BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Unified Vision-Language Understanding and Generation)
Abstract
Vision-Language Pre-training(VLP)已经提高了许多vision-language tasks的性能,但是:
- 现存的大多数pre-trained models仅在understanding-based tasks或generation-based tasks表现较好,很少有在二者上都能取得良好性能的model
- 性能的改进大多是通过扩大dataset实现的,而从网上搜集的image-text pairs是noisy的
本文提出了BLIP:
- 一个新的VLP框架
- 能灵活地解决understanding-based tasks和generation-based tasks
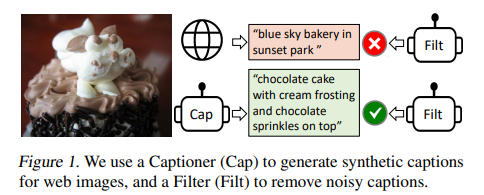
- 通过一个captioner生成synthetic captions和一个filter去除noisy的文字信息,处理网上noisy的数据,最终生成bootstrapping dataset
下游任务:
- image-text retrieval(+2.7% in average recall@1)
- image captioning(+2.8% in CIDEr)
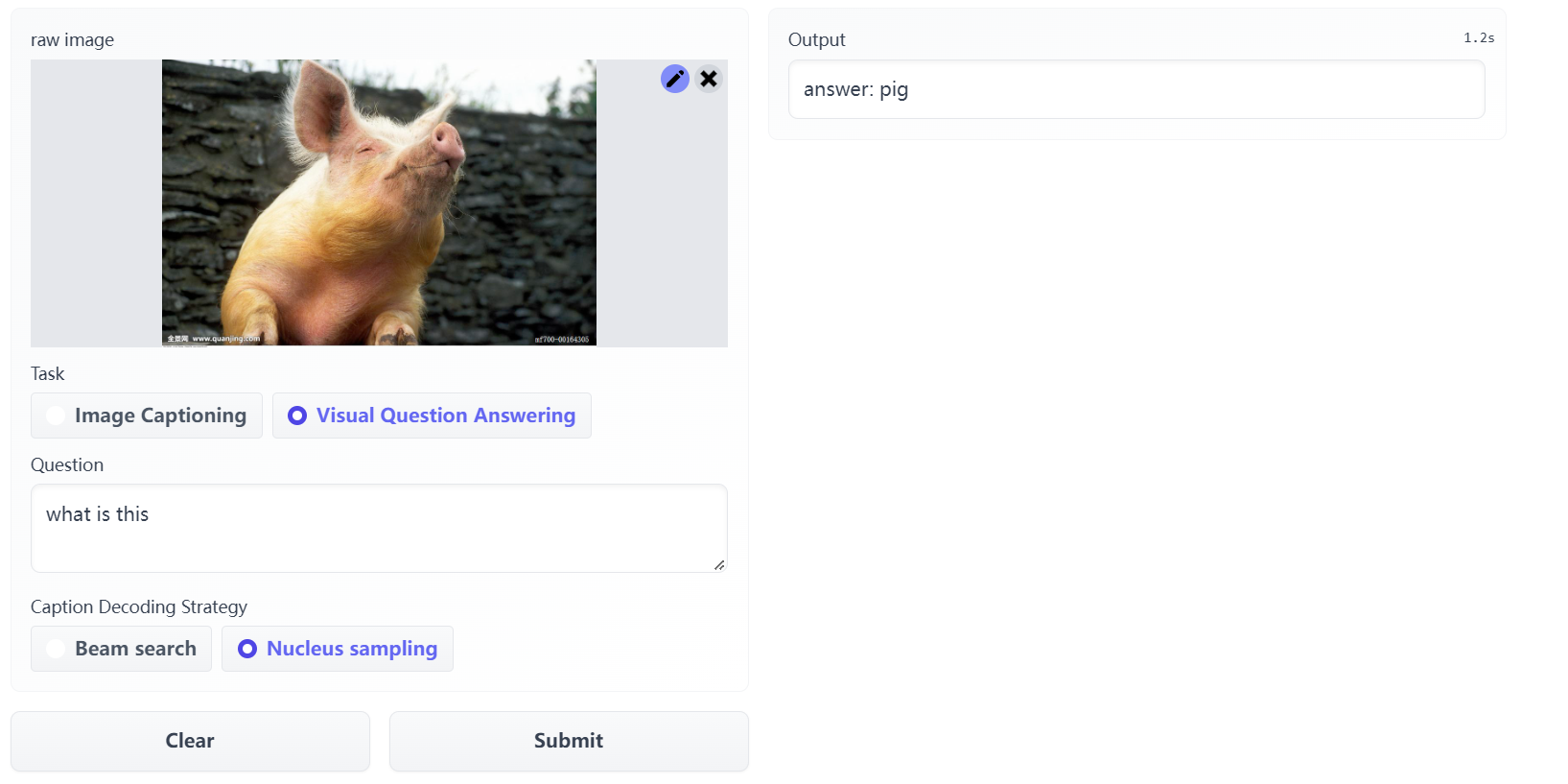
- VQA (+1.6% in VQA score)
BLIP可以以zero-shot的方式直接转移到video-language tasks上
1.Introduction
现有VLP的两个局限性:
- 模型角度:使用的大部分是encoder-based model或encoder-decoder model。但encoder-based model难以直接转化到文本生成的任务上(如image captioning);encoder-decoder model还不能用于image-text retrieval tasks
- 数据角度:大多SOTA的方法都是从网上搜集的image-text pairs,尽管能以扩大数据集的方式提升性能,但这些noisy的数据对vision-language learning来说不是最好的
BILP的两个贡献:
- Multimodal mixture of Encoder-decoder(MED):MED可以作为unimodal encoder或image-grounded text encoder或image-grounded text decoder。与三个vision-language objectives联合训练:image-text contrastive learning, image-text matching, 和 image-conditioned language modeling
- Captioning and Filtering (CapFilt):一种从noisy image-text pairs中进行bootstrapping的方法。将pre-trained MED分为两部分进行fintune:一个captioner从网上的图像中生成synthetic captions;一个filter用于从原始的数据和synthetic texts中去除noisy captions
2.Method
使用visual transformer作为image encoder,将输入的图像划分为patches并且将他们编码为一系列embeddings,并用额外的[CLS] token来表示图像的全局特征。并且对于视觉特征提取来说,使用visual transformer比使用pre-trained object detectors进行更易于计算
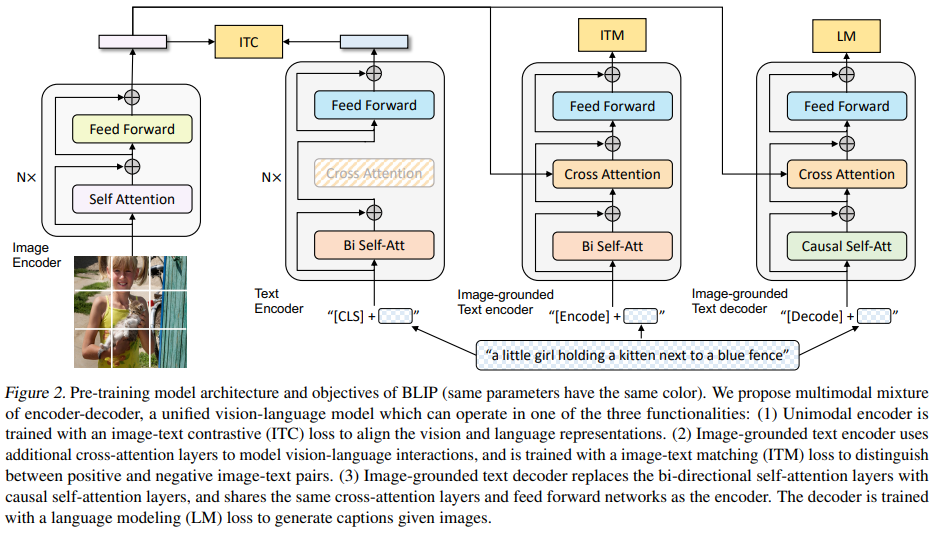
2.1 MED
- Unimodal encoder:分别对图像和文本进行编码。文本编码器与BERT相同,将[CLS] token加到输入文本的开头来总结句子
- Image-grounded text encoder:通过在text encoder的每个self-attention(SA) layer和feed forward network(FFN) layer之间插入一个额外的cross-attention(CA) layer来注入视觉信息。文本中附加的[Encode] token中输出的embedding用于image-text pair的多模态表示信息
- Image-grounded text decoder:将Image-grounded text encoder中的bi-directional self-attention layers替换为causal self-attention layers。[Decode] token用于表示序列的开始,end-of-sequence token表示结束
2.2 Pre-trained Objectives
在pre-train时用了三个objectives,包括两个understanding-based objectives和一个generation-based objective。对每个image-text pair只需在计算量较大的visual transformer上向前传播一次,并在text transformer上向前传播三次,用不同的函数计算下列的三个损失函数
- Image-Text Contrastive Loss(ITC):用于unimodal encoder。通过鼓励positive image-text pairs对相似的表示,而negative pairs相反,来对齐visual transformer和text transformer的特征空间。引入momentum encoder来产生特征,并从其产生的soft labels作为训练目标
ALBEF相关论文
- Image-Text Matching Loss(ITM):用于image-grounded text encoder。旨在学习image-text multimodal representation。用ITM头来预测image-text pairs 是正的还是负的
- Language Modeling Loss(LM):用于image-grounded text decoder。旨在生成给定图像的文本描述。与广泛用于VLP的MLM loss相比,LM有能将视觉信息转换为连贯字幕的泛化能力
- 为了预训练更高效,text encoder和text decoder共享除 SA 层之外的所有参数
2.3 CapFilt

- 数据集:COCO
- (Iw,Tw)为web image-text pair;(Ih,Th)为人工标注的image-text pair
- 包括两个模块:给web图片生成caption的captioner、去除noisy image-text pairs的filter。二者都是从相同的pre-trained MED model初始化的,并在COCO数据集上单独finetun
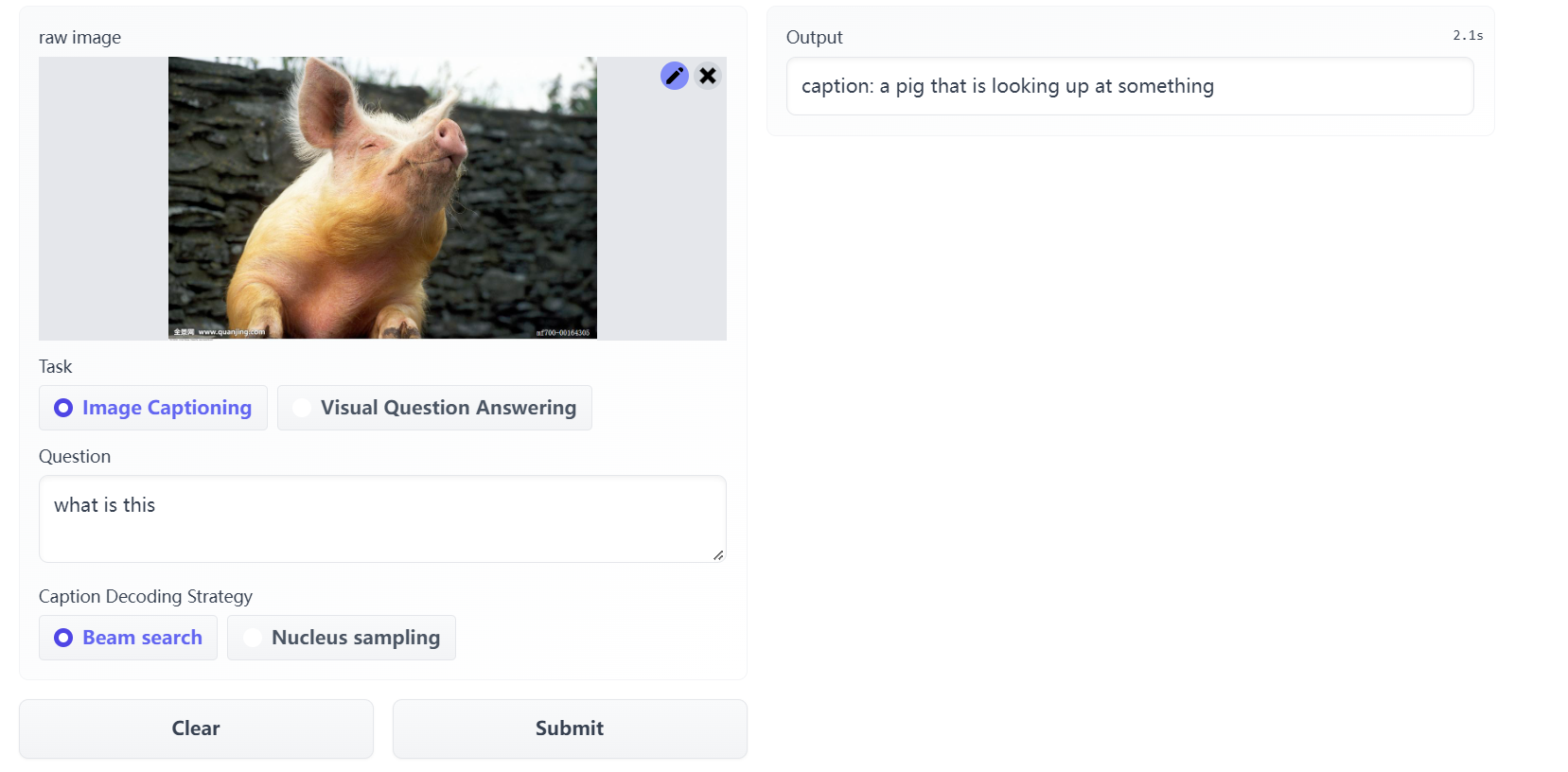
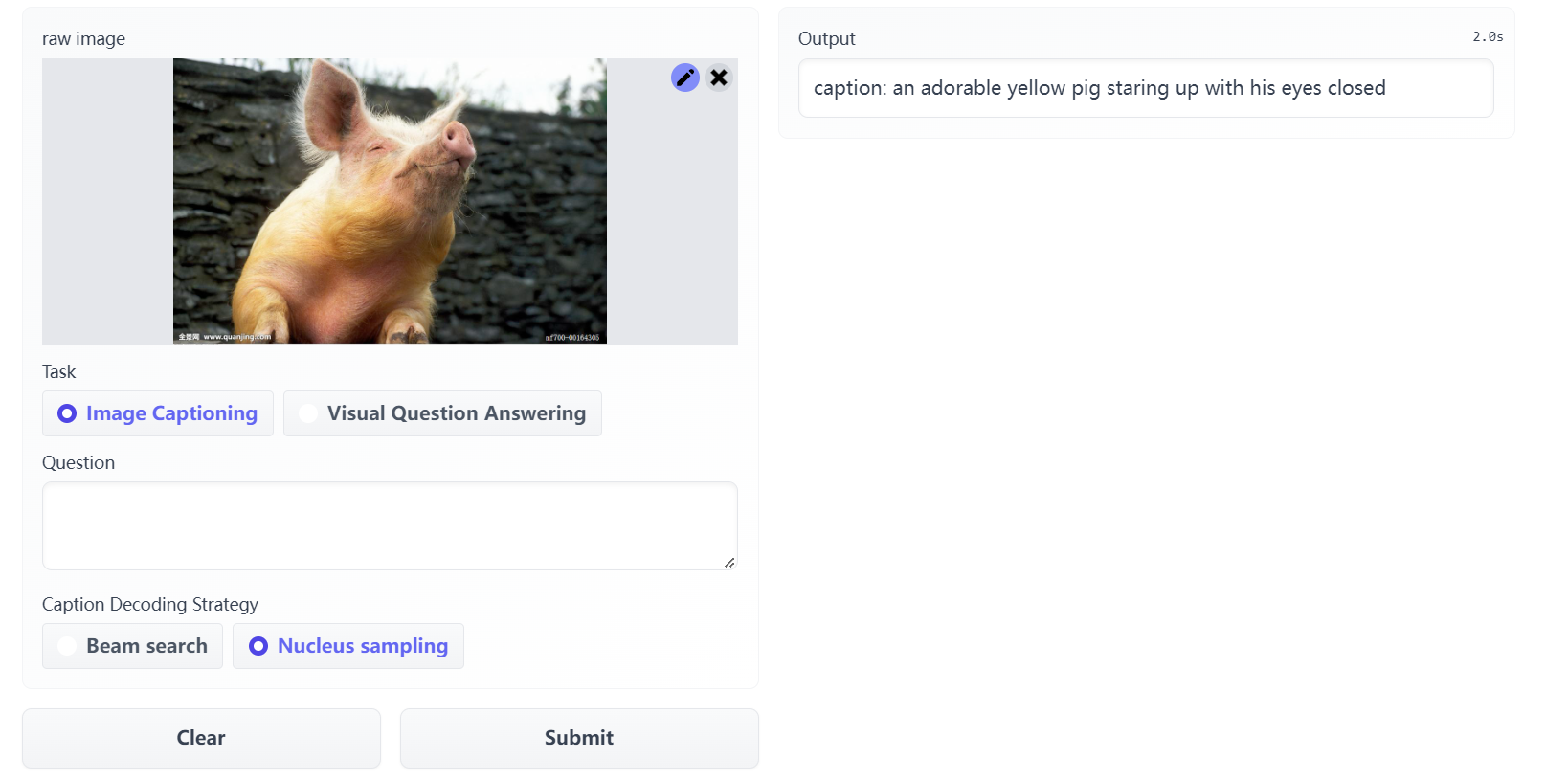
- captioner:是一个image-grounded text decoder,用LM进行finetun,以解码给定图像的文本。对于给定的web图像Iw,captioner生成synthetic captions Ts,每张图片都有对应的caption
- filter:是一个image-grounded text encoder,用ITC和ITM进行finetun,以判断图像和文本是否匹配。如果ITM头预测文字与图像不匹配,则认为该文字noisy,并去除。最后将过滤后的image-text pairs与人工标注的pairs合并为一个新的数据集,并用于pre-train一个新的model


3.Experiments
数据集:
- 两个人工标注的数据集:COCO, Visual Genome
- 三个web数据集:Conceptual Captions, Conceptual 12M, SBU captions
- 一个额外的web数据集:LAION(包括115M的有更多noisy文本的图像)
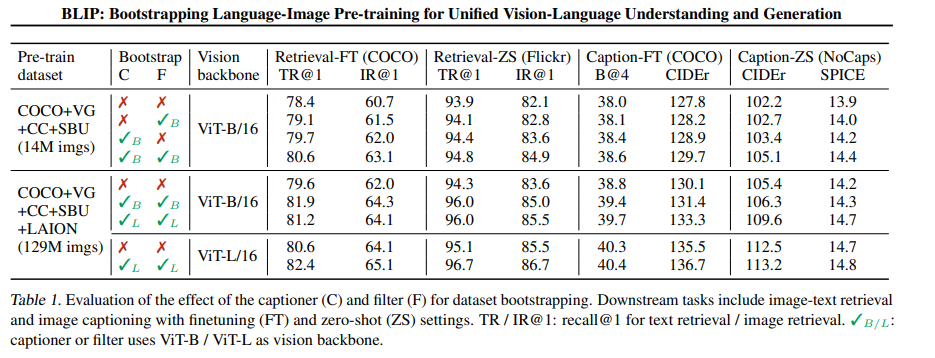
caption和filter的影响

beam search和nucleus sampling对生成synthetic caption的影响
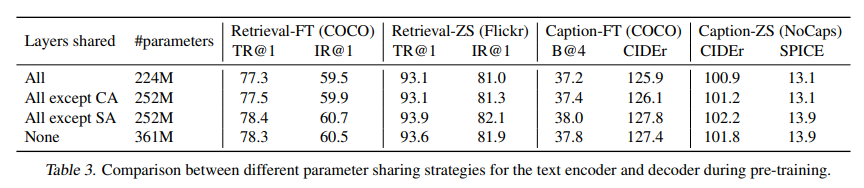
参数共享策略的影响

caption与filter之间共享参数的影响
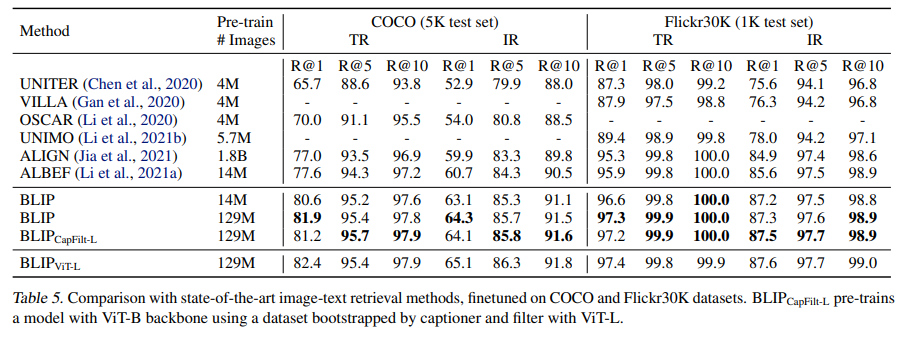
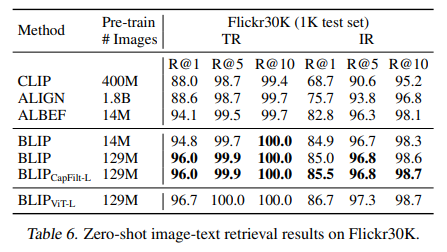
与SOTA的image-text retrieval方法的比较
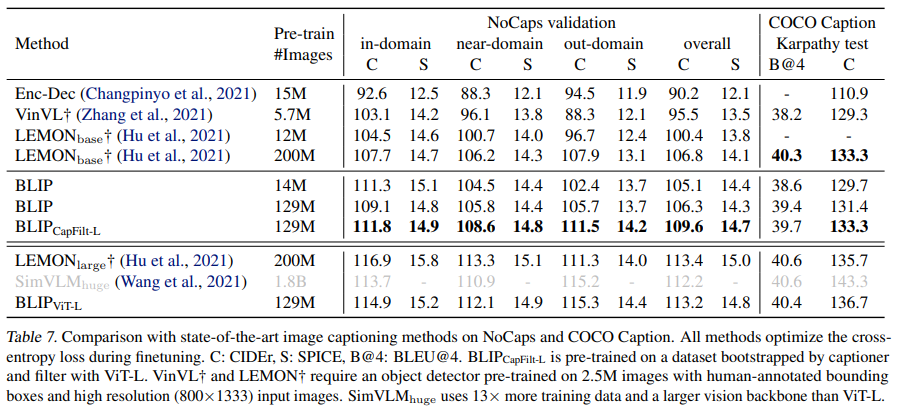
与SOTA的image caption方法的比较
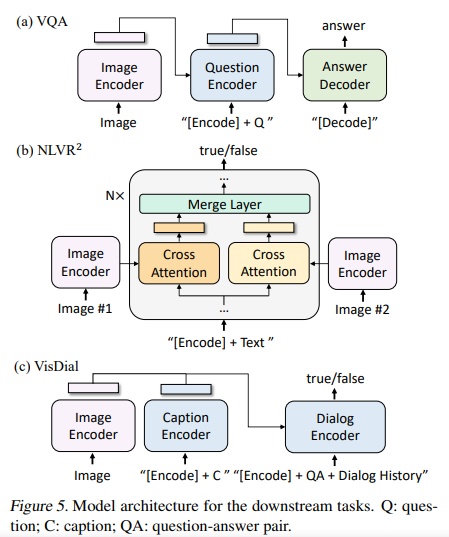
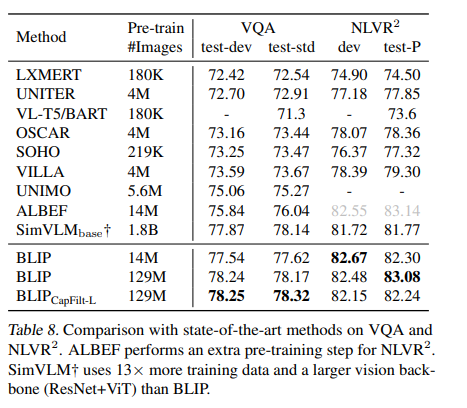
与SOTA的VQA和NLVR的比较

与SOTA的VisDial的比较
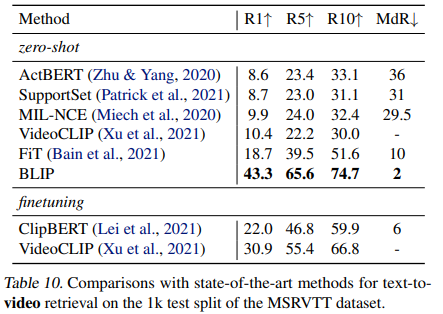
与SOTA的text-to-video retrieval方法的比较
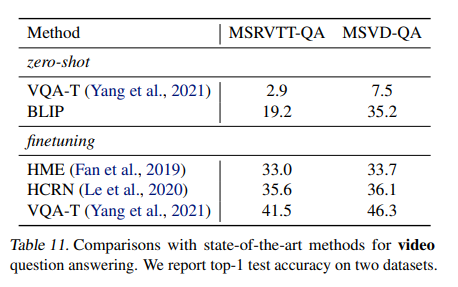
与SOTA的video question answering的比较
4.Conclusion
提高BLIP性能的潜在方法:
- 进行多轮数据集bootstrapping
- 为每张图片生成多个synthetic caption以扩大语料库
- 训练多个不同的captioner和filter进行model ensemble