spark由scala语言编写,开发spark程序,自然也少不了scala环境,这里介绍如何利用Intellij IDEA开发spark。
1、环境准备。jdk,scala,idea这些对于本文来说都已经默认安装。
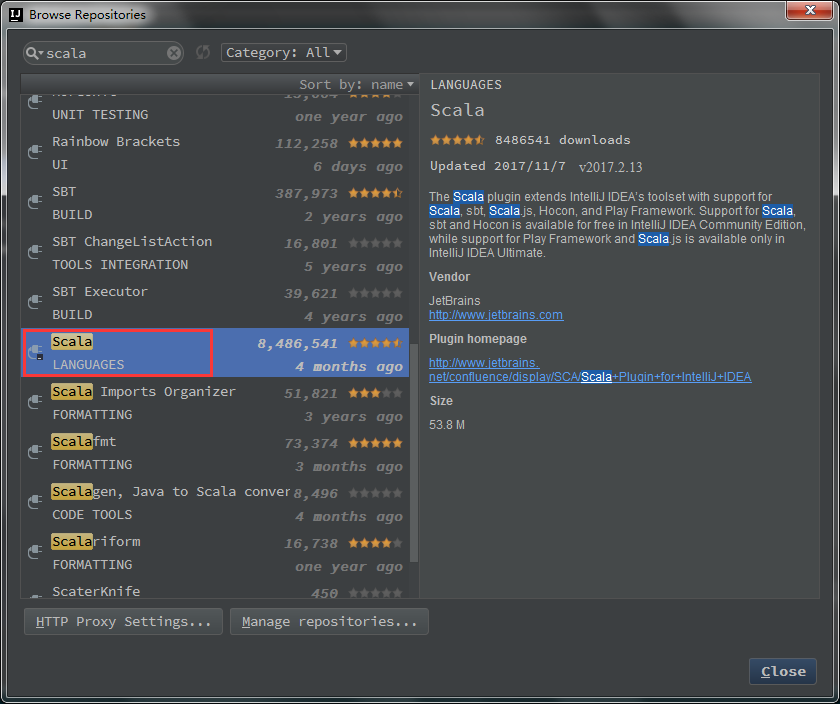
2、idea中安装scala language插件。File->Settings->Plugins->Browse Repositories,搜索scala。选中Scala,点击Install。
3、新建java工程。
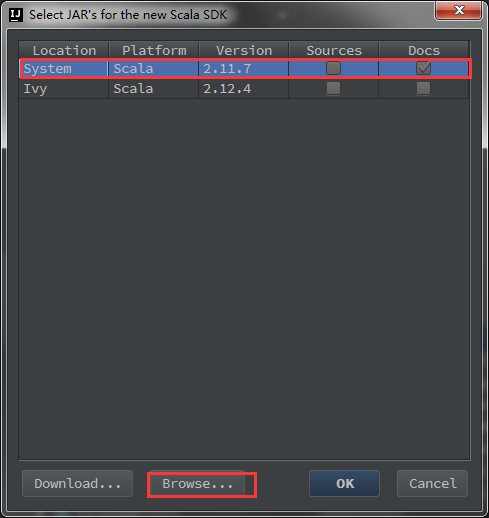
4、设置scala sdk。File->Project Structure->Libraries->+,新建Scala SDK。

如果之前没有配置过系统的scala sdk,选择Browse,指定系统中安装的scala位置。
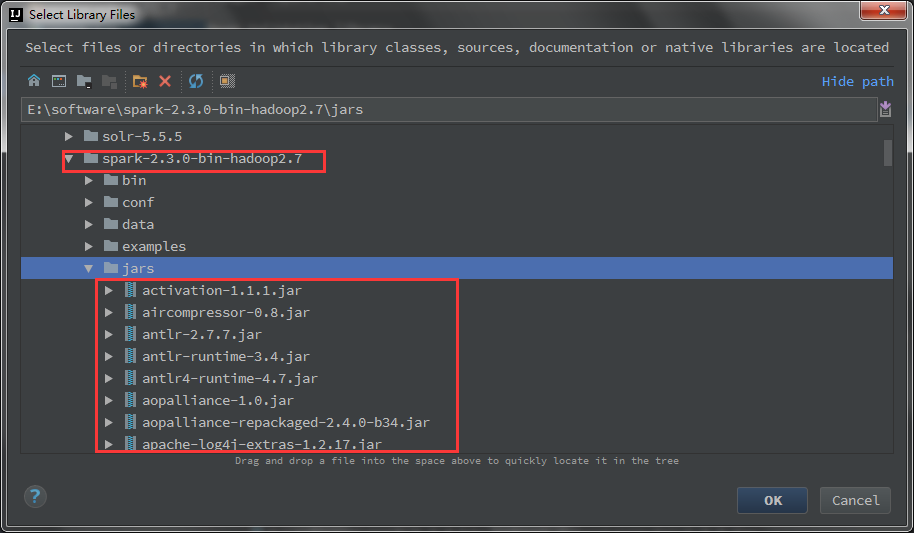
5、导入spark-library。继续上一步中的File->Project Structure->Libraries->+Java。新建一个java的库,然后导入spark的jar包。最后可以对jar文件夹命名。这里我叫spark-lib。
最终形成的libary长这样子。

6、设置sources。File->Project Structure->Modules->Sources->src。这里选中src,右键New Folder取名main,然后在main下面new folder:java,resources,scala。最后右键scala文件夹,选择Sources。然后右侧的+Add Content Root下面就会增加src\main\scala作为源文件夹。
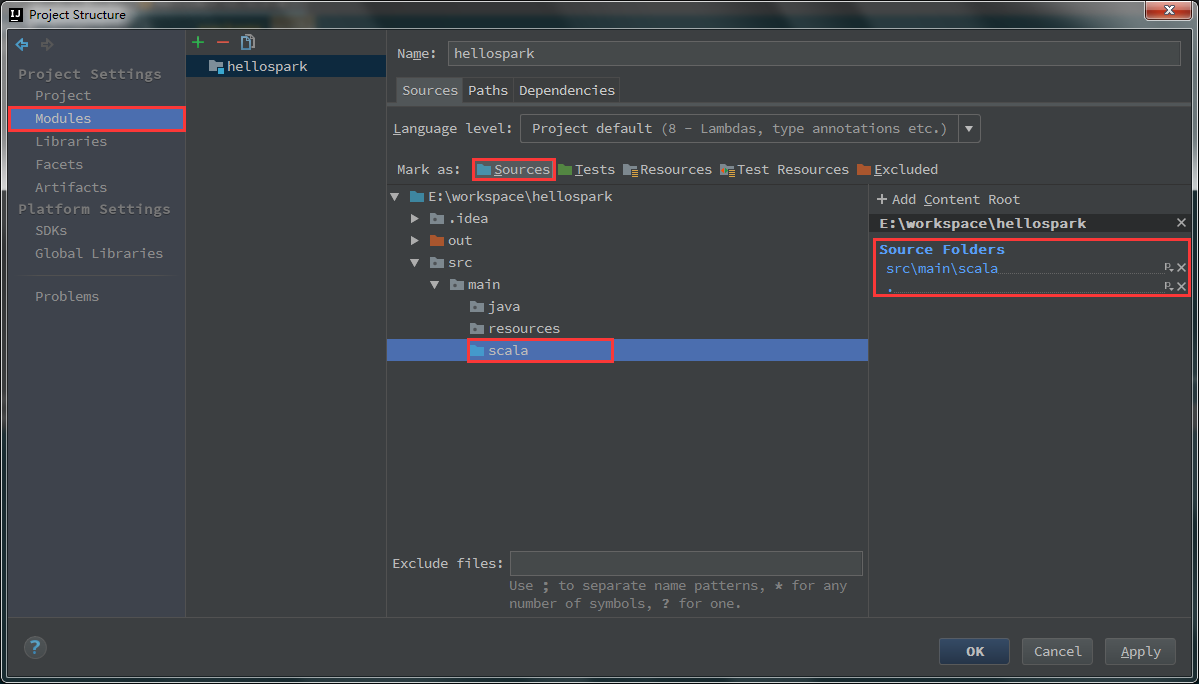
如果不设置源文件夹或者设置错误,后面运行spark程序会出错。
不设置时,报错
错误: 找不到或无法加载主类 scala.HelloWorld
main,main\scala文件夹均设置为Sources就会报如下错误,因此只需要设置scala文件夹为Sources。
Error:(5, 8) HelloWorld is already defined as object HelloWorld
object HelloWorld {
7、编写程序。右键scala文件夹->New->Scala Class->选择object。

编码如下:
package scala
import org.apache.spark.{SparkConf, SparkContext}
object HelloWorld {
def main(args: Array[String]): Unit = {
val logFile = "E:\\software\\spark-2.3.0-bin-hadoop2.7\\helloSpark.txt"
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
val rdd = sc.textFile(logFile)
val counts = rdd.flatMap(line=>line.split(",")).map(x=>(x,1)).reduceByKey((x,y)=>(x+y))
counts.foreach(println)
sc.stop()
}
}
运行,Ctrl+Shift+F10。
以下是部分日志,单词统计结果出现在日志中:
2018-04-04 23:32:57 INFO Executor:54 - Running task 0.0 in stage 1.0 (TID 1)
2018-04-04 23:32:57 INFO ShuffleBlockFetcherIterator:54 - Getting 1 non-empty blocks out of 1 blocks
2018-04-04 23:32:57 INFO ShuffleBlockFetcherIterator:54 - Started 0 remote fetches in 6 ms
(scala,1)
(spark,2)
(hello,3)
(sparkui,1)
(java,1)
2018-04-04 23:32:57 INFO Executor:54 - Finished task 0.0 in stage 1.0 (TID 1). 1138 bytes result sent to driver
2018-04-04 23:32:57 INFO TaskSetManager:54 - Finished task 0.0 in stage 1.0 (TID 1) in 56 ms on localhost (executor driver) (1/1)
2018-04-04 23:32:57 INFO TaskSchedulerImpl:54 - Removed TaskSet 1.0, whose tasks have all completed, from pool
2018-04-04 23:32:57 INFO DAGScheduler:54 - ResultStage 1 (main at <unknown>:0) finished in 0.072 s
2018-04-04 23:32:57 INFO DAGScheduler:54 - Job 0 finished: main at <unknown>:0, took 0.859162 s
2018-04-04 23:32:57 INFO AbstractConnector:318 - Stopped Spark@1f4c2977{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2018-04-04 23:32:57 INFO SparkUI:54 - Stopped Spark web UI at http://10.119.9.164:4040
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)