前言
TDengine 是一款由中国团队开发的开源、云原生的时序数据库(Time Series Database),专为物联网、工业互联网、金融、IT 运维监控等场景设计并优化。它能让大量设备、数据采集器每天产生的高达 TB 甚至 PB 级的数据得到高效实时的处理,对业务的运行状态进行实时的监测、预警,从大数据中挖掘出商业价值。
它具备处理物联网数据所需要的所有功能,包括:
- 类SQL查询语言来插入或查询数据
- 支持C/C++, Java(JDBC), Python, Go, RESTful, and Node.JS 等开发接口
- 通过TDengine Shell或Python/R/Matlab可做各种Ad Hoc查询分析
- 通过连续查询,支持基于滑动窗口的流式计算
- 引入超级表,让设备之间的数据聚合通过标签变得简单、灵活
- 内嵌消息队列,应用可订阅最新的数据
- 内嵌缓存机制,每台设备的最新状态或记录都可快速获得
- 无历史数据与实时数据之分
taos shell命令批量下载数据库遇到中断问题
在使用taos shell命令直接下载某个超级表到指定csv文件中,发现当表中数据超过几百万时,就会出现请求中断:
Query interrupted (Query terminated),4798749 row(s) in set (357.461000s)
具体taos shell 命令如下:
SELECT * FROM <database_name> >> <***.csv>;

分析问题:
这种问题很有可能是taos数据库在读取较大表格时候,由于数据量大,电脑缓存不够,或者是内部配置文件做了限制导致的。
解决方案
查看tao.cfg文件
尽量不要去设置这些max什么的限制

使用分页下载,在合并csv
1. 构建.sql文件批量进行下载
基本步骤:
- 获取到taos超级表名
- 根据超级表名及分页限制数,打印SQL语句
这里注意分页Taos命令语句如下:
SELECT * FROM <table_name> LIMIT 1000000 offset 1000000 >> data_<number>.csv
详细代码如下:
import taos
def get_number(numbers,limit_numbers):
number_list = []
mid_number = numbers//limit_numbers
mod_number = numbers%limit_numbers
for i in range(mid_number+1):
# print(i)
if mod_number and i!=mid_number:
number_list.append([limit_numbers,i*limit_numbers])
elif mod_number and i==mid_number:
number_list.append([mod_number,i*limit_numbers])
elif i!=mid_number:
number_list.append([limit_numbers,i*limit_numbers])
else:
pass
# print(number_list)
return number_list
class UtilsTao:
def __init__(self,db_name,port, hostname, username,password):
self.db_name = db_name
self.port = port
self.hostname = hostname
self.username = username
self.password = password
self.conn, self.cursor = self.connect_taos_db() # Connect to database and cursor.
def connect_taos_db(self):
# 连接Taos数据库
conn = taos.connect(host=self.hostname, port=self.port, user=self.username, password=self.password, database=self.db_name)
cursor = conn.cursor()
cursor.execute("use {}".format(self.db_name))
return conn, cursor
def printsql(self,super_tables):
for table in super_tables:
# 查看指定表中的行数
self.cursor.execute("SELECT COUNT(*) FROM {}".format(table))
# 如果行数超过100万行则进行分页获取表中数据,并打印出sql语句。
results = self.cursor.fetchall() # Get all rows from table.
length = int(results[0][0])
if length >= 1000000:
number_list = get_number(numbers=length, limit_numbers=1000000)
# 执行分页查询,获取表中数据的行数列表。将其打印出来
for i in number_list:
if i[1] == 0 :
sql = "SELECT * FROM {} LIMIT 1000000 >> {}_{}_data_{}.csv;".format(table,self.db_name,table,i[1])
print(sql)
# self.cursor.execute(sql)
else:
sql = "SELECT * FROM {} LIMIT 1000000 offset {} >> {}_{}_data_{}.csv;".format(table,i[1],self.db_name,table,i[1])
print(sql)
# self.cursor.execute(sql)
else:
sql_content = "SELECT * FROM {} >> {}_{}_data.csv;".format(table,self.db_name,table)
# self.cursor.execute(sql_content)
print(sql_content)
# results_csv = self.cursor.fetchall()
def close_taos_db(self):
# 关闭Taos数据库
# 关闭数据库连接
self.cursor.close()
self.conn.close()
def get_super_tables_name(self):
# get all super tablesname from database;
sql = "SHOW stables"# Show all tables name in database.
self.cursor.execute(sql) # Execute the SQL statement.
# 获取超级表名称列表
results = self.cursor.fetchall()
super_tables = [row[0] for row in results]
# 输出超级表名称列表
print(super_tables)
return super_tables
if __name__ == '__main__':
db_name,hostname,port, username,password = 'xxx', 'xxxx',8888, 'xxxx', 'xxxxx'
tao_ = UtilsTao(db_name,port,hostname,username,password)
super_tables = tao_.get_super_tables_name()
tao_.printsql(super_tables)
tao_.close_taos_db()
输出如下:
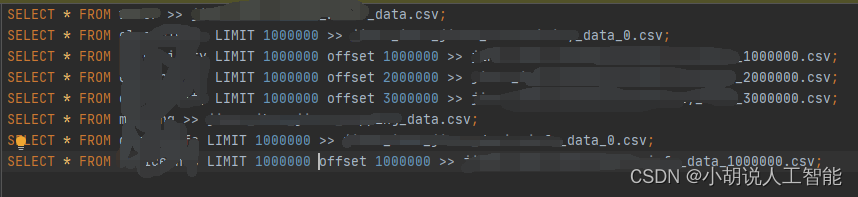
- 复制SQL语句,生成.sql文件
- 在taos Shell命令窗口运行批量下载命令
source sql_batch.sql
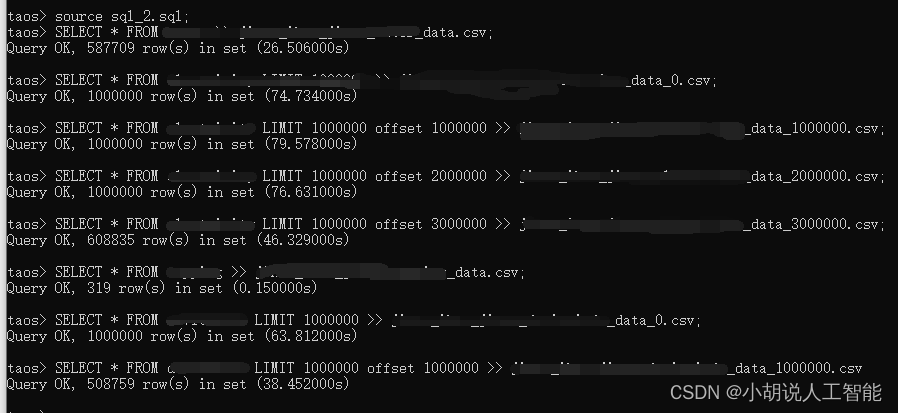
可以看到Query 均顺利为OK了,意思就下载下来了,这里可以看到有些数据量因为小于100万,则直接下载成一个csv文件了。
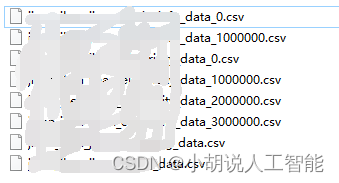
2. 合并分csv文件成总csv文件
接下来对分页的csv文件进行合并成总csv文件。具体代码如下:
import pandas as pd
import os
class ConcatCsv:
def __init__(self, dir, db_name):
self.dir = dir
self.dbname = db_name # 数据库名称
def get_table_list(self):
file_name = os.listdir(self.dir) # 获取文件夹中的文件名称列表。
table_dict = {}
for file_ in file_name:
table_name = file_.split(self.dbname)[1].split("_")[1]
if table_name in table_dict.keys(): # 检查列表中是否有该表名称。如果有,则加入到对应的列表中。
number = table_dict[table_name] + 1
table_dict.update({table_name: number})
else:
table_dict.update({table_name: 1})
return file_name, table_dict
def concat_csv(self):
file_name, table_dict = self.get_table_list()
for table_name, number in table_dict.items():
if number == 1:
pass
else:
list_table = [file for file in file_name if table_name in file]
# 给list_table排序,注意一定要排序,对于时序数据才能按照顺序合并csv文件
list_table.sort(key=lambda x: str(x.split("_")[-1]))
print(list_table)
for i, table_ in enumerate(list_table):
if i == 0:
c = pd.read_csv(self.dir + os.sep + table_)
else:
c = pd.concat([c, pd.read_csv(self.dir + os.sep + table_)],axis=0, ignore_index=False)
c.to_csv(self.dir + os.sep + self.dbname + "_" + table_name + ".csv", index= False)
for table_ in list_table: # 删除旧的文件列表。
os.remove(self.dir + os.sep + table_)
print("concat_csv task is done!" )
if __name__ == '__main__':
dir_path = r'E:\Data\数据库'
table_dict = ConcatCsv(dir_path, 'xxxx').concat_csv()
注意:合并成总csv文件后,会删除掉分csv文件,最后只保留总csv文件
总结
整体上taos数据库中表的下载速度还是很快,平均100万的数据,最多200-300秒左右,使用本文方法,可以通过taos的命令窗口命令,批量下载,最终生成想要的总csv文件。
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。