第五章 假设检验

问题导向:由正常男子血小板计数均值这句话,容易判断属于对均值进行检验的问题
H0:与正常男子无差异等于225 H1:与正常男子有差异,不等于225
x=c(220, 188, 162, 230, 145, 160, 238,
+ 188, 247, 113, 126, 245, 164, 231, 256, 183, 190, 158, 224, 175)
t.test(x,mu=225)
运行结果如下:
One Sample t-test
data: x
t = -3.4783, df = 19, p-value = 0.002516
alternative hypothesis: true mean is not equal to 225
95 percent confidence interval:
172.3827 211.9173
sample estimates:
mean of x
192.15
t.test()函数格式:
t.test(x,y=NULL,alternative=c('two.sided','less','greater',mu=0,conf.level=0.95)
x,y表示向量,alternative=c('two.sided','less','greater')备择假设,默认为'two.sided',双边检验,mu:均值,默认为零均值,conf.level:显著性水平,以上都是缺省时的默认值
p-value = 0.002516<0.05,拒绝原假设,油漆工人的血小板数与正常男子有差异,并且mean of x =192.15 <225,说明油漆工人的血小板数小于正常男子。

问题导向:求概率,求P{X>x}的值,x为1000
x=c(1067 ,919 ,1196 ,785,1126 ,936 , 918, 1156 , 920 ,948)
pnorm(1000,mean(x),sd(x)) #pnorm(x,mean(x),sd(x))求符合正态分布x的分布函数
[1] 0.5087941
#得P值为0.5087941,也就是P{X<x}=0.5087941,则P{X>x}=1-0.5087941=0.4912059

补充知识点:原假设和备择假设的选择,原假设一般为我们不希望的结果,是拿来拒绝的,不能轻易否定,等号在原假设中。备择假设是我们希望的结果,一般而言研究什么问题就放在备择假设中,先确定备择假设
该题目研究的是两种方法治疗贫血的效果,比较的是谁好谁坏,备择假设就选两者有差异
H0:两种方法治疗无差异 H1:两种方法治疗有差异
> A=c(113,120,138,120,100,118,138,123)
> B=c(138,116,125,136,110,132,130,110)
> t.test(A,B,paired=TRUE) #paired=TRUE,表示成对数据,缺省时为FALSE
Paired t-test
data: A and B
t = -0.65127, df = 7, p-value = 0.5357
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-15.628891 8.878891
sample estimates:
mean of the differences
-3.375
p-value = 0.5357>0.05,不能拒绝原假设,两种方法治疗无差异,效果相同
另外一种方法:
> t.test(A-B) #Z=A-B,对Z做单样本均值检验要优于双样本均值检验,成对数据的t检验
结果一样
One Sample t-test
data: A - B
t = -0.65127, df = 7, p-value = 0.5357
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
-15.628891 8.878891
sample estimates:
mean of x
-3.375

(1)H0:样本来自正态分布总体 H1:样本不来自正态分布总体
1.正态性W检验方法
> x=c(-0.7,-5.6,2,2.8,0.7,3.5,4,5.8,7.1,-0.5,2.5,-1.6,1.7,3,0.4,4.5,4.6,2.5,6,-1.4)
> y=c(3.7,6.5,5,5.2,0.8,0.2,0.6,3.4,6.6,-1.1,6,3.8,2,1.6,2,2.2,1.2,3.1,1.7,-2)
> shapiro.test(x)
Shapiro-Wilk normality test
data: x
W = 0.9699, p-value = 0.7527
> shapiro.test(y)
Shapiro-Wilk normality test
data: y
W = 0.97098, p-value = 0.7754
结果:x 和 y的P值都大于0.05,不能拒绝原假设,认为x和y都来自正态分布总体
2.Kolmogorov_Smirnov检验方法
> ks.test(x,"pnorm",mean(x),sd(x))
> #多说一句:如果x服从指数分布ks.test(x,'pexp','指数分布的参数')
One-sample Kolmogorov-Smirnov test
data: x
D = 0.10652, p-value = 0.9771
alternative hypothesis: two-sided
Warning message:
In ks.test(x, "pnorm", mean(x), sd(x)) :
ties should not be present for the Kolmogorov-Smirnov test
> ks.test(y,"pnorm",mean(y),sd(y))
One-sample Kolmogorov-Smirnov test
data: y
D = 0.11969, p-value = 0.9368
alternative hypothesis: two-sided
Warning message:
结果:x和y的P值都大于0.05,有显著的理由不能拒绝原假设,认为x和y都来自正态分布总体
3.pearson拟合优度检验
> sort(x) #先对x进行从小到大排序
[1] -5.6 -1.6 -1.4 -0.7 -0.5 0.4 0.7 1.7 2.0 2.5 2.5 2.8 3.0 3.5
[15] 4.0 4.5 4.6 5.8 6.0 7.1
> cut(x,br=c(-6,-3,0,3,6,9))#将变量分成若干小区间,br相当于在绘制频率分布直方图时,x轴构成的向量
[1] (-3,0] (-6,-3] (0,3] (0,3] (0,3] (3,6] (3,6] (3,6] (6,9]
[10] (-3,0] (0,3] (-3,0] (0,3] (0,3] (0,3] (3,6] (3,6] (0,3]
[19] (3,6] (-3,0]
Levels: (-6,-3] (-3,0] (0,3] (3,6] (6,9]
> t=table(cut(x,br=c(-6,-3,0,3,6,9)))#计算随机变量落在某个区间的频数
(-6,-3] (-3,0] (0,3] (3,6] (6,9]
1 4 8 6 1
> p=pnorm(c(-3,0,3,6,9),mean(x),sd(x))#我不理解这里的c(-3,0,3,6,9)
> p
[1] 0.04894712 0.24990009 0.62002288 0.90075856 0.98828138
> chisq.test(t,p=p)#P分布函数
Error in chisq.test(t, p = p) : probabilities must sum to 1.
报错,我也不明白。。。
(2)两组数据的均值检验
H0:两组数据均值无差异 ,均值相等 H1:两组数据均值有差异
1.方差相同模型t检验:
> t.test(x,y,var.equal=TRUE)
Two Sample t-test
data: x and y
t = -0.64187, df = 38, p-value = 0.5248
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.326179 1.206179
sample estimates:
mean of x mean of y
2.065 2.625
2.方差不同的模型t检验:
> t.test(x,y) #默认不相同
Welch Two Sample t-test
data: x and y
t = -0.64187, df = 36.086, p-value = 0.525
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.32926 1.20926
sample estimates:
mean of x mean of y
2.065 2.625
3.成对数据的t检验:
> t.test(x-y)
One Sample t-test
data: x - y
t = -0.64644, df = 19, p-value = 0.5257
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
-2.373146 1.253146
sample estimates:
mean of x
-0.56
结果:三种检验的P值都大于0.05,不能拒绝原假设,两组数据均值无差异
(3)对方差是否相同进行检验
H0:方差相同 H1:方差不相同
> var.test(x,y)
F test to compare two variances
data: x and y
F = 1.5984, num df = 19, denom df = 19, p-value = 0.3153
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.6326505 4.0381795
sample estimates:
ratio of variances
1.598361
结果:P值大于0.05,接受原假设,两组数据方差相同。

(1) H0:样本服从正态分布 H1:样本不服从正态分布
正态性检验,采用ks检验:
> a=c(126,125,136,128,123,138,142,116,110,108,115,140)
> b=c(162,172,177,170,175,152,157,159,160,162)
> ks.test(a,"pnorm",mean(a),sd(a)) #检验a
One-sample Kolmogorov-Smirnov test
data: a
D = 0.14644, p-value = 0.9266
alternative hypothesis: two-sided
> ks.test(b,"pnorm",mean(b),sd(b)) #检验b
One-sample Kolmogorov-Smirnov test
data: b
D = 0.22216, p-value = 0.707
alternative hypothesis: two-sided
Warning message: #不知道为什么有警告信息
In ks.test(b, "pnorm", mean(b), sd(b)) :
ties should not be present for the Kolmogorov-Smirnov test
结果:p-value = 0.9266>0.05,p-value = 0.707>0.05,有充分的理由不能拒绝原假设,认为两个样本都服从正态分布
(2)对方差进行检验
H0:方差相同 H1:方差不相同
> var.test(a,b)
F test to compare two variances
data: a and b
F = 1.9646, num df = 11, denom df = 9, p-value = 0.32
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.5021943 7.0488630
sample estimates:
ratio of variances
1.964622
结果:p-value = 0.32>0.05,不能拒绝原假设,认为a,b方差相同
(3)对均值进行检验
H0:均值相同 ,无差别 H1:均值不相同
> t.test(a,b,var.equal=TRUE)
Two Sample t-test
data: a and b
t = -8.8148, df = 20, p-value = 2.524e-08
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-48.24975 -29.78358
sample estimates:
mean of x mean of y
125.5833 164.6000
结果:p-value = 2.524e-08<0.05,拒绝原假设,新药组和对照组二者有差别

问题导向:二项分布的假设检验
H0: 支持该市老年人口比重14.7%的看法 H1:不支持该市老年人口比重14.7%的看法
> binom.test(57,400,p=0.147) #binom.test(成功次数,试验总次数,p=原假设概率)
Exact binomial test
data: 57 and 400
number of successes = 57, number of trials = 400, p-value = 0.8876
alternative hypothesis: true probability of success is not equal to 0.147
95 percent confidence interval:
0.1097477 0.1806511
sample estimates:
probability of success
0.1425
结果:p-value = 0.8876>0.05,支持该市老年人口比重14.7%的看法

问题导向:雏鸡分为母雏和公雏,性别比例为1:1,则原来公雏:母雏=1:1,各占1/2,属于二项分布的假设检验
H0: p=0.5 H1:p>0.5
> binom.test(178,328,p=0.5,alternative="greater") #第一种方法:成功次数,试验的总次数
Exact binomial test
data: 178 and 328
number of successes = 178, number of trials = 328, p-value = 0.06794
alternative hypothesis: true probability of success is greater than 0.5
95 percent confidence interval:
0.4957616 1.0000000
sample estimates:
probability of success
0.5426829
> binom.test(c(178,150),p=0.5,alternative="greater")
> #第二种方法:c(成功次数,失败次数)
Exact binomial test
data: c(178, 150)
number of successes = 178, number of trials = 328, p-value = 0.06794
alternative hypothesis: true probability of success is greater than 0.5
95 percent confidence interval:
0.4957616 1.0000000
sample estimates:
probability of success
0.5426829
两种方法结果是一样的,表达不同
结果:p-value = 0.06794>0.05,不能拒绝原假设,认为这种处理能增加母鸡的比例。

利用pearson卡方检验是否符合特定分布:
H0: 符合自由组合规律 H1:不符合自由组合规律
> chisq.test(c(315,101,108,32),p=c(9/16,3/16,3/16,1/16))#p为特定的分布,默认为均匀分布
Chi-squared test for given probabilities
data: c(315, 101, 108, 32)
X-squared = 0.47002, df = 3, p-value = 0.9254
结果:p-value = 0.9254>0.05,认为符合自由组合规律
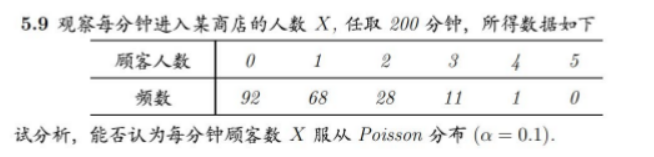
这里用pearson检验,泊松分布的均值就为参数
H0: X服从泊松分布 H1:X不服从泊松分布
> x =c(0, 1, 2, 3, 4, 5)
> y =c(92, 68, 28, 11, 1, 0)
> # 因为y的最后一组的频数小于5,卡方检验为出错,需要把最后两组和前面的合并
> y =c(92, 68, 28, 12)
> # 计算泊松分布的理论分布概率,其中,mean(rep(x,y))为样本均值
> q =ppois(x, mean(c(rep(0, 92), rep(1, 68), rep(2, 28), rep(3, 11), rep(4, 1), rep(5, 0))))
>
> q
[1] 0.4470879 0.8069937 0.9518558 0.9907271 0.9985500 0.9998094
> chisq.test(c(92, 68, 28, 12), p = c(q[1], q[2] - q[1], q[3] - q[2], 1 - q[3]))# 我一直都不明白为什么要减
Chi-squared test for given probabilities
data: c(92, 68, 28, 12)
X-squared = 0.91132, df = 3, p-value = 0.8227
错误的一种做法:
> ks.test(c(92, 68, 28, 11,10,0),'ppois',mean(c(rep(0, 92), rep(1, 68), rep(2, 28), rep(3, 11), rep(4, 1), rep(5, 0))))
One-sample Kolmogorov-Smirnov test
data: c(92, 68, 28, 11, 10, 0)
D = 0.83333, p-value = 4.287e-05
alternative hypothesis: two-sided
结果:p-value = 0.8227>0.05,X服从泊松分布
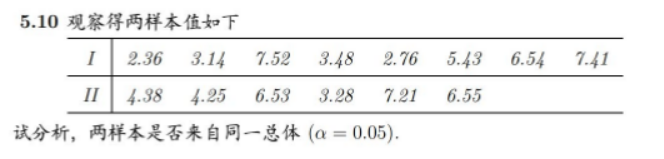
用双样本的ks检验
H0: 两分布相同 H1:两分布不相同
#ks检验 两个分布是否相同:
> x=c(2.36,3.14,752,3.48,2.76,5.43,6.54,7.41)
> y=c(4.38,4.25,6.53,3.28,7.21,6.55)
> ks.test(x,y)
Two-sample Kolmogorov-Smirnov test
data: x and y
D = 0.375, p-value = 0.6374
alternative hypothesis: two-sided
结果:p-value = 0.6374>0.05,认为两分布相同,来自同一个总体

列联表数据的独立性检验
研究的是使用检测仪对剖腹产有无影响
H0: 二者独立,无影响 H1:二者不独立 ,有影响
> x = c(358,2492,229,2745)
> dim(x)=c(2,2)#定义维度为2行2列
> chisq.test(x)
Pearson's Chi-squared test with Yates' continuity correction
data: x
X-squared = 37.414, df = 1, p-value = 9.552e-10
结果:p-value = 9.552e-10<0.05,拒绝原假设,认为使用检测仪对剖腹产有影响

列联表数据的独立性检验
H0: 二者独立 H1:二者不独立
> y=matrix(c(45 ,12 ,10 ,46 ,20, 28, 28,23 ,30 ,11 ,12,35),nrow=4,ncol=3) #默认为按列存放数据
>
> y
[,1] [,2] [,3]
[1,] 45 20 30
[2,] 12 28 11
[3,] 10 28 12
[4,] 46 23 35
> chisq.test(y)
Pearson's Chi-squared test
data: y
X-squared = 36.043, df = 6, p-value = 2.705e-06
p-value = 2.705e-06<0.05,拒绝原假设,A与B不独立,有关系。