记录一次elasticsearch挂掉之后无法启动 kibana Status: Red -分析过程
现象
现象一 kibana Status: Red
在使用过程中,发现kibana报错,无法正常使用。
参数表示
green 100% 可用的
yellow:所有的主分片已经分片,但是有缺失
red:至少一个主分片(以及它的全部副本)都在缺失中
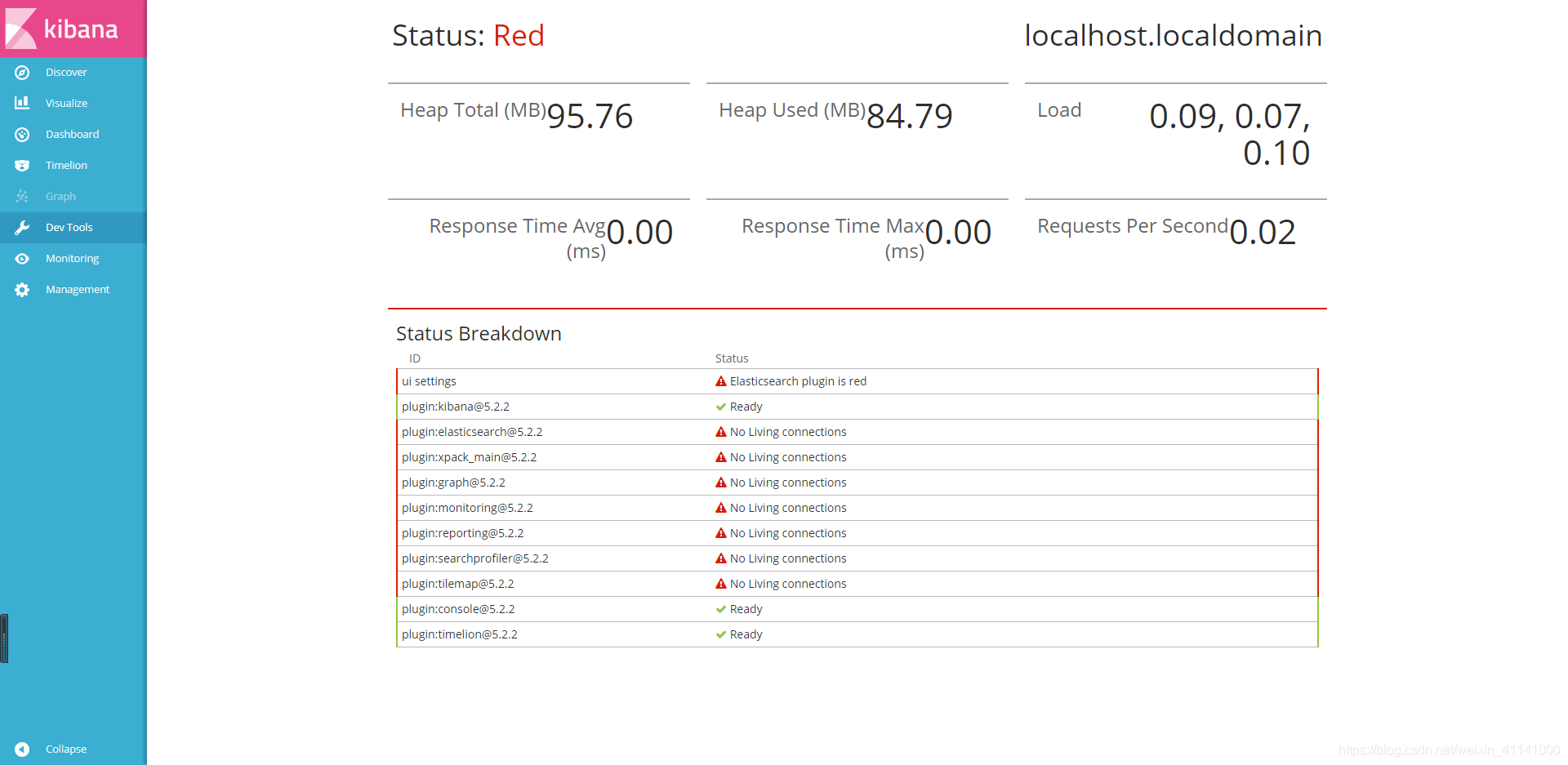
上述线程表名elasticsearch集群已经出现问题,然后检查es健康状况
现象二 elasticsearch 集群挂掉
查看索引信息 http://172.XX.XX.XX:9200/_cluster/health?pretty=true
"active_shards_percent_as_number" : 100.0 #数据的正常率,100表示一切ok
查看所有所有的状态 http://172.XX.XX.XX:9200/_cat/indices?v
访问如上连接,集群无法响应。
于是进入elasticsearch的机器检查。
现象三 elasticsearch 重启
检查es三个节点
ps -ef | grep elasticsearch
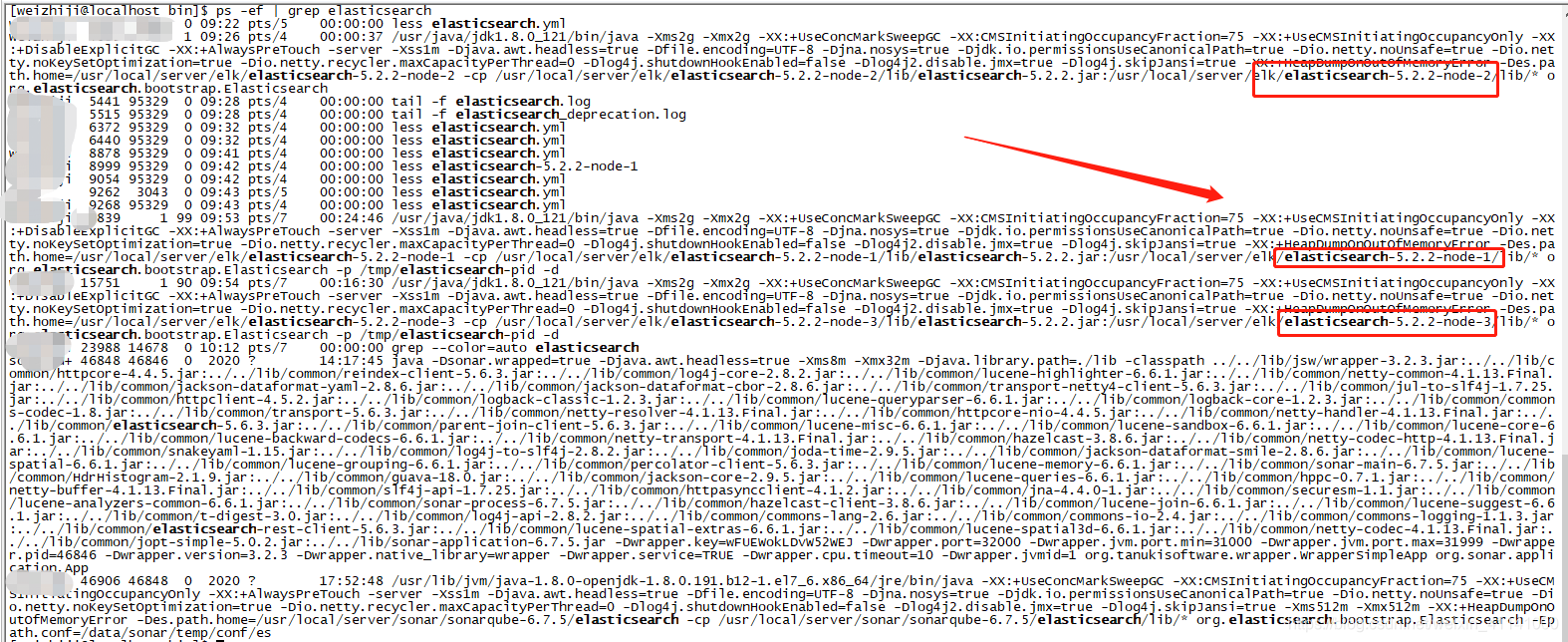
节点正常运行,但是访问节点1,http://172.XX.XX.XX:9200/_cluster/health?pretty=true 无响应。
重启节点1 -无目录可执行权限
kill -9 节点1进程号
cd 节点1目录(/xxx/elasticsearch-5.2.2-node-2/bin)
# 不可用root权限启动
./elasticsearch
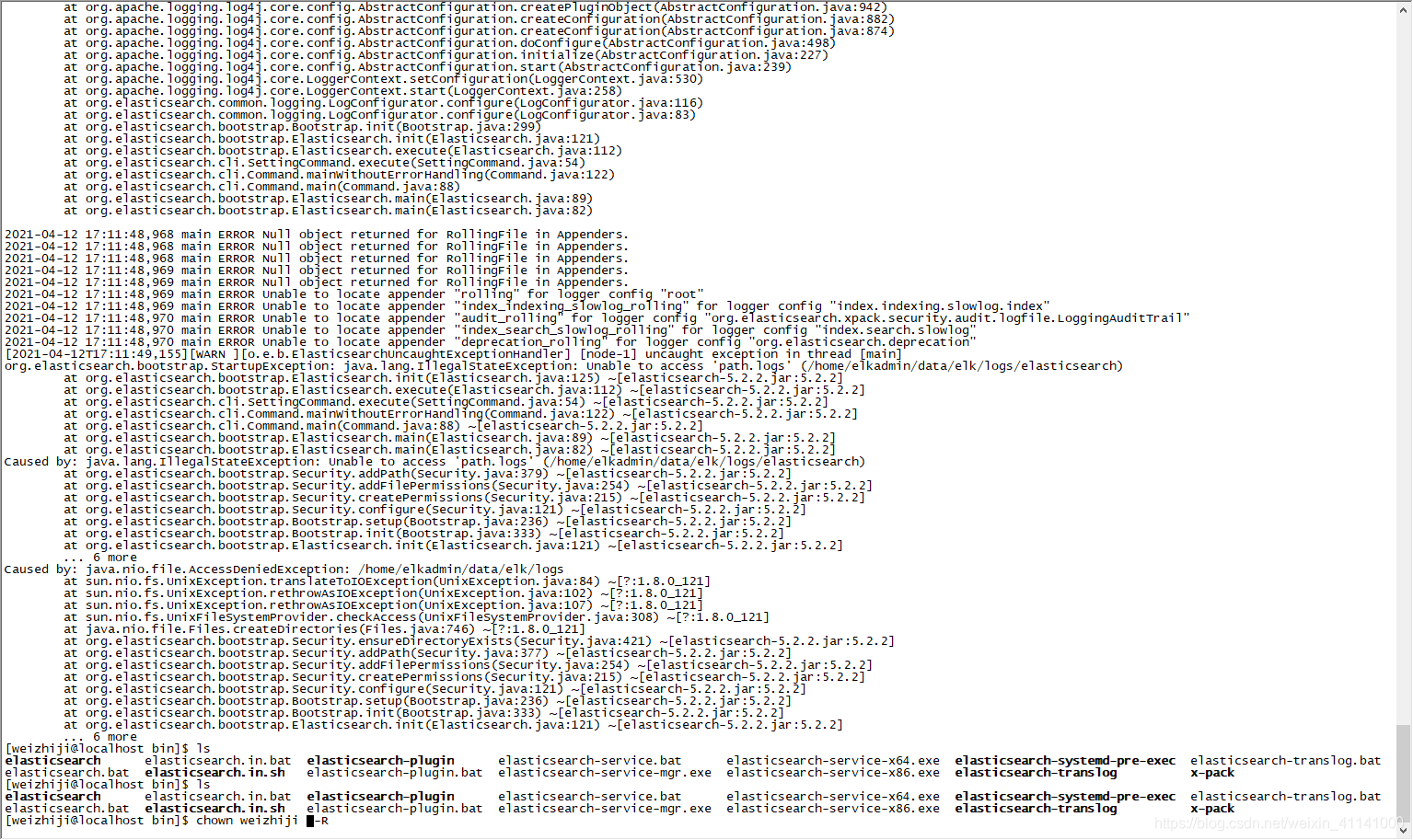
报错: Caused by: java.nio.file.AccessDeniedException: /home/elkadmin/data/elk/logs
原因:无可执行权限导致
解决:chown 用户名 /home/elkadmin/ -R
如果出现如下报错: max file descriptors [1024] for elasticsearch process is too low, increase to at least [65536]
解决办法:
将当前用户的软硬限制调大。
找到文件 /etc/security/limits.conf,编辑,在文件的最后追加如下配置:
es soft nofile 65535
es hard nofile 65537
再次重启节点1 -分片恢复加载失败
./elasticsearch 再次启动后报错
报错 failed to list shard for shard_started on node [2eHWffdTTr2FEgkQlyxrGQ]
报错 SearchPhaseExecutionException: all shards failed
原因: 分片受损后启动节点加载失败导致。
查询所有分片保存目录,无此分片2eHWffdTTr2FEgkQlyxrGQ。
并且客户端连接也无法找到分片。过程中其中
节点1重启无法加载分片
节点2重启报 skipping exporter [default_local] as it is not ready yet
经过分析:可能是其它节点没有关闭,重启主节点(节点1),导致无法加载分片启动。
最终操作 将三个节点重新杀掉,顺序重启
杀掉三个es节点
kill -9 xxx
节点1、节点2、节点3顺序重启
cd /es的bin目录下
后台启动三个节点
./elasticsearch -p /tmp/elasticsearch-pid -d
访问kibana恢复正常:http://xx.xx.xx.xx:5601/app/kibana#/discover?_g=()&_a=(columns:!(_source),index:kkmediadb,interval:auto,query:’’,sort:!(_score,desc))
复盘
原因
当时出现es节点挂掉,是因为开发人员在调试大批量删除es数据,删除语句问题导致。导致es进行大批量数据删除,导致节点卡死。