前言
这两天为了搞硕士论文课题的创新点,在网上找了大量的开源项目代码进行实验,但是很可惜每次跑完demo之后就不知道干啥了(主要还是练习少了,很多代码看不董,不知道为何要这么用),归根结底还是自己在深度学习的基础代码上面的知识学的很不扎实(尤其是构建网络这些,应该自己取搭建一下)。所以趁着距离开题还有1个月,我准备返璞归真,取把一些基础的深度学习代码自己复现一下。
本期主要复现resnet18这个网路,以及残差块ResidualBlock的网络结构(pytorch),看看它们到底是怎么运作的,学习一下。
本期代码:完全参考B站上 跟着李沐学AI的视频:
参考视频
李沐老师的教材:https://zh-v2.d2l.ai/chapter_convolutional-modern/resnet.html#id4
我也相当于是跟着老师的视频自己敲了一遍
一、卷积的相关计算公式(复习)
在此之前呢,我也已经把卷积的具体计算公式遗忘的差不多了(尤其是加入了padding,strade这些参数),所以这里我稍微复习一下:
对于长和宽来说:
经过卷积后的尺寸=(输入尺寸-卷积核尺寸+2×padding)/步长+1
这里我们来做点测试:
import torch
from torch import nn
#高宽保持不变的3x3卷积
X=torch.rand(4,3,512,512)
print(X.shape)
conv2=nn.Conv2d(in_channels=3,out_channels=3,kernel_size=3,stride=1,padding=1,)
Y=conv2(X)
print(Y.shape)
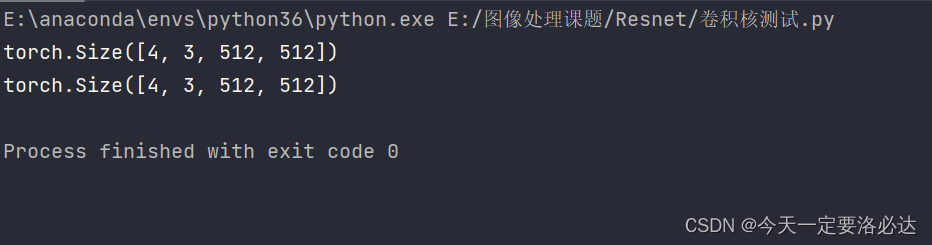
这里可以看到高宽都没变,这是一个经典的卷积核结构(311)
我们再试一个(步长改为2):
import torch
from torch import nn
#高宽减半的3x3卷积
X=torch.rand(4,3,512,512)
print(X.shape)
conv2=nn.Conv2d(in_channels=3,out_channels=3,kernel_size=3,stride=2,padding=1,)
Y=conv2(X)
print(Y.shape)
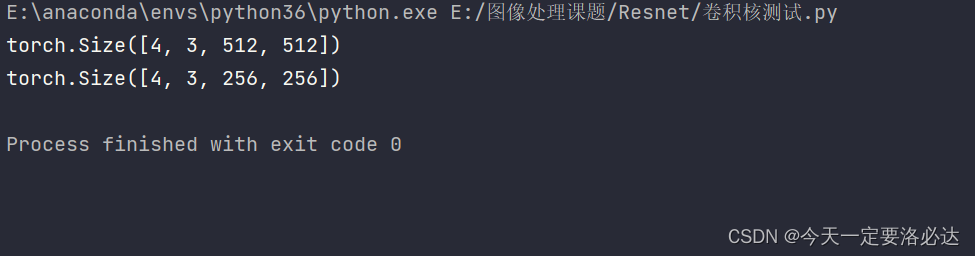
在这里,高宽都变为2了,这也是经典的结构(321)
顺带一提,改变通道数就很简单了,直接写出输入的通道数,输出想要的通道数:
import torch
from torch import nn
X=torch.rand(4,3,512,512)
print(X.shape)
conv2=nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1,)
Y=conv2(X)
print(Y.shape)

如图所示通道数从3变成了64
二、残差块ResidualBlock复现(pytorch)
在老师的视频里面,一共提到了两种作用的残差块:
1)高宽减半(h,w),通道数翻倍。这是因为卷积的步长设为了2。
2)高宽不变,通道数也不变。这是因为卷积的步长设为了1
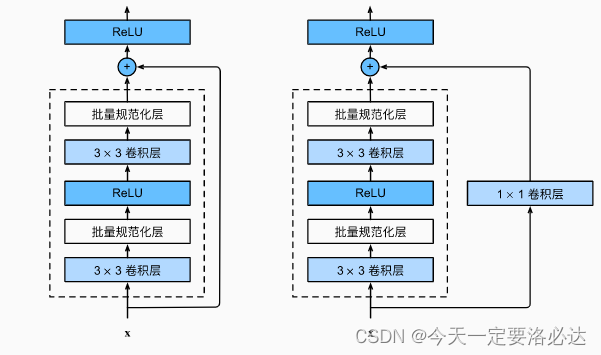
这个图也是抄的老师书上的。
具体的实现过程代码如下(老师视频里的):
import torch
from torch import nn
import torch.nn.functional as F #forward函数里面会用到F.relu()
class ResidualBlock(nn.Module): #M一定要大写,这是一个经常烦的错误
#构造方法(构造函数中至少需要传入2个参数:进出的通道数。残差块的一个最主要的作用就是改变信号的通道数)
def __init__(self,in_channles,num_channles,use_1x1conv=False,strides=1): #第三个参数是是否使用1x1卷积
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(
in_channles,num_channles,kernel_size=3,stride=strides,padding=1,) #默认为311结构 宽高不会变,但把步长改为2,就会变
self.conv2 = nn.Conv2d(
num_channles, num_channles, kernel_size=3, padding=1) #默认这里宽高也不会变,但把步长改为2,就会变
if use_1x1conv:
self.conv3=nn.Conv2d(
in_channles,num_channles,kernel_size=1,stride=strides) #这里相当于就是残差连接了
else:
self.conv3=None
self.bn1=nn.BatchNorm2d(num_channles) #批归一化
self.bn2=nn.BatchNorm2d(num_channles)
self.relu=nn.ReLU(inplace=True) #节省内存
def forward(self,x):
y= F.relu(self.bn1(self.conv1(x)))
y=self.bn2(self.conv2(y))
if self.conv3:
x=self.conv3(x)
y+=x
return F.relu(y) #在forward里的relu是这样调用的
本来想自己复现的,结果发现运行出来一直有问题,有时间我会补在下面。
我们再来看看上面的代码:
1)use_conv3为ture时,会执行宽高减半,通道数增倍的操作,属于是第一种残差块。
2)use_conv3为false时,会执行宽高不变,通道数不变的操作,属于是第二种残差块。
3)forward里面的 y+=x相当于实现了残差连接的作用。这里的x也有两种情况(后面的if能体现出来):原本输入到残差块里的x,以及高宽减半通道数增倍的x。所以要实现残差连接还是很简单的,直接在forward里添加上最开始的输入就行。
4)残差块里的conv1和conv2不会改变输入的高宽(经典311结构,311是不会改变高宽的)
5)forward里使用Relu是从F中使用,self.relu更多用在构建网络结构上,F.relu用在forward上。
三、残差网络ResNet18复现(pytorch)
首先我们看看论文里的resnet18的结构(值得一提的是,这里的2个小残差块合成了更大的残差块):
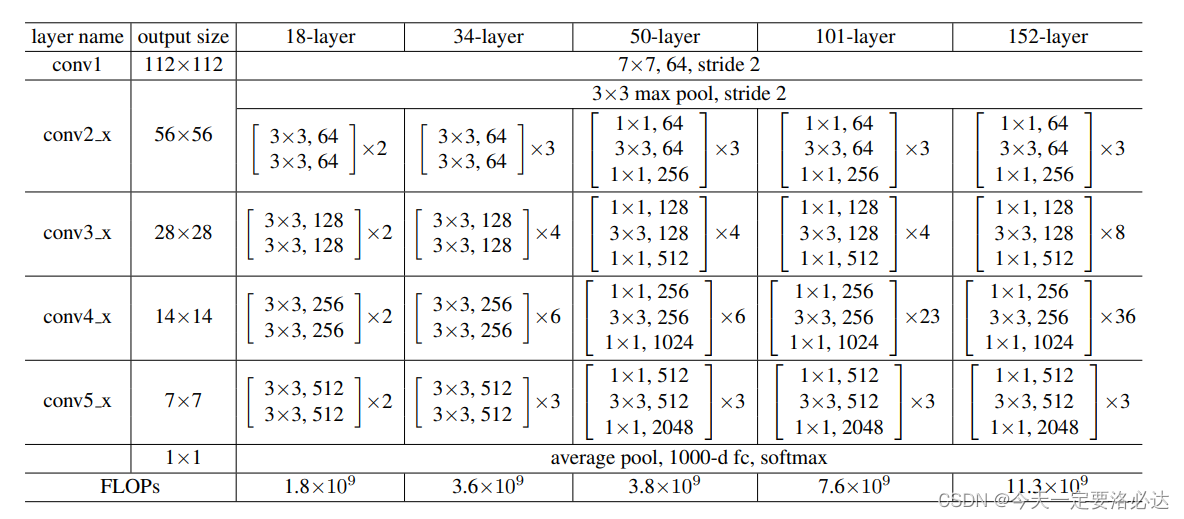
如果还要看更高清的网络结构,可以在网上找,我这里就不偷了。
整个网络结构解读如下:
1)conv1:最开始输入是3x224x224,conv1是64个7x7,步长为2的卷积块,经过之后输出为64x112x112;步长为2的3x3最大池化,输出为 64x56x56。
2)conv2:由两个高宽不变的残差块构成输出是64x56x56 (相当于 第二部分的第一个残差块是个异端,跟后面不太一样)
3)conv3:由一个高宽减半,通道数增倍的残差块,以及一个高宽不变的残差块构成输出是128x28x28
4)conv4:由一个高宽减半,通道数增倍的残差块,以及一个高宽不变的残差块构成输出是256x14x14
5)conv5:由一个高宽减半,通道数增倍的残差块,以及一个高宽不变的残差块构成输出是512x7x7
6)剩下的部分:一个池化,一个全连接层
紧接着我们来一步步定义
#搭建ResNet18网络
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def ResidualBlock_big(input_channels, num_channels, num_residuals,
first_block=False): #参数分别是进出的通道数,小残差快的个数,判断是否为第一个大残差块
blk = []
for i in range(num_residuals): #高宽减半,通道数加倍
if i == 0 and not first_block:
blk.append(ResidualBlock(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(ResidualBlock(num_channels, num_channels)) #如果是第一大残差快的小残差块,不需要让高宽减半
return blk
b2 = nn.Sequential(*ResidualBlock_big(64, 64, 2, first_block=True)) #判断是不是4个残差快中的第1个,第1个残差快不用做减半(因为前面已经减半很多了)
b3 = nn.Sequential(*ResidualBlock_big(64, 128, 2))
b4 = nn.Sequential(*ResidualBlock_big(128, 256, 2))
b5 = nn.Sequential(*ResidualBlock_big(256, 512, 2))
ResNet18 = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10)) #剩下三层
这里def函数 用来定义大的残差块,前面我们也提到有一个异端的残差块,所以这里的if else就是来判断它的,最后返回的是一个列表,后面的b2 = nn.Sequential(*ResidualBlock_big(64, 64, 2, first_block=True)) 里面的 *是把列表里面的内容取出来的意思,我们看看就知道为什么了:
import torch
from torch import nn
import torch.nn.functional as F
class ResidualBlock(nn.Module): #M一定要大写,这是一个经常烦的错误
#构造方法(构造函数中至少需要传入2个参数:进出的通道数。残差块的一个最主要的作用就是改变信号的通道数)
def __init__(self,in_channles,num_channles,use_1x1conv=False,strides=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(
in_channles,num_channles,kernel_size=3,stride=strides,padding=1,)
self.conv2 = nn.Conv2d(
num_channles, num_channles, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3=nn.Conv2d(
in_channles,num_channles,kernel_size=1,stride=strides)
else:
self.conv3=None
self.bn1=nn.BatchNorm2d(num_channles)
self.bn2=nn.BatchNorm2d(num_channles)
self.relu=nn.ReLU(inplace=True)
def forward(self,x):
y= F.relu(self.bn1(self.conv1(x)))
y=self.bn2(self.conv2(y))
if self.conv3:
x=self.conv3(x)
y+=x
return F.relu(y)
blk=[]
blk.append(ResidualBlock(64, 64,use_1x1conv=False, strides=1))
blk.append(ResidualBlock(64, 128,use_1x1conv=True, strides=2))
print(blk)
我们打印一下结构:
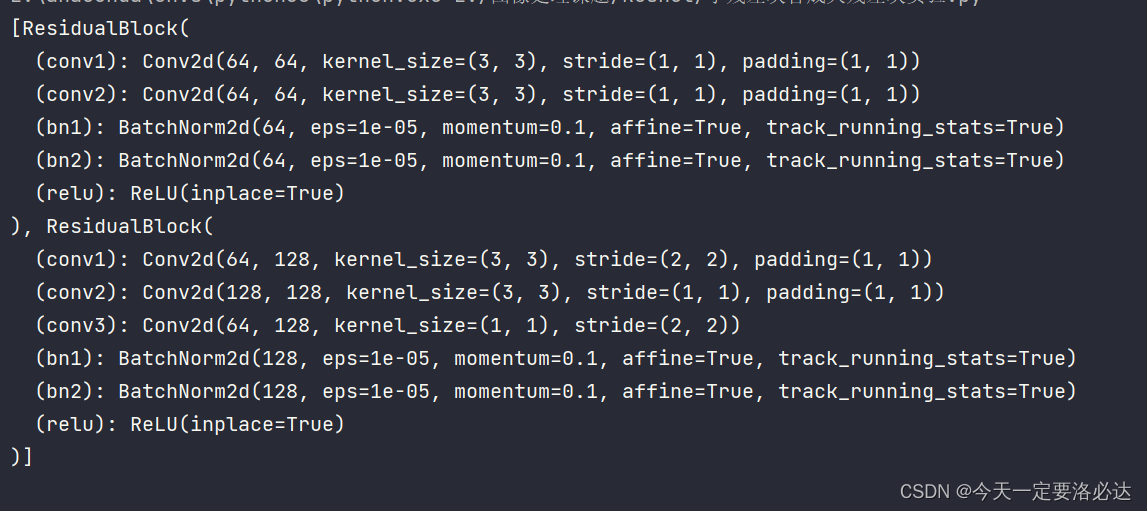
如果在前面加一个* :
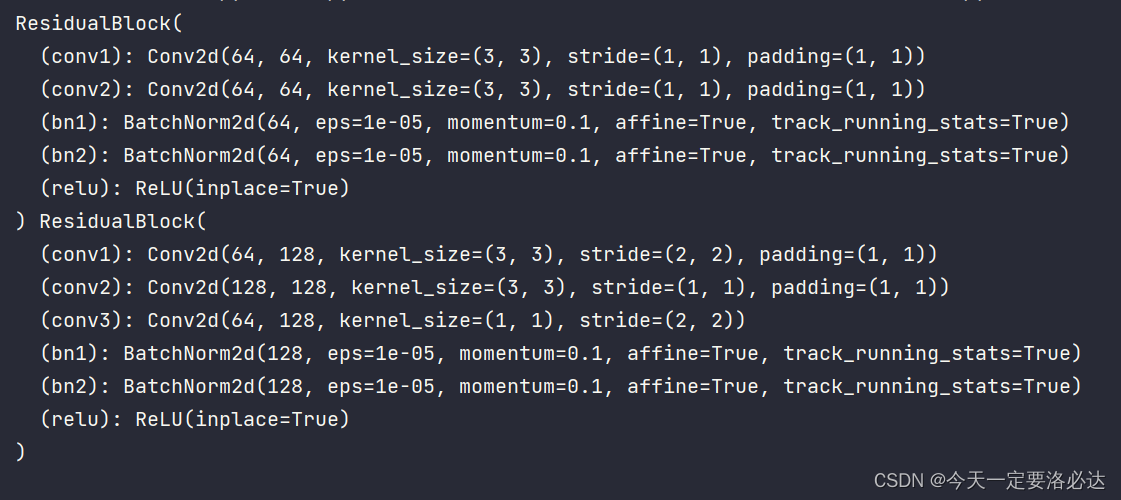
最后老师的教材给出了一种展示网络输出的方法:
X = torch.rand(size=(1, 1, 224, 224))
#打印网络结构
print(ResNet18)
for layer in ResNet18:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
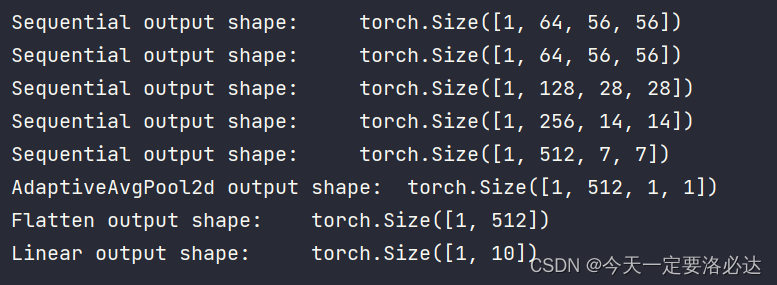
我们也print打印展示一下(展示部分):
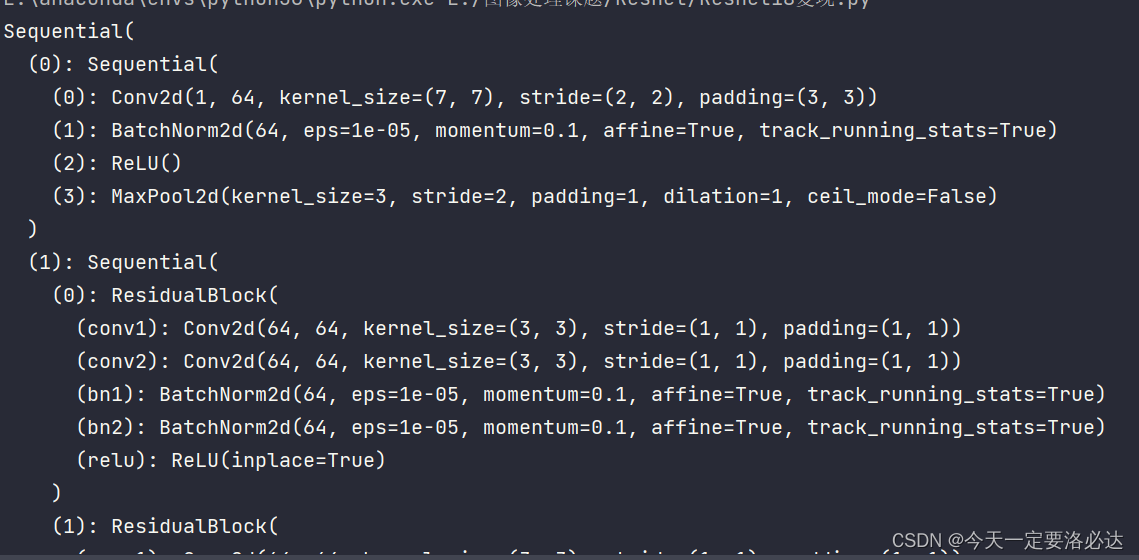
当然这个结构感觉有点乱,有时间我还是要自己复现一下
四、直接调用方法
实现完毕后,感觉自己的基础知识又夯实了一些,为以后的网络架构创新新添了动力。
当然一般情况下都是直接调用resnet18使用,更方便些:
resnet18=models.resnet18(progress=True)
五、具体实践(ResNet进行猫狗分类)
文件夹我们要弄好(猫狗的数据集):
我们首先进行数据加载:
import torch
import torch.nn as nn
import hiddenlayer as hl
import torchvision.datasets as datasets
from torchvision import transforms
from torchvision import models
import torch.utils.data as Data
from tqdm import tqdm
transforms=transforms.Compose([
transforms.RandomResizedCrop(512),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
])
train_data = datasets.ImageFolder('data/train',transform=transforms)
test_data=datasets.ImageFolder('data/test',transform=transforms)
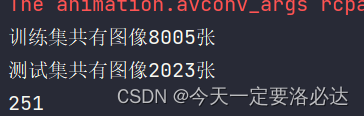
print("训练集共有图像{}张".format(len(train_data.imgs)))
print("测试集共有图像{}张".format(len(test_data.imgs)))
train_data_loader=Data.DataLoader(train_data,batch_size=32,shuffle=True,num_workers=0)
test_data_loader=Data.DataLoader(test_data,batch_size=32,shuffle=True,num_workers=0)
我们查看一下标签b_y长啥样(imagefolder会自动生成标签):
for step, (b_x, b_y) in enumerate(train_data_loader):
if step >0:
break
print(b_y)
print(len(b_y)) #len(b_y)就是batch_size

紧接着定义网络:
resnet18=models.resnet18(progress=True).to(device)
设置学习率等参数:
LR = 0.003
optimizer = torch.optim.Adam(resnet18.parameters(), lr=LR) #优化器
loss_func = nn.CrossEntropyLoss() # 损失函数,这里是多分类问题,可以用交叉熵
训练过程:
# 记录训练过程的指标
history1 = hl.History()
# 使用Canvas进行可视化
canvas1 = hl.Canvas()
train_num = 0
val_num = 0
## 对模型进行迭代训练,对所有的数据训练EPOCH轮
for epoch in range(10):
train_loss_epoch = 0
val_loss_epoch = 0
train_corrects=0
val_corrects=0
## 对训练数据的迭代器进行迭代计算
loop1 = tqdm(enumerate(train_data_loader), total=len(train_data_loader) - 1)
for step, (b_x, b_y) in loop1:
b_x=b_x.to(device) #数据传到显卡上
b_y = b_y.to(device)
resnet18.train()
## 使用每个batch进行训练模型
output = resnet18(b_x)
loss = loss_func(output, b_y)
optimizer.zero_grad() # 每个迭代步的梯度初始化为0
loss.backward() # 损失的后向传播,计算梯度
optimizer.step() # 使用梯度进行优化
train_loss_epoch += loss.item() * b_x.size(0)
train_num = train_num + b_x.size(0)
loop1.set_description(f'Epoch [{epoch}/{10 - 1}]')
loop1.set_postfix(train_loss=train_loss_epoch / train_num)
train_loss = train_loss_epoch / train_num
loop2 = tqdm(enumerate(test_data_loader), total=len(test_data_loader) - 1)
## 使用每个batch进行验证模型
for step, (b_x, b_y) in loop2:
b_x = b_x.to(device) # 数据传到显卡上
b_y = b_y.to(device)
resnet18.eval()
output = resnet18(b_x)
loss = loss_func(output, b_y)
val_loss_epoch += loss.item() * b_x.size(0)
val_num = val_num + b_x.size(0)
## 计算一个epoch的损失
loop2.set_description(f'Epoch [{epoch}/{10 - 1}]')
loop2.set_postfix(val_loss = val_loss_epoch / val_num)
val_loss = val_loss_epoch / val_num
## 保存每个epoch上的输出loss
history1.log(epoch, train_loss=train_loss,
val_loss=val_loss)
# 可视网络训练的过程
with canvas1:
canvas1.draw_plot([history1["train_loss"], history1["val_loss"]])
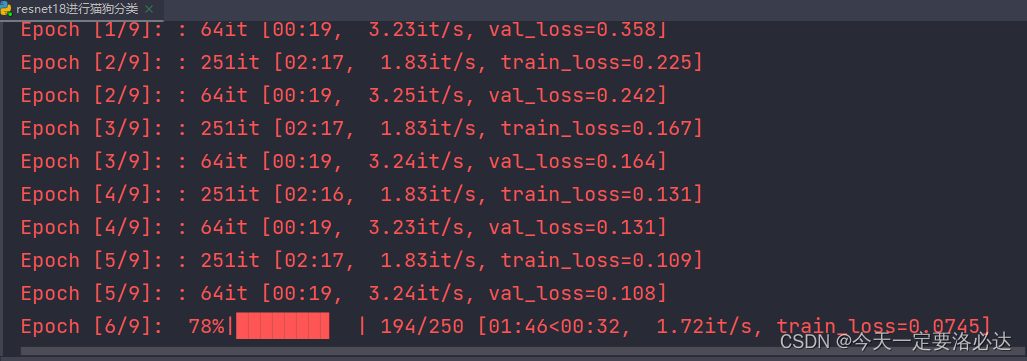
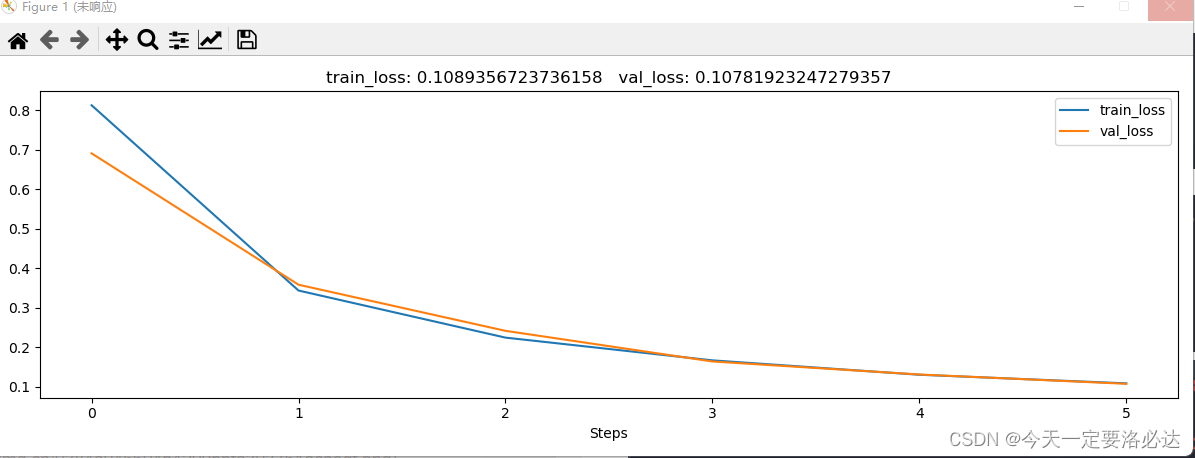
可以看出,loss下降的很快,我这里只给出train的过程,test没写了,也很简单
六.可能报错
6.1.TypeError: init() takes 2 positional arguments but 4 were given
这里报错是因为使用transforms.Compose([时,没有打最里面的那个括号【】