大数据学习之Hadoop3.2.2集群环境搭建
(一)Hadoop3.2.2完全分布式集群环境搭建
(二)Zookeeper入门之分布式集群的搭建
(三)HBase分布式集群的搭建
Apache hadoop是什么?
Apache™ Hadoop® 项目开发用于可靠、可扩展、分布式计算的开源软件。
Apache Hadoop 软件库是一个框架,允许使用简单的编程模型跨计算机集群分布式处理大型数据集。它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。该库本身不是依靠硬件来提供高可用性,而是设计用于检测和处理应用层的故障,因此在计算机集群之上提供高可用性服务,每台计算机都可能容易出现故障。
准备工作:
jdk-8u291-linux-x64.tar.gz
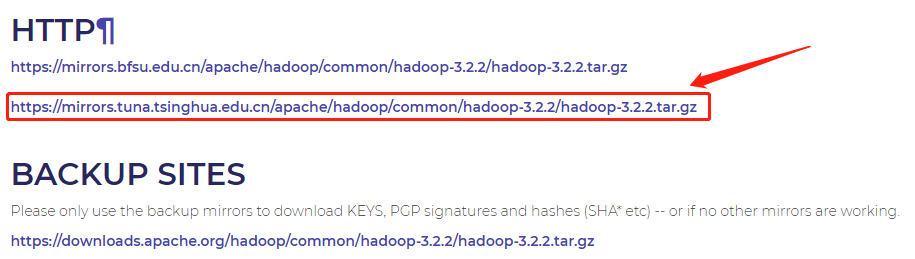
hadoop-3.2.2.tar.gz
虚拟机hadoop,hadoop1,hadoop2配置:
| hadoop | hadoop1 | hadoop2 |
|---|
| IP | 192.168.10.100 | 192.168.10.101 | 192.168.10.102 |
集群规划:
| hadoop | hadoop1 | hadoop2 |
|---|
| HDFS |
N
a
m
e
N
o
d
e
\color{#FF3030}{ NameNode }
NameNode
DataNode | DataNode |
S
e
c
o
n
a
r
y
N
a
m
e
N
o
d
e
\color{#FF3030}{ SeconaryNameNode }
SeconaryNameNode
DataNode |
| YARN | NadeManager |
R
e
s
o
u
r
c
e
M
a
n
a
g
e
r
\color{#FF3030}{ ResourceManager }
ResourceManager
NodeManager | NodeManager |
修改网络连接方式为NAT模式
修改虚拟适配器VMnet8:

(一)创建模板机hadoop:
(1)创建用户hadoop,修改密码为123456:
[root@h ~]
[root@h ~]
(2)配置hadoop用户具有root权限,方便后期sudo执行root权限的命令:
[root@h ~]
hadoop ALL=(ALL) NOPASSWD:ALL

(3)关闭防火墙(这很重要):
[root@h ~]
[root@h ~]
(4)修改主机名:
[root@h ~]
(5)把原来的主机名删了,修改为hadoop:

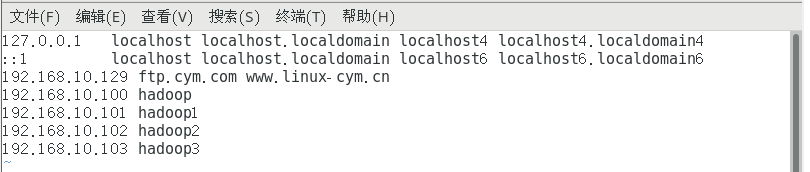
(6)修改ip地址映射:
[root@h ~]
(7)修改为静态ip(网卡名称可能不一样):
[root@h ~]
BOOTPROTO=static
ONBOOT="yes"
IPADDR=192.168.10.100
GATEWAY=192.168.10.2
DNS1=192.168.10.2
[root@h ~]
systemctl stop NetworkManager
systemctl disable NetworkManager
(8)切换用户hadoop,创建/opt/jdk—hadoop目录,用来存放jdk,hadoop:
[hadoop@hadoop ~]$ mkdir /opt/jdk-hadoop
(二)克隆模板虚拟机hadoop,生成hadoop1,hadoop2
(1)进入hadoop1,修改主机名与ip(192.168.10.101):
[root@hadoop ~]
IPADDR=192.168.10.101
(2)修改主机名为hadoop1:
[root@hadoop ~]
(3)进入hadoop2,修改主机名与ip(192.168.10.102):
[root@hadoop ~]
IPADDR=192.168.10.102
(4)修改主机名为hadoop2:
[root@hadoop ~]
(三)ssh免密登录:
1.在虚拟机hadoop的hadoop用户下生成ssh秘钥
[hadoop@hadoop ~]$ ssh-keygen -t rsa
2.将公钥分发给其余两台虚拟机的hadoop用户:
[hadoop@hadoop ~]$ ssh-copy-id -i hadoop@192.168.10.100
[hadoop@hadoop ~]$ ssh-copy-id -i hadoop@192.168.10.101
[hadoop@hadoop ~]$ ssh-copy-id -i hadoop@192.168.10.102
3.现在确认能否不输入口令就用ssh登录localhost:
[hadoop@hadoop ~]$ ssh localhost
4.如果不输入口令就无法用ssh登陆localhost,执行下面的命令:
[hadoop@hadoop ~] ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
[hadoop@hadoop ~] cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
进入虚拟机hadoop1,hadoop2重复1~3的操作
(四)jdk安装:
(1)将jdk的压缩包放在/opt/jdk-hadoop目录下并解压到/opt/jdk-hadoop目录下:
tar -zxvf jdk-8u291-linux-x64.tar.gz
(2)编辑/etc/profile文件,在文件末尾添加以下内容
export JAVA_HOME=/opt/jdk-hadoop/jdk1.8.0_291
export PATH=$PATH:JAVA_HOME/bin:
source /etc/profile
java -version
java version "1.8.0_291"

(五)Hadoop的安装
(1)将hadoop的压缩包放在/opt/jdk-hadoop目录下并解压到/opt/jdk-hadoop目录下:
tar -zxf hadoop-3.2.2.tar.gz
(2)编辑/etc/profile文件,在文件末尾添加以下内容:
export HADOOP_HOME=/opt/jdk-hadoop/hadoop-3.2.2
export PATH=$PATH:$HADOOP_HOME/bin
source /etc/profile
hadoop

(六)修改Hadoop文件
(1)hadoop-env.sh
cd /opt/jdk-haoop/hadoop-3.2.2/etc/hadoop/
vim hadoop-env.sh
export JAVA_HOME=/opt/jdk-hadoop/jdk1.8.0_291
(2)core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/jdk-haoop/hadoop-3.2.2/data</value>
</property>
</configuration>
(3)hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9868</value>
</property>
</configuration>
(4)mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/jdk-haoop/hadoop-3.2.2/share/hadoop/mapreduce/*, /opt/jdk-haoop/hadoop-3.2.2/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
(5)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
</configuration>
(6)workers
cd /opt/jdk-haoop/hadoop-3.2.2/etc/hadoop/
vim workers
hadoop
hadoop1
hadoop2
(七)启动hadoop
(1)分发jdk与hadoop给虚拟机hadoop1,hadooop2
scp -r /opt/jdk-hadoop/hadoop-3.3.2 hadoop@hadoop1:/opt/jdk-hadoop
scp -r /opt/jdk-hadoop/hadoop-3.3.2 hadoop@hadoop2:/opt/jdk-hadoop
scp -r /opt/jdk-hadoop/jdk1.8.0_291 hadoop@hadoop1:/opt/jdk-hadoop
scp -r /opt/jdk-hadoop/jdk1.8.0_291 hadoop@hadoop2:/opt/jdk-hadoop
(2)格式化namenode:
cd /opt/jdk-hadoop/hadoop-3.2.2
hdfs namenode -format
(3)在hadoop虚拟机上:
cd /opt/jdk-hadoop/hadoop-3.2.2/sbin
./start-dfs.sh
(4)在hadoop1上运行:
cd /opt/jdk-hadoop/hadoop-3.2.2/sbin
./start-yarn.sh
(5)在三台虚拟机上分别输入jps,显示如下则符合集群规划:
| hadoop | hadoop1 | hadoop2 |
|---|
| HDFS |
N
a
m
e
N
o
d
e
\color{#FF3030}{ NameNode }
NameNode
DataNode | DataNode |
S
e
c
o
n
a
r
y
N
a
m
e
N
o
d
e
\color{#FF3030}{ SeconaryNameNode }
SeconaryNameNode
DataNode |
| YARN | NadeManager |
R
e
s
o
u
r
c
e
M
a
n
a
g
e
r
\color{#FF3030}{ ResourceManager }
ResourceManager
NodeManager | NodeManager |
hadoop(生产环境中NameNode和Datanode 不会在同一节点中):
[hadoop@hadoop sbin]$ jps
7585 NameNode
7703 DataNode
13132 NodeManager
13261 Jps
hadoop1:
[hadoop@hadoop1 sbin]$ jps
2690 DataNode
3850 ResourceManager
4031 Jps
hadoop2:
[hadoop@hadoop2 ~]$ jps
3280 DataNode
3360 SecondaryNameNode
5878 NodeManager
5996 Jps
注意:jps命令为查看jvm进程,默认为本机
(6)浏览器输入以下会看到相应的网页:
192.168.10.100:9870
192.168.10.100:9000
参考地址:http://hadoop.apache.org/docs/r1.0.4/cn/cluster_setup.html
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)