经过多天的奋战,终于写出了一个完成的cnn框架,里面最主要的还是卷积反向传播这一块
网络架构
用到的包
数据集:minist
这里是随机抽取了1000份做训练集

100份做测试集

整体流程
'''先思考一下,前面的28*28*1的图片那么特征数为784,而对于一张比较小的图片100*100*3(其实100*100*3还是很小的一张图)来说大小特征数为30000那么第一层w就会有30000个
对于这么多参数的优化,时=是非常的浪费时间的,特别是每次迭代时一个batch如果为10即一次只处理10张图片的话,那就更加吃力,那么卷积神经网络
可以很好解决这种情况,看看卷积神经网络的原理--损失函数的定义-参数的优化'''
'''输入层 -- 卷积层 -- 池化层(下采样/压缩) -- 全连接层'''
import numpy as np
import random
def load_data():
# 训练集
with open('C:/Users/admin/Desktop/新建文件夹/数据挖掘/机器学习/多层感知机/MINIST_data/train-images.idx3-ubyte') as f:
loaded = np.fromfile(file=f, dtype=np.uint8)
train_data = loaded[16:].reshape((60000, 784))
print(train_data.shape) # (60000, 784)
with open('C:/Users/admin/Desktop/新建文件夹/数据挖掘/机器学习/多层感知机/MINIST_data/train-labels.idx1-ubyte') as f:
loaded = np.fromfile(file=f, dtype=np.uint8)
train_labels = loaded[8:]
print(train_labels.shape) # (60000,)
# 测试集
with open('C:/Users/admin/Desktop/新建文件夹/数据挖掘/机器学习/多层感知机/MINIST_data/t10k-images.idx3-ubyte') as f:
loaded = np.fromfile(file=f, dtype=np.uint8)
test_data = loaded[16:].reshape((10000, 784))
print(test_data.shape) # (10000, 784)
with open('C:/Users/admin/Desktop/新建文件夹/数据挖掘/机器学习/多层感知机/MINIST_data/t10k-labels.idx1-ubyte') as f:
loaded = np.fromfile(file=f, dtype=np.uint8)
test_labels = loaded[8:].reshape((10000))
print(test_labels.shape) # (10000,)
return train_data, train_labels, test_data, test_labels
def max_pooling(array):
n, m = array.shape
new_image = np.zeros((int(n / 2), int(m / 2)))
delta_pooling = np.zeros((n, m))
for i in range(0, int(n / 2)):
for j in range(0, int(m / 2)):
new_image[i][j] = np.max(array[i * 2:i * 2 + 2, j * 2:j * 2 + 2])
index = np.unravel_index(array[i * 2:i * 2 + 2, j * 2:j * 2 + 2].argmax(),
array[i * 2:i * 2 + 2, j * 2:j * 2 + 2].shape)
middle = np.zeros((2, 2))
middle[index[0]][index[1]] = 1
delta_pooling[i * 2:i * 2 + 2, j * 2:j * 2 + 2] = middle
return new_image, delta_pooling
def conv_3d(array, kernel, b, stride=1):
n, h, w = array.shape
n_1, h_1, w_1 = kernel.shape
new_image = np.zeros((h - h_1 + 1, w - w_1 + 1))
delta = np.zeros(kernel.shape)
for i in range(0, h - h_1 + 1):
for j in range(0, w - w_1 + 1):
new_image[i][j] = np.sum(array[:, i:i + h_1, j:j + w_1] * kernel) + b
return new_image
class Linear(object):
def __init__(self, input_size, output_size):
scale = np.sqrt(input_size / 2)
self.W = np.random.standard_normal((input_size, output_size)) / scale
self.b = np.random.standard_normal(output_size) / scale
self.W_grad = np.zeros((input_size, output_size))
self.b_grad = np.zeros(output_size)
def forward(self, x):
self.x = x
out = np.dot(x, self.W) + self.b
return out
def bp(self, delta, lr):
'''简单的反向传播过程'''
shape = delta.shape
self.b_grad = np.sum(delta, axis=0) / shape[0]
self.W_grad = np.dot(self.x.T, delta) / shape[0]
new_delta = np.dot(delta, self.W.T)
self.W -= lr * self.W_grad
self.b -= lr * self.b_grad
return new_delta
class Relu(object):
def forward(self, x):
self.x = x
return np.maximum(x, 0)
def backward(self, delta):
delta[self.x < 0] = 0
return delta
class Pooling(object):
def forward(self, x):
self.x = x
shape = self.x.shape
out = np.zeros((shape[0], shape[1], shape[2] // 2, shape[3] // 2))
self.delta = np.zeros(shape)
for i in range(shape[0]):
for j in range(shape[1]):
out[i][j], self.delta[i][j] = max_pooling(self.x[i][j])
return out
def bp(self, delta):
shape = self.delta.shape
for i in range(shape[0]):
for j in range(shape[1]):
for n in range(shape[2]):
for m in range(shape[3]):
if self.delta[i][j][n][m] == 1:
self.delta[i][j][n][m] = delta[i][j][n // 2][m // 2]
return self.delta
pass
class Softmax(object):
def forward(self, x, y):
self.x = x
shape = self.x.shape
out = np.exp(self.x - np.max(self.x))
for i in range(shape[0]):
sums = np.sum(out[i, :])
for j in range(shape[1]):
out[i][j] = out[i][j] / sums
loss = 0
delta = np.zeros(shape)
for i in range(shape[0]):
delta[i] = out[i] - y[i]
for j in range(shape[1]):
loss += - y[i][j] * np.log(out[i][j])
loss /= shape[0]
return loss, delta
pass
class Conv(object):
def __init__(self, kernel_shape, stride=1):
n_out, n_in, wk, hk = kernel_shape
self.stride = stride
scale = np.sqrt(3 * wk * hk * n_in / n_out)
self.k = np.random.standard_normal(kernel_shape) / scale
self.b = np.random.standard_normal(n_out) / scale
self.k_grad = np.zeros(kernel_shape)
self.b_grad = np.zeros(n_out)
def forward(self, x):
self.x = x
shape0 = self.x.shape
shape1 = self.k.shape
out = np.zeros((shape0[0], shape1[0], shape0[2] - shape1[2] + 1, shape0[3] - shape1[3] + 1))
for i in range(out.shape[0]):
for j in range(out.shape[1]):
out[i][j] = conv_3d(self.x[i], self.k[j], self.b[j])
return out
def bp(self, delta, lr):
shape = delta.shape
for i in range(shape[0]):
for j in range(shape[1]):
for n in range(shape[2]):
for m in range(shape[3]):
self.k_grad[j] += delta[i, j, n, m] * self.x[i, :, n:n + self.k.shape[2],
m:m + self.k.shape[3]]
self.b_grad = np.sum(delta, axis=(0, 2, 3))
self.k_grad /= shape[0]
self.b_grad /= shape[0]
'''计算x的梯度'''
k_180 = np.rot90(self.k, 2, (2, 3))
new_delta = np.zeros(self.x.shape)
shape1 = self.x.shape
padding = np.zeros(
(shape1[0], shape[1], self.x.shape[2] + self.k.shape[2] - 1, self.x.shape[3] + self.k.shape[3] - 1))
pad = (self.x.shape[2] + self.k.shape[2] - 1 - delta.shape[2]) // 2
for i in range(padding.shape[0]):
for j in range(padding.shape[1]):
padding[i][j] = np.pad(delta[i][j], ((pad, pad), (pad, pad)), 'constant')
k_180 = k_180.swapaxes(0, 1)
shape0 = padding.shape
shape1 = k_180.shape
out = np.zeros((shape0[0], shape1[0], shape0[2] - shape1[2] + 1, shape0[3] - shape1[3] + 1))
for i in range(out.shape[0]):
for j in range(out.shape[1]):
out[i][j] = conv_3d(padding[i], k_180[j], 0)
self.k -= lr * self.k_grad
self.b -= lr * self.b_grad
return out
def get_batchsize(batch_size, N):
a = []
b = list(range(N))
random.shuffle(b)
for i in range(N):
l = b[i * batch_size:batch_size * (i + 1)]
a.append(l)
if len(l) < batch_size:
break
return a
def train():
N = 1000
random_index = random.sample(range(train_data.shape[0]), N)
train_x = train_data[random_index]
train_y = train_labels[random_index]
oneHot = np.identity(10)
train_y = oneHot[train_y]
train_x = train_x.reshape(N, 1, 28, 28) / 255
conv1 = Conv(kernel_shape=(6, 1, 5, 5)) # N * 6 * 24 * 24
relu1 = Relu()
pool1 = Pooling() # N * 6 * 12 *12
conv2 = Conv(kernel_shape=(16, 6, 5, 5)) # N * 16 * 8 * 8
relu2 = Relu()
pool2 = Pooling() # N * 16 * 4 * 4
linear = Linear(256, 10)
softmax = Softmax()
epoch = 10
batch_size = 10
lr = 0.01
for i in range(epoch):
batch_radom_index = get_batchsize(batch_size, N)
for n, indexs in enumerate(batch_radom_index):
if len(indexs) == 0:
break
batch_x = train_x[indexs]
batch_y = train_y[indexs]
out = conv1.forward(batch_x)
out = relu1.forward(out)
out = pool1.forward(out)
out = conv2.forward(out)
out = relu2.forward(out)
out = pool2.forward(out)
out = out.reshape(batch_size, -1)
out = linear.forward(out)
loss, delta = softmax.forward(out, batch_y)
delta = linear.bp(delta, lr)
delta = delta.reshape((batch_size, 16, 4, 4))
delta = pool2.bp(delta)
delta = relu2.backward(delta)
delta = conv2.bp(delta, lr)
delta = pool1.bp(delta)
delta = relu1.backward(delta)
conv1.bp(delta, lr)
print("Epoch-{}-{:05d}".format(str(i), n), ":", "loss:{:.4f}".format(loss))
lr *= 0.95 ** (i + 1) # 学习率指数衰减
np.savez("data.npz", k1=conv1.k, b1=conv1.b, k2=conv2.k, b2=conv2.b, w3=linear.W, b3=linear.b)
def test():
r = np.load("data.npz") # 载入训练好的参数
N = 100
random_index = random.sample(range(test_data.shape[0]), N)
test_x = test_data[random_index]
test_y = test_labels[random_index]
# oneHot = np.identity(10)
# test_y = oneHot[test_y]
test_x = test_x.reshape(len(test_x), 1, 28, 28) / 255. # 归一化
conv1 = Conv(kernel_shape=(6, 1, 5, 5)) # N * 6 * 24 * 24
relu1 = Relu()
pool1 = Pooling() # N * 6 * 12 *12
conv2 = Conv(kernel_shape=(16, 6, 5, 5)) # N * 16 * 8 * 8
relu2 = Relu()
pool2 = Pooling() # N * 16 * 4 * 4
nn = Linear(256, 10)
softmax = Softmax()
conv1.k = r["k1"]
conv1.b = r["b1"]
conv2.k = r["k2"]
conv2.b = r["b2"]
nn.W = r["w3"]
nn.b = r["b3"]
out = conv1.forward(test_x)
out = relu1.forward(out)
out = pool1.forward(out)
out = conv2.forward(out)
out = relu2.forward(out)
out = pool2.forward(out)
out = out.reshape(N, -1)
out = nn.forward(out)
num = 0
for i in range(N):
if np.argmax(out[i, :]) == test_y[i]:
num += 1
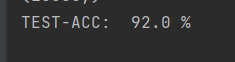
print("TEST-ACC: ", num / N * 100, "%")
train_data, train_labels, test_data, test_labels = load_data()
if __name__ == '__main__':
test()
准备下一步RNN了
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)