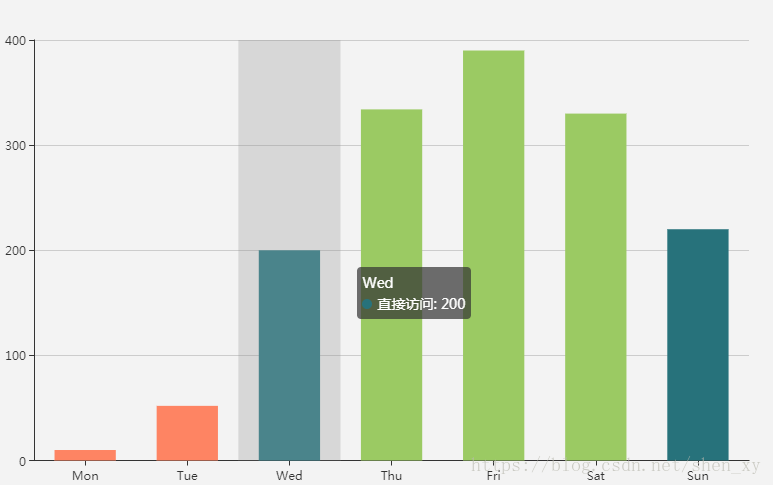
series : [
{
name:'直接访问',
type:'bar',
barWidth: '60%',
data:[10, 52, 200, 334, 390, 330, 220],
itemStyle:{
normal:{
color:function(params){
if(params.value >0 && params.value <100){
return "#FE8463";
}else if(params.value >=100 && params.value<=300 ){
return "#27727B";
}
return "#9BCA63";
}
}
}
}
]
转自:https://blog.csdn.net/shen_xy/article/details/79852503
转载于:https://www.cnblogs.com/bing0709/p/10601150.html
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)