论文阅读总结——An Explainable AI-Based Intrusion Detection System for DNS Over HTTPS (DoH) Attacks
论文介绍
本文2022年发表在IEEE Transactions on Information Forensics and Security期刊,是一篇关于检测DoH攻击的可解释机器模型的论文。
背景介绍
传统DNS解析过程:
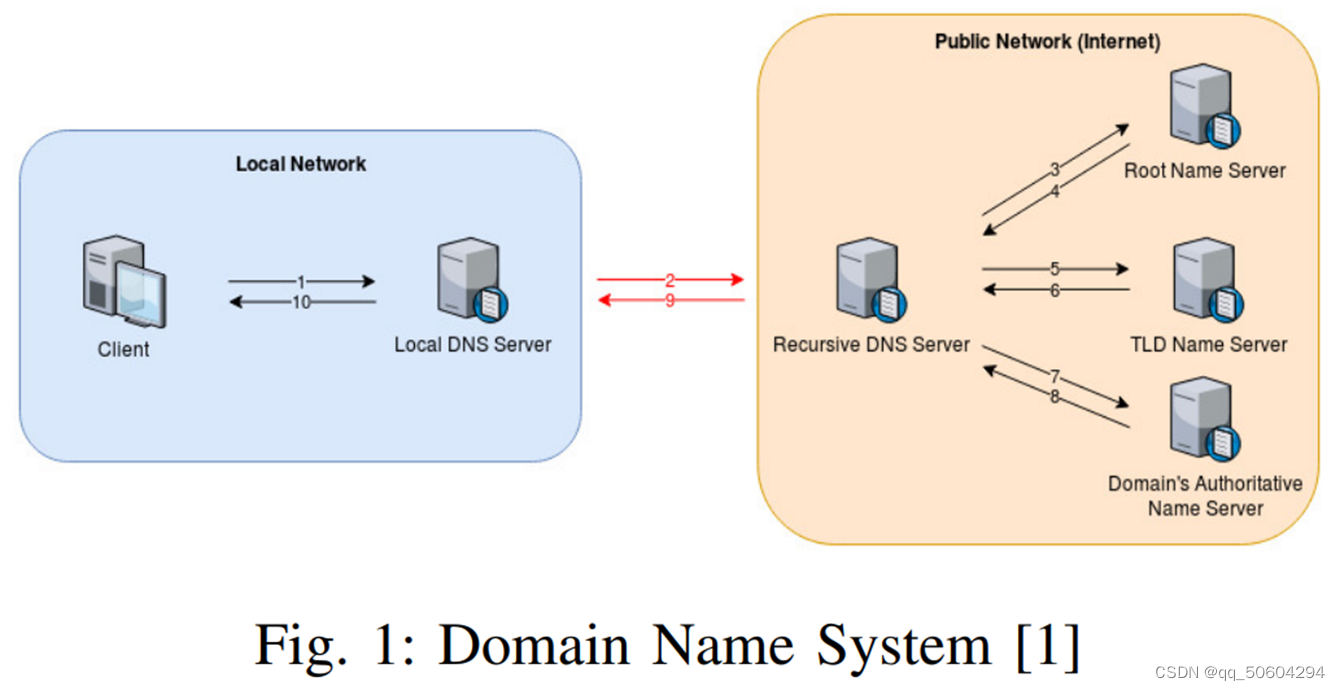
如图所示,是传统的DNS解析过程:
1、客户端提出域名解析请求,然后发送给本地的域名服务器;
2、当本地的域名服务器收到请求后,先查询本地的缓存,如果有该记录,则本地的域名服务器就直接把查询的结果返回;
3、如果没有的话由本地服务器进一步进行递归(客户端和本地服务器)和迭代解析。
DNS over HTTPS(DoH)
然而,传统的DNS解析过程是全明文传输,很容易被攻击者攻击。因此,安全化的域名解析方案DNS over HTTPS被提出。DoH是一个进行安全化的域名解析方案,使用HTTPS协议进行DNS解析请求,工作在443端口。
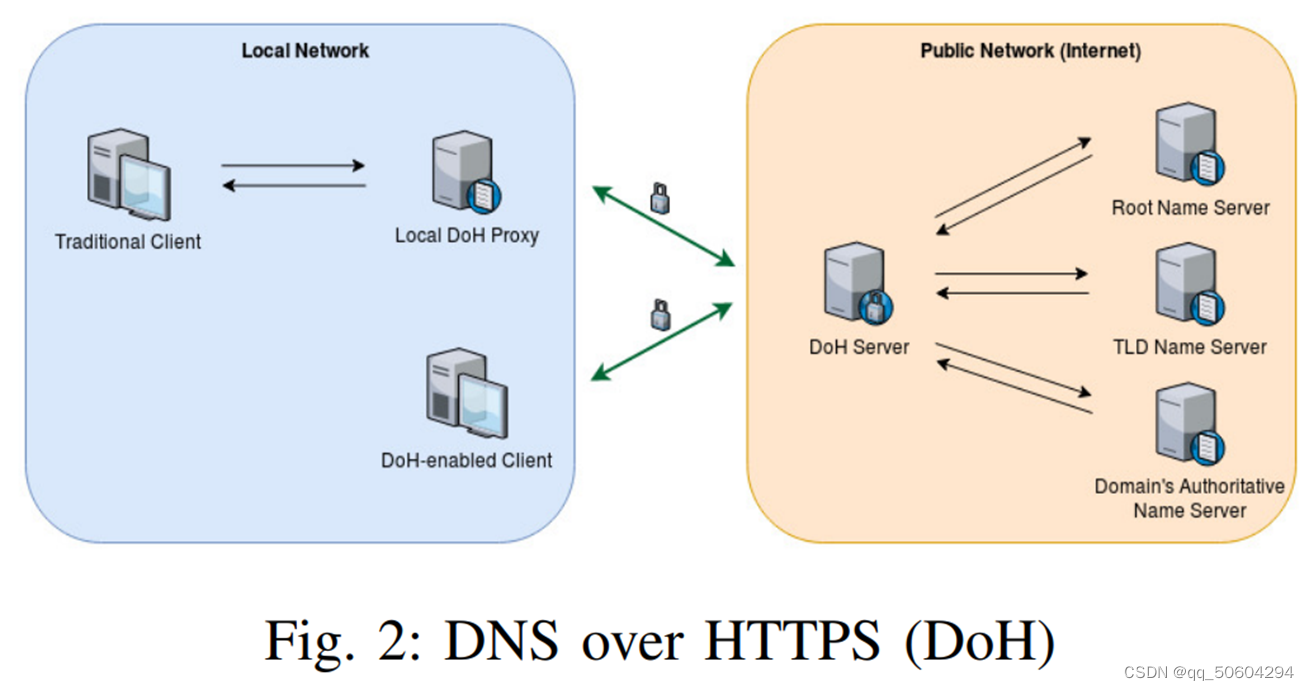
如图所示,是DoH的解析过程,可分为两种情况:
1)一种是传统客户端,解析请求必须经过本地DoH代理到达DoH服务器;
2)一种是支持DoH协议的客户端,DNS解析请求可以直接发送给DoH服务器。
然而,DoH保护合法用户的隐私与安全的同时也为攻击者提供了隐蔽的通信信道。
DNS隧道攻击
DoH隧道是指建立在受控主机和伪装成权威域名服务器的主服务器之间,可作为恶意活动的秘密数据通信通道,即下图中红色箭头部分。受控客户端发起对伪装的权威域名服务器的解析请求,当伪装的权威域名服务器收到请求后,可以将恶意数据封装在DNS解析的response数据包中返回给客户端。
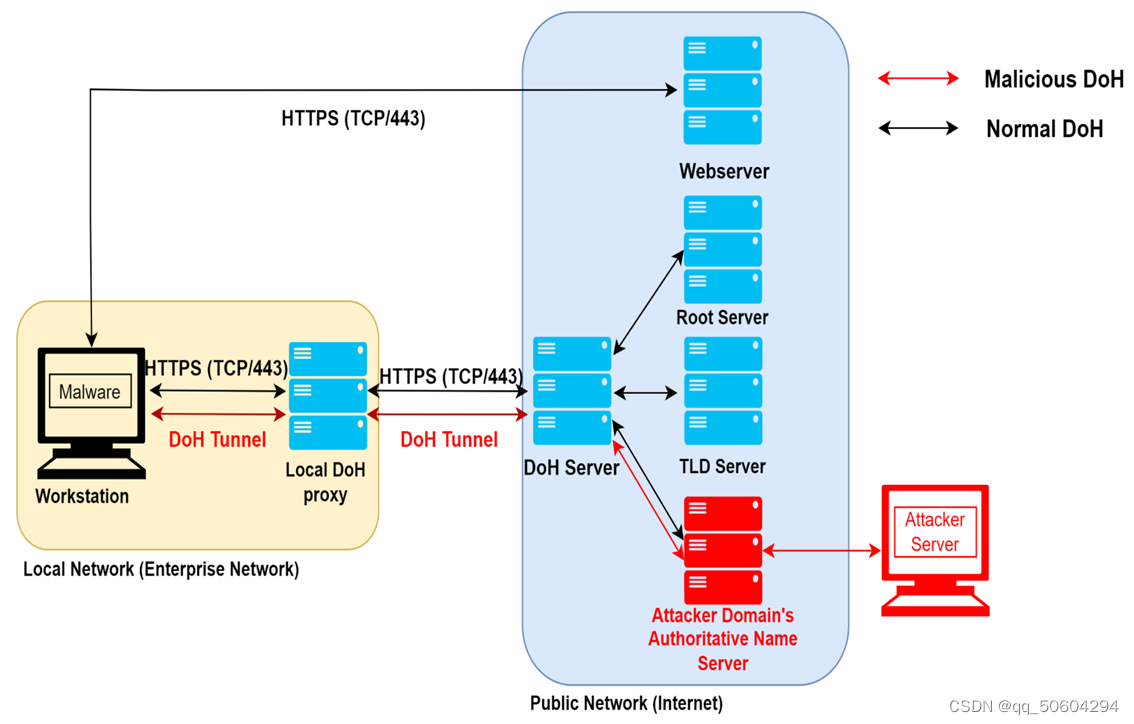
当前DNS隧道检测和DoH隧道检测相关研究的局限性
1)传统的基于数据包内容的DNS隧道检测方法在引入了DoH协议后失效;
2)一些DoH隧道攻击检测方法在使用的特征数量和准确率方面相当有限;
3)之前大多数的使用机器学习技术进行检测的方法,缺乏可解释性。
本文要解决的问题
1)准确检测和分类恶意DoH攻击
2)实现一个可解释的人工智能方案用以检测DoH攻击
系统设计
系统框架
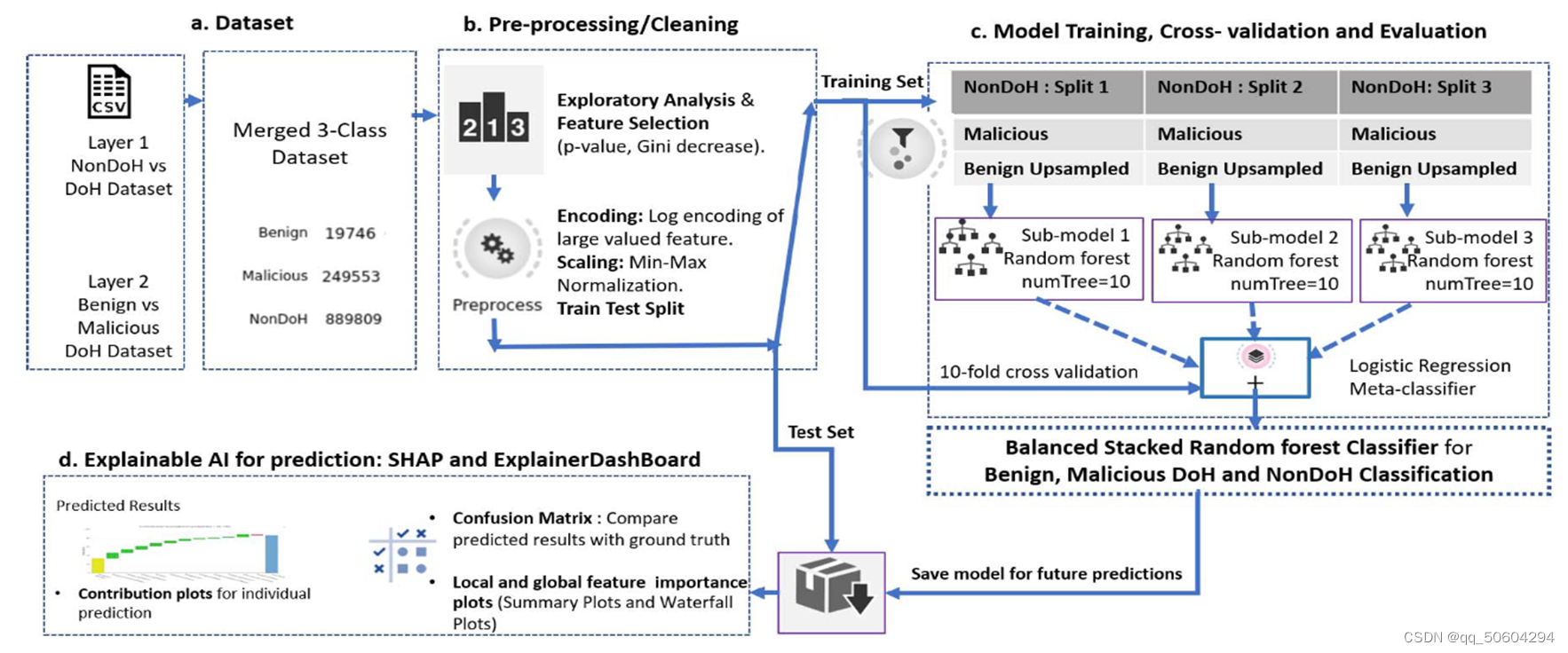
如图所示,本文提出的模型主要分为三个部分:数据预处理、模型训练与预测以及用于检测的可解释AI。
数据预处理
特征分析
作者使用了加拿大网络安全研究所发布的CIRA-CIC-DoHBrw-2020数据集,该数据集共有29个特征,包括流统计特征、包长度统计特征、包时间统计特征等。,本文中,作者使用核密度估计 (KDE) 图绘制特征的值分布,对29个特征进行了逐一分析。
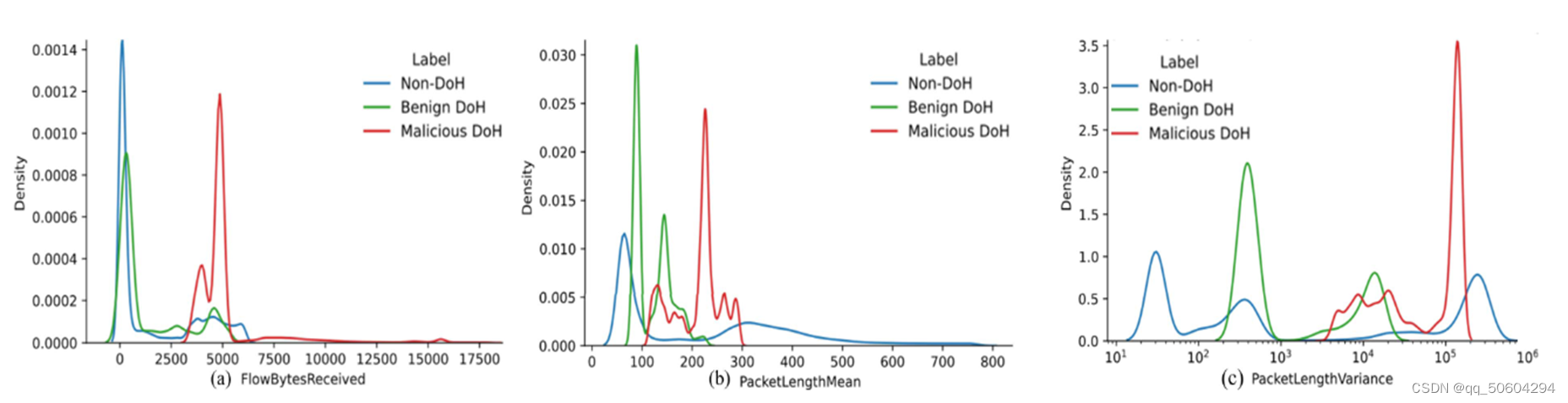
如图所示,作者对接收到的流字节数、数据包长度均值和数据包长度方差三个特征的KDE图进行了展示。从接收到的流字节数和数据包长度均值特征分布中可以看出,与非DoH和良性DoH相比,恶意DoH接收的字节数明显更高;与良性DoH流量相比,恶意DoH流量的数据包长度方差更大。
数据划分与采样
本文将数据集按照9:1的比例划分为训练集和测试集。从 90% 的训练数据中创建了三个平衡的分割来提供三个独立的子模型,使用了三种不同的非 DoH 数据划分,同时在不同的划分中共享相同的恶意样本。

从表中数据可以看出,数据集中 Non-DOH、Benign-DOH 和 Malicious-DoH 的初始比例为 45:1:12,良性DoH流量太少导致样本不平衡,因此作者对良性DoH流量进行SMOTE采样后将良性组分割为 3 个:训练集的每个子集中的比例为 15:12:12。
SMOTE过采样: SMOTE过采样是一种常用的采样方法,先以每个样本点的k个最近邻样本点为依据,然后随机的选择N个邻近点进行差值,然后对差值乘上一个[0,1]范围的阈值并与该样本相加得到新的样本点。
检测模型
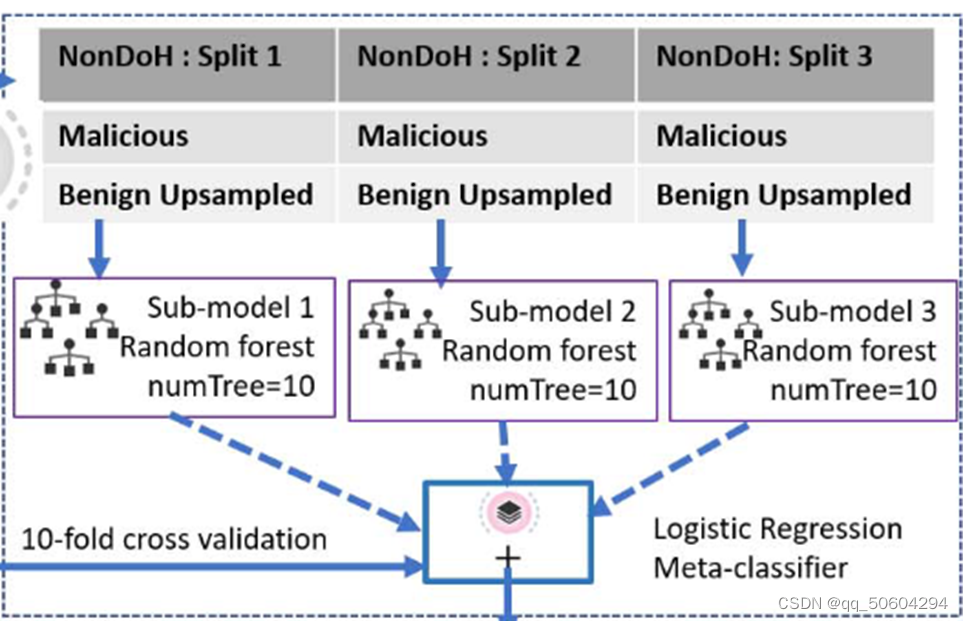
作者使用了一种集成学习模型来检测DoH隧道攻击,包括一个元分类器和三个子分类器,如下图所示。其中元分类器是逻辑回归模型,所有子模型都是 numTrees=10 的随机森林模型,并且各个决策树的最大分支深度为 5。作者使用了GridsearchCV函数来选择最佳模型最佳参数。并且本文还使用了十倍交叉验证来保证所选参数不易受到异常值的影响,降低偶然性,提高泛化能力。
XAI (可解释人工智能)
本文使用 SHAP(SHapley Additive exPlanations)库中提供的方法来研究模型的决策过程、各种特征的预期影响和潜在偏差,可视化提出的模型的决策过程。个人认为这是本文贡献最大之处,也是大家比较关心的关于机器学习的问题。

SHAP: 是一种基于博弈论的模型事后解释的方法,它的核心思想是计算特征对模型输出的边际贡献,再从全局和局部两个层面对“黑盒模型”进行解释。
优点:可以解释任何机器学习模型,可视化效果较好。
相关实验及结果分析
DoH流量检测与分类
对于所提出的平衡堆叠随机森林分类器,模型在训练集和测试集的分类性能如下,作者使用了混淆矩阵展示实验结果。
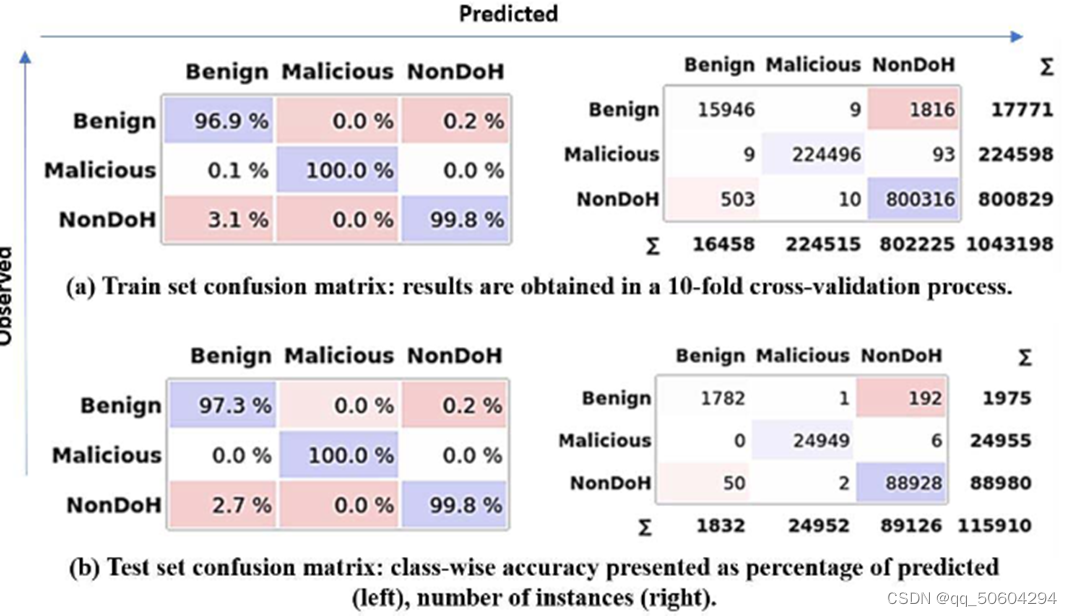
对于每种情况,类别准确率在左侧显示为预测的百分比,在右侧显示实例计数。
结论:
1)测试集上良性、恶意和非 DoH 流量的分类准确率分别为 97.3%、99.99% 和 99.8%。;
2)24955 个恶意实例中只有6个被错误分类为NonDoH;
3)主要的错误分类将良性DoH样本分类为非DoH;原因应该是良性DoH测试实例在模型的高贡献度预测特征(例如持续时间、数据包长度等)方面与非DoH相似而引起的,但是,这些错误由于其良性性质,错误对系统的损害较小。
集成学习模型对比
除了最终的平衡堆叠随机森林分类器,本文还训练了决策树、随机森林和Xgboost(梯度提升)分类器进行比较,实验结果如下表所示。

结论: 当数据集和采样方法相同时,所提出的分类器在五个指标上的结果均优于通用集成学习框架。
相关研究对比
除此之外,本文还将提出的模型与使用同一数据集的相关研究的实验结果进行了比较,结果如下:

结论:
1)研究[10]在五个指标上均取得了较好的结果,但其测试集仅有4000个样本,样本变化小,易过拟合;
2)研究[12]仅报告了准确性值,缺乏全面性;
3)与没有平衡细分训练的通用随机森林模型相比,本文模型获得了略微提高的精度和召回性能。
特征重要性分析
作者使用SHAP方法对数据集中的29个特征的重要性进行了分析,得到了所提模型的SHAP摘要图,该图提供了从训练数据中获得的全局特征重要性值。
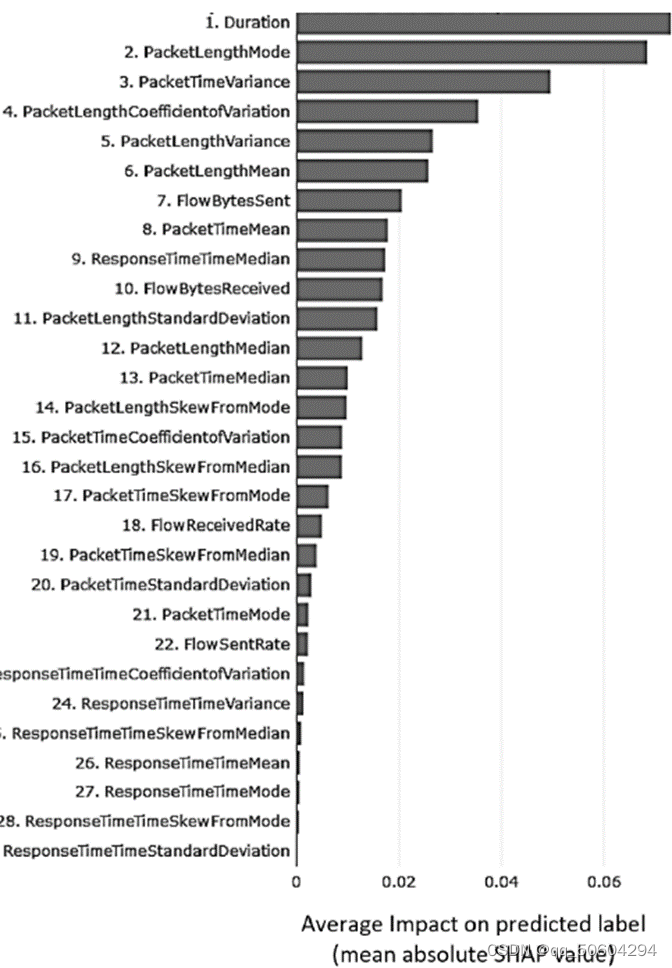
结论:
1)根据不同特征的SHAP值,可以发现DoH流量的持续时间是流量是否恶意的最重要预测因素,该特征的平均SHAP绝对值最大;
2)响应时间标准差特征的平均SHAP绝对值最小,对于预测结果的贡献最小。
SHAP依赖图和交互图结果
SHAP依赖图: 用以研究单个特征对模型处理的样本的影响
如下图,是根据测试集中所有样本的Duration特征绘制所得的SHAP依赖图,横坐标表示数据集中的实际值,纵坐标表示该值对预测的SHAP影响值,SHAP 值越高,该特征对决策的影响就越大。恶意DoH流量用正 SHAP 值表示,良性和非 DoH 流量使用负 shap 值表示进行分类。
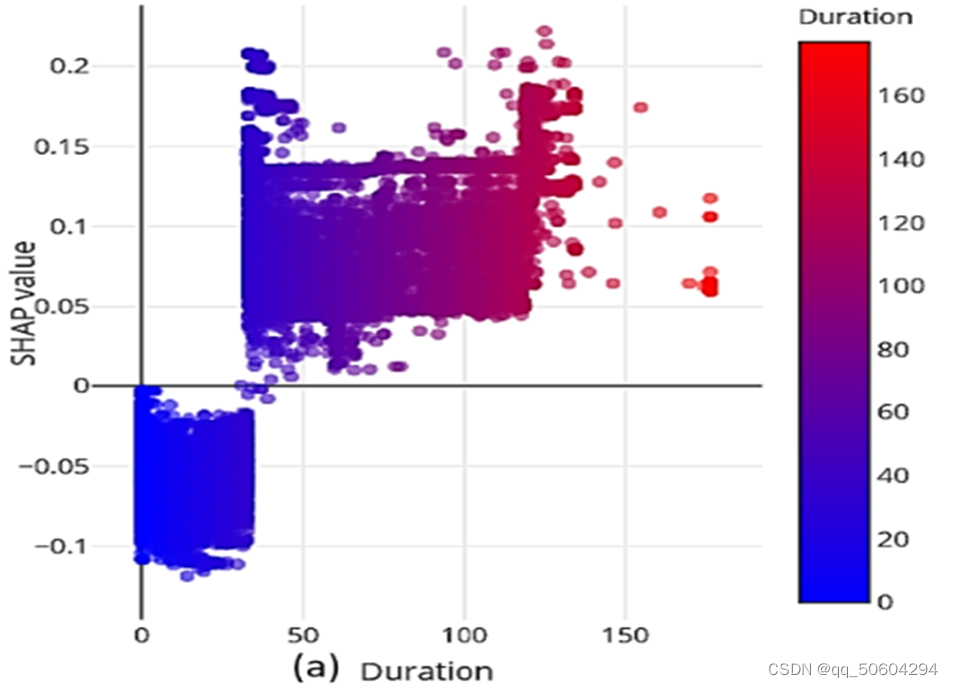
结论: 大多数被模型归类为恶意 DoH 流量的实例的持续时间都超过 40 秒。
原因分析: DoH攻击的攻击者需要与被感染主机进行通信与数据交互,因此恶意DoH流量的持续时间一般较长。
SHAP交互图: 用以研究具有交互性的特征对对模型处理的样本的影响
如图是根据测试集中所有样本的 FlowByteSent和 FlowBytesReceived特征绘制所得的SHAP交互图。
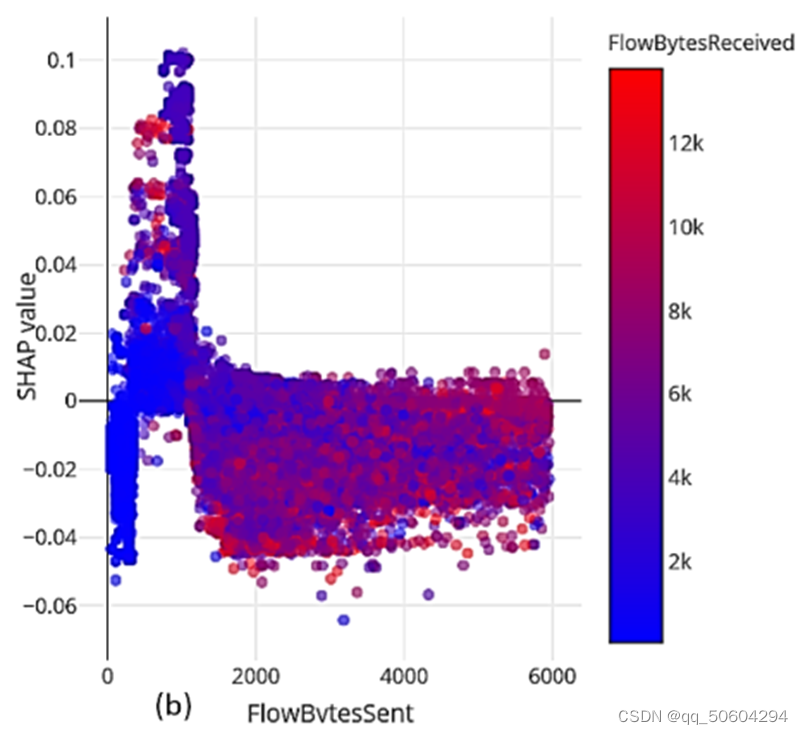
结论: 从图中的左上角部分可以观察到,当接收到的发送的字节数大于实际发送的字节数时,该实例很可能是恶意的。
原因分析: 攻击者将恶意信息隐藏在了发送数据里。
解释恶意和非DoH测试实例
除了从全局进行分析外,作者还对单个测试样本实例的决策过程进行了分析。作者将模型部署在交互式解释器仪表板上,以透明的方式测试模型功能。借助仪表板功能,可以计算每个特征对生成特定决策的置信度值的贡献程度。
恶意实例:
如图所示,该图展示了模型对恶意测试实例决策的详细解释。左上角的表格和饼图中提供了预测概率;下方的贡献图进一步详细说明了哪些特征在此特定实例的模型决策中做出了积极或消极的贡献,其中绿色方块表示积极贡献,红色方块表示消极贡献;右边的贡献表格说明了每一个特征值对预测概率的贡献百分比。

结论:
1)该恶意实例被正确预测为恶意的概率为 76.4%;
2)最高的贡献来自于持续时间,贡献比例为14.68%,第二高的贡献来自与数据包时间方差;
3)数据包长度模式则对模型置信度值产生了 5.49% 的负面影响。
非DoH测试实例:
作者还展示了对非 DOH 测试数据包的类似分析,结果如下图所示:
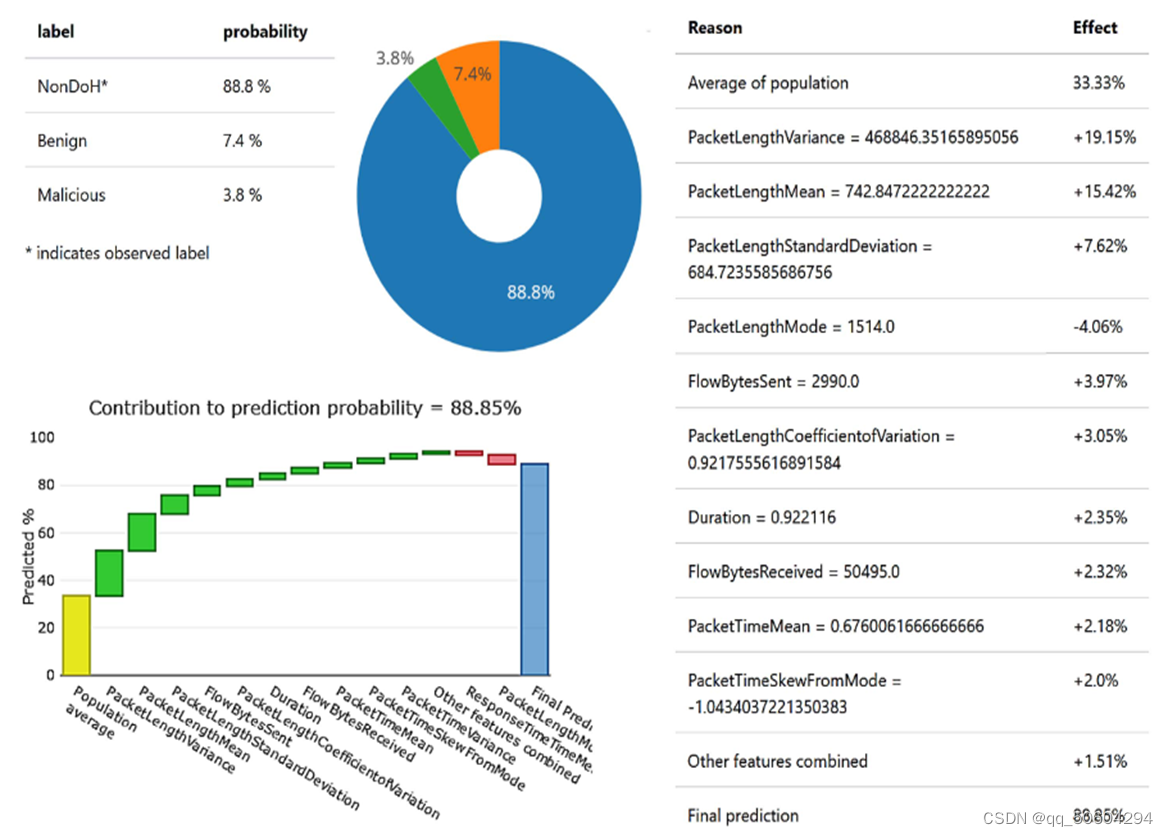
结论:
1)该非DoH实例的被正被正确预测的概率为 88.8%;
2)最高的贡献来自于数据包长度方差,贡献比例为19.15%,第二高的贡献来自于数据包长度均值;
3)数据包长度模式则对模型置信度值产生了4.06% 的负面影响。
综合两个实验结果我们可以发现,在此非DoH实例测试中,数据包模式长度为1514,对预测产生了4.06%的负面影响,而在前面的恶意实例预测中,数据包模式长度为56,对预测结果产生了 5.49% 的负面影响;之所以出现这样的结果原因是攻击者利用DoH隧道与受控主机进行数据交互和通信,因此恶意实例的数据包模式长度值应该更大。
攻击源识别可视化
最后,作者还对攻击源识别进行了可视化分析,该研究数据集中生成的恶意 DoH 流量来自各种恶意 DNS 隧道工具,包括dns2tcp、dnscat2 和 iodine。如下图所示,给出了响应时间偏移模式和数据包时间方差特征的分布以及不同恶意DNS流量来源中这两个特征的平均值和标准差。

结论:
1)iodine 和 dnscat2 的各种特征分布本质上是相似,而dns2tcp与前面两个的差异较大;
2)很好的解释了:本文模型对 dns2tcp 的恶意流量来源识别准确率达到 99.2%,对 iodine 和 dnscat2 的识别准确率分别为 92.9% 和 91.3%。
总结
1)使用核密度估计 (KDE) 图对数据集使用的特征进行了分析;
2)本文提出的平衡堆叠随机森林在DoH攻击检测中实现了高准确率与高精度,且由于三个子模型并行训练,减少了模型的训练时间;
3)结合SHAP,本文实施了可解释的人工智能方法,可视化特征对于预测的贡献,为开发 DoH 流量分类和入侵检测系统的有效方法提供见解。
展望
1)把可解释的 DoH 检测方法应用于基于深度神经网络的解决方案;
2)区分DGA相关的DoH流量与其他 HTTPS 流量。
局限
1)本文提出的数据分割和子模型开发的性能改进主要体现在由于子模型的并行性质而使训练时间减少了,但是在实验中没有体现,可以考虑增加相关实验。