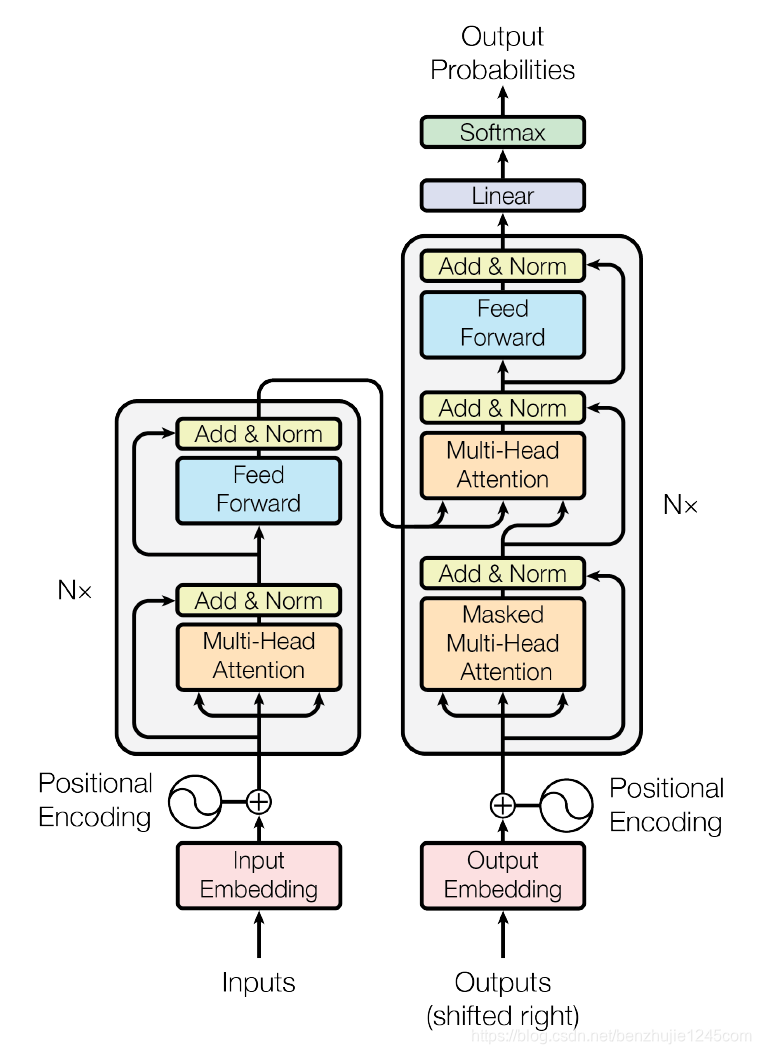
首先计算 Q 和 K 之间的点积,为了防止其结果过大,会除以
d
k
\sqrt{d_{k}}
dk,其中
d
k
d_{k}
dk 为 Key 向量的维度。
然后利用 Softmax 操作将其结果归一化为概率分布,再乘以矩阵 V 就得到权重求和的表示。
整个计算过程可以表示为:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V 为了更好的理解 Self-Attention,下面我们通过具体的例子进行详细说明。
第 1 步:计算 Query,Key 和 Value 矩阵。首先,将所有词向量放到一个矩阵
X
\boldsymbol{X}
X 中,然后分别和 3 个我们训练过的权重矩阵(
W
Q
\boldsymbol{W^Q}
WQ,
W
k
\boldsymbol{W^k}
Wk 和
W
V
\boldsymbol{W^V}
WV) 相乘,得到
Q
\mathbf{Q}
Q,
K
\boldsymbol{K}
K 和
V
\boldsymbol{V}
V 矩阵。
图 1.16 矩阵 X 中的每一行,表示输入句子中的每一个词的词向量(长度为 512,在图中为 4 个方框)。矩阵 Q,K 和 V 中的每一行,分别表示 Query 向量,Key 向量和 Value 向量(它们的长度都为 64,在图中为 3 个方框)。
在 Transformer 论文中,通过添加一种多头注意力机制,进一步完善了自注意力层。具体做法:首先,通过
h
h
h 个不同的线性变换对 Query、Key 和 Value 进行映射;然后,将不同的 Attention 拼接起来;最后,再进行一次线性变换。基本结构如图 1.18 所示:
图 1.18
每一组注意力用于将输入映射到不同的子表示空间,这使得模型可以在不同子表示空间中关注不同的位置。整个计算过程可表示为:
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
⋯
,
h
e
a
d
h
)
W
O
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
MultiHead(Q,K,V) = Concat(head_1,\cdots,head_h)\boldsymbol{W}^O \\ head_i = Attention(Q\boldsymbol{W}_i^Q,K\boldsymbol{W}_i^K,V\boldsymbol{W}_i^V)
MultiHead(Q,K,V)=Concat(head1,⋯,headh)WOheadi=Attention(QWiQ,KWiK,VWiV) 其中,
W
i
Q
∈
R
d
m
o
d
e
l
×
d
k
\boldsymbol{W}_i^Q \in \mathbb{R}^{d_{model} \times d_k}
WiQ∈Rdmodel×dk,
W
i
K
∈
R
d
m
o
d
e
l
×
d
k
\boldsymbol{W}_i^K \in \mathbb{R}^{d_{model} \times d_k}
WiK∈Rdmodel×dk,
W
i
V
∈
R
d
m
o
d
e
l
×
d
v
\boldsymbol{W}_i^V \in \mathbb{R}^{d_{model} \times d_v}
WiV∈Rdmodel×dv 和
W
O
∈
R
h
d
v
×
d
m
o
d
e
l
\boldsymbol{W}^O \in \mathbb{R}^{hd_v \times d_{model}}
WO∈Rhdv×dmodel。在论文中,指定
h
=
8
h=8
h=8(即使用 8 个注意力头)和
d
k
=
d
v
=
d
m
o
d
e
l
/
h
=
64
d_k = d_v = d_{model}/h = 64
dk=dv=dmodel/h=64。
在多头注意力下,我们为每组注意力单独维护不同的 Query、Key 和 Value 权重矩阵,从而得到不同的 Query、Key 和 Value 矩阵。如前所述,我们将
X
\boldsymbol{X}
X 乘以
W
Q
\boldsymbol{W}^Q
WQ、
W
K
\boldsymbol{W}^K
WK 和
W
V
\boldsymbol{W}^V
WV 矩阵,得到 Query、Key 和 Value 矩阵。
图 1.19
按照上面的方法,使用不同的权重矩阵进行 8 次自注意力计算,就可以得到 8 个不同的
Z
\boldsymbol{Z}
Z 矩阵。
F
F
N
(
x
)
=
max
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
FFN(x) = \max(0, xW_1 + b_1)W_2 + b_2
FFN(x)=max(0,xW1+b1)W2+b2
在每个编码器和解码器中,虽然这个全连接前馈网络结构相同,但是不共享参数。整个前馈网络的输入和输出维度都是
d
m
o
d
e
l
=
512
d_{model}=512
dmodel=512,第一个全连接层的输出和第二个全连接层的输入维度为
d
f
f
=
2048
d_{ff}=2048
dff=2048。
s
u
b
_
l
a
y
e
r
_
o
u
t
p
u
t
=
L
a
y
e
r
N
o
r
m
(
x
+
S
u
b
L
a
y
e
r
(
x
)
)
sub\_layer\_output = LayerNorm(x + SubLayer(x))
sub_layer_output=LayerNorm(x+SubLayer(x))
P
E
(
p
o
s
,
2
i
)
=
sin
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE_{(pos, 2i)} = \sin (pos / 10000^{2i/d_{model}})
PE(pos,2i)=sin(pos/100002i/dmodel)
P
E
(
p
o
s
,
2
i
+
1
)
=
cos
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE_{(pos, 2i+1)} = \cos (pos / 10000^{2i/d_{model}})
PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中,
p
o
s
pos
pos 表示位置,
i
i
i 表示维度。上面的函数使得模型可以学习到 token 之间的相对位置关系:任意位置的
P
E
(
p
o
s
+
k
)
PE_{(pos+k)}
PE(pos+k) 都可以被
P
E
(
p
o
s
)
PE_{(pos)}
PE(pos) 的线性函数表示:
cos
(
α
+
β
)
=
cos
(
α
)
cos
(
β
)
−
sin
(
α
)
sin
(
β
)
\cos(\alpha + \beta) = \cos(\alpha)\cos(\beta) - \sin(\alpha)\sin(\beta)
cos(α+β)=cos(α)cos(β)−sin(α)sin(β)
sin
(
α
+
β
)
=
sin
(
α
)
cos
(
β
)
+
cos
(
α
)
sin
(
β
)
\sin(\alpha + \beta) = \sin(\alpha)\cos(\beta) + \cos(\alpha)\sin(\beta)
sin(α+β)=sin(α)cos(β)+cos(α)sin(β)
在 Transformer 论文,提到一个细节:编码组件和解码组件中的嵌入层,以及最后的线性层共享权重矩阵。不过,在嵌入层中,会将这个共享权重矩阵乘以
d
m
o
d
e
l
\sqrt{d_{model}}
dmodel。
1.12 正则化操作
为了提高 Transformer 模型的性能,在训练过程中,使用了以下的正则化操作:
Dropout。对编码器和解码器的每个子层的输出使用 Dropout 操作,是在进行残差连接和层归一化之前。词嵌入向量和位置编码向量执行相加操作后,执行 Dropout 操作。Transformer 论文中提供的参数
P
d
r
o
p
=
0.1
P_{drop} = 0.1
Pdrop=0.1。
Label Smoothing(标签平滑)。Transformer 论文中提供的参数
ϵ
l
s
=
0.1
\epsilon_{ls} = 0.1
ϵls=0.1.