Paper review: Dynamic Routing Between Capsules
- 基本信息
- 主要内容
- 摘要
- 基本思想
- 神经科学设想
- routing-by-agreement
- 卷积胶囊
- 算法和网络
-
- 实验结果和分析
- 普通的MNIST
- 用重构展示了capsule每个维度代表的特征
- 对于仿射变换的鲁棒性
- 分割高度重叠的数字
- 其他的数据集
- 讨论和先前的工作
- 附录:how many routing iterations to use?
- 个人思考
基本信息
Dynamic Routing Between Capsules
文章题目:胶囊间的动态路由
作者: Sara Sabour, Nicholas Frosst, Geoffrey E. Hindon,其中Sara Sabour和Nicholas Frosst为Geoffrey E. Hinton在Google Brain的同事。
源文链接:https://arxiv.org/pdf/1710.09829.pdf
**注:**胶囊是一组神经元,神经元的激活值组成了表征实例参数的一个向量,因此治学严谨的学者建议将胶囊称为“向量神经元”或“张量神经元”,本人也赞同这样称呼,但是胶囊一词在中国传播较广,比较简洁,在本文使用“胶囊”这一名词。
主要内容
摘要
一个胶囊是一组神经元,神经元的激活值(activity value)组成的向量(activity vector)可以代表一类实体的实例参数(instantiation parameters of a specific type of entity)。其中激活向量的长度代表这类实体存在的可能性(通过非线性函数,在保证向量方向不受影响的情况下,使激活向量的长度不超过1,以此来代表对应数字存在的概率),向量的方向可以表示描述实体的参数或者说特性(例如姿态,包括位置、尺寸和方向,变形,速度,反光率,质地,色调等)。低级的胶囊通过转换矩阵为高级胶囊的实例参数做预测(我的理解是低层网络的向量信息不能直接来表征某个实例,因为太多了,看不出什么,所以就经过transformation matrix形成更加简洁的高层来做预测,维度扩大种类变少,并且在这个过程中向量的方向信息得以保存),来自低层预测的吻合越多,高层胶囊激活值长度越大。上下两层之间的连接作者采用了一种“routing-by-agreement”机制:低层网络倾向于连接与它的预测结果(经过transformation matrix后的结果)标量积的值更大的激活向量的高层胶囊。作者展示了经过判别式训练方法(应该属于判别式学习算法的范畴,discriminative learning algorithm;与之相对的是生成学习算法,generative learning algorithm),所设计的多层胶囊网络可以在MNIST数据集上达到目前最好的准确率,并且这种网络在高度重叠的手写字符重叠中会表现地比卷积神经网路更好。
基本思想
神经科学设想
人类的视觉通过精细地确定一系列焦点来忽略无关细节保证一个时刻仅有一小部分感光阵列以最高的分辨率被处理。在此篇论文中,作者通过臆想假定生物的多层视觉神经系统在每个视觉焦点上形成一个稀疏的树形网络,而且可以在一个焦点上识别多个物体,并且忽略不同焦点对应的树形稀疏网络是如何相互协作的。以往稀疏的树形网络是通过即时访问存储器构造的,在此篇论文中单焦点的树形稀疏网络是从一个固定大小的多层网络中“雕刻”出来的,就像从一块大岩石中雕刻出一座雕塑一样。树形稀疏网络的每一层神经元被划分成不同的组,一个组就称为一个胶囊。通过“routing-by-agreement” 方法低一级胶囊会选择性地连接高一级的胶囊,这对高一级的胶囊可以看作是把局部归位于整体。
routing-by-agreement
胶囊的输出是激活向量这一事实允许低层胶囊通过高效的路由方法,也即routing-by-agreement,连接到相关的高级胶囊上。具体的机制是,低层的胶囊用自己的激活向量与转换矩阵作积,得到的预测向量再与高层胶囊的输出(也即高级胶囊的激活向量)做标量积,如果得到的标量积很大就会增强这一对上下级胶囊间的相关性系数,同时减弱与上级其他胶囊间的相关性系数,这样就形成了一个“top-down”之间的正反馈的作用(所有相关性系数的和是1.0)。这种方法应该(should)比最原始的“max-pooling” 路由方法有效,在“max-pooling”路由方法中上级神经元只接受下级神经元中最强的特征向量。在之后的实验结果中这种"routing-by-agreement"方法也展现出了作为分割重叠数字的解释性方法的有效性。
卷积胶囊
卷积神经网络使用经过学习的特征检测器(learned feature detectors)产生的很多特征副本,这就允许跨越空间传递一些学习到的“知识”(我理解为学习到的卷积核,或者说卷积核的权值),这种方法在图像识别任务中已经被证实是有效的。即使在此篇论文中作者用向量输出的胶囊代替了CNN中标量输出的特征检测器,用“routing-by-agreement”代替了“max-pooling”作为向上传递的方法,但是为了跨越空间传递获得的knowledge,此文设计的网络中除最后一层其他层均为卷积形式。与CNN中相同的是,更高层的胶囊会覆盖更大的图像范围,但是不像“max-pooling”,在“routing-by-agreement”中没有丢失这个区域中实例的准确位置信息。对于低级的胶囊来说位置信息隐含在胶囊的位置中(也就是具体是哪个胶囊激活了),随着级数的增高,位置信息慢慢转换为在胶囊的实部中以频率的形式编码。
算法和网络
算法细节
作者强调此篇论文只是介绍胶囊网络和routing-by-agreement的基本思想,更多的设计空间有待后续去探索
为了保证得到的胶囊的激活向量的长度在(0,1.0)区间内,作者采用了“squashing”非线性函数。
v
j
=
∥
s
j
∥
2
1
+
∥
s
j
∥
2
s
j
∥
s
j
∥
(
1
)
\mathbf{v}_j = \frac{{\parallel \mathbf{s}_j\parallel}^2}{1 + {\parallel \mathbf{s}_j \parallel}^2}\frac{\mathbf{s}_j}{{\parallel \mathbf{s}_j\parallel}}\ (1)
vj=1+∥sj∥2∥sj∥2∥sj∥sj (1)
其中
v
j
\mathbf{v}_j
vj是这一级胶囊的输出,
s
j
\mathbf{s}_j
sj是所有所连接的低一级胶囊的输出与权重矩阵乘积的加权和。
s
j
=
∑
i
c
i
j
u
^
j
∣
i
(
2.1
)
\mathbf{s}_j = \sum_{i} {c}_{ij}\mathbf{\hat{u}}_{j|i}\ (2.1)
sj=i∑ciju^j∣i (2.1)
u
^
j
∣
i
=
W
i
j
u
i
(
2.2
)
\mathbf{\hat{u}}_{j|i} = \mathbf{W}_{ij}\mathbf{u}_i\ (2.2)
u^j∣i=Wijui (2.2)
c
i
j
{c}_{ij}
cij就是通过“routing-by-agreement”获得的上下级间胶囊的相关性系数,一个胶囊向上级连接的所有相关性系数和为1.0。并由“routing softmax”公式决定,其中
b
i
j
的
初
始
值
是
由
先
验
概
率
的
对
数
值
(
l
o
g
p
r
i
o
r
p
r
o
b
a
b
i
l
i
t
y
)
决
定
,
在
作
者
的
实
验
设
定
中
初
始
值
均
为
0
,
没
有
使
用
先
验
概
率
b_{ij}的初始值是由先验概率的对数值(log prior probability)决定,在作者的实验设定中初始值均为0,没有使用先验概率
bij的初始值是由先验概率的对数值(logpriorprobability)决定,在作者的实验设定中初始值均为0,没有使用先验概率:
c
i
j
=
e
x
p
(
b
i
j
)
∑
k
e
x
p
(
b
i
k
)
(
3
)
c_{ij} = \frac{exp(b_{ij})}{\sum_{k}exp(b_{ik})}\ (3)
cij=∑kexp(bik)exp(bij) (3)
c
i
j
c_{ij}
cij的后续调整是与权值一起学习得到的,agreement的强弱由下式决定,这个agreement值将会被当作具有对数似然性在重新计算前加到
b
i
j
b_{ij}
bij上:
a
i
j
=
v
j
⋅
u
^
j
∣
i
(
4
)
a_{ij} = \mathbf{v}_j\cdot\mathbf{\hat{u}}_{j|i}\ (4)
aij=vj⋅u^j∣i (4)
在卷积胶囊层中,胶囊的每个单元都是一个卷积单元,因此一个胶囊将会输出一个向量矩阵而不是单个向量输出(a grid of vectors rather than a single vector output)。
routing-by-agreement的算法伪代码如下:

数字存在性的损失函数(对于MNIST):
为了允许多个数字存在的情况,作者设计了一种分离的损失函数,
L
k
\mathbf{L}_k
Lk代表代表每个数字的胶囊k:
L
c
=
T
c
m
a
x
(
0
,
m
+
−
∥
v
c
∥
)
2
+
λ
(
1
−
T
c
)
m
a
x
(
0
,
∥
v
c
∥
−
m
−
)
2
\mathbf{L}_{c} = T_{c}\mathbf{max}(0, m^{+} - \parallel\mathbf{v}_{c}\parallel)^2 + \lambda(1- T_{c})\mathbf{max}(0, \parallel\mathbf{v}_{c}\parallel - m^{-})^2
Lc=Tcmax(0,m+−∥vc∥)2+λ(1−Tc)max(0,∥vc∥−m−)2
如果数字c在图片中存在,
T
c
T_{c}
Tc就等于1,不存在就为0。
m
+
=
0.9
m^+ = 0.9
m+=0.9 ,
m
−
=
0.1
m^- = 0.1
m−=0.1。缺失种类的下权值(down-weighting)损失可以阻止初期学习过程对所有胶囊尺寸的缩减。整体的损失
L
\mathbf{L}
L就是各个数字胶囊损失的总和。作者建议
λ
=
0.5
\lambda = 0.5
λ=0.5。
网络结构
网络主体
作者介绍的网络结构主体是一个简单的三层网络,两个卷积层加一个全连接层。第一层是普通的CNN卷积层,将像素点的像素强度值转换为局部特征检测器的活性值,是输入图像经过256X(9X9)的卷积核以1为slide步进卷积后送入ReLU非线性函数得到的输出;第二层是胶囊卷积网络,称为“Primary Capsules”,是第一层256张feature map经过32(channel)X8(Dimension)个(256X9X9)尺寸的卷积核以2为步进卷积得到,并形成32组8D的向量版的feature map,也就是第二层一共有32X6X6个胶囊,每个胶囊是8D的向量,一个grid中(8D的其中一维)的capsule元素是共用一套权值(一个(256X9X9)尺寸的卷积核)的,输出的非线性函数是squashing函数,也就是Eqs(1)。作者特别说明**“Primary Capsule”层是拥有多维属性的最底层**,激活这一层的神经元就好比图像渲染的反过程;第三层是“Digit Capsules”,是10个(代表10中数字字符)16D的胶囊单元,也是网络的输出层,每个单元通过routing-by-agreement接收来自第二层的所有(32X[6X6]个)向量版的feature map(相当于全连接)中的每个胶囊,连接的权值是一个[8X16]的二维矩阵,具体的结构如下图所示。

用重构来做正则化方法
作者介绍的网络主体是一个三层网络,除此之外还可以另外加入重构网络,通过加入重构网络得到的损失(重构网络训练的目标是缩小重构网络输出与图片原始像素值的Euclidean距离,在训练期间重构损失被加权了0.0005,防止其占据主要的损失),使得“Digit Capsule”实现对输入数字实例参数的编码,重构的网络结构如下:

对于每一个实例,只取出与实例数字对应的“Digit Capsule”来做重构。三个全连接层是用来给像素强度建模的。作者在TensorFlow中实现了算法,并且使用了Adam Optimizer以及指数型衰减的学习律。
c
i
j
c_{ij}
cij是通过“top-down”的“routing-by-agreement”方法学习的,也即
b
i
j
=
b
i
j
+
u
^
j
∣
i
⋅
v
j
b_{ij} = b_{ij} + \mathbf{\hat{u}}_{j|i}\cdot\mathbf{v}_j
bij=bij+u^j∣i⋅vj。
实验结果和分析
普通的MNIST
先上两张结果的论文截图,第一张是分类准确率,第二张主要展示的是几个正确和错误分类的输入图和对应输出正确Digit Capsule的重构图,从重构图的直观感觉看该网络学习到了数字的特征细节同时平滑了噪声。在没有使用ensembling or drastic data augmentation的情况下,准确率的结果基本是达到了state-of-art的水平。baseline的结果是一个三层卷积加两层全连接加一层10单元的 softmax层组成的CNN网络(256x256x128x328x192x10,损失函数为交叉熵)取得的。在各种routing-by-agreement的迭代次数和有无重构正则化方法的对比显示出routing-by-agreement和重构正则化的有效性(routing-by-agreement的有效性看起来不如重构正则化)。


用重构展示了capsule每个维度代表的特征
作者利用重构网络来观察capsule每个维度代表的特征,方法是在Digit Capsule的某个维度上做一点改变然后观察重新重构出的结果,如下图所示演示了几种Digit Capsule的某个维度所代表的特征,这样的实验也能反应出胶囊网络学习到特征的鲁棒性。这个实验我觉得确实是展现了CapsNet学习特征的能力,如果更近一步验证我觉得应该是将重构得到的数字返回给检测网络,看对应的值的改变是否与人为改变的相符。

对于仿射变换的鲁棒性
因为普通的MNIST的数字也有很多的variation,比如在skew, rotation, style, width, stroke thickness等方面,所以CapsNet的胶囊从中学到了可以应对variation的向量。
作者为了展示网络对于仿射变换的鲁棒性又用两种扩展的MNIST数据集做了测试实验(并没有在这两种新的数据集上做训练),均取得了较好的实验结果,一个未充分训练的CapsNet( with early stopping which achieved 99.23% accuracy on the expanded MNIST test)可以在affnist测试集上达到 79% 的正确率,与之相对的,一个参数量相当的传统CNN(在扩展集上达到99.22%准确度)只取得了 **66%**的正确率。
- a padded and translated MNIST training set, 在这个数据集中MNIST字符被随机地放在一张黑色的40 × 40 pixels的背景上
- affNIST4 data set,这个数据集中数字是有随机的小的仿射变换的。
分割高度重叠的数字
作者讲了“routing-by-agreement”方法产生类似于并行注意力( parallel attention)的效果,可以使得每个上层胶囊只专注于下层的部分胶囊而忽略其他的。这样就能允许网络可以在一张图片中识别多个实例,即使实例间有所重叠。作者希望这种机制有利于重叠实例的分割,而不借助于像素级的分割操作。作者用MNIST的测试和训练集分别制作了每张图片含有两个不同数字且重叠度高达80%的重叠数据集,原来的每张图像产生1K个 MultiMNIST examples,最后的训练和测试集的规模达到了60M和10M。与原网络不同的是新的网络的输出结果取长度值最大的两个Digit Capsule的label作为结果,学习率的衰减步进增大了10倍,因为数据集增大了。输入图像和输出经过重构的几张展示结果如下:

另外,重构的结果显示CapsNet虽然处理的是整幅图片(也就是说不需要分割),但是可以排除重叠的干扰,从中识别出单独的数字。
其他的数据集
作者又在CIFAR10上用CapsNet做了实验,使用了一些不同的超参数,用一个集成了7个模型(每个模型都是上文介绍的三层网络)的网络(每个模型经过三轮“routing-by-agreement”on 24 × 24 patches of the image)取得了10.6%的错误率,这样的识别准确率是与CNN最初应用到CIFAR10时相当。论文还简单介绍了CapsNet在其他简单的数据集上的应用,包括smallNORB(3D模型的图像,5个种类,每个种类10张图片,训练集和测试集各占一半)和SVHN(门牌号的街景图片,类似于MNIST的RGB彩色图像,作者用的训练样本为73257个),网络结构都所调整。
讨论和先前的工作
简述了用了将近30年的HMM(hidden Markov model )加高斯混合器(Gaussian Mixture)方法和目前的RNN(Recurrent Neural Network)在语音识别任务上的对比,HMM+GM方法容易学习,计算量小,但是表达能力有限( one-of-n representation),如果需要增强表达能力需要将参数量平方,与RNN( distributed
representations)线性增大参数量相比效率指数型下降的。然后由此引发对CNN在图像识别领域的指数型低效的思考,这一问题在图像的仿射变换上凸现出来,要适应视角变换引发的variation需要指数型增多detector和训练样本。而CapsNet的设计初衷就是解决这一问题,它将像素值转换为代表实例特征的向量,然后从经过变换矩阵得到的结果来对实例的属性做出推测。作者的这段话很关键,我还是不要翻译了,读原文合适。
Capsules avoid these exponential inefficiencies by converting pixel intensities into vectors of instantiation parameters of recognized fragments and then applying transformation matrices to the fragments to predict the instantiation parameters of larger fragments. Transformation matrices that learn to encode the intrinsic spatial relationship between a part and a whole constitute viewpoint invariant knowledge that automatically generalizes to novel viewpoints.
作者最后再次对CapsNet的效果进行了理论分析:
- CapNet做了一个很强的假设:在图片的每个位置都有capsule表示的一种事物的一个实例( At each location in the image, there is at most one instance of the type of entity that a capsule represents)。这个假设(由来是一种称为"crowding" 的感知现象)消除了捆绑问题(binding problem), 并且使得胶囊可以使用distributed representation (its activity vector)来对某个位置上一种事物的一个实例的属性进行编码,这种distributed representation比activating a point on a high-dimensional grid是指数型地有效。有了正确的distributed representation,胶囊就可以充分利用空间关系可以通过矩阵乘来调制这一事实。
- CapsNet提取的特征向量可以随variation的变化而变化,而不是竭力去消除variation,向量对variation的鲁棒性是更加高的,可以应对的变换情况更多。
- CapsNet采用的“routing-by-agreement”方法有利于实现对图像的分割识别,我想这可能是由于输入进来的图像中的多个实例的特征都可以分别找到合适的Digit Capsule吧。
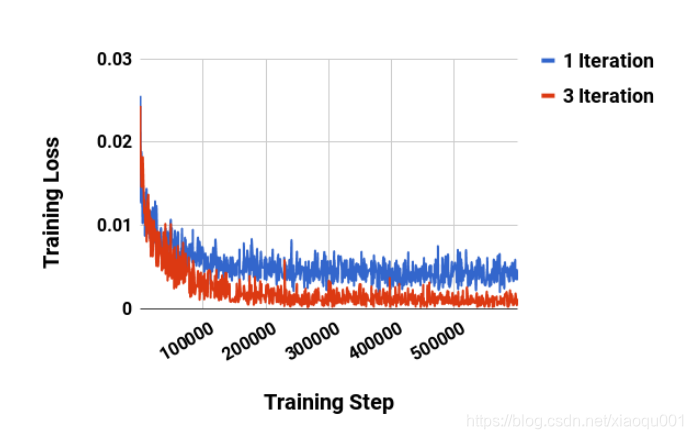
附录:how many routing iterations to use?
作者在附录中给出了对路由迭代次数的分析和评估,简单说来可以概括为两点:第一点是
b
i
j
b_{ij}
bij在每一轮之间的改变量在2次迭代之后就很小了,如图Figure A.1(a)(b)所示,所以也就没必要再做多余的迭代计算;第二点是迭代次数过多会增大模型的容量导致过拟合,经过对1-iteration和3-iteration的对比实验,作者最终建议3-iteration,这种情况可以让训练收敛更快,也不至于过拟合,如图Figure A.2所示。

个人思考
首先,我个人理解CapsNet设计的初衷应该是期待在网络中学习到实例向量化的信息,比如姿势、变形、速度、质地、反光度,尤其是物体线条的向量化信息,那么是向量的话就可以经得住仿射变换,而且用不同的方向就可以演绎出很多variation版本,因此用张量神经元组来代替单个神经元激活值的标量,从而可以接受仿射变换保留实例的一些属性信息,还可以经受住variation的考验。另外,我没想到
b
i
j
b_{ij}
bij是每次迭代都要重置为0,而不是经过学习的,“routing-by-agreement”在形式上是"max-pooling"的替代,但这种向上级选择性传递的方法使得下级胶囊可以“各找各的主子”,具有了一定的并行识别能力,因此是一种有效解决重叠问题的“explaining way”。虽然可以同时识别两个不同的数字,但是不能同时识别两个相同的数字还是一个掣肘的缺点。我个人认为,图像识别还是要有位置信息,每个位置都有或大或小不同的instance,都应该被识别出来。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)