看过掌柜前几篇关于时序文章:
- 利用ARIMA模型对时间序列进行分析的经典案例(详细代码)
- “利用ARIMA模型对时间序列进行分析的经典案例(详细代码)”一文中会遇到的问题总结
- ARIMA模型预测后出现一条直线的原因
的朋友都知道在最后一篇掌柜遗留了一个问题,就是已确定当前的时序数据具有季节周期性,那么如何解决这类时序数据并进行预测分析呢?本文掌柜将从以下几个方面一一作答:
-
SARIMA模型是什么?
-
如何使用SARIMA模型进行时序分析的?(SARIMA模型的步骤有哪些?)
-
SARIMA模型的优点以及限制性有哪些?
首先我们来看第一个问题,SARIMA模型是什么?
简单来讲,就是ARIMA的扩展,它明确支持带有季节成分的 单变量时间序列。
而多出来的几个参数就是下图大写的PDQ那部分:
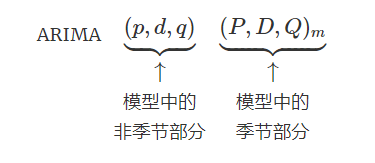
其中m 表示时序的周期性,比如 以月为周期monthly,以年为周期yearly等。
下面接着看第二个问题:如何使用SARIMA模型进行时序分析的?(SARIMA模型的步骤有哪些?)
这里有这样一组示例数据:

上图👆表示的是 从1958年3月到2001年12月,美国夏威夷州空气中二氧化碳含量的时序图。
可以很明显的从时序图看出来,这是一个季节周期性的时序,所以下面我们用SARIMA模型进行一个处理和预测。
( PS: 如果你的数据不是一开始就能明显看出季节周期性的,就请用掌柜上一篇博客👉:《ARIMA模型预测后出现一条直线的原因 》中提到的几种方法 来进行季节周期性的确定!!! )
- SARIMA模型的参数选取
1.1 网格搜索(Grid Search) 法
首先对p、d、q 以及 P、D、Q进行不同参数组合的探索。话不多说,直接上代码:
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
然后我们就可以看到每个SARIMA模型对应的参数组合:

(这里的m 我们是以年为周期,即12个月,所以 m = 12。
当然如果你还是对如何确定 m的值有疑问?可以画出ACF和PACF图来确定 m的值。下图就是掌柜画出的ACF和PACF图:

由上图👆可知,ACF和PACF图的12阶以内,自相关系数和偏自相关系数都是拖尾,所以对于非季节性部分可采用ARMA(1,1)模型;
然后再以12阶为一个周期来看,可以发现ACF图在 12阶时,自相关系数不为零;但是24阶的时候就落在2倍标准差范围内!同理可知,PACF图在12阶和24阶,甚至36阶的偏自相关系数都不为零!! 所以这是一个 ACF截尾,PACF拖尾的季节性MA模型。季节性这部分的周期性参数 m = 12,模型为MA(1)。
PPS: 但是这种看图的方法带了很多主观因素在里面,所以还是建议大家采用更科学的网格搜索(Grid Search)👇法进行最优参数的查找!!! )
下面对SARIMA模型进行参数的网格搜索,找到最优SARIMA模型。
那么问题来了,如何判断模型最优???
答:通常都是找寻最小的AIC(Akaike Information Criterion 即 赤池信息准则)值。 不熟悉赤池信息准则的朋友可以看维基百科的解释👉:赤池信息量准则。下图就是掌柜搜索后的结果:

可以发现 SARIMASX (1, 1, 1)x(1, 1, 1, 12) 就是我们要找的最优模型。
- 建立SARIMA模型
接着用原始数据进行SARIMA模型的拟合:
mod = sm.tsa.statespace.SARIMAX(y,
order=(1, 1, 1),
seasonal_order=(1, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit()
print(results.summary().tables[1])
然后我们会得到这样一组表格数据,主要看coef 列 和 P>|z| 列:

coef 列显示每个特征的权重(即重要性)以及每个特征如何影响时间序列。而P>|z|列是对每个特征重要性的检验。上图每个权重的 p 值都低于或接近 0.05,因此在我们的模型中保留所有权重是合理的。
- SARIMA模型的验证
SARIMA模型建立好后我们还需要进行模型的验证,以确保模型所做的假设都是合理的。这里主要采用plot_diagnostics 方法,它可以快速生成模型诊断结果并检查出有无任何异常行为。

这里主要看模型的残差是不相关的且符合正态分布;如果没有满足这些特性,说明模型还需要改善!
上面👆这四个图,先看右上角的直方图:
在右上图中,我们看到红色的KDE线紧跟N(0,1)线(其中N(0,1))是均值0和标准偏差为1的正态分布的标准表示法。这很好地表明了残差是正态分布的。
左下方的qq图显示,残差(蓝色点)的有序分布遵循从具有N(0,1)的标准正态分布获取的样本的线性趋势。同样,这也表明残差是正态分布的。
左上图表示随时间推移,残差没有明显的季节性变化,似乎是白噪声。
右下角的自相关(即ACF图)图更确认了这一点,该图表明时间序列残差与自身的滞后值具有较低的相关性。
当然,如果想更确定的检验 残差是否是白噪声序列,可以采用Ljung-Box检验:检验的结果就是看最后一列前十二行的检验概率。掌柜也采用LB检验后得到如下数据:

计算可知前12阶的P值几乎都是大于0.05,所以在0.05的显著性水平下,不拒绝原假设,即残差为白噪声序列,这说明拟合的模型已经充分提取了时间序列中的信息。
- SARIMA模型的预测
4.1 验证预测模型
这里主要采用 get_prediction() 和 conf_int() 方法来获取时间序列预测的值和相关的置信区间。选取1998年1月开始的数据,并设置dynamic = False 进行验证预测:
pred = results.get_prediction(start=pd.to_datetime('1998-01-01'), dynamic=False)
pred_ci = pred.conf_int()
ax = y['1990':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead Forecast', alpha=.7)
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('CO2 Levels')
plt.legend()
plt.show()

从上图可以看出,模型预测值与真实值几乎重叠,说明模型效果很好。接着再使用MSE(均方误差)和RMSE(均方根误差)来查看模型的准确度。
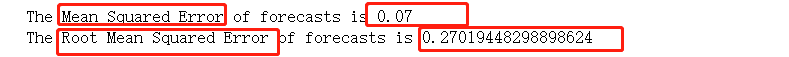
可以看到这个MSE和RMSE是非常的小,说明dynamic = False 情况下,模型的预测效果过于完美(太过理想化),这不太符合实际情况,所以打算采用动态预测再次进行验证。
即dynamic = True又是怎样的一种情况???
pred2 = results.get_prediction(start=pd.to_datetime('1998-01-01'), dynamic = True, full_results=True)
pred_ci2 = pred2.conf_int()
ax = y['1990':].plot(label='Original')
pred2.predicted_mean.plot(ax=ax, label='Dynamic Forecast', alpha=.7)
ax.fill_between(pred_ci2.index,
pred_ci2.iloc[:, 0],
pred_ci2.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('CO2')
plt.legend()
plt.show()
得到如下图形:

同理可以得到MSE和RMSE值:
y_forecasted2 = pred2.predicted_mean
y_truth2 = y['1998-01-01':]
mse = ((y_forecasted2 - y_truth2) ** 2).mean()
print('The Mean Squared Error of forecasts is {}'.format(round(mse, 2)))
print('The Root Mean Squared Error of forecasts is {}'.format(np.sqrt(sum((y_forecasted2-y_truth2)**2)/len(y_forecasted2))))

动态预测的MSE和RMSE值都略大于静态预测值,这是因为动态预测依赖于时间序列中较少的历史数据进行预测,而静态预测的每个点都是使用的该点完整历史数据进行预测的。不过这里动态预测出来的MSE和RMSE也不是很大,说明模型确实效果很好。
综上,SARIMA (1,1,1)x(1,1,1)12 模型效果还不错,下面进行最后一步!
4.2.模型预测
这里我们预测未来10年的数据并得到如下图:
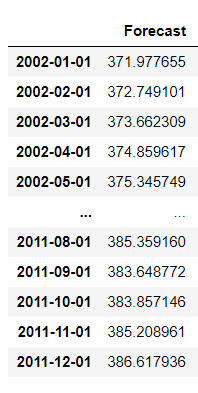

可知随着时间的推移,二氧化碳的含量还是会在一个稳定的区间里逐步增加!
好了,最后一个问题:SARIMA模型的优点和缺点? 以及本篇中还有待优化的地方。
(请静候下一篇🤝)完整的代码掌柜已经上传Github👉Time Series Learning,请自取谢谢。
参考资料:
A Guide to Time Series Forecasting with ARIMA in Python 3
How to forecast sales with Python using SARIMA model
季节性ARIMA模型
A Gentle Introduction to SARIMA for Time Series Forecasting in Python
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)