MXNet 中文文档
- MXNet 中文文档
- MXNet设计和实现简介
- 编程接口
- Symbol 声明式的符号表达式
- NDArray命令式的张量计算
- KVStore 多设备间的数据交互
- 读入数据模块
- 训练模块
- 系统实现
- MXNet Python库操作简介
- NDArray在CPU和GPU上Numpy类型的张量计算
- Symbolic and Automatic Differentiation
- Symbols的基本组成
- 更多复杂的组成
- 参数shape接口
- 绑定symbol和运行
- 分布式Key-Value存储
- Initialization
- Push Aggregation 和 Updater
- Pull
- 处理一个键值对的链表
- 多机器
- 分布式训练
- 如何在MXNet上写一个分布式程序
- 在一个集群上载入任务
- 机器使用多网卡情况
- 深度学习编程模型
MXNet设计和实现简介
对于一个优秀的深度学习系统,或者更广来说优秀的科学计算系统,最重要的是编程接口的设计。他们都采用将一个领域特定语言(domain specific language)嵌入到一个主语言中。例如numpy将矩阵运算嵌入到python中。这类嵌入一般分为两种,其中一种嵌入的较浅,其中每个语句都按原来的意思执行,且通常采用命令式编程(imperative programming),其中numpy和Torch就是属于这种。而另一种则用一种深的嵌入方式,提供一整套针对具体应用的迷你语言。这一种通常使用声明式语言(declarative programing),既用户只需要声明要做什么,而具体执行则由系统完成。这类系统包括Caffe,theano和刚公布的TensorFlow。
| 浅嵌入,命令式编程 | 深嵌入,声明式编程 |
|---|
| 如何执行 a=b+1 | 需要b已经被赋值。立即执行加法,将结果保存在a中。 | 返回对应的计算图(computation graph),我们可以之后对b进行赋值,然后再执行加法运算 |
| 优点 | 语义上容易理解,灵活,可以精确控制行为。通常可以无缝地和主语言交互,方便地利用主语言的各类算法,工具包,debug和性能调试器。 | 在真正开始计算的时候已经拿到了整个计算图,所以我们可以做一系列优化来提升性能。实现辅助函数也容易,例如对任何计算图都提供forward和backward函数,对计算图进行可视化,将图保存到硬盘和从硬盘读取。 |
| 缺点 | 实现统一的辅助函数和提供整体优化都很困难。 | 很多主语言的特性都用不上。某些在主语言中实现简单,但在这里却经常麻烦,例如if-else语句 。debug也不容易,例如监视一个复杂的计算图中的某个节点的中间结果并不简单。 |
目前现有的系统大部分都采用上两种编程模式的一种。与它们不同的是,MXNet尝试将两种模式无缝的结合起来。在命令式编程上MXNet提供张量运算,而声明式编程中MXNet支持符号表达式。用户可以自由的混合它们来快速实现自己的想法。例如可以用声明式编程来描述神经网络,并利用系统提供的自动求导来训练模型。另一方便,模型的迭代训练和更新模型法则中可能涉及大量的控制逻辑,因此我们可以用命令式编程来实现。同时用它来进行方便地调式和与主语言交互数据。
下表比较MXNet和其他流行的深度学习系统
| 主语言 | 从语言 | 硬件 | 分布式 | 命令式 | 声明式 |
|---|
| Caffe | C++ | Python/Matlab | CPU/GPU | x | x | v |
| Torch | Lua | - | CPU/GPU/FPGA | x | v | x |
| Theano | Python | - | CPU/GPU | x | v | x |
| TensorFlow | C++ | Python | CPU/GPU/Mobile | v | x | v |
| MXNet | C++ | Python/R/Julia/Go | CPU/GPU/Mobile | v | v | v |
MXNet的系统框架如下:
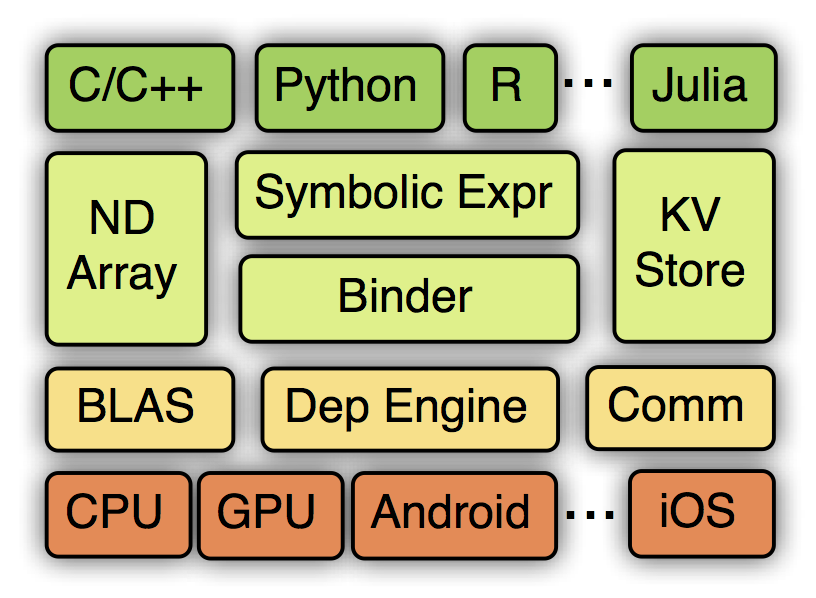
从上到下分别为各种主语言的嵌入,编程接口(矩阵运算,符号表达式,分布式通讯),两种编程模式的统一系统实现,以及各硬件的支持。
编程接口
Symbol: 声明式的符号表达式
MXNet使用多值输出的符号表达式来声明计算图。符号是由操作子(也就是TensorFlow 中的ops概念)构建而来。一个操作子可以是一个简单的矩阵运算“+”,也可以是一个复杂的神经网络里面的层,例如卷积层。一个操作子可以有多个输入变量和多个输出变量,还可以有内部状态变量。一个变量既可以是自由的,我们可以之后对其赋值;也可以是某个操作子的输出。
NDArray:命令式的张量计算
MXNet提供命令式的张量计算来桥接主语言的和符号表达式。下面代码中,我们在GPU上计算矩阵和常量的乘法,并使用numpy来打印结果
>>> import MXNet as mx
>>> a = mx.nd.ones((2, 3), mx.gpu())
>>> print (a * 2).asnumpy()
[[ 2. 2. 2.]
[ 2. 2. 2.]]
另一方面,NDArray可以无缝和符号表达式进行对接。假设我们使用Symbol定义了一个神经网络,那么我们可以如下实现一个梯度下降算法
for (int i = 0; i < n; ++i) {
net.forward();
net.backward();
net.weight -= eta * net.grad
}
这里梯度由Symbol计算而得。Symbol的输出结果均表示成NDArray,我们可以通过NDArray提供的张量计算来更新权重。此外,还利用了主语言的for循环来进行迭代,学习率eta也是在主语言中进行修改。
KVStore: 多设备间的数据交互
MXNet提供一个分布式的key-value存储来进行数据交换。它主要有两个函数,
push: 将key-value对从一个设备push进存储
pull:将某个key上的值从存储中pull出来此外,KVStore还接受自定义的更新函数来控制收到的值如何写入到存储中。最后KVStore提供数种包含最终一致性模型和顺序一致性模型在内的数据一致性模型。
分布式梯度下降算法:
KVStore kvstore("dist_async")
kvstore.set_updater([](NDArray weight, NDArray gradient) {
weight -= eta * gradient
})
for (int i = 0
kvstore.pull(network.weight)
network.forward()
network.backward()
kvstore.push(network.gradient)
}
在这里先使用最终一致性模型创建一个kvstore,然后将更新函数注册进去。在每轮迭代前,每个计算节点先将最新的权重pull回来,之后将计算的得到的梯度push出去。kvstore将会利用更新函数来使用收到的梯度更新其所存储的权重。
这里push和pull跟NDArray一样使用了延后计算的技术。它们只是将对应的操作提交给后台引擎,而引擎则调度实际的数据交互。所以上述的实现跟我们使用纯符号实现的性能相差无几。
读入数据模块
数据读取在整体系统性能上占重要地位。MXNet提供工具能将任意大小的样本压缩打包成单个或者数个文件来加速顺序和随机读取。
通常数据存在本地磁盘或者远端的分布式文件系统上(例如HDFS或者Amazon S3),每次我们只需要将当前需要的数据读进内存。MXNet提供迭代器可以按块读取不同格式的文件。迭代器使用多线程来解码数据,并使用多线程预读取来隐藏文件读取的开销。
训练模块
MXNet实现了常用的优化算法来训练模型。用户只需要提供数据数据迭代器和神经网络的Symbol便可。此外,用户可以提供额外的KVStore来进行分布式的训练。例如下面代码使用分布式异步SGD来训练一个模型,其中每个计算节点使用两快GPU。
import MXNet as mx
model = mx.model.FeedForward(
ctx = [mx.gpu(0), mx.gpu(1)],
symbol = network,
num_epoch = 100,
learning_rate = 0.01,
momentum = 0.9,
wd = 0.00001,
initializer = mx.init.Xavier(factor_type="in", magnitude=2.34))
model.fit(
X = train_iter,
eval_data = val_iter,
kvstore = mx.kvstore.create('dist_async'),
epoch_end_callback = mx.callback.do_checkpoint('model_'))
系统实现
计算图
一个已经赋值的符号表达式可以表示成一个计算图。下图是之前定义的多层感知机的部分计算图,包含forward和backward。
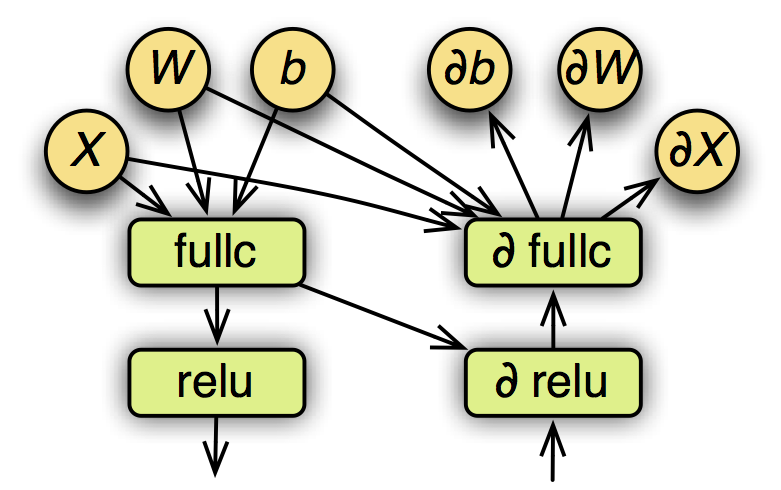
其中圆表示变量,方框表示操作子,箭头表示数据依赖关系。在执行之前,MXNet会对计算图进行优化,以及为所有变量提前申请空间。
计算图优化
计算图优化已经在数据库等领域被研究多年,我们目前只探索了数个简单的方法。
- 注意到我们提前申明了哪些输出变量是需要的,这样我们只需要计算这些输出需要的操作。例如,在预测时不需要计算梯度,所以整个backforward图都可以忽略。而在特征抽取中,可能只需要某些中间层的输出,从而可以忽略掉后面的计算。
- 可以合并某些操作。例如 ab+1*只需要一个blas或者cuda函数即可,而不需要将其表示成两个操作。
- 实现了一些“大”操作,例如一个卷积层就只需要一个操作子。这样我们可以大大减小计算图的大小,并且方便手动的对这个操作进行优化。
内存申请
内存通常是一个重要的瓶颈,尤其是对GPU和智能设备而言。而神经网络计算时通常需要大量的临时空间,例如每个层的输入和输出变量。对每个变量都申请一段独立的空间会带来高额的内存开销。幸运的是,可以从计算图推断出所有变量的生存期,就是这个变量从创建到最后被使用的时间段,从而可以对两个不交叉的变量重复使用同一内存空间。这个问题在诸多领域,例如编译器的寄存器分配上,有过研究。然而最优的分配算法需要 O(n2) 时间复杂度,这里n是图中变量的个数。
MXNet提供了两个启发式的策略,每个策略都是线性的复杂度。
- inplace。在这个策略里,我们模拟图的遍历过程,并为每个变量维护一个还有多少其他变量需要它的计数。当我们发现某个变量的计数变成0时,我们便回收其内存空间。
- co-share。我们允许两个变量使用同一段内存空间。这么做当然会使得这两个变量不能同时在写这段空间。所以我们只考虑对不能并行的变量进行co-share。每一次我们考虑图中的一条路(path),路上所有变量都有依赖关系所以不能被并行,然后我们对其进行内存分配并将它们从图中删掉。
引擎
在MXNet中,所有的任务,包括张量计算,symbol执行,数据通讯,都会交由引擎来执行。首先,所有的资源单元,例如NDArray,随机数生成器,和临时空间,都会在引擎处注册一个唯一的标签。然后每个提交给引擎的任务都会标明它所需要的资源标签。引擎则会跟踪每个资源,如果某个任务所需要的资源到到位了,例如产生这个资源的上一个任务已经完成了,那么引擎会则调度和执行这个任务。
通常一个MXNet运行实例会使用多个硬件资源,包括CPU,GPU,PCIe通道,网络,和磁盘,所以引擎会使用多线程来调度,既任何两个没有资源依赖冲突的任务都可能会被并行执行,以求最大化资源利用。
与通常的数据流引擎不同的是,MXNet的引擎允许一个任务修改现有的资源。为了保证调度正确性,提交任务时需要分开标明哪些资源是只读,哪些资源会被修改。这个附加的写依赖可以带来很多便利。例如我们可以方便实现在numpy以及其他张量库中常见的数组修改操作,同时也使得内存分配时更加容易,比如操作子可以修改其内部状态变量而不需要每次都重来内存。再次,假如我们要用同一个种子生成两个随机数,那么我们可以标注这两个操作会同时修改种子来使得引擎不会并行执行,从而使得代码的结果可以很好的被重复。
数据通讯
KVStore的实现是基于参数服务器。但它跟前面的工作有两个显著的区别。
- 我们通过引擎来管理数据一致性,这使得参数服务器的实现变得相当简单,同时使得KVStore的运算可以无缝的与其他结合在一起。
- 我们使用一个两层的通讯结构,原理如下图所示。第一层的服务器管理单机内部的多个设备之间的通讯。第二层服务器则管理机器之间通过网络的通讯。第一层的服务器在与第二层通讯前可能合并设备之间的数据来降低网络带宽消费。同时考虑到机器内和外通讯带宽和延时的不同性,我们可以对其使用不同的一致性模型。例如第一层我们用强的一致性模型,而第二层我们则使用弱的一致性模型来减少同步开销。
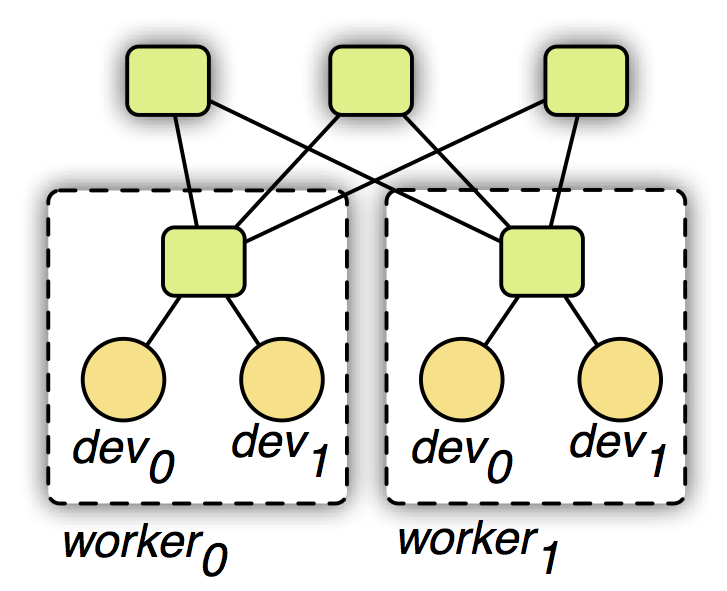
可移植性
轻量和可移植性是MXNet的一个重要目标。MXNet核心使用C++实现,并提供C风格的头文件。因此方便系统移植,也使得其很容易被其他支持C FFI (forigen language interface )的语言调用。此外,我们也提供一个脚本将MXNet核心功能的代码连同所有依赖打包成一个单一的只有数万行的C++源文件,使得其在一些受限的平台,例如智能设备,方便编译和使用。
MXNet Python库操作简介
MXNet的Python库有三个基本的概念:
- NDArray:提供矩阵和张量计算,可在CPU和GPU上进行,并自动化的平行。
- Symbol:使定义神经网络变得非常简单,并提供自动化的微分。
- KVStore:使数据在多GPU和多机器之间的同步变得简单。
NDArray:在CPU和GPU上Numpy类型的张量计算
创建和初始化
可以在GPU或者是CPU上创建NDArray
>>> import mxnet as mx
>>> a = mx.nd.empty((2, 3))
>>> b = mx.nd.empty((2, 3), mx.gpu())
>>> c = mx.nd.empty((2, 3), mx.gpu(2))
>>> c.shape
(2L, 3L)
>>> c.context
gpu(2)
可以通过多种方式进行初始化
>>> a = mx.nd.zeros((2, 3))
>>> b = mx.nd.ones((2, 3))
>>> b[:] = 2
可以将一个数组的值复制给另一个数组,即使是不同是设备
>>> a = mx.nd.ones((2, 3))
>>> b = mx.nd.zeros((2, 3), mx.gpu())
>>> a.copyto(b)
可以将NDArray转换成numpy.ndarray
>>> a = mx.nd.ones((2, 3))
>>> b = a.asnumpy()
>>> type(b)
<type 'numpy.ndarray'>
>>> print b
[[ 1. 1. 1.]
[ 1. 1. 1.]]
反过来也是一样
>>> import numpy as np
>>> a = mx.nd.empty((2, 3))
>>> a[:] = np.random.uniform(-0.1, 0.1, a.shape)
>>> print a.asnumpy()
[[-0.06821112 -0.03704893 0.06688045]
[ 0.09947646 -0.07700162 0.07681718]]
基本操作
元素级别的操作
在默认情况下,NDArray使用元素级别运算
>>> a = mx.nd.ones((2, 3)) * 2
>>> b = mx.nd.ones((2, 3)) * 4
>>> print b.asnumpy()
[[ 4. 4. 4.]
[ 4. 4. 4.]]
>>> c = a + b
>>> print c.asnumpy()
[[ 6. 6. 6.]
[ 6. 6. 6.]]
>>> d = a * b
>>> print d.asnumpy()
[[ 8. 8. 8.]
[ 8. 8. 8.]]
如果两个NDArray位于两个不同的设备,需要将它们移动到一个设备上
>>> a = mx.nd.ones((2, 3)) * 2
>>> b = mx.nd.ones((2, 3), mx.gpu()) * 3
>>> c = a.copyto(mx.gpu()) * b
>>> print c.asnumpy()
[[ 6. 6. 6.]
[ 6. 6. 6.]]
加载和保存
有两种方法使加载和保存数据变得简单。第一种是使用pickle,NDArray兼容pickle
>>> import mxnet as mx
>>> import pickle as pkl
>>> a = mx.nd.ones((2, 3)) * 2
>>> data = pkl.dumps(a)
>>> b = pkl.loads(data)
>>> print b.asnumpy()
[[ 2. 2. 2.]
[ 2. 2. 2.]]
另一种直接将NDArray以二进制的形式倒入到磁盘中
>>> a = mx.nd.ones((2,3))*2
>>> b = mx.nd.ones((2,3))*3
>>> mx.nd.save('mydata.bin', [a, b])
>>> c = mx.nd.load('mydata.bin')
>>> print c[0].asnumpy()
[[ 2. 2. 2.]
[ 2. 2. 2.]]
>>> print c[1].asnumpy()
[[ 3. 3. 3.]
[ 3. 3. 3.]]
可以导入字典
>>> mx.nd.save('mydata.bin', {'a':a, 'b':b})
>>> c = mx.nd.load('mydata.bin')
>>> print c['a'].asnumpy()
[[ 2. 2. 2.]
[ 2. 2. 2.]]
>>> print c['b'].asnumpy()
[[ 3. 3. 3.]
[ 3. 3. 3.]]
自动并行化
NDArray能够自动地进行并行化操作。当我们需要用多个资源进行计算时,这个功能就显得非常友好。
例如,a+=1后面接着b+=1,其中a在CPU上运行,b在GPU上运行,我们希望将他们同时进行运算以提高效率。此外,CPU与GPU之间的数据复制的开销是非常昂贵的,因此我们希望能让运行他们与其他的计算同样能进行运算。
然而通过人眼去判断哪些应该并行处理,哪些不应该并行处理是一件非常难的事情。在下面的例子里,a+=1和c*=3能够进行并行话计算,但是a+=1和b*=3只能按顺序进行计算
a = mx.nd.ones((2,3))
b = a
c = a.copyto(mx.cpu())
a += 1
b *= 3
c *= 3
幸运的是MXNet能自动地解析这些依赖关系,并且能保证并行化操作能正确地运行。如果我们写一个程序,只使用一个单线程,MXNet会自动地将它分配到多个设备上:多个GPU或者是多个机器上。
他这是通过延迟计算实现的。每个我们写的操作都发布到了internal引擎,然后返回来。例如,我们运行a+=1,他在我们将加运算推送到引擎后立即返回结果。这种异步性允许我们push更多的运算到引擎上,因此他能够决定读写的依赖关系,并且选择一个最佳的方式进行并行运算。
当我们相要把计算结果复制到其他地方时,如: print a.asnumpy() or mx.nd.save([a]), 他的运算实际上已经结束了。因此,当我想要写一个高度并行化的代码时,我们只需要延迟访问结果就可以了。
Symbolic and Automatic Differentiation
NDArray是MXNet中最基本的计算单元。除此之外,MXNet提供一个符号化接口,成为Symbol,用来简明地构造神经网络。这个接口很灵活和高效。
Symbols的基本组成
下面的代码创建了两层感知网络:
>>> import mxnet as mx
>>> net = mx.symbol.Variable('data')
>>> net = mx.symbol.FullyConnected(data=net, name='fc1', num_hidden=128)
>>> net = mx.symbol.Activation(data=net, name='relu1', act_type="relu")
>>> net = mx.symbol.FullyConnected(data=net, name='fc2', num_hidden=64)
>>> net = mx.symbol.SoftmaxOutput(data=net, name='out')
>>> type(net)
<class 'mxnet.symbol.Symbol'>
每个Symbol都有一个唯一的字符串名字。变量通常用来定义输入或者自由变量。其他的symbols用一个symbol作为他们的输入,或者接受其他的超参数如隐藏神经元的数量或者激活函数。
这个symbol能够以一个函数的形式被查看,他的参数的名字可以自动生成并且通过下面的方式进行查看。
>>> net.list_arguments()
['data', 'fc1_weight', 'fc1_bias', 'fc2_weight', 'fc2_bias', 'out_label']
可以看到,上面的这些参数是每个symbol所需要的输入参数
- data:variable data所需要的输入数据
- fc1_weight和fc1_bias:是第一全连层fc1所需要的权值和偏执
- fc2_weight和fc2_bias:是第二全连层fc2所需要的权值和偏执
- out_lable:损失函数的计算出来的标签
可以明确地制定生成的名字:
>>> net = mx.symbol.Variable('data')
>>> w = mx.symbol.Variable('myweight')
>>> net = mx.symbol.FullyConnected(data=net, weight=w, name='fc1', num_hidden=128)
>>> net.list_arguments()
['data', 'myweight', 'fc1_bias']
更多复杂的组成
MXNet为深度学习提供了优化的symbols,我们能很容易地定义操作子。下面的例子先在两个symbol之间执行了元素级别的加法,然后将加的结果反馈到了fully connected operator。
>>> lhs = mx.symbol.Variable('data1')
>>> rhs = mx.symbol.Variable('data2')
>>> net = mx.symbol.FullyConnected(data=lhs + rhs, name='fc1', num_hidden=128)
>>> net.list_arguments()
['data1', 'data2', 'fc1_weight', 'fc1_bias']
我们能更加灵活地去构造一个symbol
>>> net = mx.symbol.Variable('data')
>>> net = mx.symbol.FullyConnected(data=net, name='fc1', num_hidden=128)
>>> net2 = mx.symbol.Variable('data2')
>>> net2 = mx.symbol.FullyConnected(data=net2, name='net2', num_hidden=128)
>>> composed_net = net(data=net2, name='compose')
>>> composed_net.list_arguments()
['data2', 'net2_weight', 'net2_bias', 'compose_fc1_weight', 'compose_fc1_bias']
在上面的例子中,net作为一个函数应用于一个已经存在的symbol net,他们的结果composed_net将会替换原始的参数data net2.
参数shape接口
接下来了解如何调用所有参数的大小维数
>>> net = mx.symbol.Variable('data')
>>> net = mx.symbol.FullyConnected(data=net, name='fc1', num_hidden=10)
>>> arg_shape, out_shape, aux_shape = net.infer_shape(data=(100, 100))
>>> dict(zip(net.list_arguments(), arg_shape))
{'data': (100, 100), 'fc1_weight': (10, 100), 'fc1_bias': (10,)}
>>> out_shape
[(100, 10)]
这个shape接口可以用来检测参数shape不一致。
绑定symbol和运行
我们可以绑定symbol的自由变量,执行前馈和反馈的操作。bind函数可以创建一个Excutor用来计算出真正的结果。
>>>
>>> A = mx.symbol.Variable('A')
>>> B = mx.symbol.Variable('B')
>>> C = A * B
>>> a = mx.nd.ones(3) * 4
>>> b = mx.nd.ones(3) * 2
>>>
>>> c_exec = C.bind(ctx=mx.cpu(), args={'A' : a, 'B': b})
>>>
>>> c_exec.forward()
>>> c_exec.outputs[0].asnumpy()
[ 8. 8. 8.]
对于神经网络而言,一个更加常用的形式是simple_bind,将会为你创建所有的参数数组。然后你调用forward和backward来获取梯度。
>>>
>>> net = some symbol
>>> texec = net.simple_bind(data=input_shape)
>>> texec.forward()
>>> texec.backward()
分布式Key-Value存储
KVStore是一个数据共享的地方,我们可以将它认为是一个单一对象被不同的设备所共享,在这里每个设备都能将数据推送和拉取。
Initialization
考虑一个简单的例子,在store里面初始化一个(int, NDArray)对,然后将这个值拉出去。
>>> kv = mx.kv.create('local')
>>> shape = (2,3)
>>> kv.init(3, mx.nd.ones(shape)*2)
>>> a = mx.nd.zeros(shape)
>>> kv.pull(3, out = a)
>>> print a.asnumpy()
[[ 2. 2. 2.]
[ 2. 2. 2.]]
Push, Aggregation, 和 Updater
对于任何已经被初始化的key值,我们可以push一个新的相同大小的值。
>>> kv.push(3, mx.nd.ones(shape)*8)
>>> kv.pull(3, out = a)
>>> print a.asnumpy()
[[ 8. 8. 8.]
[ 8. 8. 8.]]
用来push的值可以在任意的设备上。除此之外,我们可以push多个值到相同的key,首先KVStore会将所有的值进行求和,然后push这个聚合的值。
>>> gpus = [mx.gpu(i) for i in range(4)]
>>> b = [mx.nd.ones(shape, gpu) for gpu in gpus]
>>> kv.push(3, b)
>>> kv.pull(3, out = a)
>>> print a.asnumpy()
[[ 4. 4. 4.]
[ 4. 4. 4.]]
对每次push,KVStore使用updater将push的值和存储的值加起来。默认的updater是ASSIGN,我们可以替换默认的来控制怎样融合数据
>>> def update(key, input, stored):
>>> print "update on key: %d" % key
>>> stored += input * 2
>>> kv._set_updater(update)
>>> kv.pull(3, out=a)
>>> print a.asnumpy()
[[ 4. 4. 4.]
[ 4. 4. 4.]]
>>> kv.push(3, mx.nd.ones(shape))
update on key: 3
>>> kv.pull(3, out=a)
>>> print a.asnumpy()
[[ 6. 6. 6.]
[ 6. 6. 6.]]
Pull
通过一个单独的调用将值pull到几个设备上。
>>> b = [mx.nd.ones(shape, gpu) for gpu in gpus]
>>> kv.pull(3, out = b)
>>> print b[1].asnumpy()
[[ 6. 6. 6.]
[ 6. 6. 6.]]
处理一个键值对的链表
KVStore提供处理一系列键值对的接口,对于单个设备:
>>> keys = [5, 7, 9]
>>> kv.init(keys, [mx.nd.ones(shape)]*len(keys))
>>> kv.push(keys, [mx.nd.ones(shape)]*len(keys))
update on key: 5
update on key: 7
update on key: 9
>>> b = [mx.nd.zeros(shape)]*len(keys)
>>> kv.pull(keys, out = b)
>>> print b[1].asnumpy()
[[ 3. 3. 3.]
[ 3. 3. 3.]]
对多个设备:
>>> b = [[mx.nd.ones(shape, gpu) for gpu in gpus]] * len(keys)
>>> kv.push(keys, b)
update on key: 5
update on key: 7
update on key: 9
>>> kv.pull(keys, out = b)
>>> print b[1][1].asnumpy()
[[ 11. 11. 11.]
[ 11. 11. 11.]]
多机器
基于参数服务器,updater将运行在服务器节点上,
分布式训练
如何在MXNet上写一个分布式程序
MXNet提供了一个分布式key-value store名为kvstore减少了数据同步操作的复杂性。它提供了以下的功能:
push:将本地数据push到分布式存储,如梯度等pull:将数据从分布式存储中pull过来,如新的权值set_updater:为分布式存储设置一个updater,明确store是如何将接收到的数据进行融合的,例如:怎样使用接收到的梯度来更新权值。
如果你的程序按照下面的结构写的,事情会更加简单:
data = mx.io.ImageRecordIter(...)
net = mx.symbol.SoftmaxOutput(...)
model = mx.model.FeedForward.create(symbol = net, X = data, ...)
上面的数据是取自于一个image record iterator,并使用一个符号化网络进行模型训练。为了将它扩展成一个分布式的程序,首先要建立一个kvstore,然后将它传入到create函数中。下面的程序将上面的SGD修改成了分布式异步的SGD:
kv = mx.kvstore.create('dist_sync')
model = mx.model.FeedForward.create(symbol = net, X = data, kvstore = kv, ...)
使用下面的命令,用本地机器来模拟一个分布式的环境(两个工作节点,两个服务器节点):
mxnet/tracker/dmlc_local.py -n 2 -s 2 python train.py
数据并行
在上面的例子中每个工作节点处理整个训练数据。对于收敛这不是所期望的,因为它们可能在一次迭代中对相同的数据计算同一个梯度,因此这并没有提高计算速度。
这个问题可以通过数据并行来解决,也就是每个工作节点处理数据的一部分。kvstore提供两个函数用来查询工作节点的信息:
kvstore.num_workers:返回工作节点的数目。kvstore.rank:返回当前worker的唯一的rank值,是一个[0,kvstore.num_workers-1]的整数。
此外,mxnet提供的数据迭代器支持对数据的虚拟分区,它会将数据分成几个parts,并且只会读取其中的一个part。因此,我们可以将上面的程序改为,将数据分成和num_workers一样数目的parts,并要求每个worker只读其中的一个part:
data = mx.io.ImageRecordIter(num_parts = kv.num_workers, part_index = kv.rank, ...)
同步和异步
kvstore提供两种方式将minibatch SGD转变成一个分布式版本。第一种方式是使用Bulk Synchronous Parallel (BSP) protocol,在MXNet上被称为dist_sync。在更新权值之前,它会将每次迭代中(或者minibatch中)所有工作节点上产生的梯度值聚合起来。假设每个工作节点使用mini-batch 的大小为
b
,并且总共有 n 个workers。然后dist_sync将会产生与单个worker处理batch大小为
b∗n
相似的结果。
需要注意的是,由于数据分区的不完善,每个worker可能会得到有些不同大小的数据。为了确保每个worker在每次数据传递时计算相同数目的batches,我们需要在create函数中为dist_sync明确的设置epoch_size的大小(对于dist_async不需要)。其中一种可选方式是:
epoch_size = num_examples_in_data / batch_size / kv.num_workers
第二种方式是使用异步来更新,被称为dist_async。在这个协议中,每个worker独立地更新权值。仍假设有
n
个workers,每个worker使用batch 大小为b的数据。然后dist_async可以被视为单个机器SGD使用batch大小为b,但是在每次迭代过程中,它会使用几次迭代之前的权值(平均为n)来计算梯度。
哪个方式更好往往取决于几个因素。通常来说,dist_async要比dist_sync快,因为没有workers之间的数据同步。但是dist_sync可以保证收敛,也就是说,它相当于单个机器使用相当大小的batch大小。关于dist_async的收敛速率仍然是一个有趣的研究课题。
如果使用dist_sync,一个sever首先会将所有的workers产生的梯度值聚合在一起,然后再执行更新。当使用dist_async时,server会在接收到任意worker传来的梯度值后立即更新。
在一个集群上载入任务
MXNet提供几种方式在一个集群上载入任务,包括了资源管理器如:Yarn或者简单的ssh
机器使用多网卡情况
对于机器集群上安装了多网卡的用户,MXNet提供了方法让你选择你想选的网卡。例如:你的机器装备了两个网卡,一张卡叫做“eth0(ethernet device)”,另一张卡叫做“ib0(infiniband device)”。你能按下面的方式选择NIC
export DMLC_INTERFACE="ib0"
或
export DMLC_INTERFACE="eth0"
深度学习编程模型
MXNet有多个机器学习的库,每一个都有它自己的特点。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)