer leads to 37% relative improvement compared to the single stateof-the-art system on ASVspoof 2019 LA and generalizes well on ASVspoof 2021 LA. Especially, using the positional aggregator in the SE-Rawformer brings a 43% improvement on average.
3.SAMO:Speaker Attractor Multi-Center One-Class Learning For Voice Anti-Spoofing
标题:SAMO:用于语音反欺骗的说话人吸引器多中心单类学习
作者:Siwen Ding 1,You Zhang 2, Zhiyao Duan 2
单位:1 Columbia University, New York, NY, USA
2 University of Rochester, Rochester, NY, USA
链接:https://ieeexplore.ieee.org/document/10094704
摘要:语音防欺骗系统是自动说话人验证(ASV)系统的重要辅助设备。一个主要的挑战是由先进的语音合成技术带来的看不见的攻击。我们之前对单类学习的研究通过压缩嵌入空间中的真实语音,提高了对不可见攻击的泛化能力。然而,这种紧凑性没有考虑到说话者的多样性。在这项工作中,我们提出了说话人吸引子多中心单类学习(SAMO),它将真实语音聚集在一些说话人吸引子周围,并在高维嵌入空间中推开所有吸引子的欺骗攻击。在训练方面,我们提出了一种真诚语音聚类和真诚/欺骗分类的协同优化算法。在推理方面,我们提出了针对未注册说话人的反欺骗策略。我们提出的系统优于现有的最先进的单一系统,在asvspof2019 LA评估集上的等错误率(EER)相对提高了38%。
Voice anti-spoofing systems are crucial auxiliaries for automatic speaker verification (ASV) systems. A major challenge is caused by unseen attacks empowered by advanced speech synthesis technologies. Our previous research on one-class learning has improved the generalization ability to unseen attacks by compacting the bona fide speech in the embedding space. However, such compactness lacks consideration of the diversity of speakers. In this work, we propose speaker attractor multi-center one-class learning (SAMO), which clusters bona fide speech around a number of speaker attractors and pushes away spoofing attacks from all the attractors in a high-dimensional embedding space. For training, we propose an algorithm for the co-optimization of bona fide speech clustering and bona fide/spoof classification. For inference, we propose strategies to enable anti-spoofing for speakers without enrollment. Our proposed system outperforms existing state-of-the-art single systems with a relative improvement of 38% on equal error rate (EER) on the ASVspoof2019 LA evaluation set.
4.Shift to Your Device Data Augmentation for Device-Independent Speaker Verification Anti-Spoofing
标题:转移到你的设备:数据增强设备无关的说话人验证反欺骗
作者:Junhao Wang, Li Lu, Zhongjie Ba, Feng Lin, Kui Ren
单位:School of Cyber Science and Technology, Zhejiang University, China
ZJU-Hangzhou Global Scientific and Technological Innovation Center, China
链接:https://ieeexplore.ieee.org/document/10097168
摘要:本文提出了一种新的DeAug反卷积增强数据增强方法,用于基于超声的说话人验证防欺骗系统,以检测物理访问中声源的活动性,旨在提高对未收集数据的未见设备的活动性检测性能。具体来说,DeAug首先对可用的收集数据进行维纳反卷积预处理,以生成增强的干净信号样本。然后,将生成的样本与不同的器件脉冲响应进行卷积,使信号具有未见器件的通道特性。在跨域数据集上的实验表明,本文提出的增强方法可使基于超声的防欺骗系统的性能相对提高97.8%,在多设备增强数据上进行域对抗训练后,性能可进一步提高43.4%。This paper proposes a novel Deconvolution-enhanced data Augmentation method, DeAug, for ultrasonic-based speaker verification anti-spoofing systems to detect the liveness of voice sources in physical access, which aims to improve the performance of liveness detection on unseen devices where no data is collected yet. Specifically, DeAug first employs a wiener deconvolution pre-processing on available collected data to generate enhanced clean signal samples. Then, the generated samples are convolved with different device impulse responses, to enable the signal with the unseen devices’ channel characteristics. Experiments on cross-domain datasets show that our proposed augmentation method can improve the performance of ultrasonic-based anti-spoofing systems by 97.8% relatively, and a further improvement of up to 43.4% can be obtained after applying domain adversarial training on multi-device augmented data.
Others
1.Conditional Conformer: Improving Speaker Modulation For Single And Multi-User Speech Enhancement
标题:条件Conformer:改善单用户和多用户语音增强的说话人调制
作者:Tom O’Malley, Shaojin Ding, Arun Narayanan, Quan Wang, Rajeev Rikhye, Qiao Liang, Yanzhang He, Ian McGraw∗
单位:Google LLC, U.S.A
链接:https://ieeexplore.ieee.org/document/10095369
摘要:最近,特征线性调制(FiLM)在将说话人嵌入到语音分离和voiceffilter模型中的表现优于其他方法。我们提出了一种改进的方法,将这种嵌入纳入语音过滤器前端,用于自动语音识别(ASR)和文本无关的说话人验证(TI-SV)。我们扩展了广泛使用的Conformer架构,在FiLM层之前和之后构造了一个具有附加特征处理的FiLM Block。除了应用于单用户VoiceFilter之外,我们还表明,通过投影空间中说话人嵌入的元素最大池化,我们的系统可以很容易地扩展到多用户VoiceFilter模型。最后一种架构,我们称之为条件一致性,它将说话人嵌入紧密地集成到一个一致性主干中。与之前的多用户voiceffilter模型相比,我们将TI-SV相等错误率提高了56%,并且与注意机制相比,我们的元素最大池将相对WER降低了10%。
Recently, Feature-wise Linear Modulation (FiLM) has been shown to outperform other approaches to incorporate speaker embedding into speech separation and VoiceFilter models. We propose an improved method of incorporating such embeddings into a VoiceFilter frontend for automatic speech recognition (ASR) and textindependent speaker verification (TI-SV). We extend the widelyused Conformer architecture to construct a FiLM Block with additional feature processing before and after the FiLM layers. Apart from its application to single-user VoiceFilter, we show that our system can be easily extended to multi-user VoiceFilter models via element-wise max pooling of the speaker embeddings in a projected space. The final architecture, which we call Conditional Conformer, tightly integrates the speaker embeddings into a Conformer backbone. We improve TI-SV equal error rates by as much as 56% over prior multi-user VoiceFilter models, and our element-wise max pooling reduces relative WER compared to an attention mechanism by as much as 10%.
2.Exploiting Speaker Embeddings for Improved Microphone Clustering and Speech Separation in ad-hoc Microphone Arrays
标题:利用说话人嵌入改进麦克风聚类和语音分离在特设麦克风阵列
作者:Stijn Kindt, Jenthe Thienpondt, Nilesh Madhu
单位:IDLab, Department of Electronics and Information Systems, Ghent University - imec, Ghent, Belgium
链接:
https://ieeexplore.ieee.org/document/10094862
摘要:为了分离由临时分布式麦克风捕获的源,关键的第一步是将麦克风分配到适当的源主导集群。用于这种(盲)聚类的特征是基于音频信号在高维潜在空间中的固定长度嵌入。在以前的工作中,嵌入是由Mel频率倒谱系数及其调制谱手工设计的。本文认为,为可靠地区分说话人而明确设计的嵌入框架将产生更合适的特征。我们提出由最先进的ECAPATDNN说话人验证模型生成的特征用于聚类。我们根据随后的信号增强以及聚类的质量对这些特征进行基准测试,进一步,我们为后者引入了3个直观的指标。结果表明,与手工设计的特征相比,基于ecapa - tdnn的特征在随后的增强阶段导致更多的逻辑聚类和更好的性能-从而验证了我们的假设。
For separating sources captured by ad hoc distributed microphones a key first step is assigning the microphones to the appropriate source-dominated clusters. The features used for such (blind) clustering are based on a fixed length embedding of the audio signals in a high-dimensional latent space. In previous work, the embedding was hand-engineered from the Mel frequency cepstral coefficients and their modulation-spectra. This paper argues that embedding frameworks designed explicitly for the purpose of reliably discriminating between speakers would produce more appropriate features. We propose features generated by the state-of-the-art ECAPATDNN speaker verification model for the clustering. We benchmark these features in terms of the subsequent signal enhancement as well as on the quality of the clustering where, further, we introduce 3 intuitive metrics for the latter. Results indicate that in contrast to the hand-engineered features, the ECAPA-TDNN-based features lead to more logical clusters and better performance in the subsequent enhancement stages - thus validating our hypothesis.
3.Perceptual Analysis of Speaker Embeddings for Voice Discrimination between Machine And Human Listening
标题:用于机器和人类听力之间的语音识别的说话人嵌入感知分析
作者:Iordanis Thoidis; Clément Gaultier; Tobias Goehring
单位:School of Electrical and Computer Engineering, Aristotle University of Thessaloniki, Thessaloniki, Greece;
Cambridge Hearing Group, MRC Cognition and Brain Sciences Unit, University of Cambridge, UK
链接:https://ieeexplore.ieee.org/document/10094782
摘要:这项研究调查了说话人嵌入捕获的与人类语音感知相关的信息。卷积神经网络经过训练,可以在干净和嘈杂的条件下执行一次性说话人验证,从而将说话人特定特征的高级抽象编码到潜在嵌入向量中。我们证明,可以通过使用训练损失函数来获得鲁棒且有辨别力的说话者嵌入,该函数可以在推理过程中优化嵌入以进行相似性评分。计算分析表明,此类说话人嵌入预测了各种手工制作的声学特征,而没有任何单个特征可以解释嵌入的实质性差异。此外,正如人类听众推断的那样,说话者嵌入空间中的相对距离与语音相似度适度一致。这些发现证实了机器和人类在辨别声音时听力之间的重叠,并激发了对剩余差异的进一步研究,以提高模型性能。
This study investigates the information captured by speaker embeddings with relevance to human speech perception. A Convolutional Neural Network was trained to perform one-shot speaker verification under clean and noisy conditions, such that high-level abstractions of speaker-specific features were encoded in a latent embedding vector. We demonstrate that robust and discriminative speaker embeddings can be obtained by using a training loss function that optimizes the embeddings for similarity scoring during inference. Computational analysis showed that such speaker embeddings predicted various hand-crafted acoustic features, while no single feature explained substantial variance of the embeddings. Moreover, the relative distances in the speaker embedding space moderately coincided with voice similarity, as inferred by human listeners. These findings confirm the overlap between machine and human listening when discriminating voices and motivate further research on the remaining disparities for improving model performance.